Downloaded 30 times










![14
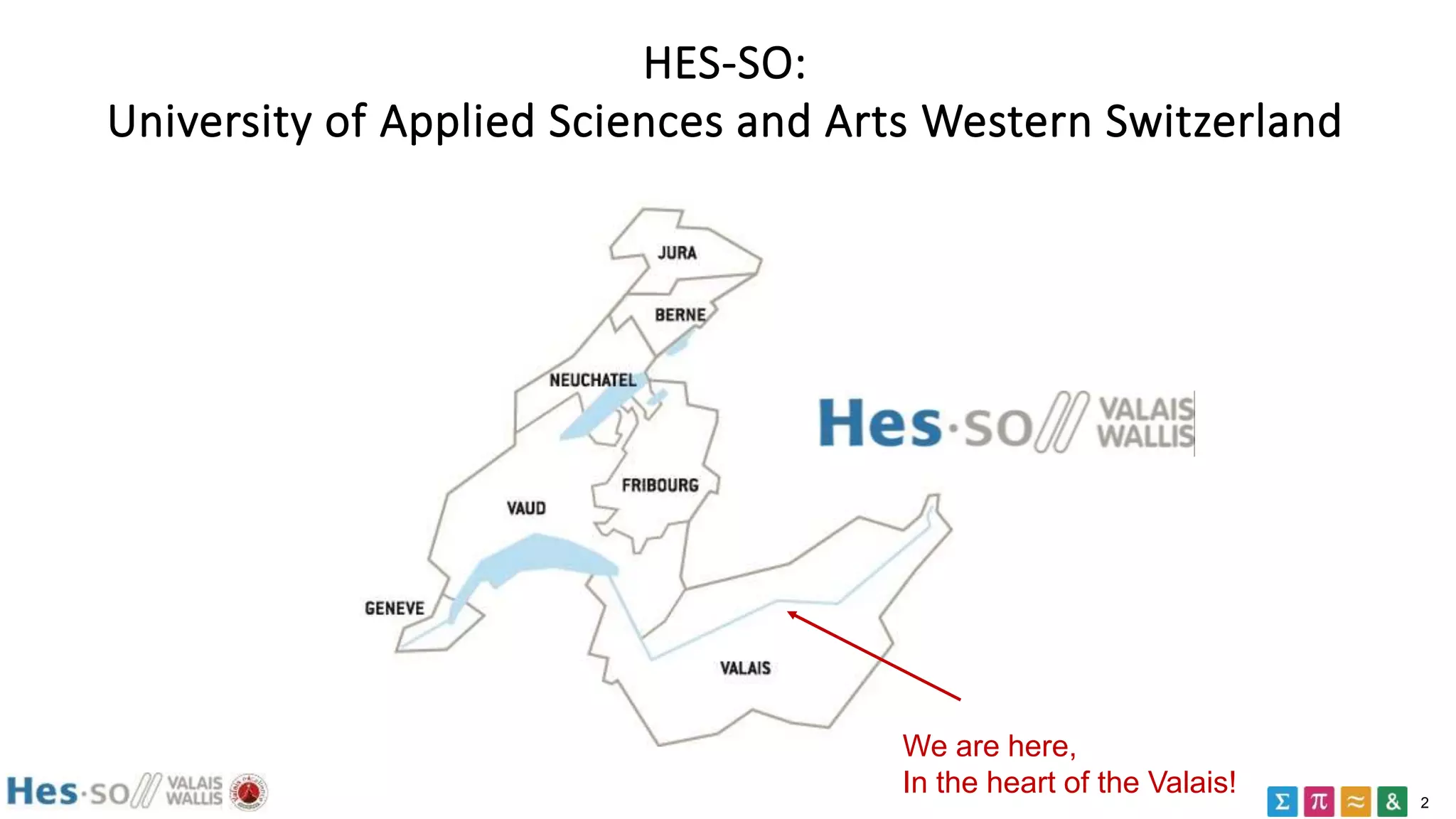
SHACL: an example
