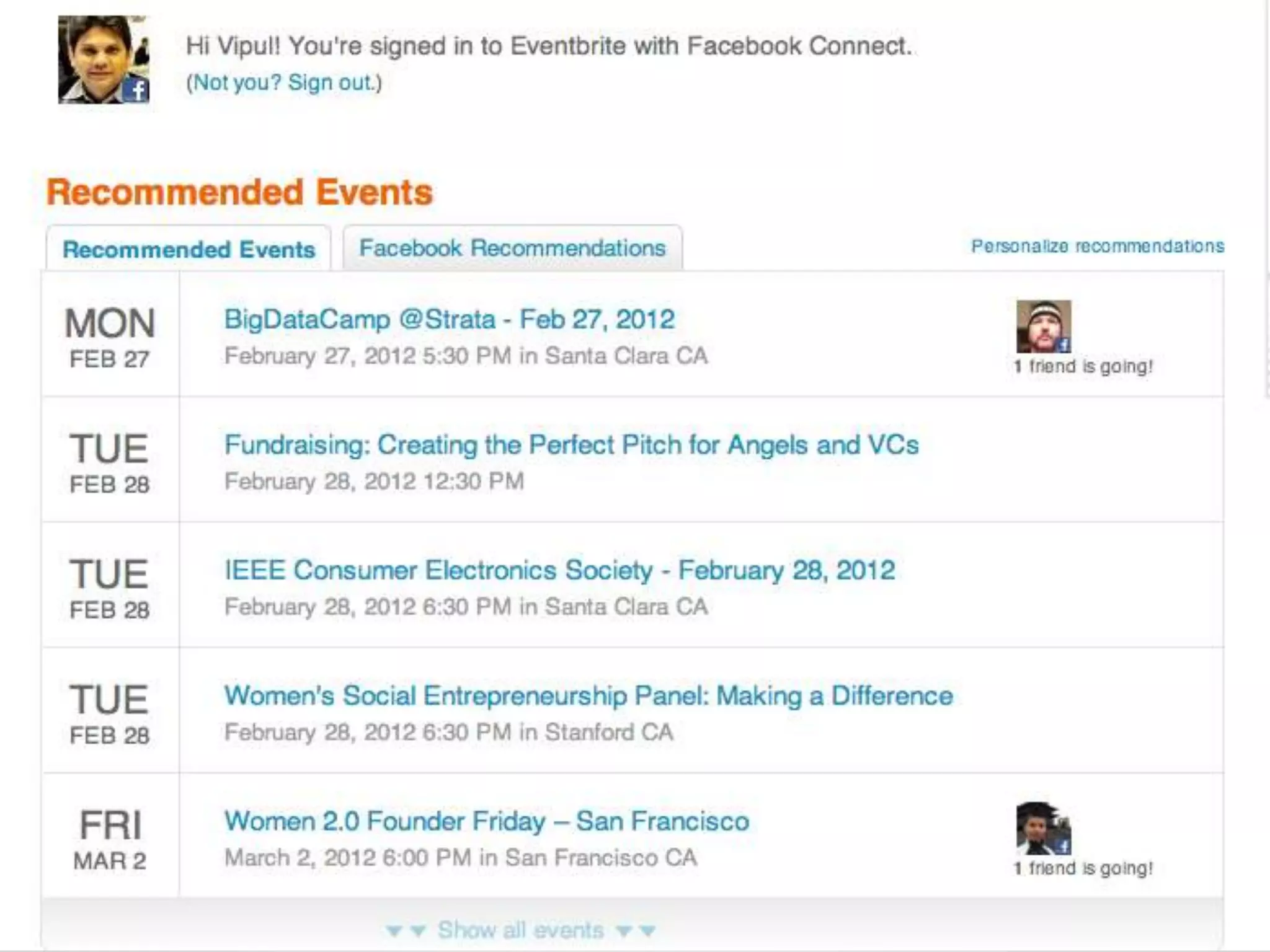
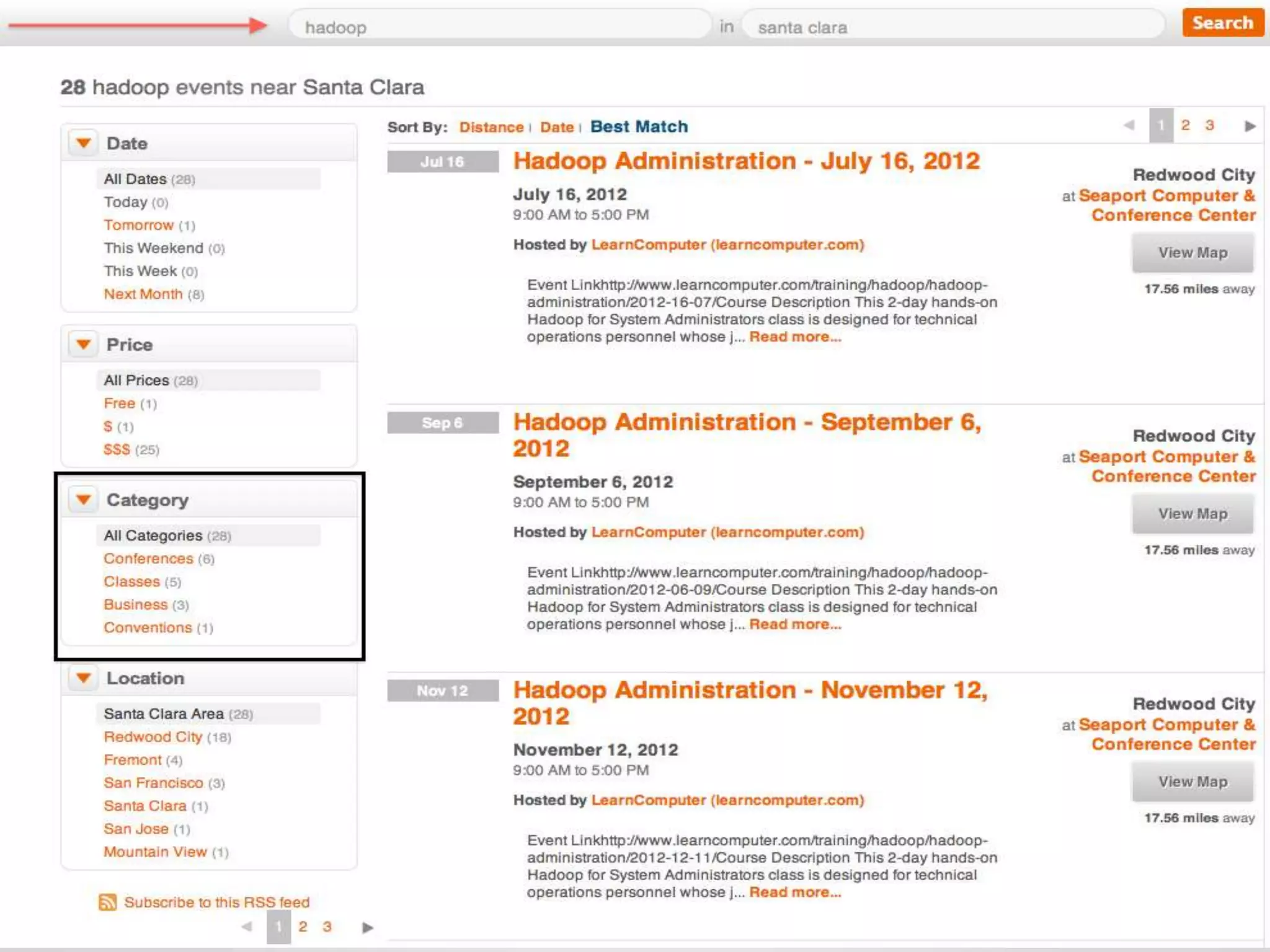
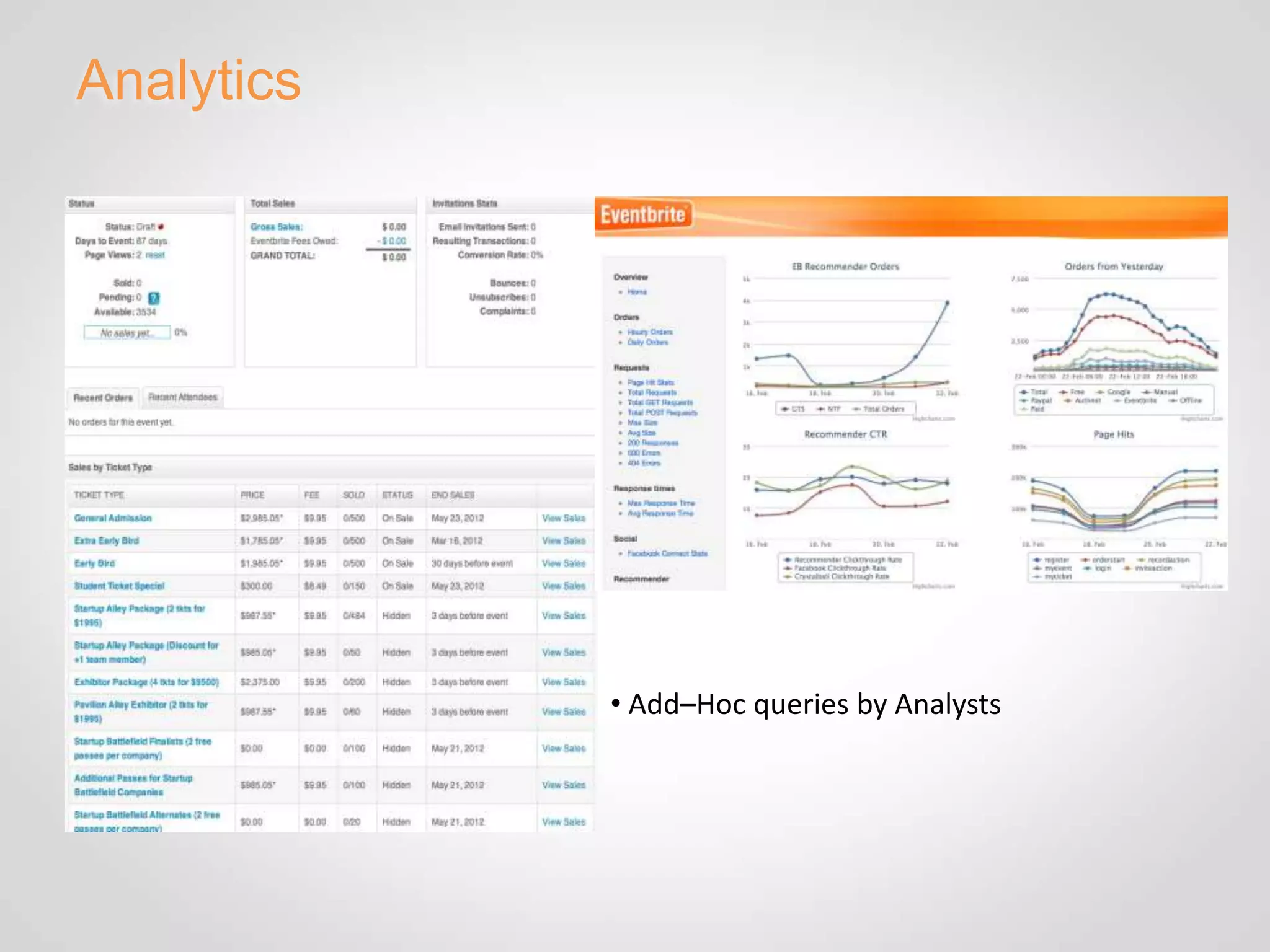
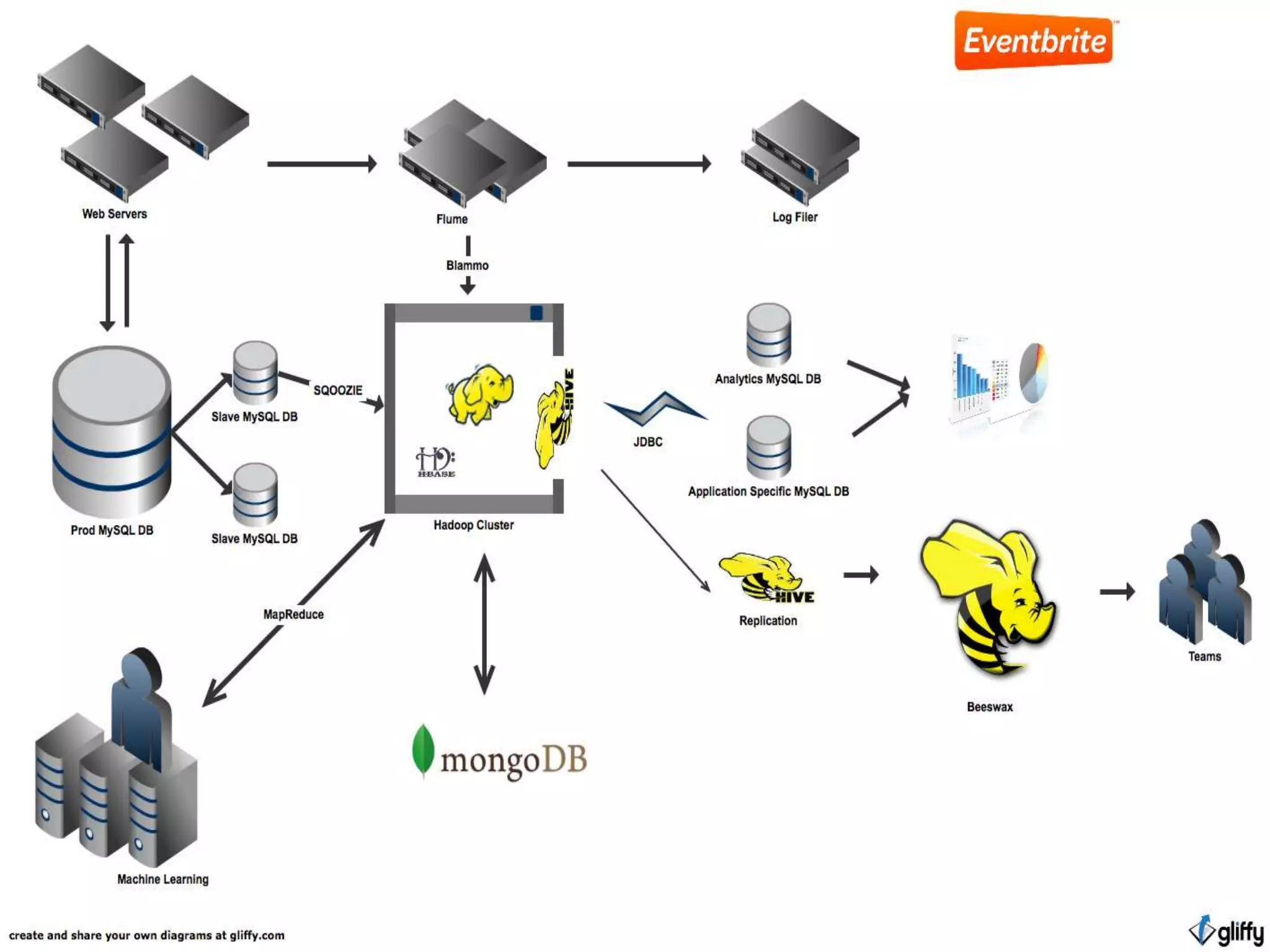
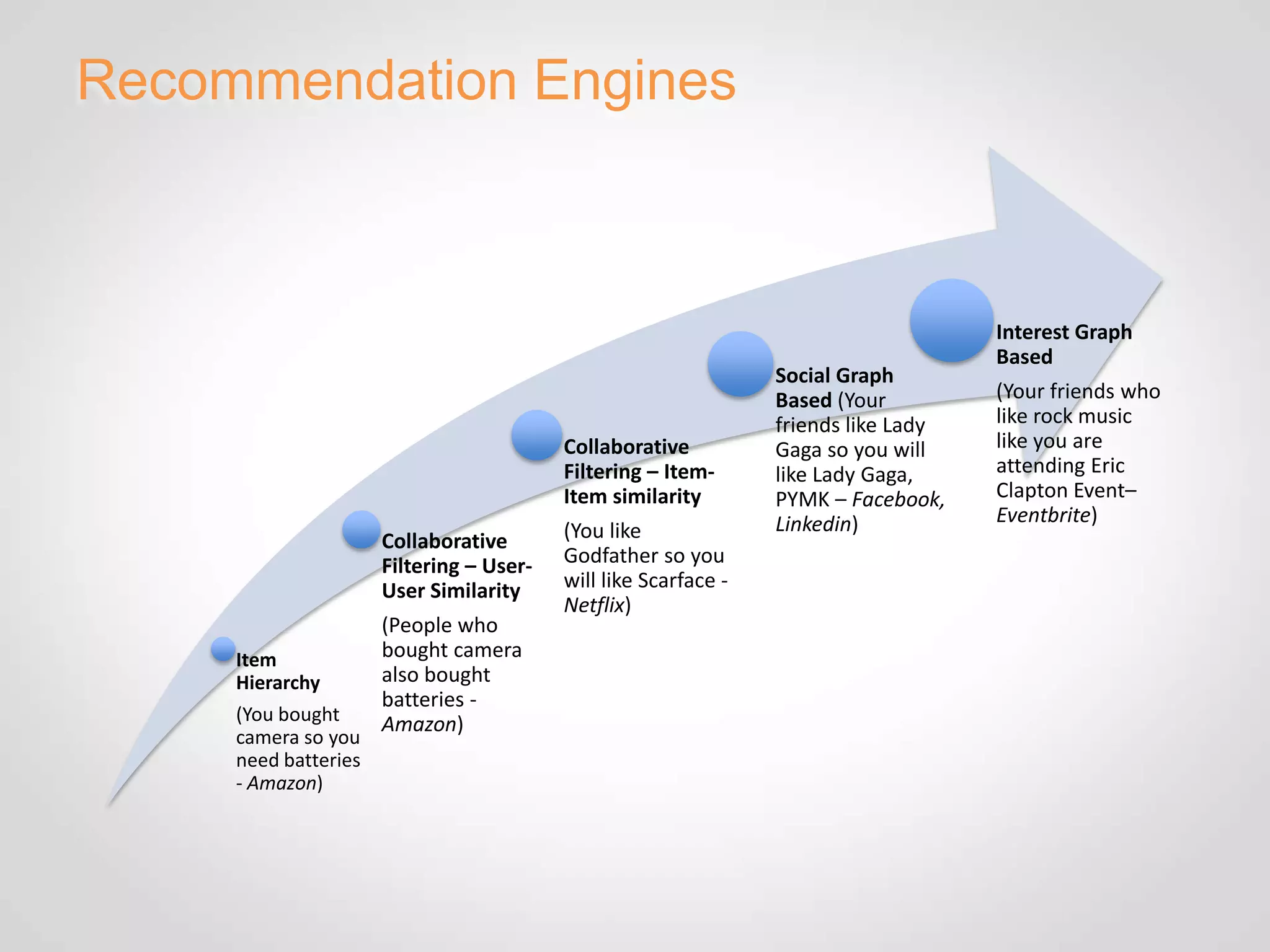
