Downloaded 41 times

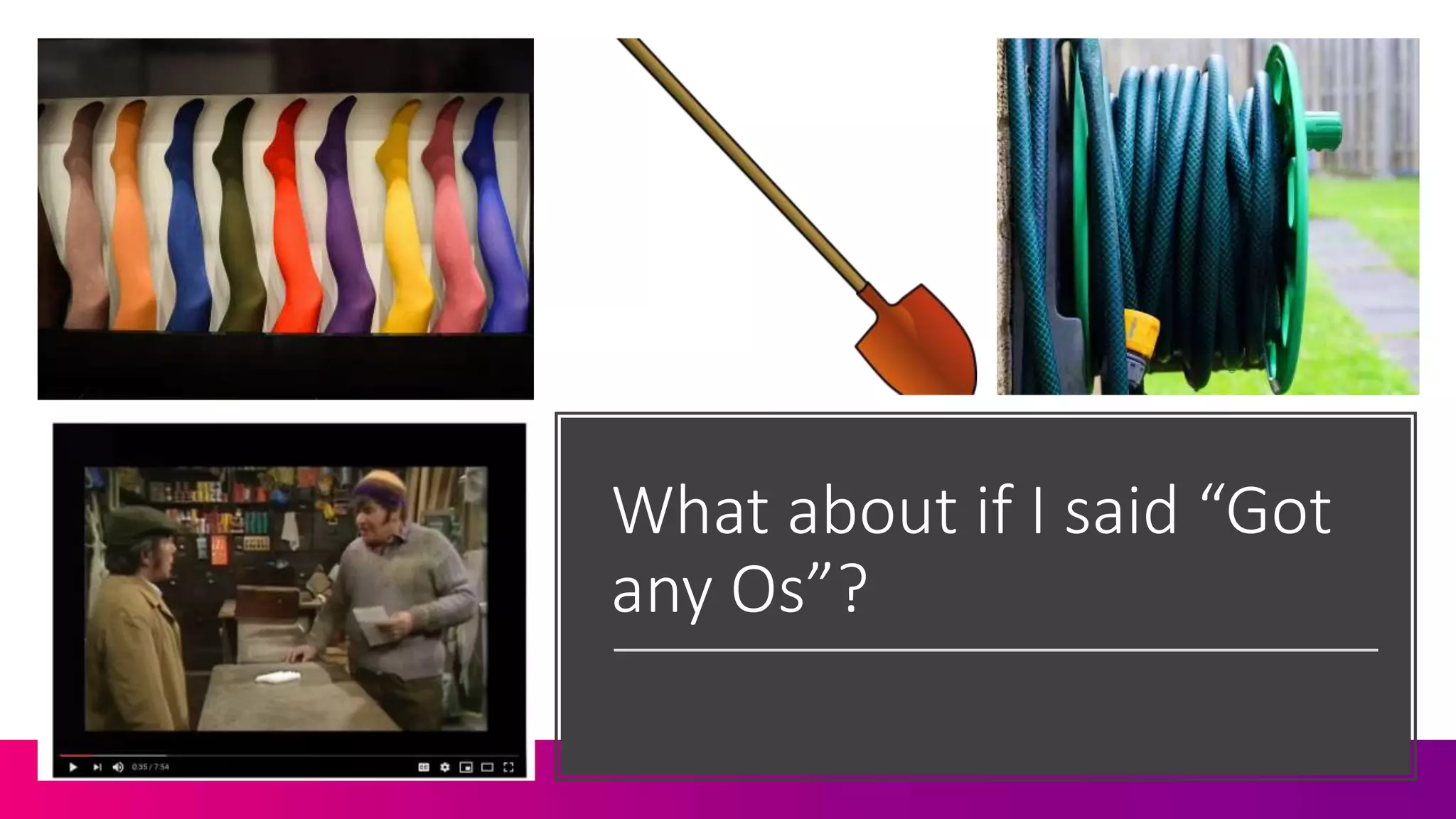
![If I came into
your hardware
store…
Image Attribution: Acabashi [CC BY-SA 4.0 (https://creativecommons.org/licenses/by-sa/4.0)]](https://image.slidesharecdn.com/c3-conductor-talk-2019-final-dawn-anderson-190509072543/75/Natural-Language-Processing-and-Search-Intent-Understanding-C3-Conductor-2019-Dawn-Anderson-2-2048.jpg)









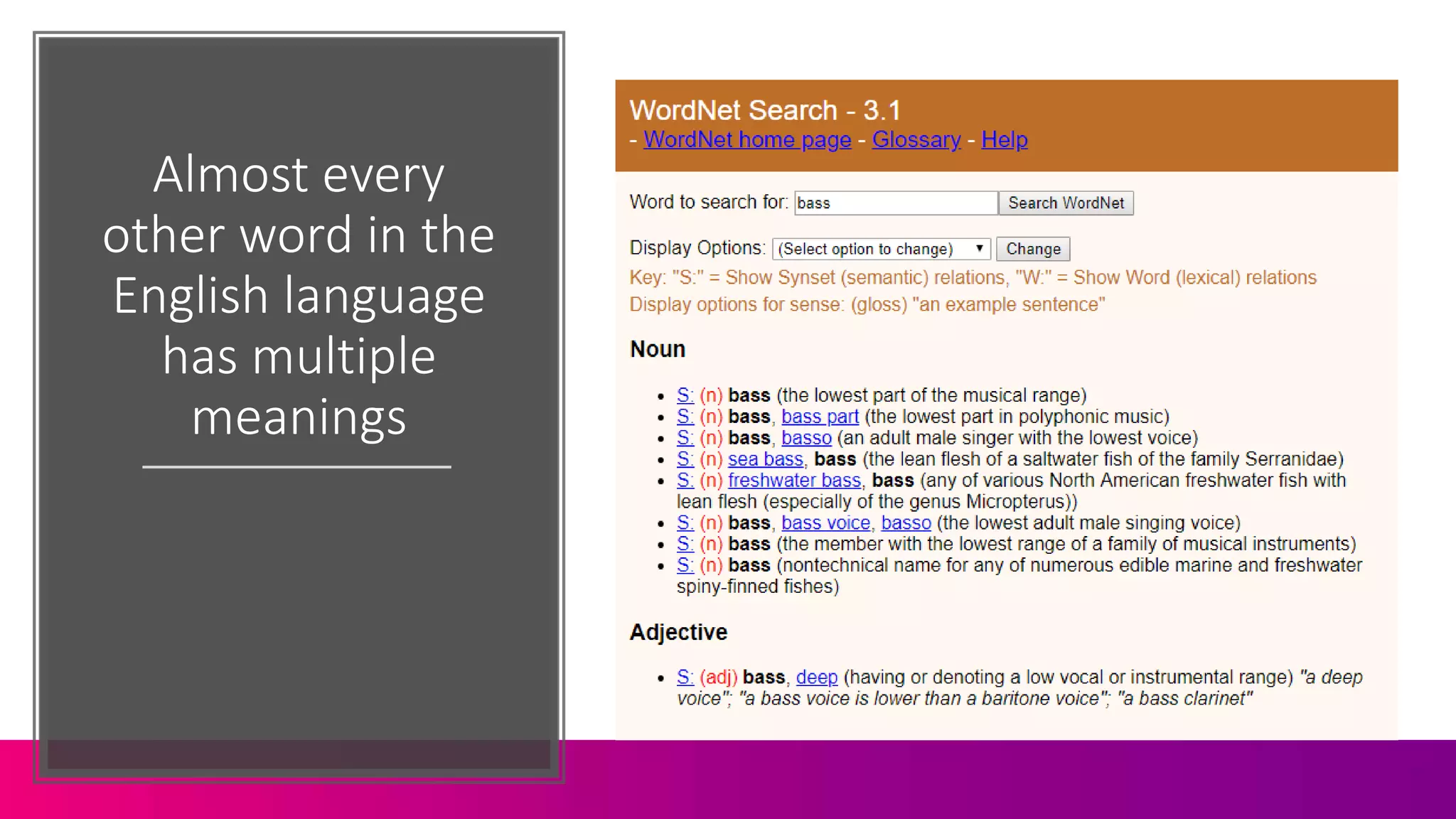
![“The meaning of a word is
its use in a language”
(Ludwig Wittgenstein
, 1953)
Image attribution: Moritz Nähr [Public domain]](https://image.slidesharecdn.com/c3-conductor-talk-2019-final-dawn-anderson-190509072543/75/Natural-Language-Processing-and-Search-Intent-Understanding-C3-Conductor-2019-Dawn-Anderson-14-2048.jpg)


























































































































![[Four candles] interest over time](https://image.slidesharecdn.com/c3-conductor-talk-2019-final-dawn-anderson-190509072543/75/Natural-Language-Processing-and-Search-Intent-Understanding-C3-Conductor-2019-Dawn-Anderson-162-2048.jpg)