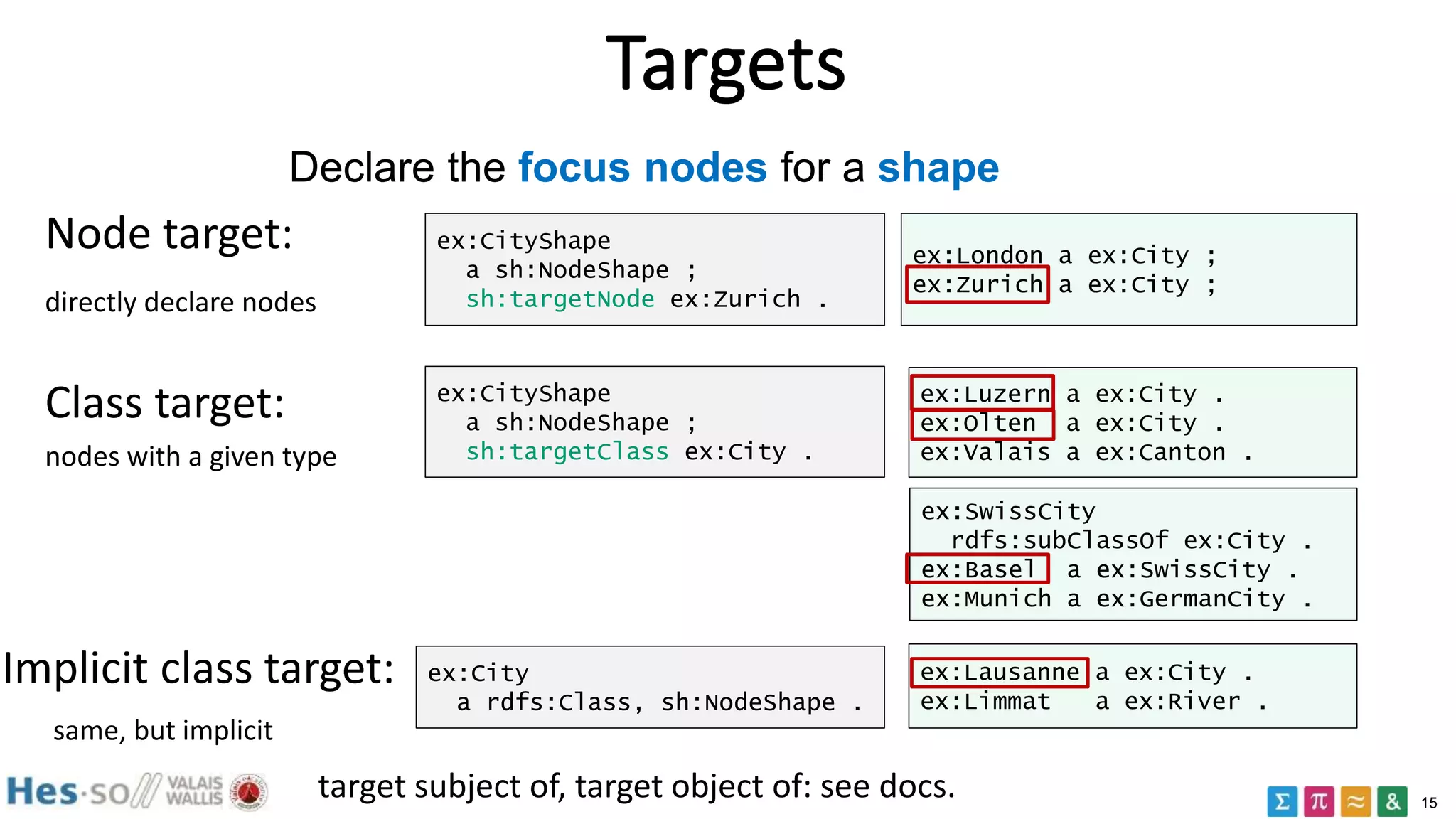
ex:CityShape
a sh:NodeShape ;
sh:targetClass ex:City ;
