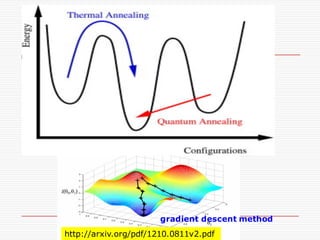
“Unfortunately, this turnsout to be very difficult.
Very very difficult. And given the tremendous
promise, there are lots of people working on”
--- Chris Olah
4.
"Validating correctness isa difficult enterprise
because the system is inherently stochastic and
only intended to behave in a certain way in
expectation — potentially after hours of
computation.”
--- TensorFlow White Paper
5.
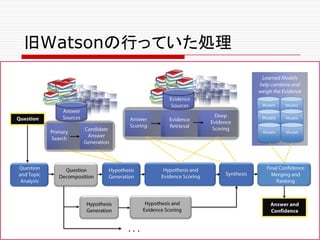
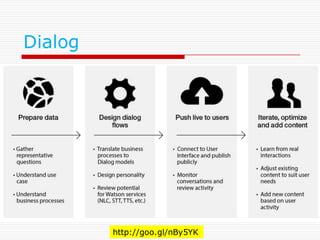
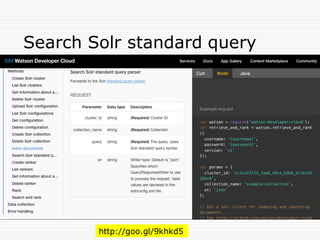
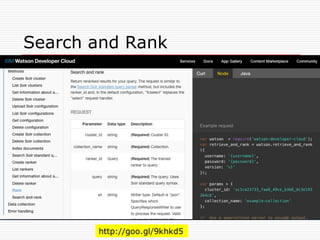
Agenda
o Watson API
nWatson vs. Watson
n Natural Language Classifier
n Dialog
n Cortana, Alexa との比較
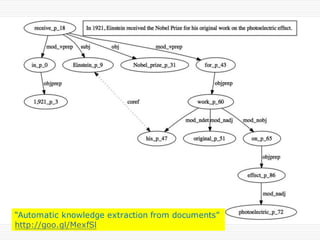
n Retrieve and Rank
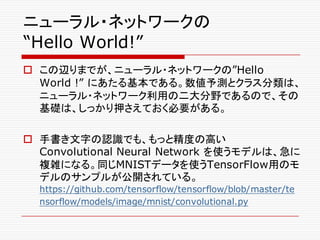
o Deep Learningでの自然言語へのアプローチ
n Deep Learning, NLP, and Representations
6.
Agenda
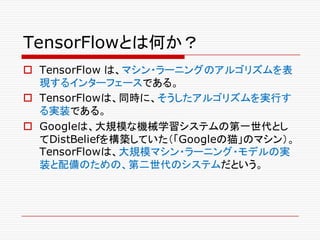
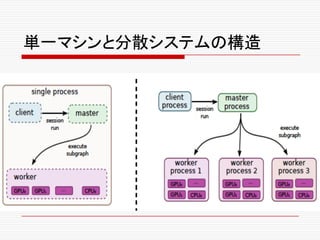
o Google TensolFlowの登場
nGoogle TensolFlowとは何か?
n TensorFlowのプログラミング・モデルと
基本的なコンセプト
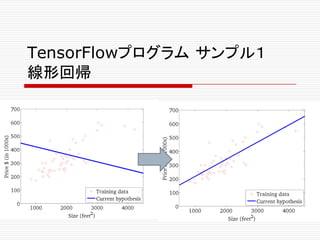
n TensorFlowプログラム サンプル1
線形回帰
n TensorFlowプログラム サンプル 2
手書き文字の認識
o TensolFlow White Paper (翻訳)
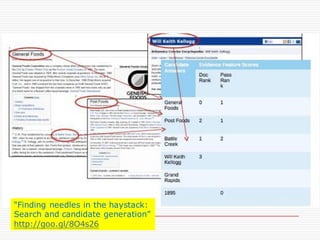
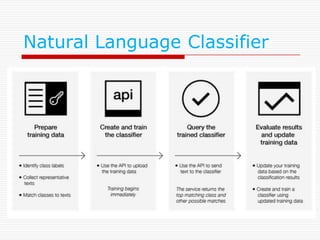
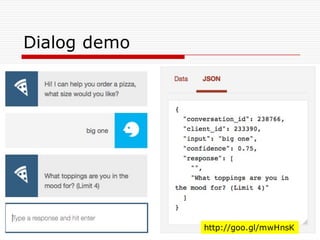
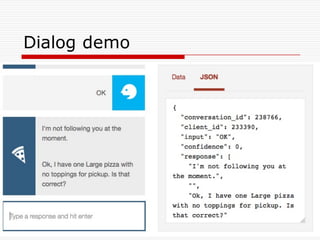
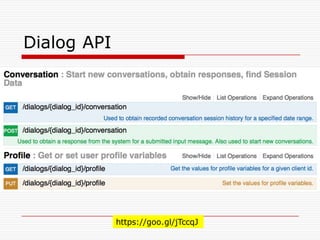
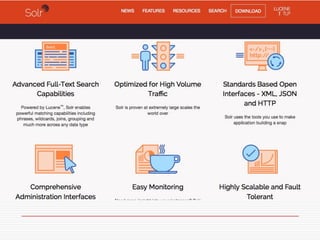
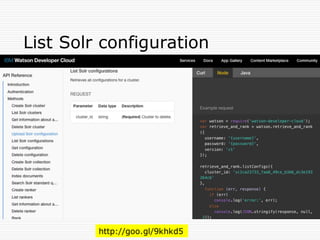
Natural Language Classifier
Demo
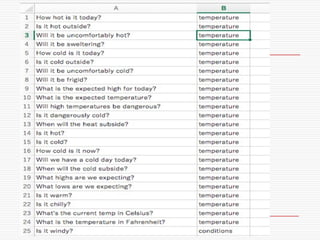
oIs it hot outside?
o Natural Language Classifier is 98% confident
that the question submitted is talking about
'temperature’.
Classification: temperature
Confidence: 98%
http://goo.gl/hGByud
24.
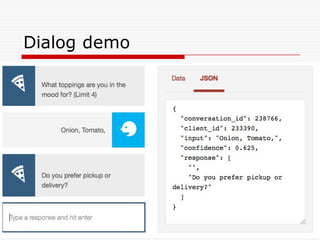
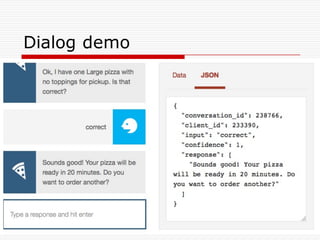
Natural Language Classifier
Demo
oWhat is the expected high for today?
o Natural Language Classifier is 98% confident
that the question submitted is talking about
'temperature’.
Classification: temperature
Confidence: 98%
http://goo.gl/hGByud
25.
Natural Language Classifier
Demo
oWill it be foggy tomorrow morning?
o Natural Language Classifier is 68% confident
that the question submitted is talking about
‘conditions’.
Classification: conditions
Confidence: 68%
http://goo.gl/hGByud
26.
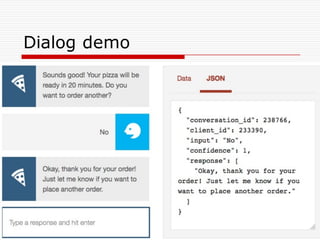
Natural Language Classifier
Demo
oWill it be foggy tomorrow morning?
o Natural Language Classifier is 68% confident
that the question submitted is talking about
‘conditions’.
Classification: conditions
Confidence: 68%
http://goo.gl/hGByud
27.
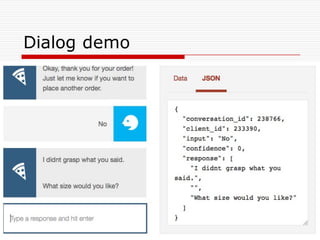
Natural Language Classifier
Demo
oWill it be foggy tomorrow morning?
o Natural Language Classifier is 68% confident
that the question submitted is talking about
‘conditions’.
Classification: conditions
Confidence: 68%
http://goo.gl/hGByud
28.
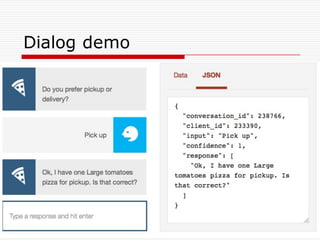
Natural Language Classifier
Demo
oShould I prepare for sleet?
o Natural Language Classifier is 91% confident
that the question submitted is talking about
‘conditions’.
Classification: conditions
Confidence: 91%
http://goo.gl/hGByud
29.
Natural Language Classifier
Demo
oWill there be a storm today?
o Natural Language Classifier is 98% confident
that the question submitted is talking about
‘conditions’.
Classification: conditions
Confidence: 98%
http://goo.gl/hGByud
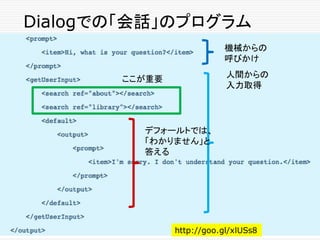
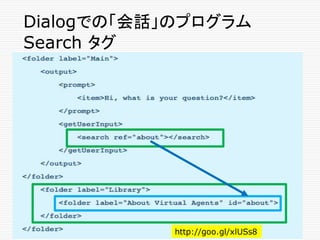
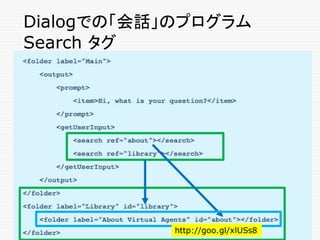
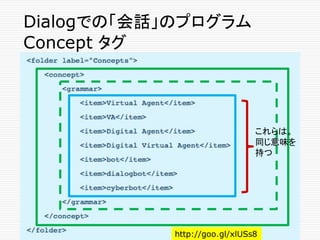
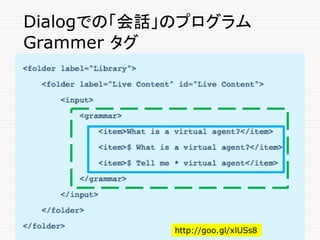
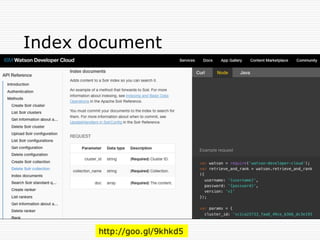
Grammerタグ内の Wild Card文字
Asterisk (*)
o “What is * dialog” は、次のものにマッチする
o "What is a dialog"
o "What is this thing called a dialog"
o “What is the meaning of a dialog”
o ...
56.
Grammerタグ内の Wild Card文字
Dollar sign ($)
o “$ is a dialog” は、次のものにマッチする。
o "So, can you tell me what is a dialog, please"
o "I've heard about virtual agents, but is a dialog
one of those"
o "Tell me, is a dialog something I can create"
o "Is a dialog something I can use for my
business”
o ...
57.
Grammerタグ内の Wild Card文字
Percent sign (%)
o “% is a dialog”は、次のものにマッチする。
o What is a dialog
o Can you tell me about a dialog
o What is it
o is
o a dialog
o ...
58.
Grammerタグ内の Wild Card文字
Hash sign (#)
o “# is dialog”は、次のものにマッチする。
o What is a Dialog
o Can you tell me what Dialog is
o Is this thing I'm looking at a Dialog
o What is Dialog
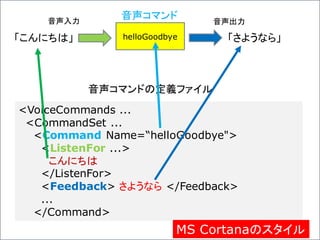
MS Cortana
Voice Commandの定義サンプル
<VoiceCommands
xmlns="http://schemas.microsoft.com/voicecommands/1.2">
<CommandSetxml:lang="en-us”
Name="AdventureWorksCommandSet_en-us">
<CommandPrefix> Adventure Works, </CommandPrefix>
<Example> Show trip to London </Example>
<Command Name="showTripToDestination">
<Example> Show trip to London </Example>
<ListenFor RequireAppName="BeforeOrAfterPhrase">
show [my] trip to {destination}
</ListenFor>
<ListenFor RequireAppName="ExplicitlySpecified">
show [my] {builtin:AppName} trip to {destination}
</ListenFor>
<Feedback> Showing trip to {destination} </Feedback>
<Navigate Target="foo"/>
</Command>
helloworld.speechAsset.
SampleUtterances.txt
HelloWorldIntent say hello
HelloWorldIntentsay hello world
HelloWorldIntent hello
HelloWorldIntent say hi
HelloWorldIntent say hi world
HelloWorldIntent hi
HelloWorldIntent how are you
HelpIntent help
HelpIntent help me
HelpIntent what can I ask you
HelpIntent get help
HelpIntent to help
HelpIntent to help me
intentName 発話
cortanaのListenFor
と同じ働きをする。それぞ
れの発話に、intent
Nameが付けられている。
“say hello”と“how are
you”は、同じintent
Nameが割り当てられて
いる。
“An example ofwhat recurrent neural nets
can now do” WikiPedia で学習したもの
o The meaning of life is the tradition of the
ancient human reproduction: it is less
favorable to the good boy for when to remove
her bigger. In the show’s agreement
unanimously resurfaced. The wild pasteured
with consistent street forests were
incorporated by the 15th century BE. In 1996
the primary rapford undergoes an effort that
the reserve conditioning, written into Jewish
cities, sleepers to incorporate the .St Eurasia
that activates the population.
http://goo.gl/vHRHSn
88.
“An example ofwhat recurrent neural nets
can now do” New York Timesで学習
o while he was giving attention to the second
advantage of school building a 2-for-2 stool
killed by the Cultures saddled with a halfsuit
defending the Bharatiya Fernall ’s office . Ms .
Claire Parters will also have a history temple
for him to raise jobs until naked Prodiena to
paint baseball partners , provided people to
ride both of Manhattan in 1978 , but what was
largely directed to China in 1946 , focusing on
the trademark period is the sailboat yesterday
and comments on whom they obtain overheard
within the 120th anniversary , where ......
http://goo.gl/vHRHSn
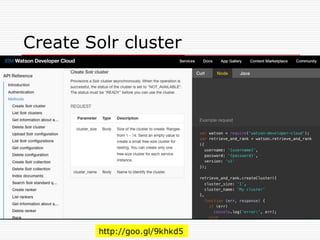
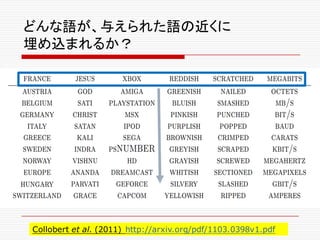
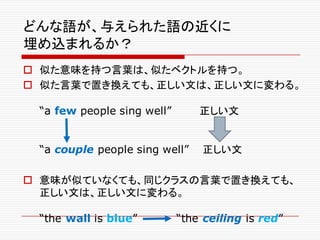
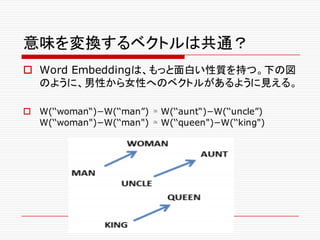
Word2Vecの登場
o 2013年に、GoogleのTomas Mikolovらは、語が埋め
込まれたベクター空間が、言語学的に(文法的にも、意味
論的にも)面白い性質を持っていることを発見する。
o“We find that these representations are
surprisingly good at capturing syntactic and
semantic regularities in language, and that
each relationship is characterized by a relation-
specific vector offset.” (Linguistic Regularities
in Continuous Space WordGoog
Representations
http://research.microsoft.com/pubs/189726/rvecs.pdf )
o Jeff Deanも、この論文に注目して、共同の作業が始まる。
TensorFlowのコードとグラフのサンプル
import tensorflow astf
b = tf.Variable(tf.zeros([100]))
W = tf.Variable(tf.random_uniform([784,100],-1,1))
x = tf.placeholder(name=“x”)
relu = tf.nn.relu(tf.matmul(W, x) + b)
C = [...]
s = tf.Session()
for step in xrange(0, 10):
input = ...construct 100-D input array ...
result = s.run(C, feed_dict={x: input})
print step, result
....
W = tf.Variable(tf.random_uniform([1],-1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
# Minimize the mean squared errors.
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
# Before starting, initialize the variables. We will 'run' this first.
init = tf.initialize_all_variables()
# Launch the graph.
sess = tf.Session()
sess.run(init)
# Fit the line.
for step in xrange(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(W), sess.run(b))
135.
....
