Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Hiroaki Komine
PPTX, PDF
1,805 views
Ibm watson api サービス
Bluemix で利用できる Watson API サービスの概要の説明資料です。
Software
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Downloaded 40 times
1
/ 98
2
/ 98
3
/ 98
4
/ 98
5
/ 98
6
/ 98
7
/ 98
8
/ 98
9
/ 98
10
/ 98
11
/ 98
12
/ 98
13
/ 98
14
/ 98
15
/ 98
16
/ 98
17
/ 98
18
/ 98
19
/ 98
20
/ 98
21
/ 98
22
/ 98
23
/ 98
24
/ 98
25
/ 98
26
/ 98
27
/ 98
28
/ 98
29
/ 98
30
/ 98
31
/ 98
32
/ 98
33
/ 98
34
/ 98
35
/ 98
36
/ 98
37
/ 98
38
/ 98
39
/ 98
40
/ 98
41
/ 98
42
/ 98
43
/ 98
44
/ 98
45
/ 98
46
/ 98
47
/ 98
48
/ 98
49
/ 98
50
/ 98
51
/ 98
52
/ 98
53
/ 98
54
/ 98
55
/ 98
56
/ 98
57
/ 98
58
/ 98
59
/ 98
60
/ 98
61
/ 98
62
/ 98
63
/ 98
64
/ 98
65
/ 98
66
/ 98
67
/ 98
68
/ 98
69
/ 98
70
/ 98
71
/ 98
72
/ 98
73
/ 98
74
/ 98
75
/ 98
76
/ 98
77
/ 98
78
/ 98
79
/ 98
80
/ 98
81
/ 98
82
/ 98
83
/ 98
84
/ 98
85
/ 98
86
/ 98
87
/ 98
88
/ 98
89
/ 98
90
/ 98
91
/ 98
92
/ 98
93
/ 98
94
/ 98
95
/ 98
96
/ 98
97
/ 98
98
/ 98
More Related Content
PPTX
いまからでも聞いていただきたい Watsonの得意な3つのこと!
by
岬 宇藤
PPTX
量子コンピュータ
by
Masanori Saito
PDF
IBM Bluemix紹介
by
Li Zhanfei (Jonathan)
PDF
Watsonを使ってAIアプリを作ってみよう!-ハンズオン-
by
BMXUG
PDF
SIer目線でみたbluemix "bluemixハッカソン、watson ハッカソンでの知見"
by
Hideaki Tokida
PDF
りんな風 女子高生Bot - docomo雑談対話API +α を使って 自分専用Botを作る -
by
Koji Shiraishi
PPTX
IBM Bluemix × Watson でMashup Hackathon (API説明)
by
Masaya Fujita
PDF
【Open cloud innovation festa 2016 資料】 SoftLayerで始めるデジタルマーケティング
by
Kohei Nishikawa
いまからでも聞いていただきたい Watsonの得意な3つのこと!
by
岬 宇藤
量子コンピュータ
by
Masanori Saito
IBM Bluemix紹介
by
Li Zhanfei (Jonathan)
Watsonを使ってAIアプリを作ってみよう!-ハンズオン-
by
BMXUG
SIer目線でみたbluemix "bluemixハッカソン、watson ハッカソンでの知見"
by
Hideaki Tokida
りんな風 女子高生Bot - docomo雑談対話API +α を使って 自分専用Botを作る -
by
Koji Shiraishi
IBM Bluemix × Watson でMashup Hackathon (API説明)
by
Masaya Fujita
【Open cloud innovation festa 2016 資料】 SoftLayerで始めるデジタルマーケティング
by
Kohei Nishikawa
Similar to Ibm watson api サービス
PDF
Ibm watson machine learning and watson knowledge stuido 20160827
by
Tsuyoshi Hirayama
PDF
【Salesforce Webセミナー】IBM_人工知能(AI)により変革する、顧客との関係 IBMとSalesforceの提携で生まれる、お客様との新た...