![[Fork Handles] interest over time](https://image.slidesharecdn.com/c3-conductor-talk-2019-final-dawn-anderson-190509072543/75/Natural-Language-Processing-and-Search-Intent-Understanding-C3-Conductor-2019-Dawn-Anderson-163-2048.jpg)

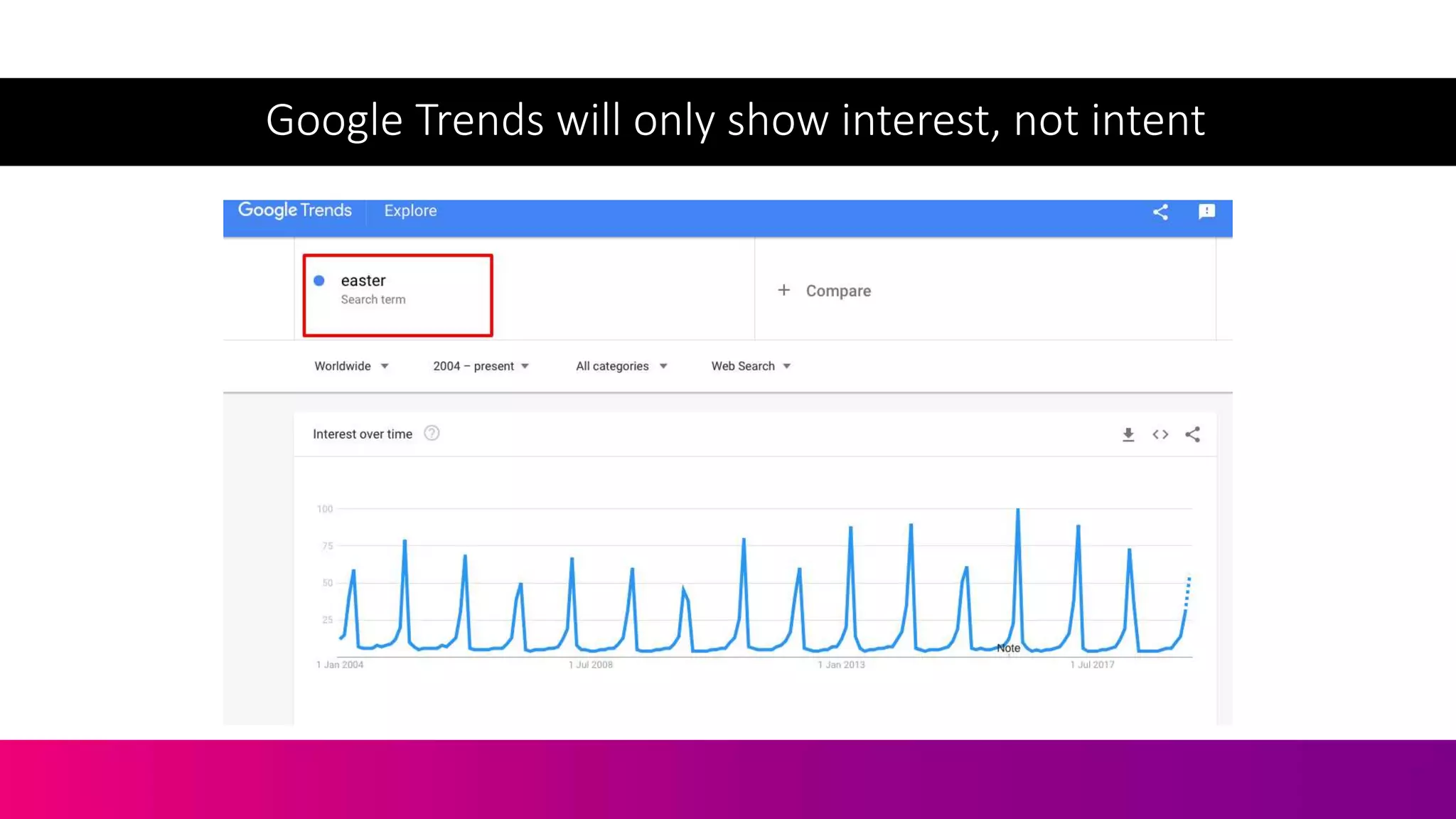

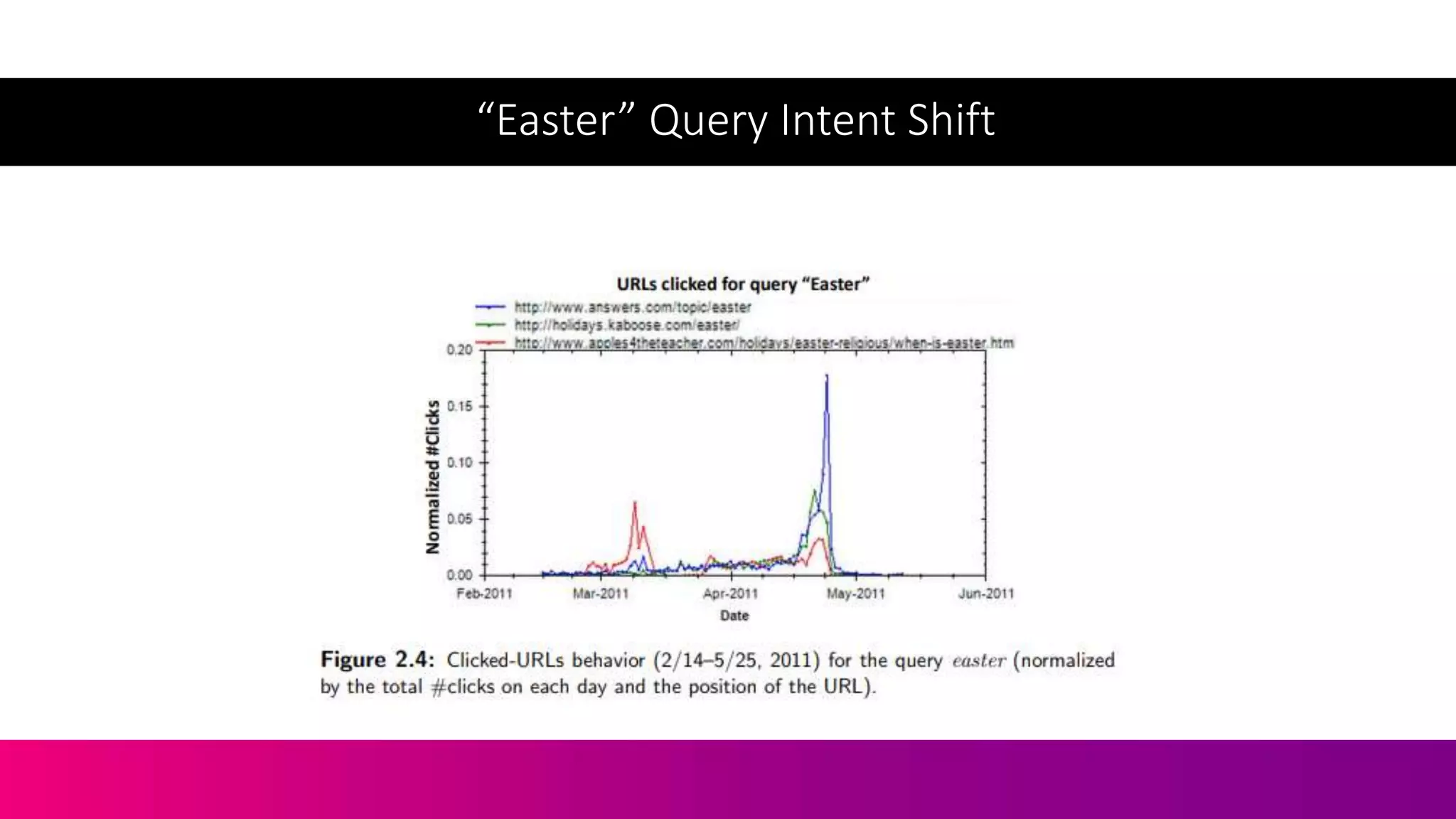
![Let’s Take The Query [Easter]](https://image.slidesharecdn.com/c3-conductor-talk-2019-final-dawn-anderson-190509072543/75/Natural-Language-Processing-and-Search-Intent-Understanding-C3-Conductor-2019-Dawn-Anderson-167-2048.jpg)





























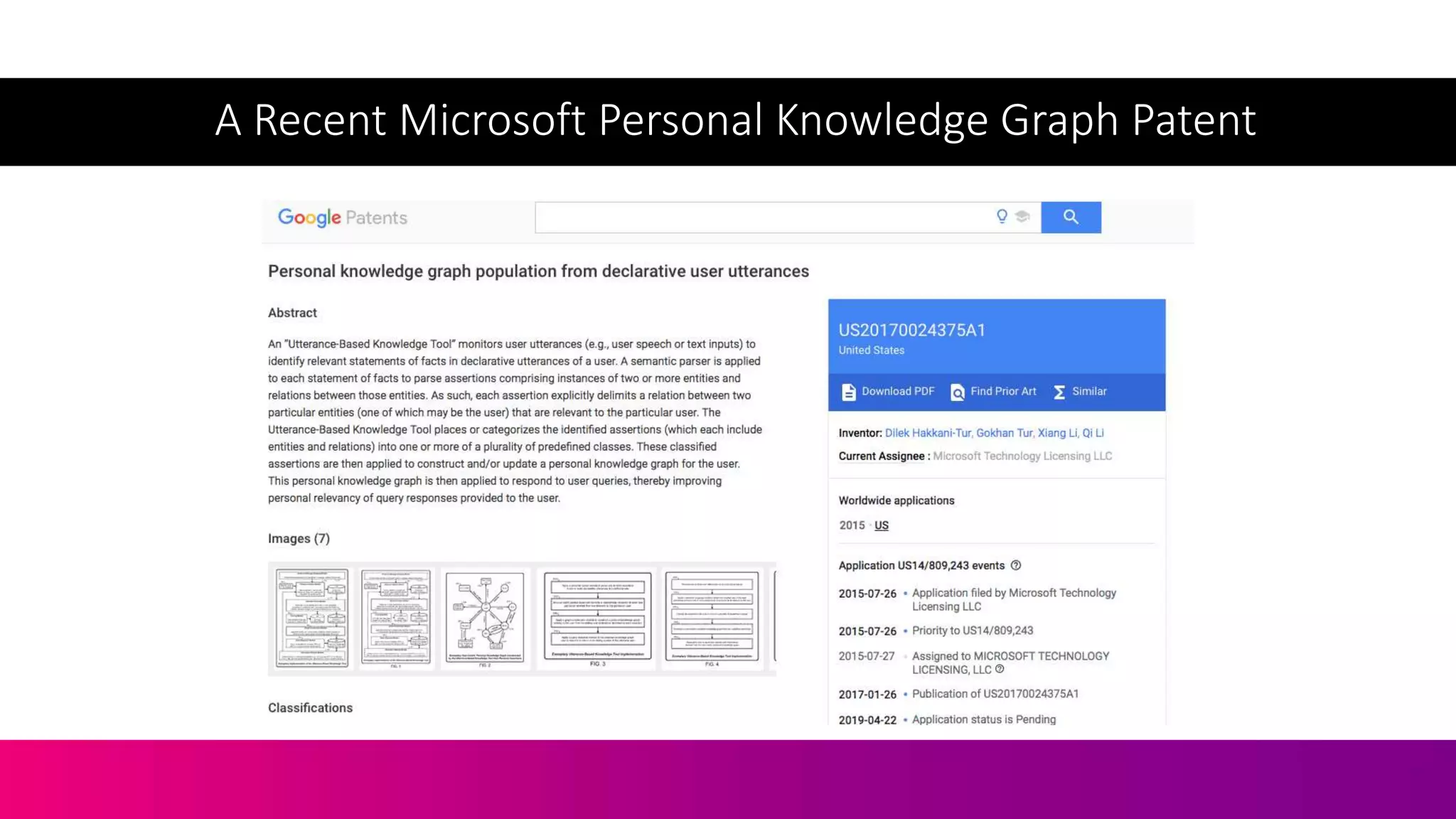





![• Balog, K - Entity-Oriented Search | SpringerLink. 2019. Entity-Oriented Search |
SpringerLink. [ONLINE] Available at: https://link.springer.com/book/10.1007/978-
3-319-93935-3. [Accessed 06 May 2019].
• Boyd-Graber, J., Hu, Y. and Mimno, D., 2017. Applications of topic
models. Foundations and Trends® in Information Retrieval, 11(2-3), pp.143-296.
• ECIR 2019. 2019. Proceedings. [ONLINE] Available
at: http://ecir2019.org/proceedings/. [Accessed 06 May 2019].
• Gabrilovich, E. and Markovitch, S., 2007, January. Computing semantic relatedness