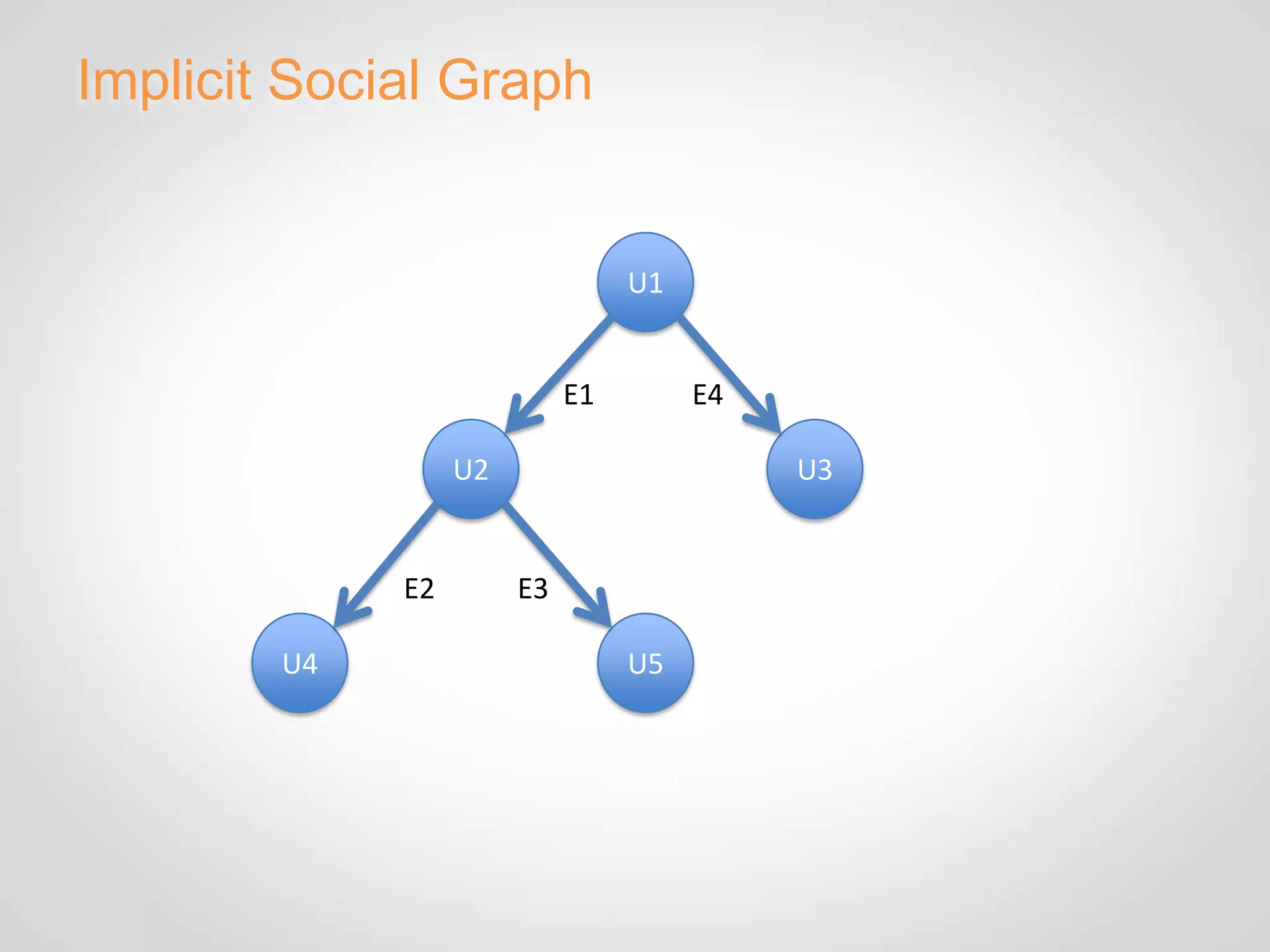
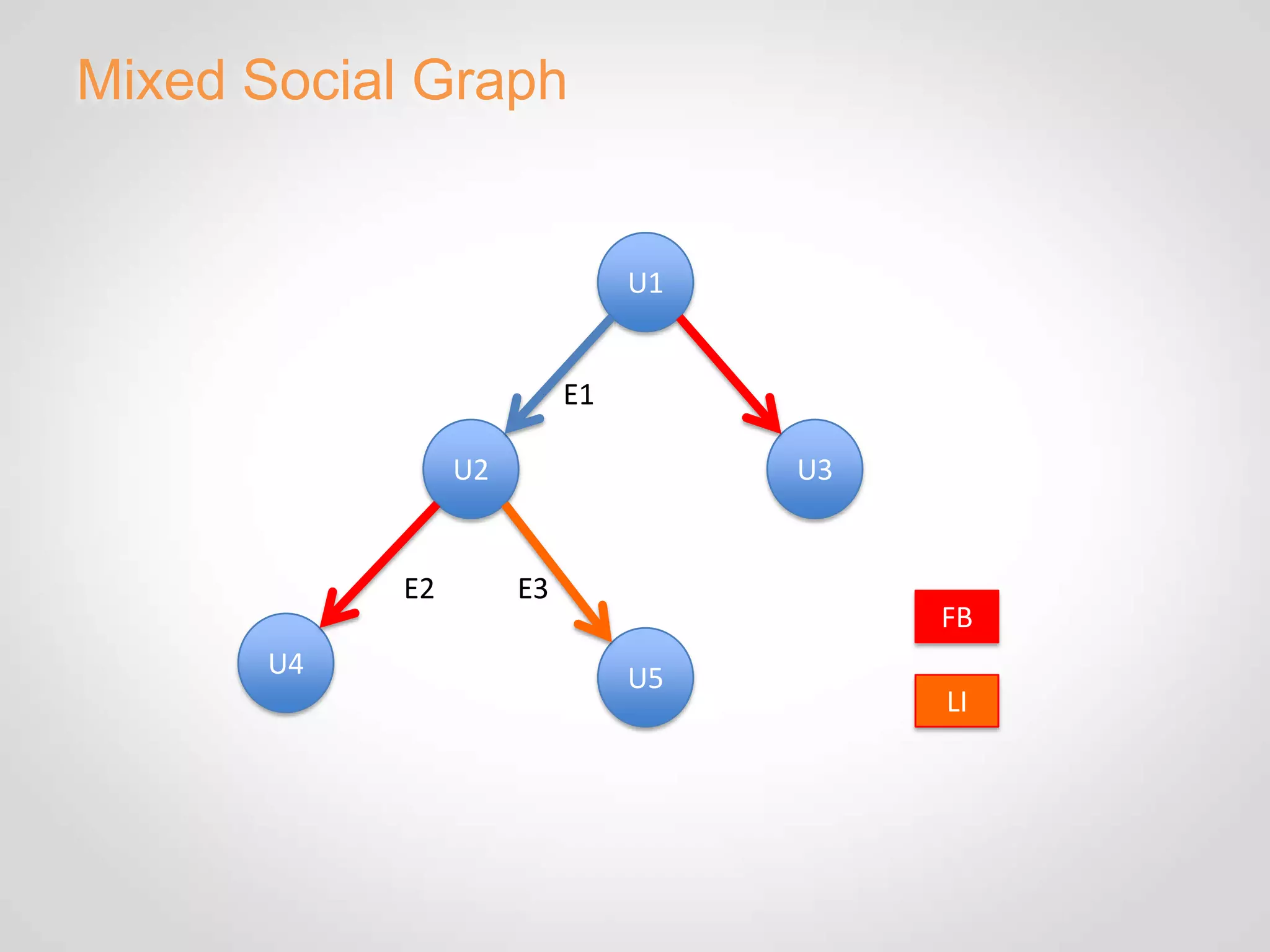
The document discusses Eventbrite's data platform and services. It describes Eventbrite as a social event ticketing platform that has doubled revenue yearly. It then summarizes Eventbrite's use of Hadoop, HBase, MongoDB and other technologies to power analytics, recommendations, and real-time data processing. Recommendation engines discussed include collaborative filtering, item hierarchies, and building implicit and mixed social graphs to connect users and events.

















![Feature Generation
• Mixed Features
• A series of map-reduce jobs
• Output on HDFS in flat files; Input to subsequent jobs
• Orders = Event Attendees
• MAP: eid: uid
• REDUCE: eid:[uid]
• Attendees Social Graph
• Input: eid:[uid]
• MAP: uidi:[uid]
• REDUCE: uid:[neighbors]
• Interest based features, user specific, graph mining etc
• Upload feature values to HBase](https://image.slidesharecdn.com/testtting1320-120328171405-phpapp02/75/Testtting-25-2048.jpg)













![挫折觉醒简报抢档抢先看5[1].20](https://cdn.slidesharecdn.com/ss_thumbnails/51-20-110527091831-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)












![挫折觉醒简报抢档抢先看5[1].20](https://cdn.slidesharecdn.com/ss_thumbnails/51-20-110527093519-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