by
Tsuyoshi Hirayama
PDF
kintone Cafe Japan 2016: kintone x 機械学習で実現する簡単名刺管理
by
Takahiro Kubo
PDF
企業における自然言語処理技術の活用の現場(情報処理学会東海支部主催講演会@名古屋大学)
by
Yuya Unno
PDF
第86回 Machine Learning 15minutes! IBMの大規模言語モデルGraniteと生成AI Governance 機能のご紹介
by
Tsuyoshi Hirayama
PDF
第73回 Machine Learning 15minutes ! IBM AI Foundation Modelsへの取り組み
by
Tsuyoshi Hirayama
PDF
Waston が拓く UX の新しい地平 〜 UX デザイナーが IBM Waston を使ってみた 〜:2017年4月22日 AI eats UX me...
by
Yoshiki Hayama
PPTX
[2017年11月22日] Call Center Watsonのご紹介(日本IBM GTS Innovation Forum 2017)
by
Hiroshi Tomioka
PDF
ラズパイ+SL+BMでワトソンと話そう
by
Maho Takara
PDF
Watson Explorerを使ったテキストマイニング
by
Hori Tasuku
PDF
SoftLayer Bluemix Summit 2015: BluemixでWatsonをつかいたおせ!
by
Miki Yutani
PDF
GTC 2016 基調講演からディープラーニング関連情報のご紹介
by
NVIDIA Japan
PDF
Developers Summit 2015 【19-E-4】 体感!「IBM Bluemix」が実現するリアルに迅速な開発
by
Manabu Matsui
PDF
人工知能に何ができないか? ー ゲームと人工知能の視点から -
by
Youichiro Miyake
PDF
Watson API トレーニング 20160716 rev02
by
Hiroaki Komine
PDF
Watson.assistant chat bot-20200117
by
Yasushi Osonoi
PDF
人工知能事例 試せる機械学習
by
Hiroshi Matsumoto
PDF
OSSを活用して進化しつづける IBMクラウドとコグニティグ・ ソリューションIBM Watsonの最新情報
by
岬 宇藤
PDF
Watson Visual Recognition x Pepper
by
篤 富田
PDF
機械学習技術の現在+TensolFlow White Paper
by
maruyama097
Ibm watson machine learning and watson knowledge stuido 20160827
by
Tsuyoshi Hirayama
【Salesforce Webセミナー】IBM_人工知能(AI)により変革する、顧客との関係 IBMとSalesforceの提携で生まれる、お客様との新た...
by
Tsuyoshi Hirayama
kintone Cafe Japan 2016: kintone x 機械学習で実現する簡単名刺管理
by
Takahiro Kubo
企業における自然言語処理技術の活用の現場(情報処理学会東海支部主催講演会@名古屋大学)
by
Yuya Unno
第86回 Machine Learning 15minutes! IBMの大規模言語モデルGraniteと生成AI Governance 機能のご紹介
by
Tsuyoshi Hirayama
第73回 Machine Learning 15minutes ! IBM AI Foundation Modelsへの取り組み
by
Tsuyoshi Hirayama
Waston が拓く UX の新しい地平 〜 UX デザイナーが IBM Waston を使ってみた 〜:2017年4月22日 AI eats UX me...
by
Yoshiki Hayama
[2017年11月22日] Call Center Watsonのご紹介(日本IBM GTS Innovation Forum 2017)
by
Hiroshi Tomioka
ラズパイ+SL+BMでワトソンと話そう
by
Maho Takara
Watson Explorerを使ったテキストマイニング
by
Hori Tasuku
SoftLayer Bluemix Summit 2015: BluemixでWatsonをつかいたおせ!
by
Miki Yutani
GTC 2016 基調講演からディープラーニング関連情報のご紹介
by
NVIDIA Japan
Developers Summit 2015 【19-E-4】 体感!「IBM Bluemix」が実現するリアルに迅速な開発
by
Manabu Matsui
人工知能に何ができないか? ー ゲームと人工知能の視点から -
by
Youichiro Miyake
Watson API トレーニング 20160716 rev02
by
Hiroaki Komine
Watson.assistant chat bot-20200117
by
Yasushi Osonoi
人工知能事例 試せる機械学習
by
Hiroshi Matsumoto
OSSを活用して進化しつづける IBMクラウドとコグニティグ・ ソリューションIBM Watsonの最新情報
by
岬 宇藤
Watson Visual Recognition x Pepper
by
篤 富田
機械学習技術の現在+TensolFlow White Paper
by
maruyama097
More from Hiroaki Komine
PDF
テクてく Lotus 技術者夜会 03/16 Lotus Notes/Domino Upgrade Pack とは
by
Hiroaki Komine
PDF
Lotus greenhouse への登録手順
by
Hiroaki Komine
PDF
新入生向け、おやじの会のお誘い 20140928 公開用
by
Hiroaki Komine
PPT
割り箸パチンコ
by
Hiroaki Komine
PDF
IBM Connect Japan 2012 TC-4/OB-5 ついにその実体を現す IBM Project Vulcan! その中核となる IBM S...