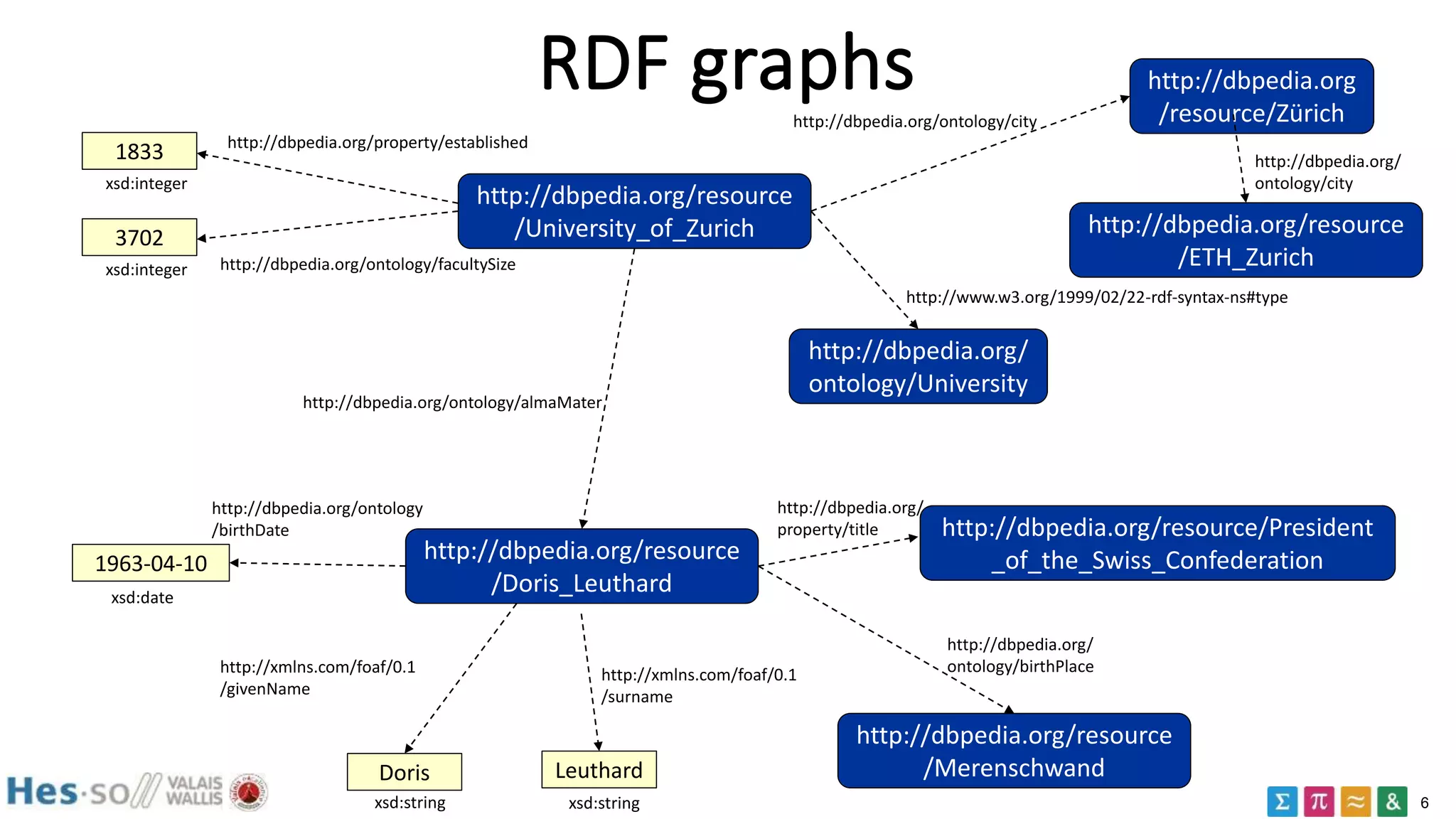
sh:property [
sh:path ex:population ;
sh:maxCount 1 ;
sh:datatype xsd:integer ;
] .