using wikipedia-based explicit semantic analysis. In IJcAI (Vol. 7, pp. 1606-1611).
• Hakkani-Tur, D., Tur, G., Li, X. and Li, Q., Microsoft Technology Licensing LLC,
2017. Personal knowledge graph population from declarative user utterances. U.S.
Patent Application 14/809,243.
• Lim, Y.J., Linn, J., Liang, Y., Steinebach, C., Lu, W.L., Kim, D.H., Kunz, J., Koepnick, L.
and Yang, M., Google LLC, 2018. Predicting intent of a search for a particular
context. U.S. Patent Application 15/598,580.
• Lotfi, A., Bouchachia, H., Gegov, A., Langensiepen, C. and McGinnity, M., 2018.
Advances in Computational Intelligence Systems. Intelligence.](https://image.slidesharecdn.com/c3-conductor-talk-2019-final-dawn-anderson-190509072543/75/Natural-Language-Processing-and-Search-Intent-Understanding-C3-Conductor-2019-Dawn-Anderson-217-2048.jpg)
![• Lohar, P., Ganguly, D., Afli, H., Way, A. and Jones, G.J., 2016. FaDA: Fast
document aligner using word embedding. The Prague Bulletin of
Mathematical Linguistics, 106(1), pp.169-179.
• McDonald, R., Brokos, G.I. and Androutsopoulos, I., 2018. Deep relevance