by
Hiroaki Komine
PDF
IBM Eclipse tools for Bluemix の構成手順
by
Hiroaki Komine
PDF
Lotus DEvCon 2000 - LotusScript Tips and Techniques
by
Hiroaki Komine
PPT
寺尾小学校親子花火大会 2014 校庭配置図
by
Hiroaki Komine
テクてく Lotus 技術者夜会 03/16 Lotus Notes/Domino Upgrade Pack とは
by
Hiroaki Komine
Lotus greenhouse への登録手順
by
Hiroaki Komine
新入生向け、おやじの会のお誘い 20140928 公開用
by
Hiroaki Komine
割り箸パチンコ
by
Hiroaki Komine
IBM Connect Japan 2012 TC-4/OB-5 ついにその実体を現す IBM Project Vulcan! その中核となる IBM S...
by
Hiroaki Komine
IBM Eclipse tools for Bluemix の構成手順
by
Hiroaki Komine
Lotus DEvCon 2000 - LotusScript Tips and Techniques
by
Hiroaki Komine
寺尾小学校親子花火大会 2014 校庭配置図
by
Hiroaki Komine
Ibm watson api サービス
1.
© 2017 International
Business Machines Corporation 日本アイ・ビー・エム株式会社 TSDL Watson開発 小峯 宏秋 IBM Watson API サービスの概要 1 2017年8月24日
2.
© 2017 International
Business Machines Corporation この資料の目的 東京ソフトウェア&システム開発研究所 2 IBM Watson の概要を理解する。 IBM Bluemix で利用できるWatson サービスの全体像と、 それらのサービスの使い方を知る。 個々の Watsonサービスを試す。
3.
© 2017 International
Business Machines Corporation アジェンダ 東京ソフトウェア&システム開発研究所 3 1. IBM Watson APIサービスの概要 2. IBM BluemixのWatson APIサービス 3. Watson APIサービスの使い方 4. 【実習】Watson APIサービスを使用する
4.
© 2017 International
Business Machines Corporation IBM Watson の展開 4東京ソフトウェア&システム開発研究所 発祥 • 質問応答システム@Jeopardy! 現在 • コグニティブ・システムを実現する技術・製品・サービス
5.
© 2017 International
Business Machines Corporation Watson の AI 5東京ソフトウェア&システム開発研究所 AI =「Augmented Intelligence (拡張知能)」 蒸気機関 これまで運べなかった大量の荷 物や人を素早く運ぶことができ るようになった 工業化 品質の揃った大量の製品 を短時間で生産可能に なった コンピュータ 複雑な計算を瞬時でこなすこと で、月にロケットを飛ばすこと も可能にした インターネット 遠く離れた人や物といつでも コミュニケーションでき、 様々な情報にアクセスできる ようになった Watson 自然言語で書かれたたくさ んの書物の内容を理解して、 そこに含まれる知見を汲み 取ることを可能にする 新しい技術で、人のできることが広がる
6.