W = tf.Variable(tf.random_uniform([1],-1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
# Minimize the mean squared errors.
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
# Before starting, initialize the variables. We will 'run' this first.
init = tf.initialize_all_variables()
# Launch the graph.
sess = tf.Session()
sess.run(init)
# Fit the line.
for step in xrange(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(W), sess.run(b))
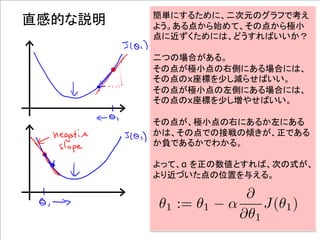
グラフの定義
アルゴリズム
グラフの起動
グラフで訓練
繰り返し
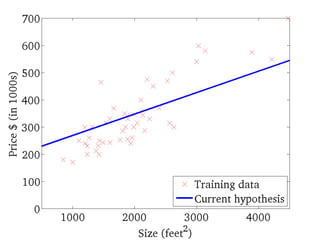
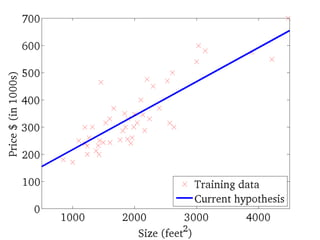
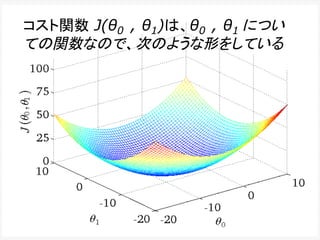
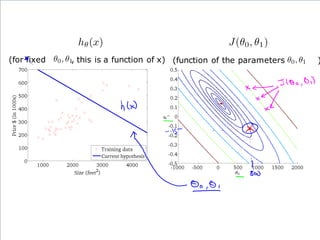
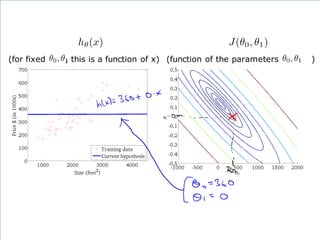
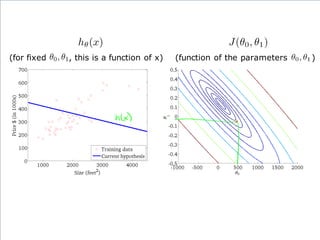
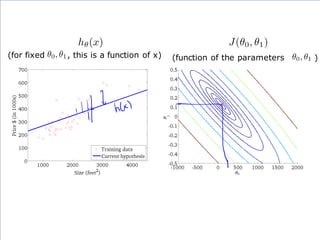
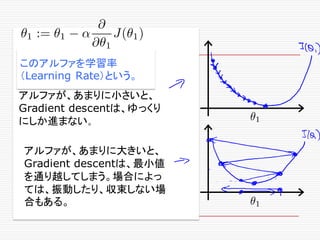
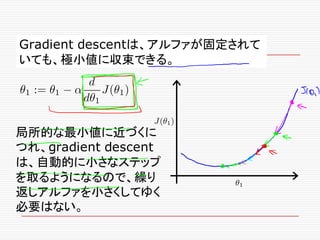
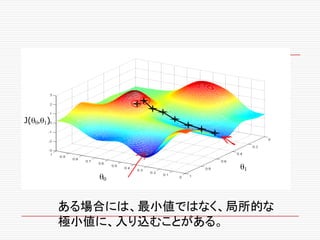
If α istoo small, gradient
descent can be slow.
If α is too large, gradient
descent can overshoot the
minimum. It may fail to
converge, or even diverge.
アルファが、あまりに小さいと、
Gradient descentは、ゆっくり
にしか進まない。
アルファが、あまりに大きいと、
Gradient descentは、最小値
を通り越してしまう。場合によっ
ては、振動したり、収束しない場
合もある。
このアルファを学習率
(Learning Rate)という。
....
W = tf.Variable(tf.random_uniform([1],-1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
# Minimize the mean squared errors.
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
# Before starting, initialize the variables. We will 'run' this first.
init = tf.initialize_all_variables()
# Launch the graph.
sess = tf.Session()
sess.run(init)
# Fit the line.
for step in xrange(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(W), sess.run(b))
....
# Create themodel
x = tf.placeholder("float", [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
# Define loss and optimizer
y_ = tf.placeholder("float", [None, 10])
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))
train_step = tf.train.GradientDescentOptimizer(0.01)¥
.minimize(cross_entropy)
# Train
tf.initialize_all_variables().run()
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
train_step.run({x: batch_xs, y_: batch_ys})
ソースの全体は、こちらにある。
https://goo.gl/MwscZO
166.
....
# Create themodel
x = tf.placeholder("float", [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
# Define loss and optimizer
y_ = tf.placeholder("float", [None, 10])
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))
train_step = tf.train.GradientDescentOptimizer(0.01)¥
.minimize(cross_entropy)
# Train
tf.initialize_all_variables().run()
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
train_step.run({x: batch_xs, y_: batch_ys})
グラフの定義
アルゴリズム
グラフで訓練
繰り返し
ソースの全体は、こちらにある。
https://goo.gl/MwscZO
167.
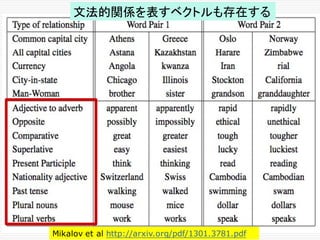
線形回帰とクラス分類との比較
変数の定義部分
W = tf.Variable(tf.random_uniform([1],-1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
実数が行列に変わっているだけで、ほとんど同じものだ。
mutmul(x, W)は、行列同士の掛け算である。
クラス分類の方に、softmaxがつくのは当然である。
線形回帰
クラス分類
TensorFlowのコードとグラフのサンプル
import tensorflow astf
b = tf.Variable(tf.zeros([100]))
W = tf.Variable(tf.random_uniform([784,100],-1,1))
x = tf.placeholder(name=“x”)
relu = tf.nn.relu(tf.matmul(W, x) + b)
C = [...]
s = tf.Session()
for step in xrange(0, 10):
input = ...construct 100-D input array ...
result = s.run(C, feed_dict={x: input})
print step, result
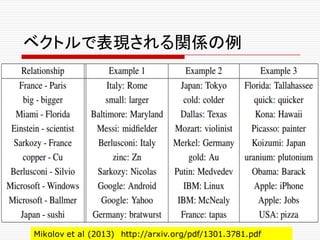
o [1] Mart´ınAbadi, Ashish Agarwal, Paul Barham, Eugene
Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado,
Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghe-
mawat, Ian Goodfellow, Andrew Harp, Geoffrey Irv- ing,
Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz
Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mane´,
Rajat Monga, Sherry Moore, Derek Murray, Chris Olah,
Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya
Sutskever, Kunal Talwar, Paul Tucker, Vincent
Vanhoucke, Vijay Vasudevan, Fernanda Vie´gas, Oriol
Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke,
Yuan Yu, and Xiaoqiang Zheng. TensorFlow: Large-scale
machine learning on heterogeneous systems, 2015.
Soft- ware available from tensorflow.org.
o [2] Anelia Angelova, Alex Krizhevsky, and Vincent Van-
houcke. Pedestrian detection with a large-field-of-view
deep network. In Robotics and Automation (ICRA), 2015
IEEE International Conference on, pages 704–711. IEEE,
2015. CalTech PDF.
325.
o [3] Arvindand David E. Culler. Annual review
of computer science vol. 1, 1986. chapter
Dataflow Architectures, pages 225–253. 1986.
www.dtic.mil/cgi-bin/GetTRDoc?Location=U2&
doc=GetTRDoc.pdf&AD=ADA166235.
o [4] Arvind and Rishiyur S. Nikhil. Executing a pro-
gram on the MIT tagged-token dataflow architec- ture.
IEEE Trans. Comput., 39(3):300–318, 1990.
dl.acm.org/citation.cfm?id=78583.
o [5] Jimmy Ba, Volodymyr Mnih, and Koray Kavukcuoglu.
Multiple object recognition with visual atten- tion.
arXiv preprint arXiv:1412.7755, 2014.
arxiv.org/abs/1412.7755.
o [6] Franc¸oise Beaufays. The
neural networks behind Google Voice
transcription, 2015.
googleresearch.blogspot.com/2015/08/the-neural-
networks-behind-google-voice.html.
326.
o [7] JamesBergstra, Olivier Breuleux, Fre´de´ric Bastien,
Pas- cal Lamblin, Razvan Pascanu, Guillaume Desjardins,
Joseph Turian, David Warde-Farley, and Yoshua Bengio.
Theano: A CPU and GPU math expression compiler. In
Proceedings of the Python for scientific computing con-
ference (SciPy), volume 4, page 3. Austin, TX, 2010.
UMontreal PDF.
o [8] Craig Chambers, Ashish Raniwala, Frances Perry,
Stephen Adams, Robert R Henry, Robert Bradshaw,
and Nathan Weizenbaum. FlumeJava: easy, effi-
cient data-parallel pipelines. In ACM Sigplan No- tices,
volume 45, pages 363–375. ACM, 2010. re-
search.google.com/pubs/archive/35650.pdf.
o [9] Sharan Chetlur, Cliff Woolley, Philippe Vandermer-
sch, Jonathan Cohen, John Tran, Bryan Catanzaro,
and Evan Shelhamer. cuDNN: Efficient primitives for
deep learning. arXiv preprint arXiv:1410.0759, 2014.
arxiv.org/abs/1410.0759.
327.
o [10] TrishulChilimbi, Yutaka Suzue, Johnson Apacible,
and Karthik Kalyanaraman. Project Adam: Building
an efficient and scalable deep learning training system.
In 11th USENIX Symposium on Operating Systems
Design and Implementation (OSDI 14), pages 571–582,
2014.
www.usenix.org/system/files/conference/osdi14/osdi14-
paper-chilimbi.pdf.
o [11] Jack Clark. Google turning its
lucrative web search over to AI
machines, 2015.
www.bloomberg.com/news/articles/2015-10-26/google-
turning-its-lucrative-web-search-over-to-ai-machines.
o [12] Cliff Click. Global code motion/global value number-
ing. In ACM SIGPLAN Notices, volume 30, pages 246–
257. ACM, 1995. courses.cs.washington.edu/courses/
cse501/06wi/reading/click-pldi95.pdf.
328.
o [13] RonanCollobert, Samy Bengio, and Johnny
Marie´thoz. Torch: A modular machine learning
software library. Technical report, IDIAP, 2002.
infoscience.epfl.ch/record/82802/files/rr02-46.pdf.
o [14] Jeffrey Dean, Gregory S. Corrado, Rajat Monga, Kai
Chen, Matthieu Devin, Quoc V. Le, Mark Z. Mao,
Marc’Aurelio Ranzato, Andrew Senior, Paul Tucker,
Ke Yang, and Andrew Y. Ng. Large scale distributed deep
networks. In NIPS, 2012. Google Research PDF.
o [15] Jack J Dongarra, Jeremy Du Croz, Sven Hammar-
ling, and Iain S Duff. A set of level 3 basic lin-
ear algebra subprograms. ACM Transactions on
Mathematical Software (TOMS), 16(1):1–17, 1990.
www.maths.manchester.ac.uk/˜sven/pubs/Level3BLAS-
1-TOMS16-90.pdf.
o [16] Andrea Frome, Greg S Corrado, Jonathon Shlens,
Samy Bengio, Jeff Dean, Tomas Mikolov, et al. DeVISE:
A deep visual-semantic embedding model. In
Advances in Neural Information Pro- cessing Systems,
pages 2121–2129, 2013. re-
search.google.com/pubs/archive/41473.pdf.
329.
o [17] JavierGonzalez-Dominguez, Ignacio Lopez-Moreno,
Pe- dro J Moreno, and Joaquin Gonzalez-Rodriguez.
Frame- by-frame language identification in short
utterances using deep neural networks. Neural Networks,
64:49–58, 2015.
o [18] Otavio Good. How Google Translate
squeezes deep learning onto a
phone, 2015.
googleresearch.blogspot.com/2015/07/how-google-
translate-squeezes-deep.html.
o [19] Ian J. Goodfellow, Yaroslav Bulatov, Julian Ibarz,
Sacha Arnoud, and Vinay Shet. Multi-digit number
recognition from Street View imagery using deep
convolutional neu- ral networks. In International
Conference on Learning Representations, 2014.