ranking using enhanced document-query interactions. arXiv preprint
arXiv:1809.01682.
• NTENT. 2019. Query Understanding - NTENT. [ONLINE] Available
at: https://ntent.com/technology/query-understanding/. [Accessed 09 May
2019].
• Plank, Barbara | Keynote - Natural Language Processing: -
https://www.youtube.com/watch?v=Wl6c0OpF6Ho
• Radinsky, Kira - Tedx Talk -
https://www.youtube.com/watch?v=gAifa_CVGCY
• Radinsky, K., 2012, December. Learning to predict the future using Web
knowledge and dynamics. In ACM SIGIR Forum(Vol. 46, No. 2, pp. 114-115).
ACM.](https://image.slidesharecdn.com/c3-conductor-talk-2019-final-dawn-anderson-190509072543/75/Natural-Language-Processing-and-Search-Intent-Understanding-C3-Conductor-2019-Dawn-Anderson-218-2048.jpg)




![• http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-
gram-model/
• Semantic similarity and relatedness as scaffolding for natural
language processing ->
https://www.youtube.com/watch?v=YTBVfQ8iBSo
• gensim: models.word2vec – Word2vec embeddings. 2019. gensim:
models.word2vec – Word2vec embeddings. [ONLINE] Available
at: https://radimrehurek.com/gensim/models/word2vec.html.