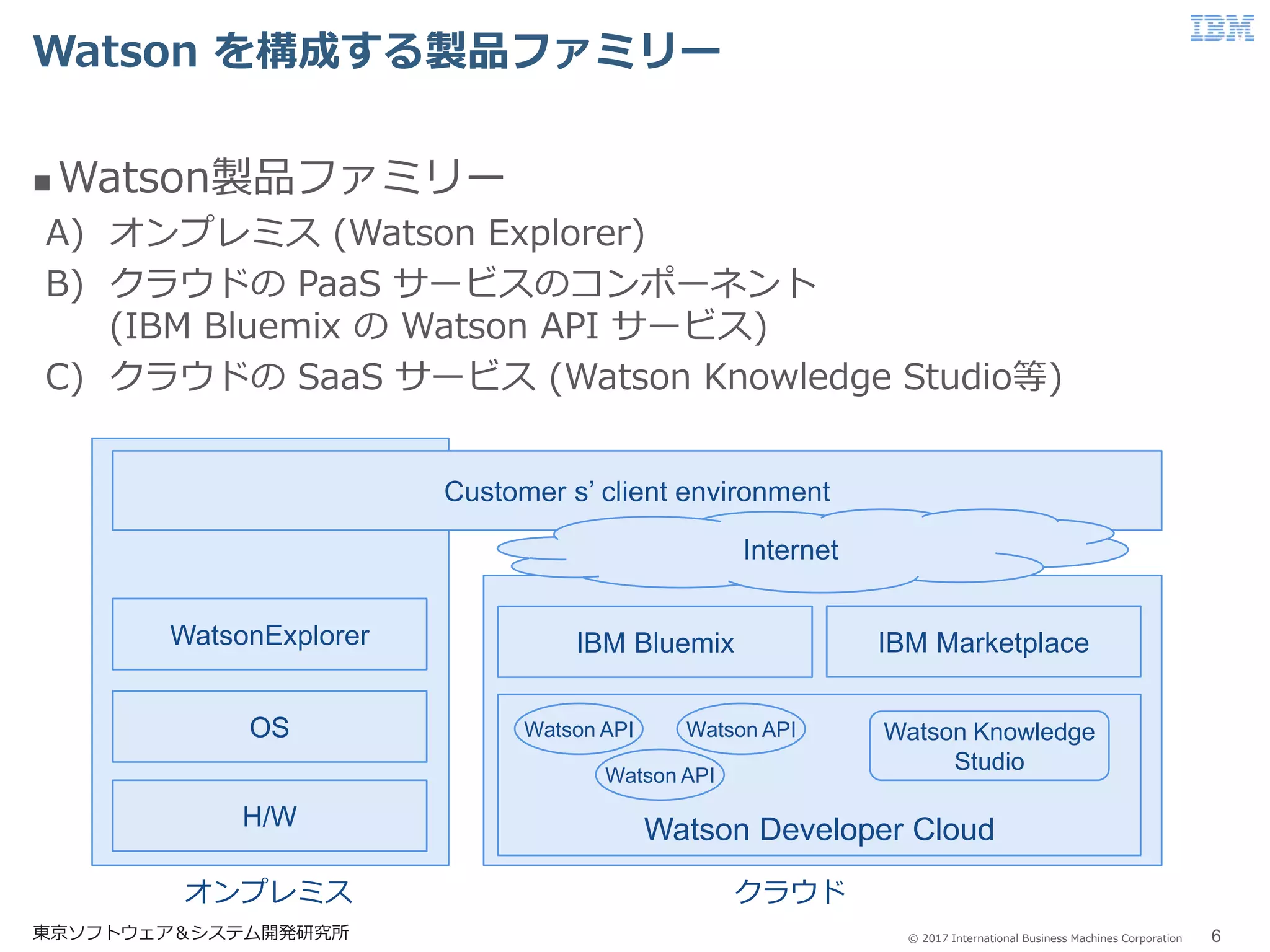
© 2017 International
Business Machines Corporation Watson を構成する製品ファミリー 東京ソフトウェア&システム開発研究所 6 Watson製品ファミリー A) オンプレミス (Watson Explorer) B) クラウドの PaaS サービスのコンポーネント (IBM Bluemix の Watson API サービス) C) クラウドの SaaS サービス (Watson Knowledge Studio等) Customer s’ client environment H/W OS WatsonExplorer Watson Developer Cloud IBM Bluemix IBM Marketplace Internet Watson API Watson Knowledge Studio Watson API Watson API オンプレミス クラウド
7.