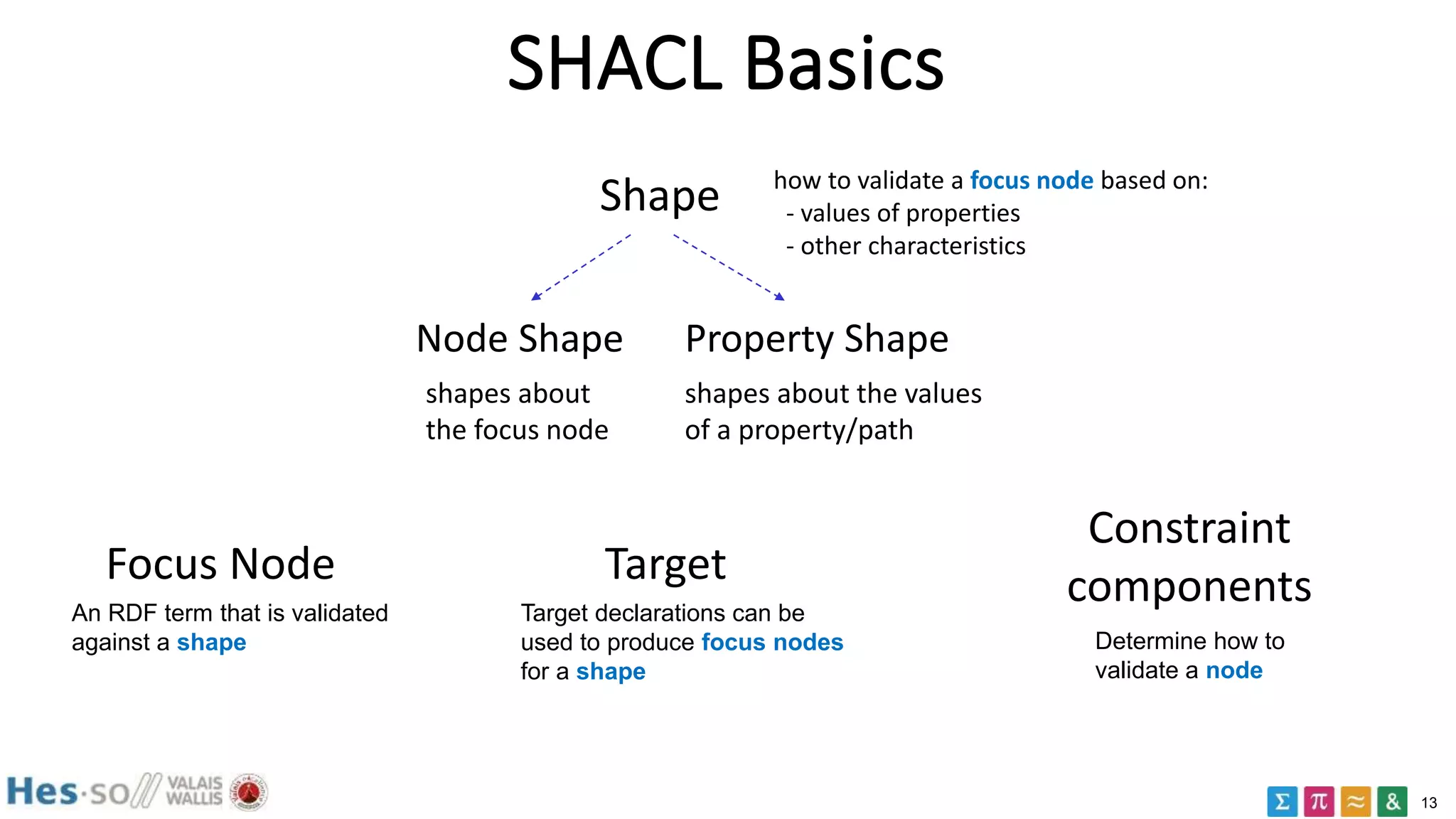
it is a node shape
applies to all cities
constraint the values
of ex:population
max 1 population
of type integer
e.g. "all cities have at
most one population
property of type
integer"
ex:London a ex:City ;
ex:population "two million" .
ex:Paris a ex:City ;
ex:population 2304 ;
ex:population 5342 ;](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-14-2048.jpg)

![17
Property Shapes
Constraints about a given property and its values for the focus node
- sh:property associates a shape with a property constraint
- sh:path identifies the path
:Student a sh:NodeShape ;
sh:property [
sh:path ex:email;
sh:nodeKind sh:IRI
] .
:anna a :Student ;
ex:email <mailto:anna@uzh.ch> .