arxiv.org/pdf/1312.6082.
330.
o [20] GeorgHeigold, Vincent Vanhoucke, Alan Senior,
Patrick Nguyen, Marc’Aurelio Ranzato, Matthieu Devin,
and Jeffrey Dean. Multilingual acoustic models using dis-
tributed deep neural networks. In Acoustics, Speech
and Signal Processing (ICASSP), 2013 IEEE Interna-
tional Conference on, pages 8619–8623. IEEE, 2013. re-
search.google.com/pubs/archive/40807.pdf.
o [21] Geoffrey E. Hinton, Li Deng, Dong Yu, George E.
Dahl, Abdel-rahman Mohamed, Navdeep Jaitly, An- drew
Senior, Vincent Vanhoucke, Patrick Nguyen, Tara N.
Sainath, and Brian Kingsbury. Deep neural
networks for acoustic modeling in speech recognition:
The shared views of four research groups. IEEE
Signal Process. Mag., 29(6):82– 97, 2012.
www.cs.toronto.edu/˜gdahl/papers/
deepSpeechReviewSPM2012.pdf.
o [22] Sepp Hochreiter and Ju¨rgen Schmidhuber. Long
short- term memory. Neural computation, 9(8):1735–
1780, 1997. ftp.idsia.ch/pub/juergen/lstm.pdf.
331.
o [23] SergeyIoffe and Christian Szegedy. Batch
normaliza- tion: Accelerating deep network training by
reducing internal covariate shift. CoRR, abs/1502.03167,
2015. arxiv.org/abs/1502.03167.
o [24] Michael Isard, Mihai Budiu, Yuan Yu, Andrew
Birrell, and Dennis Fetterly. Dryad: distributed data-
parallel programs from sequential building blocks. In
ACM SIGOPS Operating Systems Review, volume 41,
pages 59–72. ACM, 2007.
www.michaelisard.com/pubs/eurosys07.pdf.
o [25] Benoˆıt Jacob, Gae¨l Guennebaud, et al. Eigen
library for linear algebra. eigen.tuxfamily.org.
o [26] Yangqing Jia, Evan Shelhamer, Jeff Donahue,
Sergey Karayev, Jonathan Long, Ross Girshick, Sergio
Guadar- rama, and Trevor Darrell. Caffe: Convolutional
archi- tecture for fast feature embedding. In
Proceedings of the ACM International Conference on
Multimedia, pages 675–678. ACM, 2014.
arxiv.org/pdf/1408.5093.
332.
o [27] AndrejKarpathy, George Toderici, Sachin Shetty,
Tommy Leung, Rahul Sukthankar, and Li Fei- Fei.
Large-scale video classification with con- volutional
neural networks. In Computer Vision and Pattern
Recognition (CVPR), 2014 IEEE Con- ference on, pages
1725–1732. IEEE, 2014. re-
search.google.com/pubs/archive/42455.pdf.
o [28] A Krizhevsky. Cuda-convnet, 2014.
code.google.com/p/cuda-convnet/.
o [29] Alex Krizhevsky. One weird trick for paralleliz-
ing convolutional neural networks. arXiv preprint
arXiv:1404.5997, 2014. arxiv.org/abs/1404.5997.
o [30] Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton.
The CIFAR-10 dataset.
www.cs.toronto.edu/˜kriz/cifar.html.
o [31] Quoc Le, Marc’Aurelio Ranzato, Rajat Monga,
Matthieu Devin, Greg Corrado, Kai Chen, Jeff Dean, and
Andrew Ng. Building high-level features using large scale
unsu- pervised learning. In ICML’2012, 2012. Google
Research PDF
333.
o [32] YannLeCun, Corinna Cortes, and Christopher JC
Burges. The MNIST database of handwritten digits, 1998.
yann.lecun.com/exdb/mnist/.
o [33] Mu Li, Dave Andersen, and Alex Smola. Parameter
server. parameterserver.org.
o [34] Chris J Maddison, Aja Huang, Ilya Sutskever, and
David Silver. Move evaluation in Go using deep
convolutional neural networks. arXiv preprint
arXiv:1412.6564, 2014. arxiv.org/abs/1412.6564.
o [35] Tomas Mikolov, Kai Chen, Greg Corrado, and
Jef- frey Dean. Efficient estimation of word representa-
tions in vector space. In International Conference
on Learning Representations: Workshops Track, 2013.
arxiv.org/abs/1301.3781.
o [36] Derek G Murray, Frank McSherry, Rebecca Isaacs,
Michael Isard, Paul Barham, and Mart´ın Abadi. Naiad:
a timely dataflow system. In Proceedings of the Twenty-
Fourth ACM Symposium on Operating Systems Princi-
ples, pages 439–455. ACM, 2013. Microsoft Research
PDF.
334.
o [37] DerekG. Murray, Malte Schwarzkopf, Christopher
Smowton, Steven Smit, Anil Madhavapeddy, and Steven
Hand. Ciel: a universal execution engine for dis-
tributed data-flow computing. In Proceedings of the
Ninth USENIX Symposium on Networked Systems Design
and Implementation, 2011. Usenix PDF.
o [38] Arun Nair, Praveen Srinivasan, Sam Blackwell,
Cagdas Alcicek, Rory Fearon, Alessandro De Maria, Ve-
davyas Panneershelvam, Mustafa Suleyman, Charles
Beattie, Stig Petersen, et al. Massively parallel meth-
ods for deep reinforcement learning. arXiv preprint
arXiv:1507.04296, 2015. arxiv.org/abs/1507.04296.
o [39] CUDA Nvidia. Cublas library. NVIDIA Corpo-
ration, Santa Clara, California, 15, 2008. devel-
oper.nvidia.com/cublas.
335.
o [40] JonathanRagan-Kelley, Connelly Barnes, Andrew
Adams, Sylvain Paris, Fre´do Durand, and Saman Ama-
rasinghe. Halide: A language and compiler for optimiz-
ing parallelism, locality, and recomputation in image pro-
cessing pipelines. ACM SIGPLAN Notices, 48(6):519–
530, 2013. people.csail.mit.edu/fredo/tmp/Halide-
5min.pdf.
o [41] Bharath Ramsundar, Steven Kearnes, Patrick Riley,
Dale Webster, David Konerding, and Vijay Pande.
Massively multitask networks for drug discovery. arXiv
preprint arXiv:1502.02072, 2015.
arxiv.org/abs/1502.02072.
o [43] Chuck Rosenberg. Improving Photo
Search: A step across the semantic gap, 2013.
googleresearch.blogspot.com/2013/06/improving-photo-
search-step-across.html.
336.
o [44] ChristopherJ Rossbach, Yuan Yu, Jon Currey, Jean-
Philippe Martin, and Dennis Fetterly. Dandelion: a
compiler and runtime for heterogeneous systems. In
Proceedings of the Twenty-Fourth ACM Symposium
on Operating Systems Principles, pages 49–68. ACM,
2013. research-srv.microsoft.com/pubs/201110/sosp13-
dandelion-final.pdf.
o [45] David E Rumelhart, Geoffrey E Hinton, and Ronald J
Williams. Learning representations by back-
propagating errors. Cognitive modeling, 5:3, 1988.
www.cs.toronto.edu/ hinton/absps/naturebp.pdf.
o [46] Has¸im Sak, Andrew Senior,Kanishka
Rao, Franc¸oise Beaufays, and Johan
Schalkwyk. Google Voice Search:
faster and more accurate, 2015.
googleresearch.blogspot.com/2015/09/google-voice-
search-faster-and-more.html.
337.
o [47] IlyaSutskever, Oriol Vinyals, and Quoc V. Le.
Sequence to sequence learning with neural networks. In
NIPS, 2014. papers.nips.cc/paper/5346-sequence-to-
sequence- learning-with-neural.
o [48] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre
Ser- manet, Scott Reed, Dragomir Anguelov, Dumitru
Er- han, Vincent Vanhoucke, and Andrew Rabinovich.
Go- ing deeper with convolutions. In CVPR’2015, 2015.
arxiv.org/abs/1409.4842.
o [49] Seiya Tokui. Chainer: A powerful, flexible and
intuitive framework of neural networks. chainer.org.
o [50] Vincent Vanhoucke. Speech recognition and deep
learn- ing, 2015.
googleresearch.blogspot.com/2012/08/speech-
recognition-and-deep-learning.html.
338.
o [51] AbhishekVerma, Luis Pedrosa, Madhukar Korupolu,
David Oppenheimer, Eric Tune, and John Wilkes. Large-
scale cluster management at Google with Borg. In
Proceedings of the Tenth European Conference on
Computer Systems, page 18. ACM, 2015. re-
search.google.com/pubs/archive/43438.pdf.
o [52] O. Vinyals, L. Kaiser, T. Koo, S. Petrov, I. Sutskever,
and G. Hinton. Grammar as a foreign language.
Technical report, arXiv:1412.7449, 2014.
arxiv.org/abs/1412.7449.
o [53] Oriol Vinyals, Meire Fortunato, and Navdeep
Jaitly. Pointer networks. In NIPS, 2015.
arxiv.org/abs/1506.03134.
o [54] Dong Yu, Adam Eversole, Mike Seltzer, Kaisheng
Yao, Zhiheng Huang, Brian Guenter, Oleksii Kuchaiev, Yu
Zhang, Frank Seide, Huaming Wang, et al. An
introduction to computational networks and the com-
putational network toolkit. Technical report, Tech. Rep.
MSR, Microsoft Research, 2014, 2014. re-
search.microsoft.com/apps/pubs/?id=226641.
339.
o [55] MateiZaharia, Mosharaf Chowdhury, Tathagata Das,
Ankur Dave, Justin Ma, Murphy McCauley, Michael J
Franklin, Scott Shenker, and Ion Stoica. Resilient
distributed datasets: A fault-tolerant abstraction for in-
memory cluster computing. In Proceedings of the 9th
USENIX conference on Networked Systems De- sign
and Implementation. USENIX Association, 2012.
www.usenix.org/system/files/conference/nsdi12/nsdi12-
final138.pdf.
o [56] Matthew D. Zeiler, Marc’Aurelio Ranzato, Rajat
Monga, Mark Mao, Ke Yang, Quoc Le, Patrick Nguyen,
Andrew Senior, Vincent Vanhoucke, Jeff Dean, and
Geoffrey E. Hinton. On rectified linear units
for speech processing. In ICASSP, 2013. re-
search.google.com/pubs/archive/40811.pdf.



