[Accessed 09 May 2019].](https://image.slidesharecdn.com/c3-conductor-talk-2019-final-dawn-anderson-190509072543/75/Natural-Language-Processing-and-Search-Intent-Understanding-C3-Conductor-2019-Dawn-Anderson-223-2048.jpg)

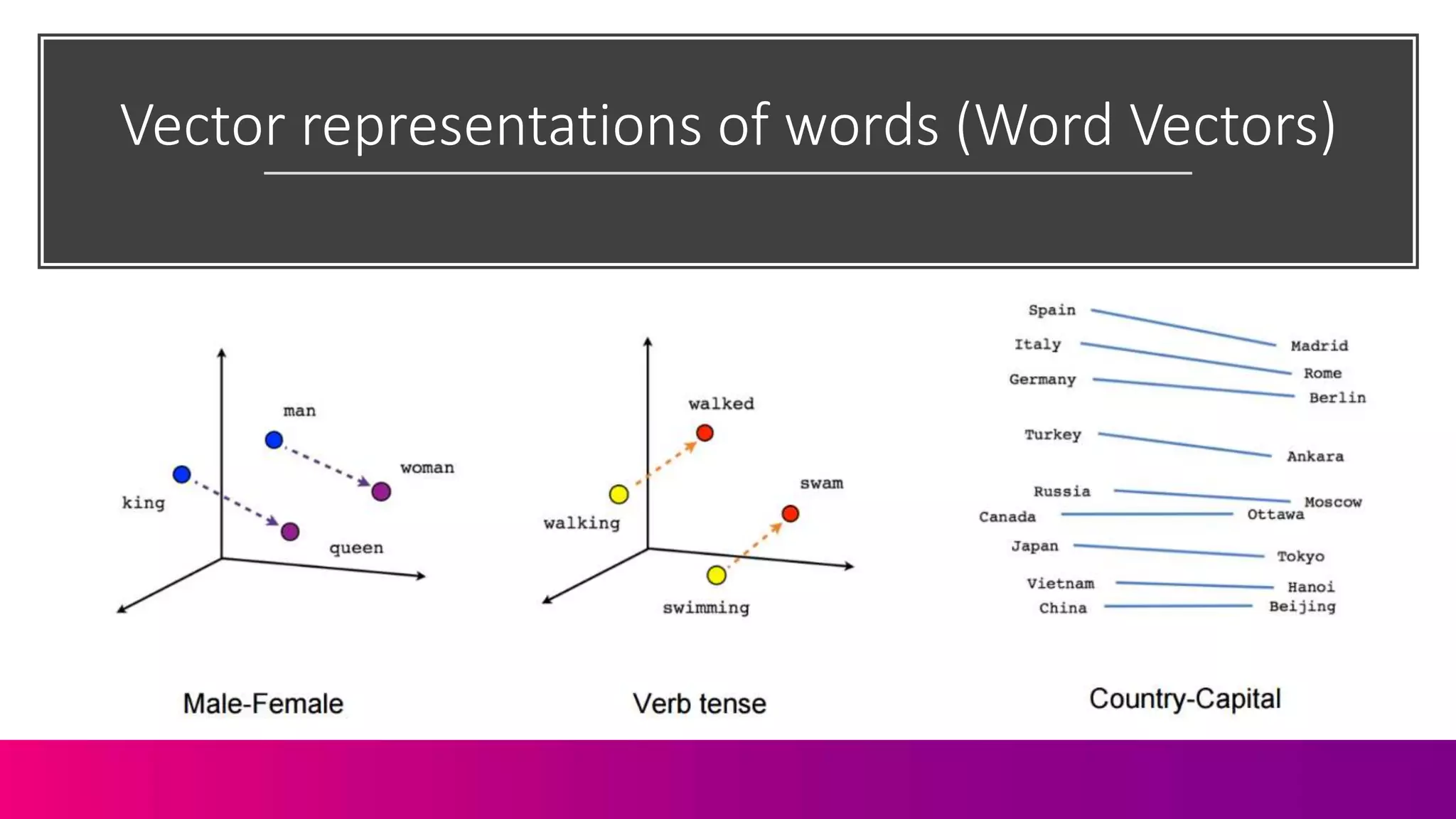
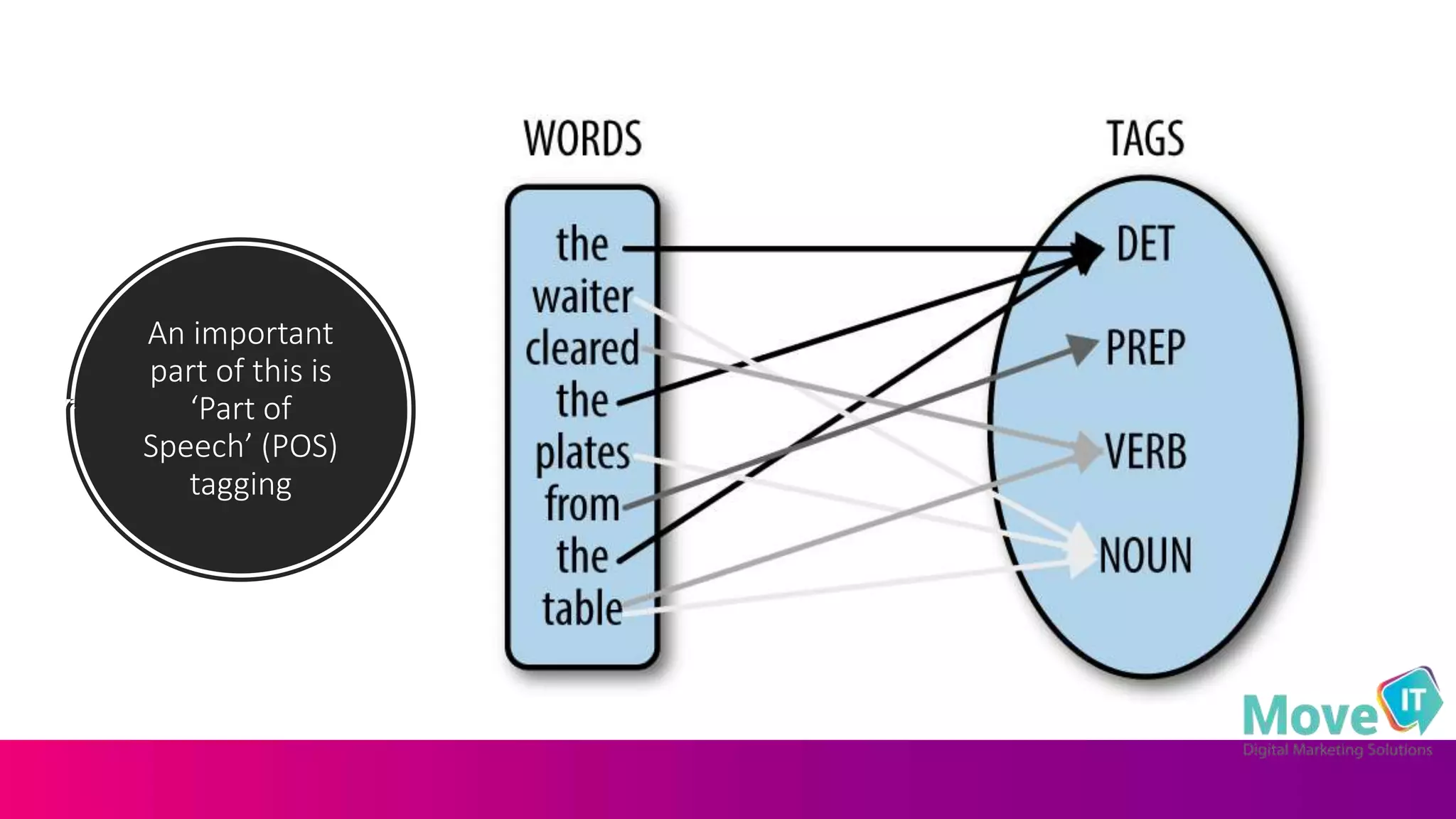