:max a :Student ;
ex:email <mailto:max@uzh.ch> .
:greta a :Student ;
ex:email "greta@uzh.ch" .](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-17-2048.jpg)


![20
Value Type Constraints: Datatype
sh:datatype: condition to be satisfied for the datatype of each value node.
:University a sh:NodeShape ;
sh:property [
sh:path ex:established;
sh:datatype xsd:date ;
] .
:hes-so ex:established "1997-01-20"^^xsd:date .
:eth ex:established "Unknown"^^xsd:date .
:uzh ex:established 1990 .](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-20-2048.jpg)
![21
Value Type Constraints: Class
sh:class condition: each value node is a SHACL instance of a given type.
:Person
a sh:NodeShape, rdfs:Class ;
sh:property [
sh:path ex:almaMater ;
sh:class :University
] .
:unifr a :University .
:eth a :FederalSchool .
:unibe a :CantonalUniversity
:FederalSchool rdfs:subClassOf :University .
:anna a :Person;
ex:almaMater :unifr .
:max a :Person ;
ex:almaMater :eth .
:greta a :Person;
ex:almaMater :unibe .](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-21-2048.jpg)
![22
Value Type Constraints: Kind
sh:nodeKind: condition to be satisfied by the RDF node kind
:Student
a sh:NodeShape, rdfs:Class ;
sh:property [
sh:path ex:name ;
sh:nodeKind sh:Literal ;
];
sh:property [
sh:path ex:friendOf ;
sh:nodeKind sh:BlankNodeOrIRI
];
sh:nodeKind sh:IRI .
:anna a :Student;
ex:name _:1 ;
ex:friendOf :max .
:max a :Student;
ex:name "Max";
ex:friendOf [ex:name "Lucas"] .
:greta a :Student;
ex:name "Greta" ;
ex:friendOf "Lucas" .
_:1 a :Student.
BlankNode, IRI, Literal,
BlankNodeOrIRI, IRIOrLiteral
BlankNodeOrLiteral,
possible
kinds](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-22-2048.jpg)
![23
Cardinality constraints
sh:minCount: minimum number of value nodes that satisfy the condition
sh:maxCount: maximum number of value nodes that satisfy the condition.
:Student a sh:NodeShape ;
sh:property [
sh:path ex:hasCourse ;
sh:minCount 2 ;
sh:maxCount 3 ;
] .
:anna ex:hasCourse
:math, :physics .
:max ex:hasCourse
:chemistry .
:greta ex:hasCourse
:math, :physics,
:chemistry, :history .](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-23-2048.jpg)
![24
Value Range Constraints
Value range conditions for value nodes that are comparable via operators
such as <, <=, > and >=. sh:minInclusive, sh:maxInclusive,
sh:minExclusive, sh:maxExclusive
:Grade a sh:NodeShape ;
sh:property [
sh:path ex:gradeValue ;
sh:minInclusive 1 ;
sh:maxInclusive 5 ;
sh:datatype xsd:integer
] .
:failure ex:gradeValue 1 .
:sufficient ex:gradeValue 3 .
:excelent ex:gradeValue 5 .
:toobad ex:gradeValue 0 .](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-24-2048.jpg)

![26
minLength/maxLength
:Student a sh:NodeShape ;
sh:property [
sh:path ex:name ;
sh:minLength 4 ;
sh:maxLength 10 ;
] .
:anna ex:name "Anna" .
:max ex:name "Max" .
:greta ex:name :Greta .
:strange ex:name _:strange .
sh:minLength: minimum string length of each value node.
sh:maxLength: maximum string length of each value node.](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-26-2048.jpg)
![27
pattern
:Student a sh:NodeShape ;
sh:property [
sh:path ex:studentID ;
sh:pattern "^Pd{3,4}" ;
sh:flags "i" ;
] .
:anna ex:studentID "P2345" .
:max ex:studentID "p567" .
:greta ex:studentID "P12" .