![MS Cortana
Voice Commandの定義サンプル
<VoiceCommands
xmlns="http://schemas.microsoft.com/voicecommands/1.2">
<CommandSet xml:lang="en-us”
Name="AdventureWorksCommandSet_en-us">
<CommandPrefix> Adventure Works, </CommandPrefix>
<Example> Show trip to London </Example>
<Command Name="showTripToDestination">
<Example> Show trip to London </Example>
<ListenFor RequireAppName="BeforeOrAfterPhrase">
show [my] trip to {destination}
</ListenFor>
<ListenFor RequireAppName="ExplicitlySpecified">
show [my] {builtin:AppName} trip to {destination}
</ListenFor>
<Feedback> Showing trip to {destination} </Feedback>
<Navigate Target="foo"/>
</Command>](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-62-320.jpg)


















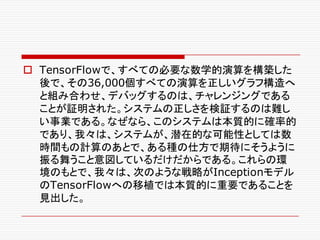
![画像認識と言語モデルの複雑さの比較
o 「ディープ・ニューラル・ネットワークの計算グラフは、きわ
めて複雑なものになりうる。例えば、Googleの
Inceptionモデル[48]に似た訓練用の計算グラフは、
ディープ・コンボリューション・ニューラル・ネットワークで、
2014年のコンテストで最高の分類パフォーマンスを示し
たのだが、TensorFlowの計算グラフでは、36,000個以
上のノードを持っている。そして、言語モデルのための
ディープ・リカレントLSTMモデルは、15,000以上のノード
を持っている。」
“TensorFlow Whitepaper” 第9節から](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-89-320.jpg)