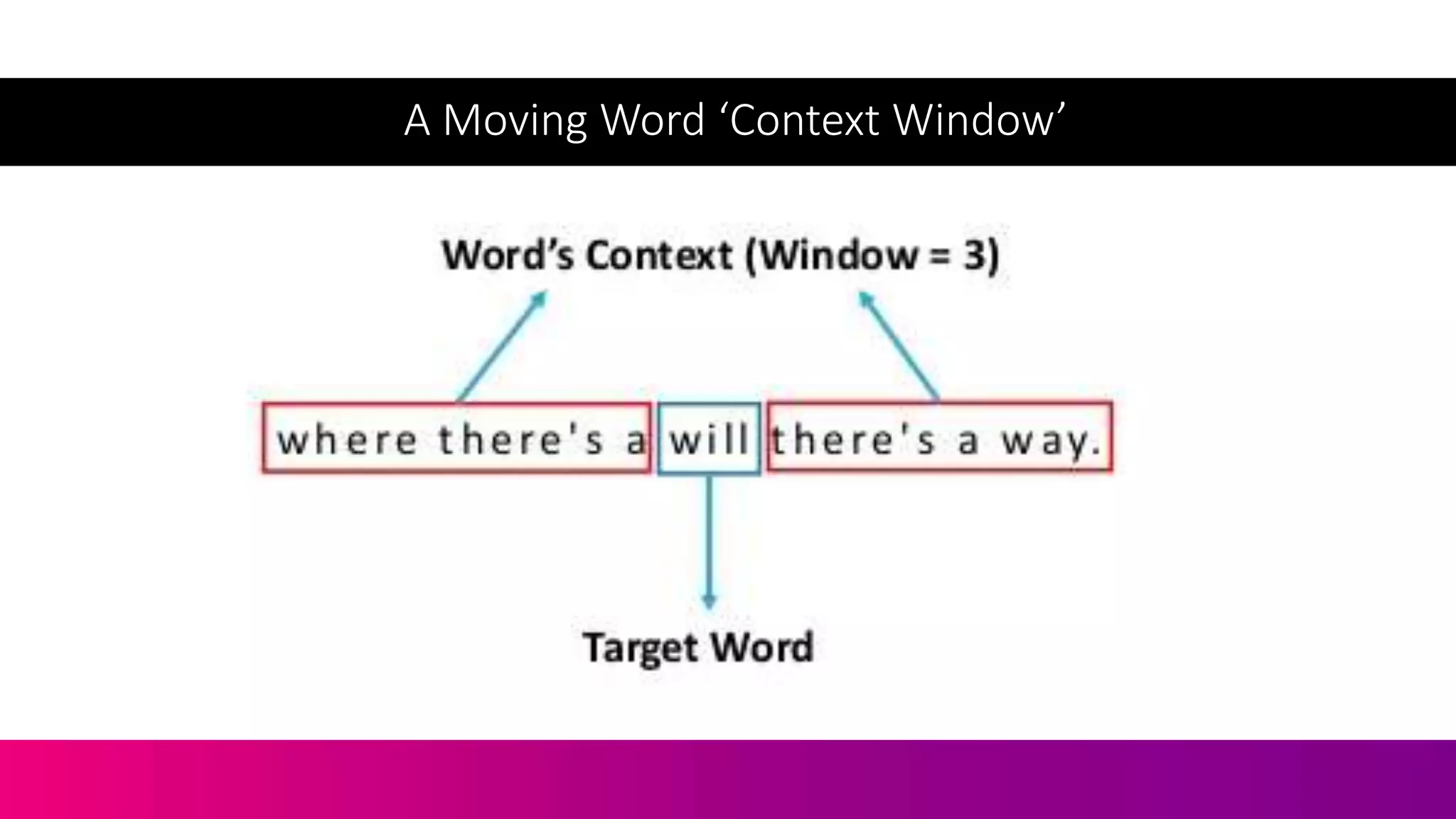
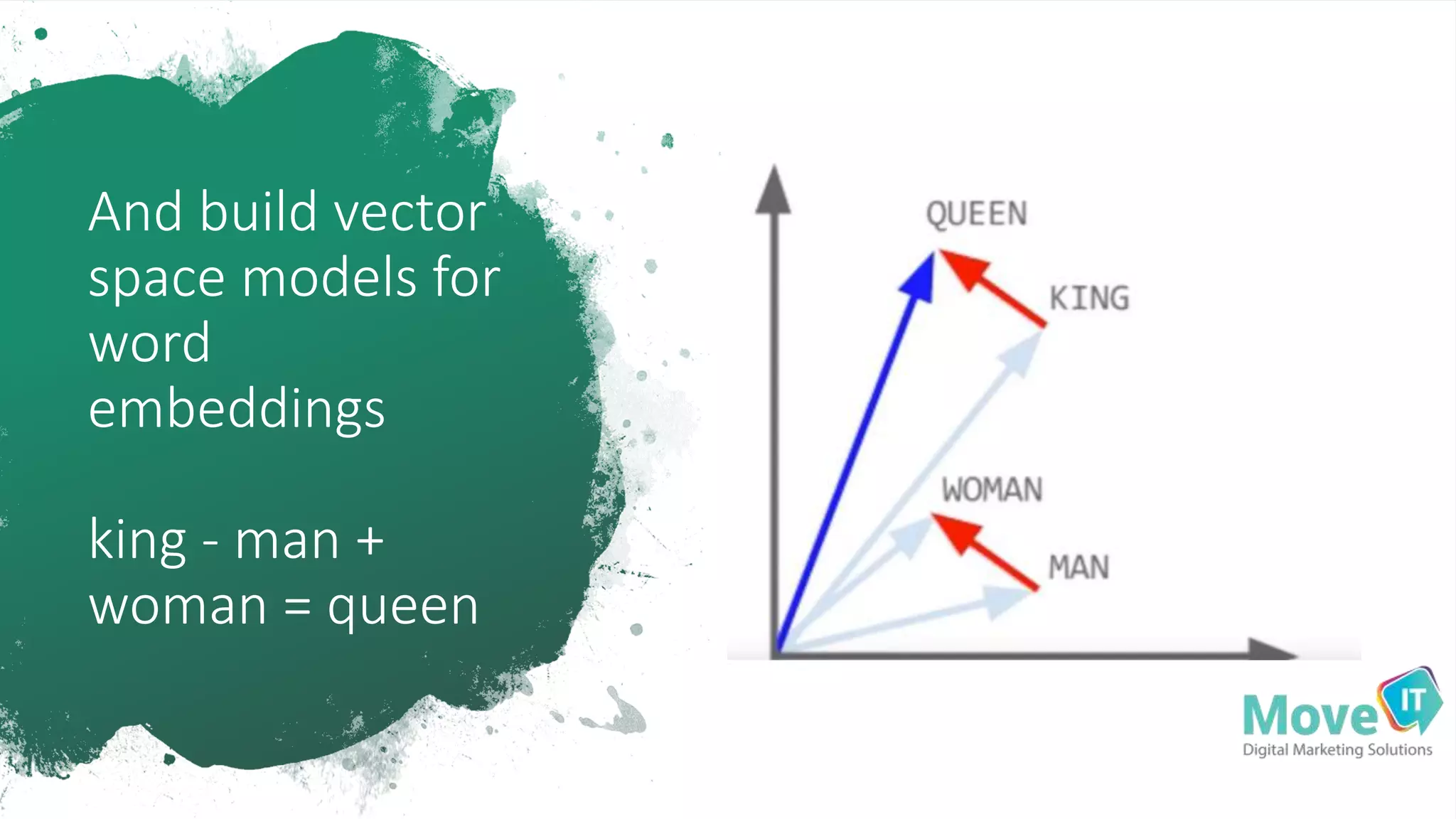
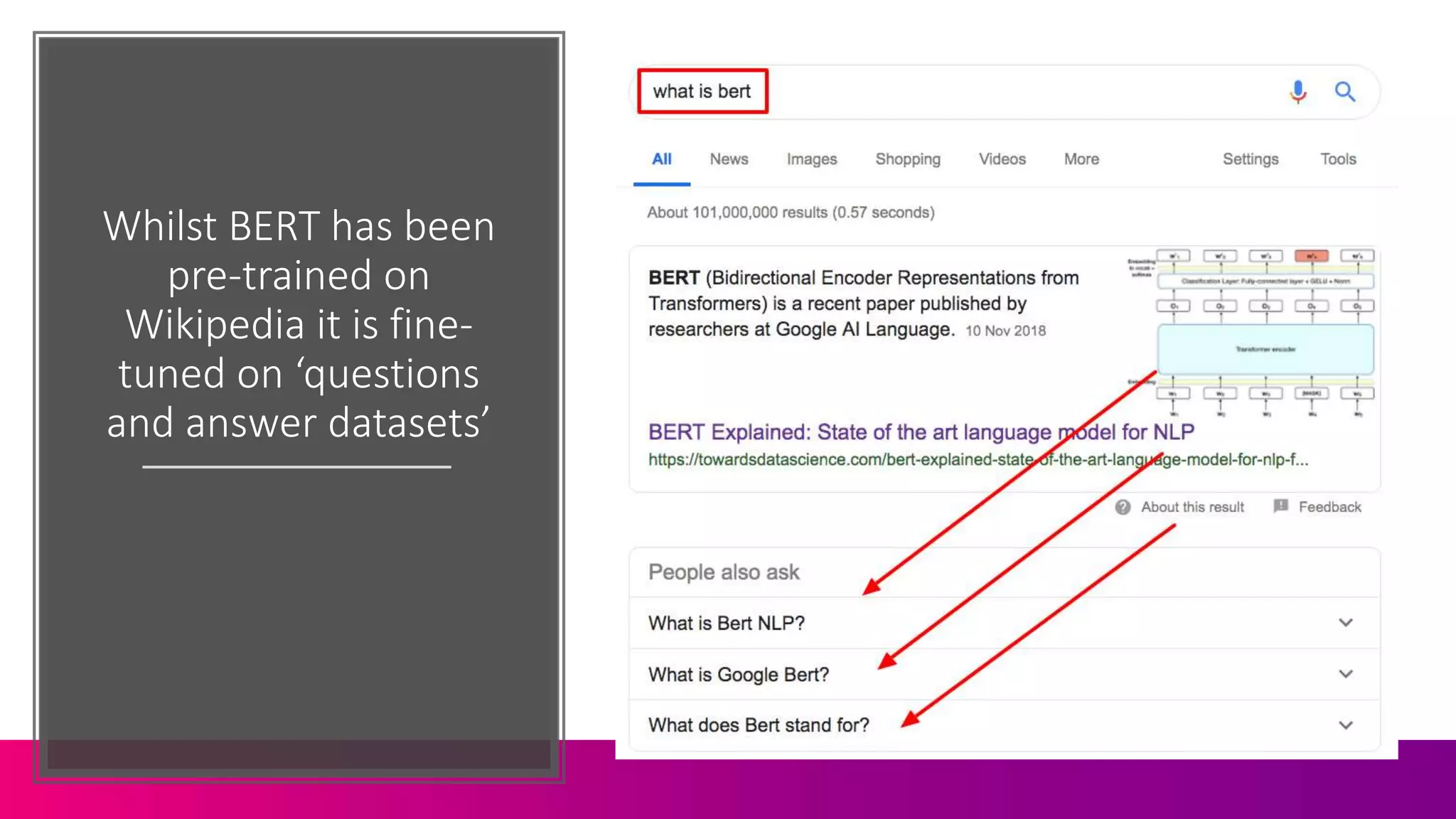
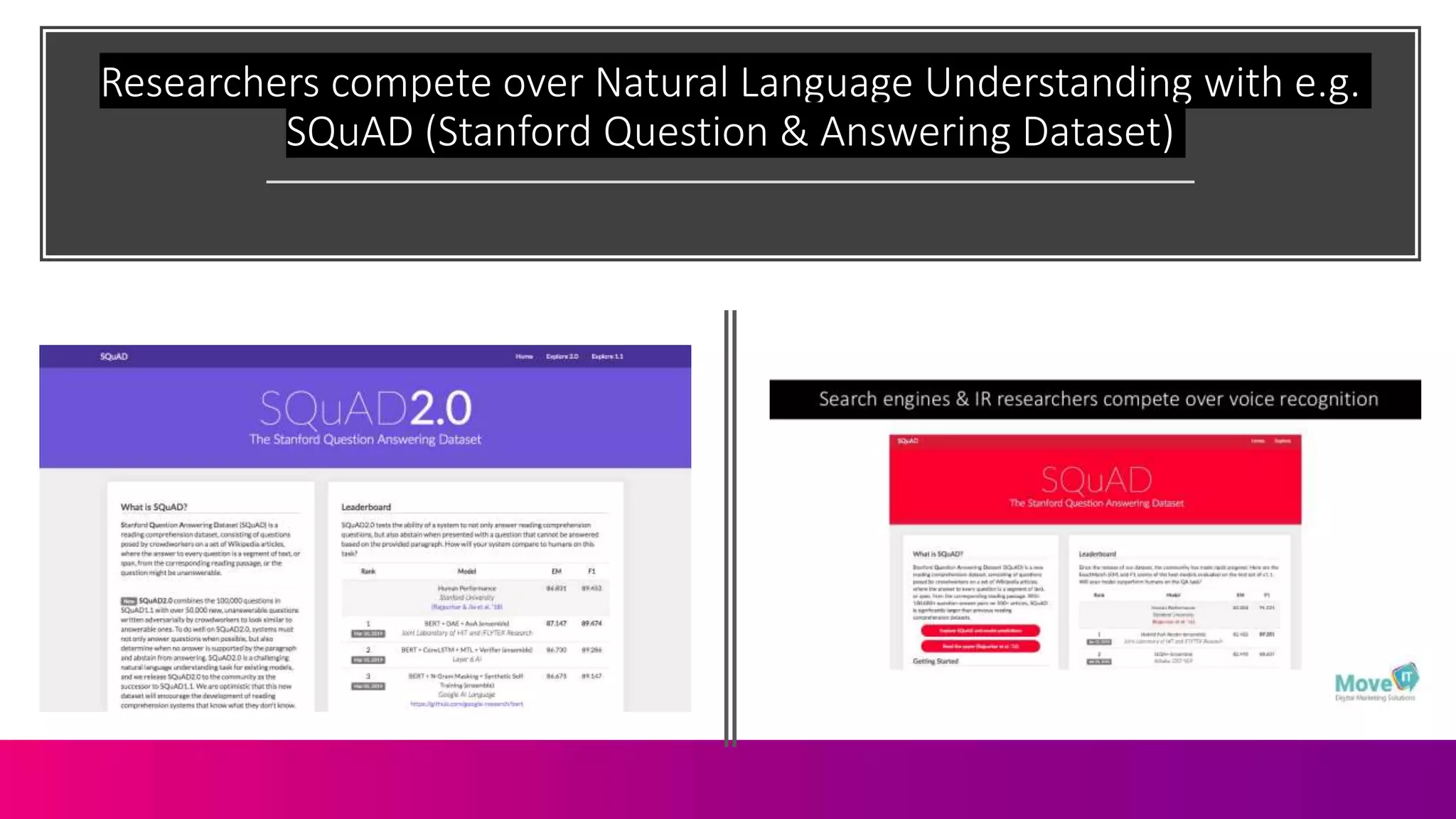
The document discusses the complexities of information retrieval in search engines, emphasizing the importance of contextual understanding, query intent, and the challenges posed by unstructured data. It highlights how algorithms, such as BERT, utilize bi-directional language modeling to improve natural language processing by interpreting context and disambiguating meanings. Additionally, the text explores the evolution of query classification and the significance of structured data and entities in enhancing search relevance.






















![[기초개념] Graph Convolutional Network (GCN)](https://cdn.slidesharecdn.com/ss_thumbnails/agistdkimgcn190507-190507153736-thumbnail.jpg?width=640&height=640&fit=bounds)
































