:lara ex:studentID "B123" .
sh:pattern: regular expression that each value node matches.](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-27-2048.jpg)
![28
languageIn
ex:SwissLangShape a sh:NodeShape ;
sh:targetNode ex:Mountain, ex:Berg ;
sh:property [
sh:path ex:prefLabel ;
sh:languageIn ( "en" "fr" ) ;
] .
ex:Mountain
ex:prefLabel "Mountain"@en ;
ex:prefLabel "Hill"@en-UK ;
ex:prefLabel "Montagne"@fr .
ex:Berg
ex:prefLabel "Berg" ;
ex:prefLabel "Berg"@de ;
ex:prefLabel ex:BergLabel .
sh:languageIn: allowed language tags for each value node.](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-28-2048.jpg)
![29
uniqueLang
:Canton a sh:NodeShape ;
sh:property [
sh:path ex:name ;
sh:uniqueLang true
] .
:valais ex:name
"Valais"@fr, "Wallis"@de .
:fribourg ex:name
"Fribourg"@fr,
"Freiburg"@de,
"Friburgo"@es .
:zurich ex:name
"Zurich"@de, "Zuerich"@de.
sh:uniqueLang: no pair of value nodes may use the same language tag.](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-29-2048.jpg)

![31
equals
:Student a sh:NodeShape ;
sh:property [
sh:path ex:givenName ;
sh:equals ex:firstName
];
:anna ex:givenName "Anna";
ex:lastName "Parker";
ex:firstName "Anna" .
:max ex:givenName "Max";
ex:lastName "Sutter" ;
ex:firstName "Maximilian" .
:greta ex:givenName "Greta";
ex:lastName "Greta" ;
ex:firstName "Greta" .
sh:equals: all value nodes equal to the objects of the focus node](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-31-2048.jpg)
![32
disjoint
:Student a sh:NodeShape ;
sh:property [
sh:path ex:givenName ;
sh:disjoint ex:lastName
] .
:anna ex:givenName "Anna";
ex:lastName "Parker";
ex:firstName "Anna" .
:max ex:givenName "Max";
ex:lastName "Sutter" ;
ex:firstName "Maximilian" .
:greta ex:givenName "Greta";
ex:lastName "Greta" ;
ex:firstName "Greta" .
sh:disjoint: value nodes is disjoint with the objects of the focus node](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-32-2048.jpg)
![33
lessThan/lessThanOrEquals
ex:LessThanShape a sh:NodeShape ;
sh:property [
sh:path ex:startDate ;
sh:lessThan ex:endDate ;
] .
:project
ex:startDate "2017-01-02"^^xsd:date ;
ex:endDate "2015-01-02"^^xsd:date .](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-33-2048.jpg)

![35
not
ex:NotShape a sh:NodeShape ;
sh:targetNode :anna ;
sh:not [
a sh:PropertyShape ;
sh:path ex:established ;
sh:minCount 1 ;
] .
:anna ex:established "Some value" .
sh:not: Negation of a shape](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-35-2048.jpg)
![36
and
ex:Shape1 a sh:NodeShape ;
sh:property [
sh:path ex:courses ;
sh:minCount 1 ;
] .
ex:Shape2 a sh:NodeShape ;
sh:targetNode :anna, :max ;
sh:and (
ex:Shape1
[ sh:path ex:courses ;
sh:maxCount 1 ; ]
) .
:anna ex:courses "Math" .
:max ex:courses "Math" ;
ex:courses "Chemistry" .
sh:and: Conjunction of a list of shapes](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-36-2048.jpg)
![37
or
ex:OrShape a sh:NodeShape ;
sh:targetNode :anna, :max ;
sh:or (
[ sh:path ex:firstName ;
sh:minCount 1 ; ]
[ sh:path ex:givenName ;
sh:minCount 1 ; ]
) .
:anna ex:firstName "Anna" .
:max ex:givenName "Max" .
sh:or: Disjunction of a list of shapes](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-37-2048.jpg)
![38
or
ex:AddressShape a sh:NodeShape ;
sh:targetClass ex:Student ;
sh:property [
sh:path ex:address ;
sh:or (
[ sh:datatype xsd:string ; ]
[ sh:class ex:Address ; ]
)
] .
:anna
ex:address "12 Petit Rue, 1220,
Geneva" .
:max ex:address :maxAddress .