![TensorFlowのコードとグラフのサンプル
import tensorflow as tf
b = tf.Variable(tf.zeros([100]))
W = tf.Variable(tf.random_uniform([784,100],-1,1))
x = tf.placeholder(name=“x”)
relu = tf.nn.relu(tf.matmul(W, x) + b)
C = [...]
s = tf.Session()
for step in xrange(0, 10):
input = ...construct 100-D input array ...
result = s.run(C, feed_dict={x: input})
print step, result](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-123-320.jpg)








![....
W = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
# Minimize the mean squared errors.
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
# Before starting, initialize the variables. We will 'run' this first.
init = tf.initialize_all_variables()
# Launch the graph.
sess = tf.Session()
sess.run(init)
# Fit the line.
for step in xrange(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(W), sess.run(b))](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-134-320.jpg)
![....
W = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
# Minimize the mean squared errors.
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
# Before starting, initialize the variables. We will 'run' this first.
init = tf.initialize_all_variables()
# Launch the graph.
sess = tf.Session()
sess.run(init)
# Fit the line.
for step in xrange(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(W), sess.run(b))
グラフの定義
アルゴリズム
グラフの起動
グラフで訓練
繰り返し](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-135-320.jpg)




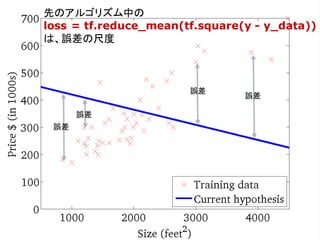
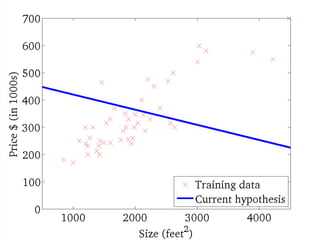
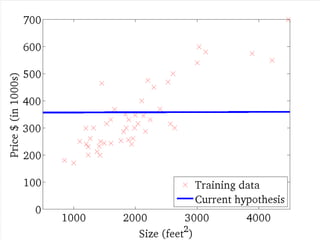
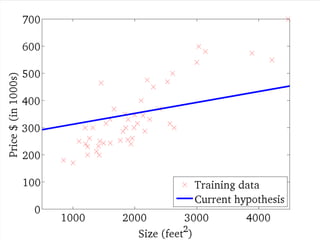





![....
W = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
# Minimize the mean squared errors.
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
# Before starting, initialize the variables. We will 'run' this first.
init = tf.initialize_all_variables()
# Launch the graph.
sess = tf.Session()
sess.run(init)
# Fit the line.
for step in xrange(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(W), sess.run(b))](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-163-320.jpg)
![....
# Create the model
x = tf.placeholder("float", [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
# Define loss and optimizer
y_ = tf.placeholder("float", [None, 10])
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))
train_step = tf.train.GradientDescentOptimizer(0.01)¥
.minimize(cross_entropy)
# Train
tf.initialize_all_variables().run()
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
train_step.run({x: batch_xs, y_: batch_ys})
ソースの全体は、こちらにある。
https://goo.gl/MwscZO](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-165-320.jpg)
![....
# Create the model
x = tf.placeholder("float", [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
# Define loss and optimizer
y_ = tf.placeholder("float", [None, 10])
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))
train_step = tf.train.GradientDescentOptimizer(0.01)¥
.minimize(cross_entropy)
# Train
tf.initialize_all_variables().run()
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
train_step.run({x: batch_xs, y_: batch_ys})
グラフの定義
アルゴリズム
グラフで訓練
繰り返し
ソースの全体は、こちらにある。
https://goo.gl/MwscZO](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-166-320.jpg)
![線形回帰とクラス分類との比較
変数の定義部分
W = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
実数が行列に変わっているだけで、ほとんど同じものだ。
mutmul(x, W)は、行列同士の掛け算である。
クラス分類の方に、softmaxがつくのは当然である。
線形回帰
クラス分類](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-167-320.jpg)




![o TensorFlow [1] は、マシン・ラーニングのアルゴリズム
を表現するインターフェースであり、同時に、そうしたアル
ゴリズムを実行する実装である。TensorFlowを用いて表
現される計算は、携帯電話やタブレットといったモバイル・
デバイスから、数百のマシンと数千のGPUカードのような
計算デバイスを持つ大規模分散システムにいたる、広い
範囲の多様なヘテロなシステムで、ほとんど、あるいは、
全く変更なしで実行することができる。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-173-320.jpg)



![o Google Brain プロジェクトは、研究とGoogle製品での
利用の両面で、非常に大規模なディープ・ニューラル・ネッ
トワークの利用を開拓するために、2011年に開始された。
このプロジェクトの初期の仕事の一部として、我々は、ス
ケーラブルな分散訓練推論システム[14]の第一世代とし
てDistBeliefを構築した。そして、このシステムは、我々
に非常に役立った。 我々とGoogleの他のメンバーは、
DistBeliefを使って、広い範囲の多様な研究を遂行して
きた。これらには、次の仕事が含まれる。教師なし学習
[31], 言語の表現 [35, 52], イメージ分類と対象検出
のモデル [16, 48], ビデオの分類 [27], 音声認識
[56, 21, 20],シーケンスの予測 [47], 碁の指し手の
選択 [34], 歩行者の検出 [2], 強化学習 [38], そして、
その他の領域 [17, 5]。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-178-320.jpg)
![o それに加えて、しばしばGoogle Brainチームと密接に連
携して、Googleと、その他のAlphabetの会社の50以上
のチームがDistBeliefを使って、ディープ・ニューラル・
ネットワークを、広い範囲の多様な製品に配備してきた。
その中には、Google Search [11], 我々の広告製品,
我々の音声認識 [50, 6, 46], Google Photos [43],
Google Maps と StreetView [19], Google
Translate [18], YouTube, その他多くのものが含ま
れている。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-179-320.jpg)


![o ニューラル・ネットワークの訓練を大規模な配備にスケー
ルさせるために、TensorFlowは、データフロー・グラフの
コア・モデルのレプリケーションとパラレル実行を行うこと
で、クライアントが容易に沢山の種類のパラレル処理を表
現することを可能にする。そこでは、多くの異なった計算
デバイスが全て協調して、共有パラメータ、その他の状態
の集合を更新する。計算の記述のあまり大きくない変更
で、広い範囲の異なったアプローチのパラレル処理への
移行が達成され、少ない労力でそれを試すことが可能に
なる。 [14, 29, 42].](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-182-320.jpg)





![o TensorFlow の計算は、ノードの集合からなる有向グラ
フによって記述される。グラフは、データフロー計算を表現
している。ただ、 Naiad [36] と同じようなスタイルで、あ
る種類のノードにパーシステントな状態の維持と更新を可
能とし、また、グラフ内の分岐とループの制御構造を持つ
ように拡張している。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-188-320.jpg)

![TensorFlowのコードとグラフのサンプル
import tensorflow as tf
b = tf.Variable(tf.zeros([100]))
W = tf.Variable(tf.random_uniform([784,100],-1,1))
x = tf.placeholder(name=“x”)
relu = tf.nn.relu(tf.matmul(W, x) + b)
C = [...]
s = tf.Session()
for step in xrange(0, 10):
input = ...construct 100-D input array ...
result = s.run(C, feed_dict={x: input})
print step, result](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-190-320.jpg)













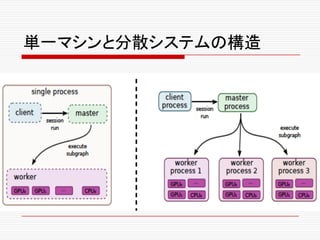
![o 我々の分散環境では、これらの異なったタスクは、クラス
ター・スケジューリング・システム[51]. によって管理され
たジョブの中のコンテナーである。これらの異なったモード
を次の図3に示す。この節の残りの大部分は、両方の実
装にとって共通な問題を議論している。3.3節は、分散実
装に特有の問題を議論している。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-204-320.jpg)












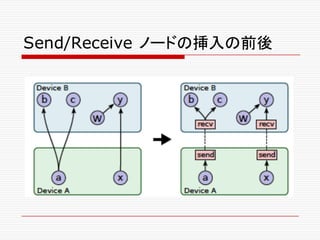








![4.1 勾配計算
o 多くの最適化アルゴリズムは、マシン・ラーニングの訓練ア
ルゴリズムでよく使われている確率的な勾配降下法[45]を
含めて、入力の集合に対するコスト関数の勾配の計算が
行われる。こうした計算へのニーズはとても高いので、
TensorFlowでは、自動的な勾配計算を組み込みでサ
ポートしている。もしも、あるTensorFlowのグラフの中の
テンソルCが、おそらくは複雑な計算を通じて、あるテンソ
ルの集合{Xk}に従属しているのなら、組み込み関数は
{dC/dXk}を返すだろう。勾配テンソルは、他のテンソルと
同じように、次のような手続きを持ちいてTensorFlowグラ
フを拡張することで計算される。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-227-320.jpg)