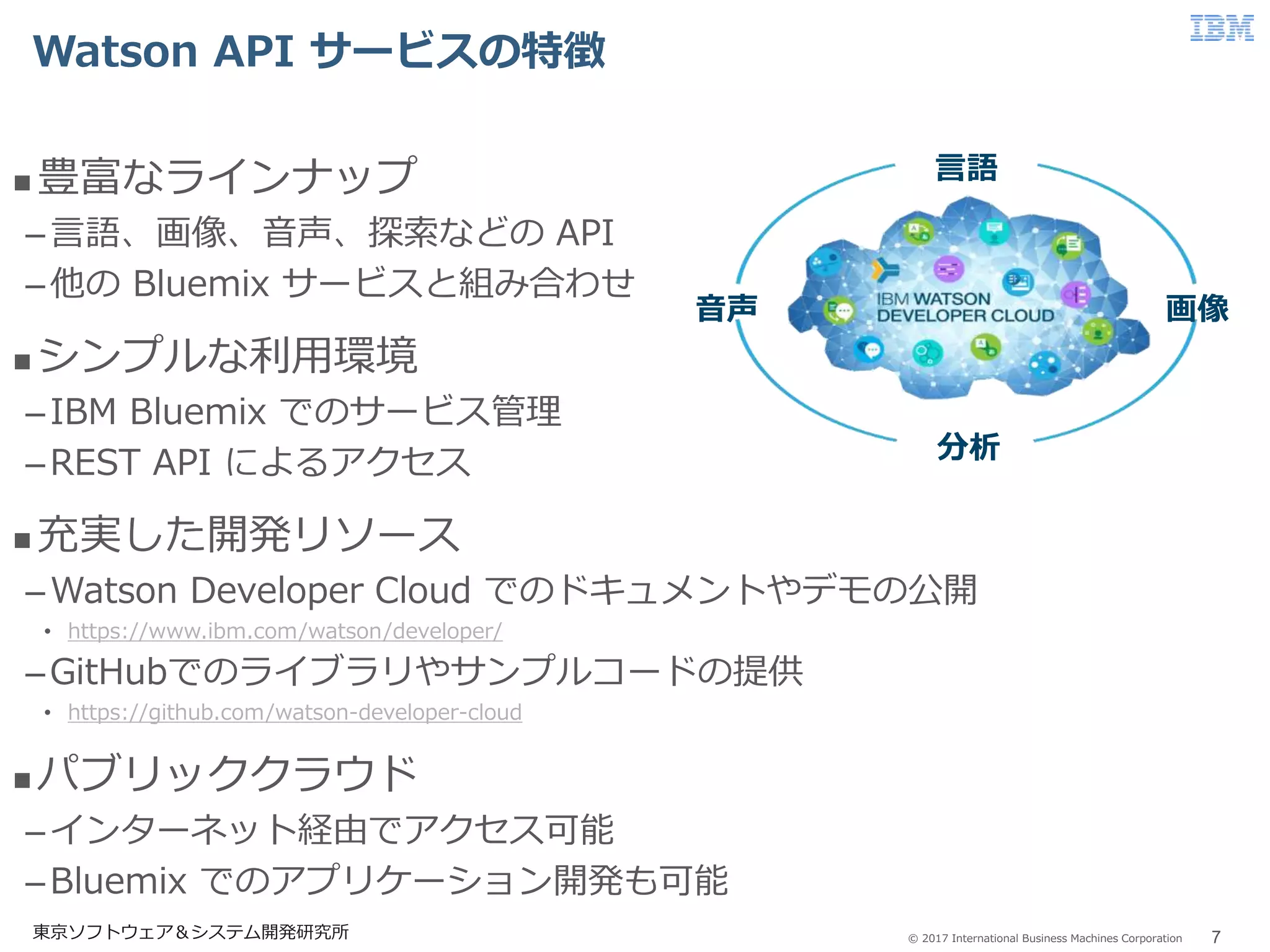
© 2017 International
Business Machines Corporation Watson API サービスの特徴 7東京ソフトウェア&システム開発研究所 豊富なラインナップ –言語、画像、音声、探索などの API –他の Bluemix サービスと組み合わせ シンプルな利用環境 –IBM Bluemix でのサービス管理 –REST API によるアクセス 充実した開発リソース –Watson Developer Cloud でのドキュメントやデモの公開 • https://www.ibm.com/watson/developer/ –GitHubでのライブラリやサンプルコードの提供 • https://github.com/watson-developer-cloud パブリッククラウド –インターネット経由でアクセス可能 –Bluemix でのアプリケーション開発も可能 言語 画像音声 分析
8.