:maxAddress a ex:Address ;
ex:street "Grand Rue" ;
ex:zip 3960 ;
ex:locality ex:Sierre .
sh:or: Disjunction of a list of shapes](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-38-2048.jpg)
![39
xone
ex:XoneShape a sh:NodeShape ;
sh:targetClass ex:Person ;
sh:xone (
[ sh:property
[ sh:path ex:fullName ;
sh:minCount 1 ; ]
]
[ sh:property
[ sh:path ex:firstName ;
sh:minCount 1 ; ] ;
sh:property
[ sh:path ex:lastName ;
sh:minCount 1 ; ]
]
) .
ex:Bob a ex:Person ;
ex:firstName "Robert" ;
ex:lastName "Coin" .
ex:Carla a ex:Person ;
ex:fullName "Carla Miller" .
ex:Dory a ex:Person ;
ex:firstName "Dory" ;
ex:lastName "Dunce" ;
ex:fullName "Dory Dunce" .
sh:xone: conforms to exactly one of the provided shapes.](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-39-2048.jpg)

![41
node
ex:AddressShape a sh:NodeShape ;
sh:property [
sh:path ex:postalCode ;
sh:datatype xsd:string ;
sh:maxCount 1 ;
] .
ex:PersonShape a sh:NodeShape ;
sh:targetClass ex:Person ;
sh:property [
sh:path ex:address ;
sh:minCount 1 ;
sh:node ex:AddressShape ;
] .
ex:Bob a ex:Person ;
ex:address ex:BobsAddress .
ex:BobsAddress ex:postalCode "1234" .
ex:Reto a ex:Person ;
ex:address ex:RetosAddress .
ex:RetosAddress ex:postalCode 5678 .
sh:node: each value node conforms to the given node shape.](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-41-2048.jpg)
![42
property, qualifiedValueShape
ex:QualifiedShape a sh:NodeShape ;
sh:targetNode ex:anna, ex:max ;
sh:property [
sh:path ex:parent ;
sh:minCount 2 ;
sh:maxCount 2 ;
sh:qualifiedValueShape [
sh:path ex:gender ;
sh:hasValue ex:female ; ] ;
sh:qualifiedMinCount 1 ;
] .
ex:John ex:gender ex:male .
ex:Jane ex:gender ex:female .
ex:Tim ex:gender ex:male .
ex:anna
ex:parent ex:John ;
ex:parent ex:Jane .
ex:max
ex:parent ex:John ;
ex:parent ex:Tim .
sh:property: specify that each value node has a given property shape.](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-42-2048.jpg)
![43
Constraints on values: hasValue
sh:hasValue: at least one value node is equal to the given RDF term.
ex:ETHGraduate a sh:NodeShape ;
sh:targetNode :anna ;
sh:property [
sh:path ex:alumniOf ;
sh:hasValue ex:ETH ;
] .
:anna ex:alumniOf ex:EPFL ;
ex:alumniOf ex:ETH .](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-43-2048.jpg)
![44
Constraints on values: in
sh:in: each value node is a member of a provided SHACL list.
ex:InShape a sh:NodeShape ;
sh:targetClass ex:SkiSlope ;
sh:property [
sh:path ex:difficulty ;
sh:in ( ex:Black ex:Blue ex:Red ) ;
] .
ex:slope1 a ex:SkiSlope;
ex:difficulty ex:Pink .
ex:slope2 a ex:SkiSlope;
ex:difficulty ex:Red .](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-44-2048.jpg)
![45
Closed shapes
sh:closed Set to true to close the shape.
sh:ignoredProperties
Optional properties that are also permitted in addition to those
explicitly enumerated via sh:property.
ex:ClosedShape a sh:NodeShape ;
sh:targetNode ex:Alice, ex:Bob ;
sh:closed true ;
sh:ignoredProperties (rdf:type) ;
sh:property [ sh:path ex:firstName ; ] ;
sh:property [ sh:path ex:lastName ; ] .
ex:Alice ex:firstName "Alice" .