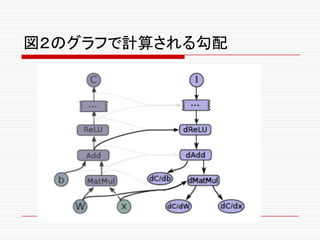
![o この関数は入力として、逆方向の経路に沿ってすでに計
算された部分的な勾配を取るだけでなく、オプションとして
順方向の演算の入力と出力を取る。図5は、図2の例で、
コストに対する勾配を計算している様子を示している。灰
色の矢印は、特定の演算については利用されなかった勾
配関数へのオプションとして可能な入力を表している。図
1に対する追加で必要なことは、次のような勾配を計算す
ることである。
[db,dW,dx] = tf.gradients(C, [b,W,x])](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-229-320.jpg)




![o Run呼び出しの二つの引数が、計算グラフの実行される
べき正確な部分グラフを定義するのを助けることができる。
第一に、Run呼び出しは、 “name:port”という名前でテ
ンソルの値を与えられたオプショナルなマッピングを、入
力として受けつける。第二に、Run呼び出しは、
output_namesを受け取る。それは、出力の名前
[:port]で指定されたリストで、どのノードが実行されるべ
きかを示している。もしもport部分が名前にあれば、Run
呼び出しが成功裏に終わった時、そのノードの特別な出
力テンソルの値がクライアントに返されるべきである。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-235-320.jpg)






![o 多くは、Arvind [3]で記述されたデータフロー・マシンの
アプローチと同じように、我々は、プリミティブなコントロー
ル・フローの小さなセットをTensorFlowに導入し、
TensorFlowをサイクルを持つグラフもハンドルできるよう
に一般化した。SwitchとMergeの演算は、ブール値を持
つテンソルの値に基づいて、ある部分グラフ全体の実行
をスキップすることを可能にする。Enter, Leave,
NextIteration 演算は、繰り返しを表現することを可能
にする。高級言語での、if 条件式や while ループは、こ
うしたコントロール・フロー演算を持つデータフロー・グラフ
に、簡単にコンパイルされうる。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-243-320.jpg)
![o TensorFlow のランタイムは、タグとフレームの概念を実
装している。概念的には、 MIT Tagged-Token
machine [4] に似ている。ループの繰り返しはタグに
よってユニークに名前が与えられ、その実行状態は
frameで表現される。入力は、それが利用可能になった
時いつでも繰り返しに入ることができ、こうして複数の繰り
返しがコンカレントに実行されうる。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-244-320.jpg)










![5.1 共通の部分表現の削除
o 計算グラフの構築は、クライアント・コードでは、多くの異
なった抽象のレイヤーで行われるので、計算グラフは、容
易に同じ計算の冗長なコピーを含むことになる。この問題
をハンドルするために、 Click [12] で記述されたのと似
たアルゴリズム、共通部分表現パスを実装した。これは、
計算グラフ上で走って、同じ入力と同じ演算の型を持つ複
数の演算のコピーを、ただ一つに正規化する。そして、こ
の正規化を反映するように、エッジを適切にリダイレクトす
る。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-255-320.jpg)




![5.4 カーネル実装の最適化ライブラリー
o 我々は、ある演算のカーネルについては、既存の高度に
最適化された数値計算ライブラリーを、しばしば利用して
いる。例えば、異なったデバイス上で行列の掛け算を行う
最適化されたライブラリーは多数存在している。 BLAS
[15], cuBLAS [39] がある。ディープ・ニューラル・ネッ
トワークでのコンボリューションの為のGPUライブラリーと
しては、 cuda-convnet [28] や cuDNN [9] がある。
我々のカーネル実装の多くは、こうした最適化されたライ
ブラリーへの比較的薄い層からなるラッパーである。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-260-320.jpg)
![o 我々は、システムのカーネル実装の多くで、オープンソー
スの Eigen linear algebra library [25]を、かなり積
極的に利用している。TensorFlow開発の一部として、
我々のチームは( Benoit Steinerを中心とする)、オー
プンソースのEigenライブラリーを、任意の次元のテンソ
ル操作をサポートするように拡張してきた。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-261-320.jpg)
![5.5 損失のある圧縮
o 幾つかのマシン・ラーニング・アルゴリズムは、典型的に
は、ニューラル・ネットワークを訓練する為に利用されるの
だが、ノイズや計算精度の低下に耐性を持っている。
DistBelief system [14] と同じようなやり方で、我々は、
デバイス間でデータを送る時(時には同じマシン内でも。
ただ、本質的に重要なのは、マシン境界越える時なのだ
が)、高い精度の内部での表現に損失のある圧縮をかけ
て利用した。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-262-320.jpg)


![o TensorFlowのインターフェースと参照実装は、Apache
2.0ライセンスの元でオープンソース化されてきた。このシ
ステムは、 www.tensorflow.org からダウンロード可
能である。このシステムは詳細なドキュメントと沢山の
チュートリアルと、多様な異なったマシン・ラーニングの仕
事で、どのようにこのシステムを利用するのかを示す沢山
のデモのサンプルを含んでいる。サンプルには、MNIST
データセットから手書き数字を分類するモデル(マシン・
ラーニング・アルゴリズムの“hello world”だ) [32]、
CIFAR- 10 データセットから画像を分類するもの [30]、
recurrent LSTM [22] ネットワークを使って言語モデル
を作るもの、語のベクトル空間への埋め込みを行うものな
どが含まれている。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-265-320.jpg)
![o システムは、TensorFlowの計算を、PythonとC++で指
定するフロントエンドを含んでいる。我々は、時間が経つ
につれ、Google内部のユーザーとより広いオープンソー
ス・コミュニティの双方の願いに応えて、他のフロントエン
ドが追加されることを期待している。
o 我々の以前のDistBelief システム [14] では、ごく少数
のマシン・ラーニング・モデルを持つだけだった。われわれ
はそれをTensorFlowに移植した。この節の残りの部分
は、我々が学んだ教訓について述べようと思う。こうしたマ
シン・ラーニング・モデルの一つのシステムから他のシス
テムへの移植の教訓は一般化可能なもので、それゆえ、
他の人たちにとっても価値があるだろう。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-266-320.jpg)
![o 特に、我々は、 Inception [23]と名付けられた、最先端
の画像認識の為のコンボリューション・ニューラル・ネット
ワーク移植の教訓にフォーカスする。この画像認識のシス
テムは、224 x 224 ピクセルのイメージを1000のラベ
ル(例えば、 “cheetah”, “garbage truck”といった)の
中の一つに分類する。こうしたモデルは、1,360万の学習
可能なパラメーターと、TensorFlowのグラフで表現した
時、36,000個の演算ノードからなる。一つの画像につい
て推論するのに、20億回の掛け算・足し算が必要になる。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-267-320.jpg)

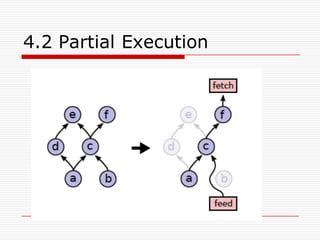
![o 2. 小さくスタートして、スケールアップする。我々が、以前
のシステムから最初に移植したのは、 CIFAR-10 データ
セット [30]上の小さなネットワークであった。こうした小さ
なネットワークをデバッグすることは、もっと複雑なモデル
では、実践的には解読できないものであったマシン・ラー
ニング・システムの内部で、個別の演算(例えば、max-
pooling)の微妙で特徴的なケースを明確にする。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-270-320.jpg)









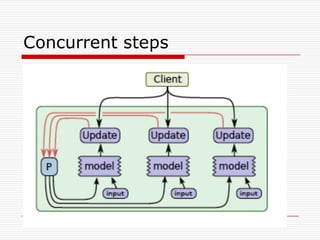
![o TensorFlowのグラフが、多数の部分グラフのレプリカを
持ち、それが大量のモデル計算をおこなうというこのアプ
ローチは、これらのレプリカの一つ一つが、モデルのパラ
メーター更新も非同期に行うことで、非同期に行われるこ
とも可能である。こうした設定では、それぞれのグラフのレ
プリカに、一つのクライアントのスレッドがあることになる。
これは、図7の下の図で示されている。この非同期なアプ
ローチは、 [14]でも述べられていた。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-280-320.jpg)
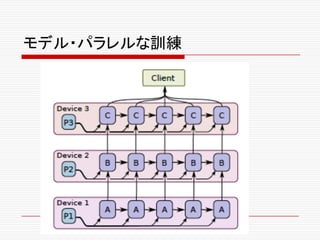
![モデル・パラレルな訓練
o モデル・パラレルな訓練では、モデルの異なった部分の計
算が、サンプルの同じバッチのために、異なる計算デバイ
ス上で同時に行われる。これも、容易にTensorFlowで表
現できる。図8は、シーケンスからシーケンスの学習に使
われるリカレントでディープなLSTMモデル([47])が、三
つの異なるデバイス上でパラレルに実行される様子を示
している。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-281-320.jpg)





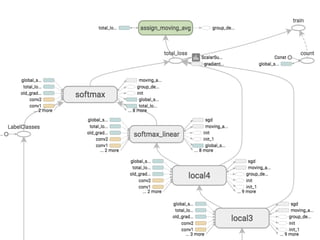
![計算グラフの可視化
o ディープ・ニューラル・ネットワークの計算グラフは、きわめ
て複雑なものになりうる。例えば、GoogleのInception
モデル[48]に似た訓練用の計算グラフは、ディープ・コン
ボリューション・ニューラル・ネットワークで、2014年のコ
ンテストで最高の分類パフォーマンスを示したのだが、
TensorFlowの計算グラフでは、36,000個以上のノード
を持っている。そして、言語モデルのためのディープ・リカ
レントLSTMモデルは、15,000以上のノードを持っている。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-289-320.jpg)


