© 2017 International
Business Machines Corporation Watson APIサービスの種類 8東京ソフトウェア&システム開発研究所 言語処理 検索分析 音声処理 画像認識 Personality Insights テキストから筆者の性格を推定する Language Translator(一部日本語未対応) ※1 自然言語テキストについて他言語へ翻訳を行う Conversation アプリケーションに自然言語インターフェース を追加してエンドユーザとのやり取りを自動化 Natural Language Understanding(日本語未対応) 自然言語処理を通じてキーワード抽出、エンティテ ィー抽出、心情分析、感情分析、概念タグ付け、関 係抽出、分類法種別、作成者抽出などを行う Text to Speech テキスト文章を音声に変換する Speech to Text 音声をテキスト文章に変換する Visual Recognition 画像コンテンツに含まれる意味を検出する Natural Language Classifier テキスト文章の分類を行う(質問の意図推定など) Tone Analyzer(日本語未対応) テキストの感情、社交性、文体を解析する Retrieve and Rank 自然言語の質問に対して回答の候補を返す Document Conversion 文書を新しい形式に変換する Discovery(日本語未対応) 認知検索およびコンテンツ分析エンジンをアプリケーションに追加して、優れた意思決定を行うのに 役立つパターン、傾向、およびアクション可能な洞察を識別する Discovery News(日本語未対応) Discovery Service上に実装され、エンリッチ情報も付加されたニュースに関する公開データセット https://www.ibm.com/watson/developercloud/services-catalog.html ※1 Language Translatorはニュースドメインのみ日本語対応 2017年8月現在の提供サービス
9.
