Downloaded 12 times



























![SELF_URI = URIRef('self:#')
def __getattr__(self, attr):
property_uri = attribute_uri(attr)
oo = list(self.attributes.objects(
self.SELF_URI,
property_uri))
if not oo:
raise AttributeError(attr)
if len(oo) == 1:
return oo[0].toPython()
return set([o.toPython() for o in oo])](https://image.slidesharecdn.com/tdd-111116085633-phpapp02/85/Test-driven-development-a-case-study-29-320.jpg)





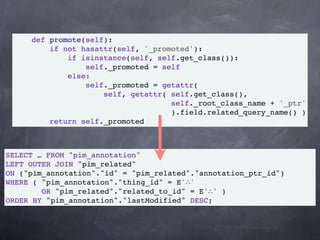
The document discusses the development of a semantic social collaboration platform utilizing technologies like Python/Django, PostgreSQL, and RDF-based APIs. It emphasizes the benefits of Test-Driven Development (TDD), promoting faster and cleaner code delivery, improved regression discovery, and easy refactoring. Additionally, it outlines a case study involving the use of RDF to manage data and annotations within the project.

































