![o TensorFlowと様々な点で比較できる多くの他のシステ
ムが存在する。Theano [7], Torch [13], Caffe [26],
Chainer [49], Computational Network Toolkit
[54] 。これらは、第一義的にニューラル・ネットワークの
訓練のためにデザインされたいくつかのシステムである。
これらのシステムは、TensorFlowの実装とは異なって、
計算を単一のマシン上にマップする。Theanoと
Chainerと同じように、TensorFlowは, シンボルの微分
をサポートする。このことは、勾配ベースの最適化アルゴ
リズムの定義と利用を容易にする。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-312-320.jpg)

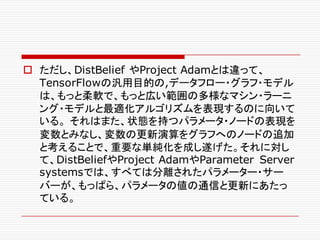
![o TensorFlowシステムは、幾つかのデザインの特徴を先
行したシステムであるDistBelief [14] と共有している。
後者のシステムは、Project Adam [10]や
Parameter Server project [33]とも似たデザインをし
ている。DistBeliefやProject Adamのように、
TensorFlowは、計算をたくさんのマシン上のたくさんの
計算デバイスに拡散することを可能とする。ユーザーは、
マシン・ラーニング・モデルを、比較的高水準の記述を
使って指定することが可能になる。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-314-320.jpg)
![o イメージ・プロセッシングのパイプラインの表現のための
Halide system [40]も、TensorFlowのデータフロー・
グラフと似た、中間表現を利用している。しかし、
TensorFlowとは異なって、Halide systemは、実際に
は、演算のセマンティックについての高レベルな知識を持
ち、この知識を利用して、並列性と局所性を考慮しながら、
複数の演算を結合した高度に最適化されたコードを生成
している。 Halideは、結果としての計算を単一のマシン
上のみで走らせており、分散の設定では走らせていない。
将来的には、我々は、TensorFlowを、演算をまたいだ動
的なコンパイルのフレームワークをもったものに拡張した
いと望んでいる。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-316-320.jpg)
![o TensorFlowと同じように、クラスターをまたいだデータフ
ロー・グラフの実行を行う、いくつかの他の分散システム
が開発されてきた。Dryad [24] と Flume [8] は、いか
にして、複雑なワークフローがデータフロー・グラフとして
表現されうるかを示している。CIEL [37] と Naiad [36]
は、データ従属コントロール・フローの一般的なサポートを
導入した。CIELは、繰り返しを、動的に広げられるDAGと
して表現し、一方、 Naiad は、低い遅延での繰り返しを
サポートするために、サイクルを持つ静的なグラフを利用
する。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-317-320.jpg)
![o Spark [55] は、以前の計算出力のsoft-stateキャッ
シュである“resilient distributed datasets” (RDDs)
を利用して、同じデータに繰り返しアクセスする計算に最
適化されている。Dandelion [44]は、GPUを含むヘテロ
なデバイスのクラスターをまたいで、データフロー・グラフ
を実行する。
o TensorFlowは、これらのシステムのからの諸要素を借
用したハイブリッドなデータフロー・モデルを使っている。
そのデータフローの、次に実行されるべきノードを選択す
るコンポーネントであるスケジューラーは、 Dryad,
Flume, CIEL, Sparkと同じ基本的なアルゴリズムを利
用している。](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-318-320.jpg)