活用想定例:仮想ショッピング店員 9 Speech to Textサービス •ユーザーの音声をテキストに変換し、 他のサービスの入力とする Conversation
サービス •短いテキストから意図を分類 「大きめのサイズはありますか」 「少し、小さいです」 「need-bigger-size」クラス に分類 •対話のフローを制御 •対話の中で引きだした情報を管理 服のサイズ、好みの色など Text to Speechサービス •アプリケーションからの応答から 音声を合成して、ユーザーに出力する 使用しているサービス お客様は音声でリクエストし、 Watson も音声で回答します。
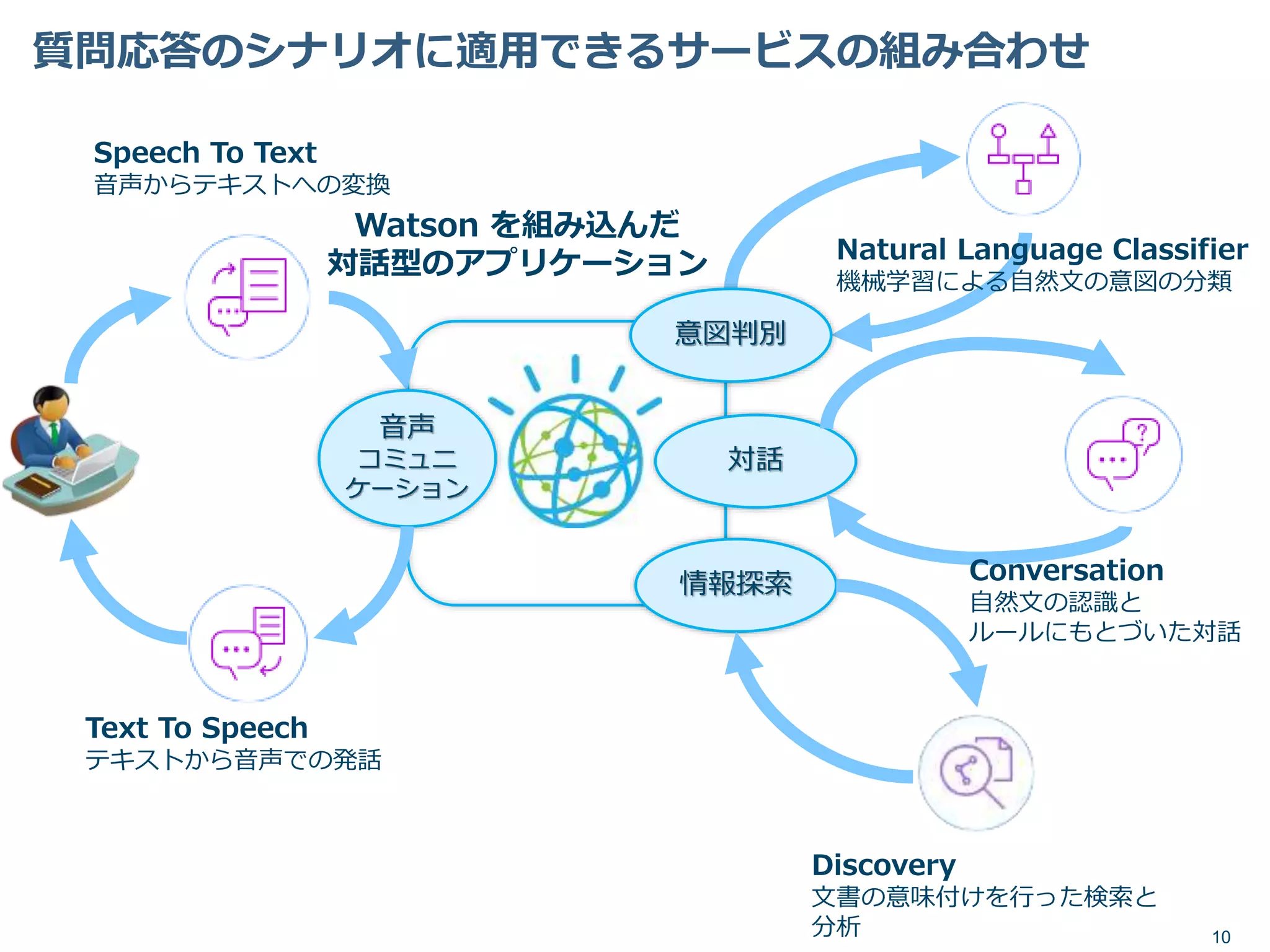
10.
質問応答のシナリオに適用できるサービスの組み合わせ 10 対話 情報探索 音声 コミュニ ケーション Discovery 文書の意味付けを行った検索と 分析 Natural Language Classifier 機械学習による自然文の意図の分類 Text
To Speech テキストから音声での発話 Speech To Text 音声からテキストへの変換 Watson を組み込んだ 対話型のアプリケーション 意図判別 Conversation 自然文の認識と ルールにもとづいた対話
11.
© 2017 International
Business Machines Corporation 活用想定例:カスタマーケア・アシスタント パーソナリティー 検索 問合せ履歴 ジャック フロスト 顧客NO: 0011 電話番号: 080-xxx-xxx メール: jack@example.com Twitter: @jackfrost 類似するお客様の問合せTop5 タイトル カテゴリー 日付 支払い方法について 支払 2015-01-23 充電が出来ない 故障 2015-03-15 家族プランの問合せ プラン 2015-04-04 現在、B社と契約中のお子様の電話代が安くならないかの相談を受けまし た。家族プランをご紹介 1. 家族割について 2. プランの変更 3. 割引適用条件について 4. 電源の入れ方 5. 充電の仕方 類似するお客様 東京ソフトウェア&システム開発研究所 11
12.