ex:Bob ex:firstName "Bob" ;
ex:middleInitial "J" .](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-45-2048.jpg)

![47
Non validating constraints
ex:PersonFormShape a sh:NodeShape ;
sh:property [
sh:path ex:firstName ;
sh:name "first name" ;
sh:description "The given name(s)" ;
sh:order 0 ;
sh:group ex:NameGroup ; ] ;
sh:property [
sh:path ex:lastName ;
sh:name "last name" ;
sh:description "The last name" ;
sh:order 1 ;
sh:group ex:NameGroup ; ] ;
Name
Address
sh:property [
sh:path ex:streetAddress ;
sh:name "street address" ;
sh:description "The street address" ;
sh:order 11 ;
sh:group ex:AddressGroup ; ] ;
sh:property [
sh:path ex:locality ;
sh:name "locality" ;
sh:description "The town or city " ;
sh:order 12 ;
sh:group ex:AddressGroup ; ] ;
sh:property [
sh:path ex:postalCode ;
sh:name "postal code" ;
sh:name "zip code"@en-US ;
sh:description "The postal code" ;
sh:order 13 ;
sh:group ex:AddressGroup ; ] .
ex:NameGroup a sh:PropertyGroup ;
sh:order 0 ;
rdfs:label "Name" .
ex:AddressGroup a sh:PropertyGroup ;
sh:order 1 ;
rdfs:label "Address" .](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-47-2048.jpg)

![49
SPARQL-based constraints
ex:LanguageShape a sh:NodeShape ;
sh:targetClass ex:Country ;
sh:sparql [
a sh:SPARQLConstraint ;
sh:message "Values are literals with German language tag." ;
sh:prefixes ex: ;
sh:select """ SELECT $this (ex:germanLabel AS ?path) ?value
WHERE {
$this ex:germanLabel ?value .
FILTER (!isLiteral(?value) ||
!langMatches(lang(?value), "de"))
} """ ;
] .
ex:country1 a ex:Country ;
ex:germanLabel "Spanien"@de .
ex:country2 a ex:Country ;
ex:germanLabel "Spain"@en .](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-49-2048.jpg)
![50
Shape Messages
ex:MyShape a sh:NodeShape ;
sh:targetNode ex:MyInstance ;
sh:property [
sh:path ex:myProperty ;
sh:minCount 1 ;
sh:datatype xsd:string ;
sh:severity sh:Warning ; ] ;
sh:property [
sh:path ex:myProperty ;
sh:maxLength 10 ;
sh:message "Too many characters"@en ;
sh:message "Zu viele Zeichen"@de ; ] ;
sh:deactivated true .](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-50-2048.jpg)
![51
ShEx
:User IRI {
schema:name xsd:string
}
:User a sh:NodeShape, rdfs:Class ;
sh:targetClass :Person ;
sh:nodeKind sh:IRI ;
sh:property [
sh:path schema:name ;
sh:datatype xsd:string
] .
Shape expressions: http://shex.io/
SHACL ShEx](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-51-2048.jpg)
![52
ShEx
:User {
schema:givenName xsd:string
schema:lastName xsd:string
}
:User a sh:NodeShape ;
sh:property [
sh:path schema:givenName ;
sh:datatype xsd:string ;
];
sh:property [
sh:path schema:lastName ;
sh:datatype xsd:string ;
] .
:alice schema:givenName "Alice" ;
schema:lastName "Cooper" .
:bob schema:givenName "Bob", "Robert" ;
schema:lastName "Smith", "Dylan" .
:carol schema:lastName "King" .
:dave schema:givenName 23;
schema:lastName :Unknown .](https://image.slidesharecdn.com/rdfdatavalidation2017-180613072935/75/RDF-data-validation-2017-SHACL-52-2048.jpg)



The document provides an overview of validation of RDF data using the SHACL (Shapes Constraint Language) recommendation. It begins with background on RDF and then discusses why validation of RDF data is important. It introduces key SHACL concepts like shapes, constraints, targets, and property shapes. Examples are provided to illustrate node shapes, value type constraints, cardinality constraints, logical constraints, and property pair constraints. The document serves as an introduction to validating RDF data using the SHACL language.




































































![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)