![o [1] Mart´ın Abadi, Ashish Agarwal, Paul Barham, Eugene
Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado,
Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghe-
mawat, Ian Goodfellow, Andrew Harp, Geoffrey Irv- ing,
Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz
Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mane´,
Rajat Monga, Sherry Moore, Derek Murray, Chris Olah,
Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya
Sutskever, Kunal Talwar, Paul Tucker, Vincent
Vanhoucke, Vijay Vasudevan, Fernanda Vie´gas, Oriol
Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke,
Yuan Yu, and Xiaoqiang Zheng. TensorFlow: Large-scale
machine learning on heterogeneous systems, 2015.
Soft- ware available from tensorflow.org.
o [2] Anelia Angelova, Alex Krizhevsky, and Vincent Van-
houcke. Pedestrian detection with a large-field-of-view
deep network. In Robotics and Automation (ICRA), 2015
IEEE International Conference on, pages 704–711. IEEE,
2015. CalTech PDF.](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-324-320.jpg)
![o [3] Arvind and David E. Culler. Annual review
of computer science vol. 1, 1986. chapter
Dataflow Architectures, pages 225–253. 1986.
www.dtic.mil/cgi-bin/GetTRDoc?Location=U2&
doc=GetTRDoc.pdf&AD=ADA166235.
o [4] Arvind and Rishiyur S. Nikhil. Executing a pro-
gram on the MIT tagged-token dataflow architec- ture.
IEEE Trans. Comput., 39(3):300–318, 1990.
dl.acm.org/citation.cfm?id=78583.
o [5] Jimmy Ba, Volodymyr Mnih, and Koray Kavukcuoglu.
Multiple object recognition with visual atten- tion.
arXiv preprint arXiv:1412.7755, 2014.
arxiv.org/abs/1412.7755.
o [6] Franc¸oise Beaufays. The
neural networks behind Google Voice
transcription, 2015.
googleresearch.blogspot.com/2015/08/the-neural-
networks-behind-google-voice.html.](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-325-320.jpg)
![o [7] James Bergstra, Olivier Breuleux, Fre´de´ric Bastien,
Pas- cal Lamblin, Razvan Pascanu, Guillaume Desjardins,
Joseph Turian, David Warde-Farley, and Yoshua Bengio.
Theano: A CPU and GPU math expression compiler. In
Proceedings of the Python for scientific computing con-
ference (SciPy), volume 4, page 3. Austin, TX, 2010.
UMontreal PDF.
o [8] Craig Chambers, Ashish Raniwala, Frances Perry,
Stephen Adams, Robert R Henry, Robert Bradshaw,
and Nathan Weizenbaum. FlumeJava: easy, effi-
cient data-parallel pipelines. In ACM Sigplan No- tices,
volume 45, pages 363–375. ACM, 2010. re-
search.google.com/pubs/archive/35650.pdf.
o [9] Sharan Chetlur, Cliff Woolley, Philippe Vandermer-
sch, Jonathan Cohen, John Tran, Bryan Catanzaro,
and Evan Shelhamer. cuDNN: Efficient primitives for
deep learning. arXiv preprint arXiv:1410.0759, 2014.
arxiv.org/abs/1410.0759.](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-326-320.jpg)
![o [10] Trishul Chilimbi, Yutaka Suzue, Johnson Apacible,
and Karthik Kalyanaraman. Project Adam: Building
an efficient and scalable deep learning training system.
In 11th USENIX Symposium on Operating Systems
Design and Implementation (OSDI 14), pages 571–582,
2014.
www.usenix.org/system/files/conference/osdi14/osdi14-
paper-chilimbi.pdf.
o [11] Jack Clark. Google turning its
lucrative web search over to AI
machines, 2015.
www.bloomberg.com/news/articles/2015-10-26/google-
turning-its-lucrative-web-search-over-to-ai-machines.
o [12] Cliff Click. Global code motion/global value number-
ing. In ACM SIGPLAN Notices, volume 30, pages 246–
257. ACM, 1995. courses.cs.washington.edu/courses/
cse501/06wi/reading/click-pldi95.pdf.](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-327-320.jpg)
![o [13] Ronan Collobert, Samy Bengio, and Johnny
Marie´thoz. Torch: A modular machine learning
software library. Technical report, IDIAP, 2002.
infoscience.epfl.ch/record/82802/files/rr02-46.pdf.
o [14] Jeffrey Dean, Gregory S. Corrado, Rajat Monga, Kai
Chen, Matthieu Devin, Quoc V. Le, Mark Z. Mao,
Marc’Aurelio Ranzato, Andrew Senior, Paul Tucker,
Ke Yang, and Andrew Y. Ng. Large scale distributed deep
networks. In NIPS, 2012. Google Research PDF.
o [15] Jack J Dongarra, Jeremy Du Croz, Sven Hammar-
ling, and Iain S Duff. A set of level 3 basic lin-
ear algebra subprograms. ACM Transactions on
Mathematical Software (TOMS), 16(1):1–17, 1990.
www.maths.manchester.ac.uk/˜sven/pubs/Level3BLAS-
1-TOMS16-90.pdf.
o [16] Andrea Frome, Greg S Corrado, Jonathon Shlens,
Samy Bengio, Jeff Dean, Tomas Mikolov, et al. DeVISE:
A deep visual-semantic embedding model. In
Advances in Neural Information Pro- cessing Systems,
pages 2121–2129, 2013. re-
search.google.com/pubs/archive/41473.pdf.](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-328-320.jpg)
![o [17] Javier Gonzalez-Dominguez, Ignacio Lopez-Moreno,
Pe- dro J Moreno, and Joaquin Gonzalez-Rodriguez.
Frame- by-frame language identification in short
utterances using deep neural networks. Neural Networks,
64:49–58, 2015.
o [18] Otavio Good. How Google Translate
squeezes deep learning onto a
phone, 2015.
googleresearch.blogspot.com/2015/07/how-google-
translate-squeezes-deep.html.
o [19] Ian J. Goodfellow, Yaroslav Bulatov, Julian Ibarz,
Sacha Arnoud, and Vinay Shet. Multi-digit number
recognition from Street View imagery using deep
convolutional neu- ral networks. In International
Conference on Learning Representations, 2014.
arxiv.org/pdf/1312.6082.](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-329-320.jpg)
![o [20] Georg Heigold, Vincent Vanhoucke, Alan Senior,
Patrick Nguyen, Marc’Aurelio Ranzato, Matthieu Devin,
and Jeffrey Dean. Multilingual acoustic models using dis-
tributed deep neural networks. In Acoustics, Speech
and Signal Processing (ICASSP), 2013 IEEE Interna-
tional Conference on, pages 8619–8623. IEEE, 2013. re-
search.google.com/pubs/archive/40807.pdf.
o [21] Geoffrey E. Hinton, Li Deng, Dong Yu, George E.
Dahl, Abdel-rahman Mohamed, Navdeep Jaitly, An- drew
Senior, Vincent Vanhoucke, Patrick Nguyen, Tara N.
Sainath, and Brian Kingsbury. Deep neural
networks for acoustic modeling in speech recognition:
The shared views of four research groups. IEEE
Signal Process. Mag., 29(6):82– 97, 2012.
www.cs.toronto.edu/˜gdahl/papers/
deepSpeechReviewSPM2012.pdf.
o [22] Sepp Hochreiter and Ju¨rgen Schmidhuber. Long
short- term memory. Neural computation, 9(8):1735–
1780, 1997. ftp.idsia.ch/pub/juergen/lstm.pdf.](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-330-320.jpg)
![o [23] Sergey Ioffe and Christian Szegedy. Batch
normaliza- tion: Accelerating deep network training by
reducing internal covariate shift. CoRR, abs/1502.03167,
2015. arxiv.org/abs/1502.03167.
o [24] Michael Isard, Mihai Budiu, Yuan Yu, Andrew
Birrell, and Dennis Fetterly. Dryad: distributed data-
parallel programs from sequential building blocks. In
ACM SIGOPS Operating Systems Review, volume 41,
pages 59–72. ACM, 2007.
www.michaelisard.com/pubs/eurosys07.pdf.
o [25] Benoˆıt Jacob, Gae¨l Guennebaud, et al. Eigen
library for linear algebra. eigen.tuxfamily.org.
o [26] Yangqing Jia, Evan Shelhamer, Jeff Donahue,
Sergey Karayev, Jonathan Long, Ross Girshick, Sergio
Guadar- rama, and Trevor Darrell. Caffe: Convolutional
archi- tecture for fast feature embedding. In
Proceedings of the ACM International Conference on
Multimedia, pages 675–678. ACM, 2014.
arxiv.org/pdf/1408.5093.](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-331-320.jpg)
![o [27] Andrej Karpathy, George Toderici, Sachin Shetty,
Tommy Leung, Rahul Sukthankar, and Li Fei- Fei.
Large-scale video classification with con- volutional
neural networks. In Computer Vision and Pattern
Recognition (CVPR), 2014 IEEE Con- ference on, pages
1725–1732. IEEE, 2014. re-
search.google.com/pubs/archive/42455.pdf.
o [28] A Krizhevsky. Cuda-convnet, 2014.
code.google.com/p/cuda-convnet/.
o [29] Alex Krizhevsky. One weird trick for paralleliz-
ing convolutional neural networks. arXiv preprint
arXiv:1404.5997, 2014. arxiv.org/abs/1404.5997.
o [30] Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton.
The CIFAR-10 dataset.
www.cs.toronto.edu/˜kriz/cifar.html.
o [31] Quoc Le, Marc’Aurelio Ranzato, Rajat Monga,
Matthieu Devin, Greg Corrado, Kai Chen, Jeff Dean, and
Andrew Ng. Building high-level features using large scale
unsu- pervised learning. In ICML’2012, 2012. Google
Research PDF](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-332-320.jpg)
![o [32] Yann LeCun, Corinna Cortes, and Christopher JC
Burges. The MNIST database of handwritten digits, 1998.
yann.lecun.com/exdb/mnist/.
o [33] Mu Li, Dave Andersen, and Alex Smola. Parameter
server. parameterserver.org.
o [34] Chris J Maddison, Aja Huang, Ilya Sutskever, and
David Silver. Move evaluation in Go using deep
convolutional neural networks. arXiv preprint
arXiv:1412.6564, 2014. arxiv.org/abs/1412.6564.
o [35] Tomas Mikolov, Kai Chen, Greg Corrado, and
Jef- frey Dean. Efficient estimation of word representa-
tions in vector space. In International Conference
on Learning Representations: Workshops Track, 2013.
arxiv.org/abs/1301.3781.
o [36] Derek G Murray, Frank McSherry, Rebecca Isaacs,
Michael Isard, Paul Barham, and Mart´ın Abadi. Naiad:
a timely dataflow system. In Proceedings of the Twenty-
Fourth ACM Symposium on Operating Systems Princi-
ples, pages 439–455. ACM, 2013. Microsoft Research
PDF.](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-333-320.jpg)
![o [37] Derek G. Murray, Malte Schwarzkopf, Christopher
Smowton, Steven Smit, Anil Madhavapeddy, and Steven
Hand. Ciel: a universal execution engine for dis-
tributed data-flow computing. In Proceedings of the
Ninth USENIX Symposium on Networked Systems Design
and Implementation, 2011. Usenix PDF.
o [38] Arun Nair, Praveen Srinivasan, Sam Blackwell,
Cagdas Alcicek, Rory Fearon, Alessandro De Maria, Ve-
davyas Panneershelvam, Mustafa Suleyman, Charles
Beattie, Stig Petersen, et al. Massively parallel meth-
ods for deep reinforcement learning. arXiv preprint
arXiv:1507.04296, 2015. arxiv.org/abs/1507.04296.
o [39] CUDA Nvidia. Cublas library. NVIDIA Corpo-
ration, Santa Clara, California, 15, 2008. devel-
oper.nvidia.com/cublas.](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-334-320.jpg)
![o [40] Jonathan Ragan-Kelley, Connelly Barnes, Andrew
Adams, Sylvain Paris, Fre´do Durand, and Saman Ama-
rasinghe. Halide: A language and compiler for optimiz-
ing parallelism, locality, and recomputation in image pro-
cessing pipelines. ACM SIGPLAN Notices, 48(6):519–
530, 2013. people.csail.mit.edu/fredo/tmp/Halide-
5min.pdf.
o [41] Bharath Ramsundar, Steven Kearnes, Patrick Riley,
Dale Webster, David Konerding, and Vijay Pande.
Massively multitask networks for drug discovery. arXiv
preprint arXiv:1502.02072, 2015.
arxiv.org/abs/1502.02072.
o [43] Chuck Rosenberg. Improving Photo
Search: A step across the semantic gap, 2013.
googleresearch.blogspot.com/2013/06/improving-photo-
search-step-across.html.](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-335-320.jpg)
![o [44] Christopher J Rossbach, Yuan Yu, Jon Currey, Jean-
Philippe Martin, and Dennis Fetterly. Dandelion: a
compiler and runtime for heterogeneous systems. In
Proceedings of the Twenty-Fourth ACM Symposium
on Operating Systems Principles, pages 49–68. ACM,
2013. research-srv.microsoft.com/pubs/201110/sosp13-
dandelion-final.pdf.
o [45] David E Rumelhart, Geoffrey E Hinton, and Ronald J
Williams. Learning representations by back-
propagating errors. Cognitive modeling, 5:3, 1988.
www.cs.toronto.edu/ hinton/absps/naturebp.pdf.
o [46] Has¸im Sak, Andrew Senior,Kanishka
Rao, Franc¸oise Beaufays, and Johan
Schalkwyk. Google Voice Search:
faster and more accurate, 2015.
googleresearch.blogspot.com/2015/09/google-voice-
search-faster-and-more.html.](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-336-320.jpg)
![o [47] Ilya Sutskever, Oriol Vinyals, and Quoc V. Le.
Sequence to sequence learning with neural networks. In
NIPS, 2014. papers.nips.cc/paper/5346-sequence-to-
sequence- learning-with-neural.
o [48] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre
Ser- manet, Scott Reed, Dragomir Anguelov, Dumitru
Er- han, Vincent Vanhoucke, and Andrew Rabinovich.
Go- ing deeper with convolutions. In CVPR’2015, 2015.
arxiv.org/abs/1409.4842.
o [49] Seiya Tokui. Chainer: A powerful, flexible and
intuitive framework of neural networks. chainer.org.
o [50] Vincent Vanhoucke. Speech recognition and deep
learn- ing, 2015.
googleresearch.blogspot.com/2012/08/speech-
recognition-and-deep-learning.html.](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-337-320.jpg)
![o [51] Abhishek Verma, Luis Pedrosa, Madhukar Korupolu,
David Oppenheimer, Eric Tune, and John Wilkes. Large-
scale cluster management at Google with Borg. In
Proceedings of the Tenth European Conference on
Computer Systems, page 18. ACM, 2015. re-
search.google.com/pubs/archive/43438.pdf.
o [52] O. Vinyals, L. Kaiser, T. Koo, S. Petrov, I. Sutskever,
and G. Hinton. Grammar as a foreign language.
Technical report, arXiv:1412.7449, 2014.
arxiv.org/abs/1412.7449.
o [53] Oriol Vinyals, Meire Fortunato, and Navdeep
Jaitly. Pointer networks. In NIPS, 2015.
arxiv.org/abs/1506.03134.
o [54] Dong Yu, Adam Eversole, Mike Seltzer, Kaisheng
Yao, Zhiheng Huang, Brian Guenter, Oleksii Kuchaiev, Yu
Zhang, Frank Seide, Huaming Wang, et al. An
introduction to computational networks and the com-
putational network toolkit. Technical report, Tech. Rep.
MSR, Microsoft Research, 2014, 2014. re-
search.microsoft.com/apps/pubs/?id=226641.](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-338-320.jpg)
![o [55] Matei Zaharia, Mosharaf Chowdhury, Tathagata Das,
Ankur Dave, Justin Ma, Murphy McCauley, Michael J
Franklin, Scott Shenker, and Ion Stoica. Resilient
distributed datasets: A fault-tolerant abstraction for in-
memory cluster computing. In Proceedings of the 9th
USENIX conference on Networked Systems De- sign
and Implementation. USENIX Association, 2012.
www.usenix.org/system/files/conference/nsdi12/nsdi12-
final138.pdf.
o [56] Matthew D. Zeiler, Marc’Aurelio Ranzato, Rajat
Monga, Mark Mao, Ke Yang, Quoc Le, Patrick Nguyen,
Andrew Senior, Vincent Vanhoucke, Jeff Dean, and
Geoffrey E. Hinton. On rectified linear units
for speech processing. In ICASSP, 2013. re-
search.google.com/pubs/archive/40811.pdf.](https://image.slidesharecdn.com/ml2-151223151746/85/TensolFlow-White-Paper-339-320.jpg)



































