© 2017 International
Business Machines Corporation Watsonの言語処理サービス 東京ソフトウェア&システム開発研究所 12 Natural Language Understanding (日本語未対応) Natural Language Classifier Discovery (日本語未対応) Conversation Personality Insights Tone Analyzer (日本語未対応)
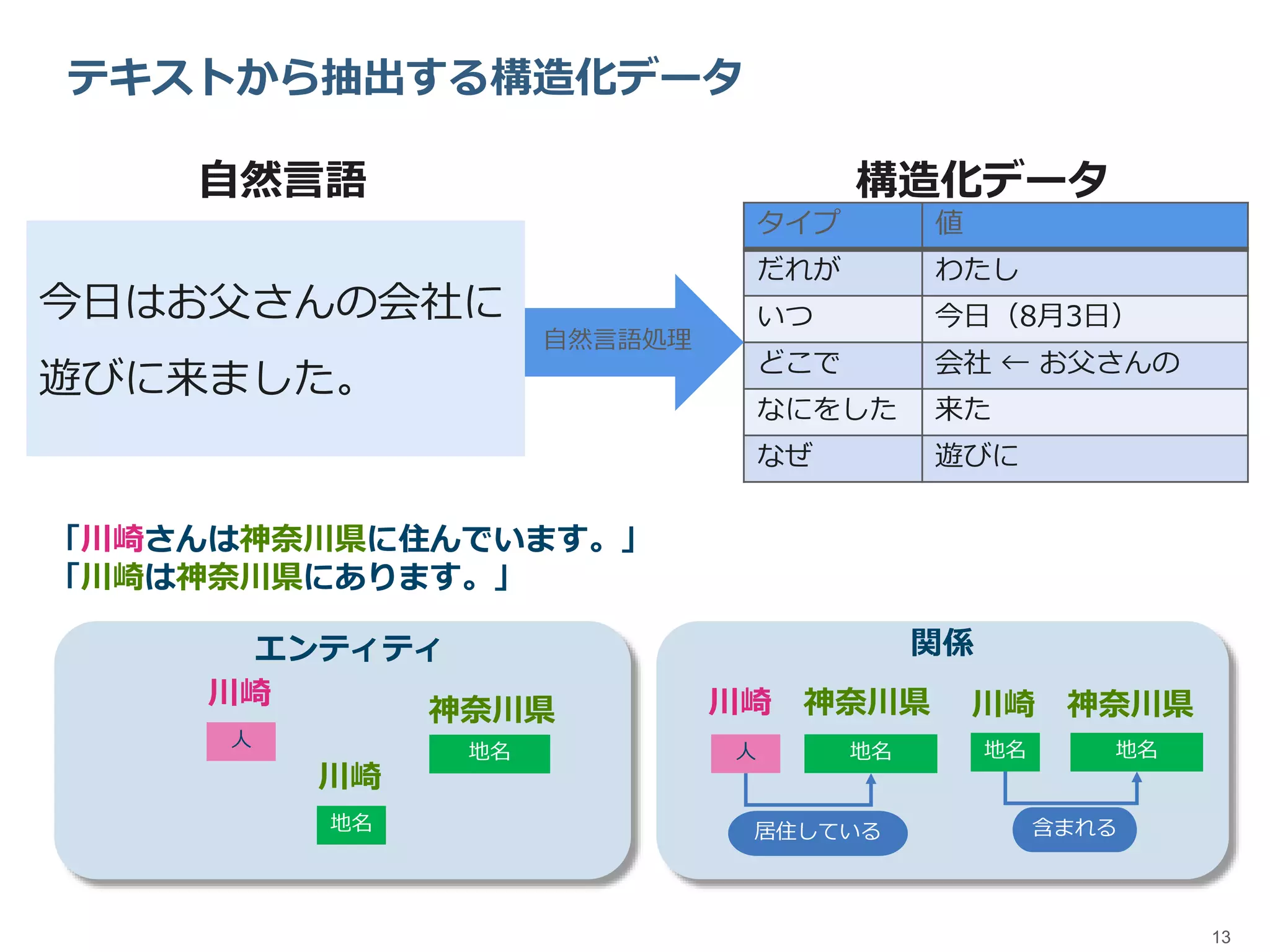
13.
13 テキストから抽出する構造化データ 自然言語 今日はお父さんの会社に 遊びに来ました。 タイプ 値 だれが わたし いつ
今日(8月3日) どこで 会社 ← お父さんの なにをした 来た なぜ 遊びに 構造化データ 自然言語処理 「川崎さんは神奈川県に住んでいます。」 「川崎は神奈川県にあります。」 人 川崎 地名 川崎 地名 神奈川県 人 川崎 神奈川県 地名 地名地名 川崎 神奈川県 居住している 含まれる エンティティ 関係
14.
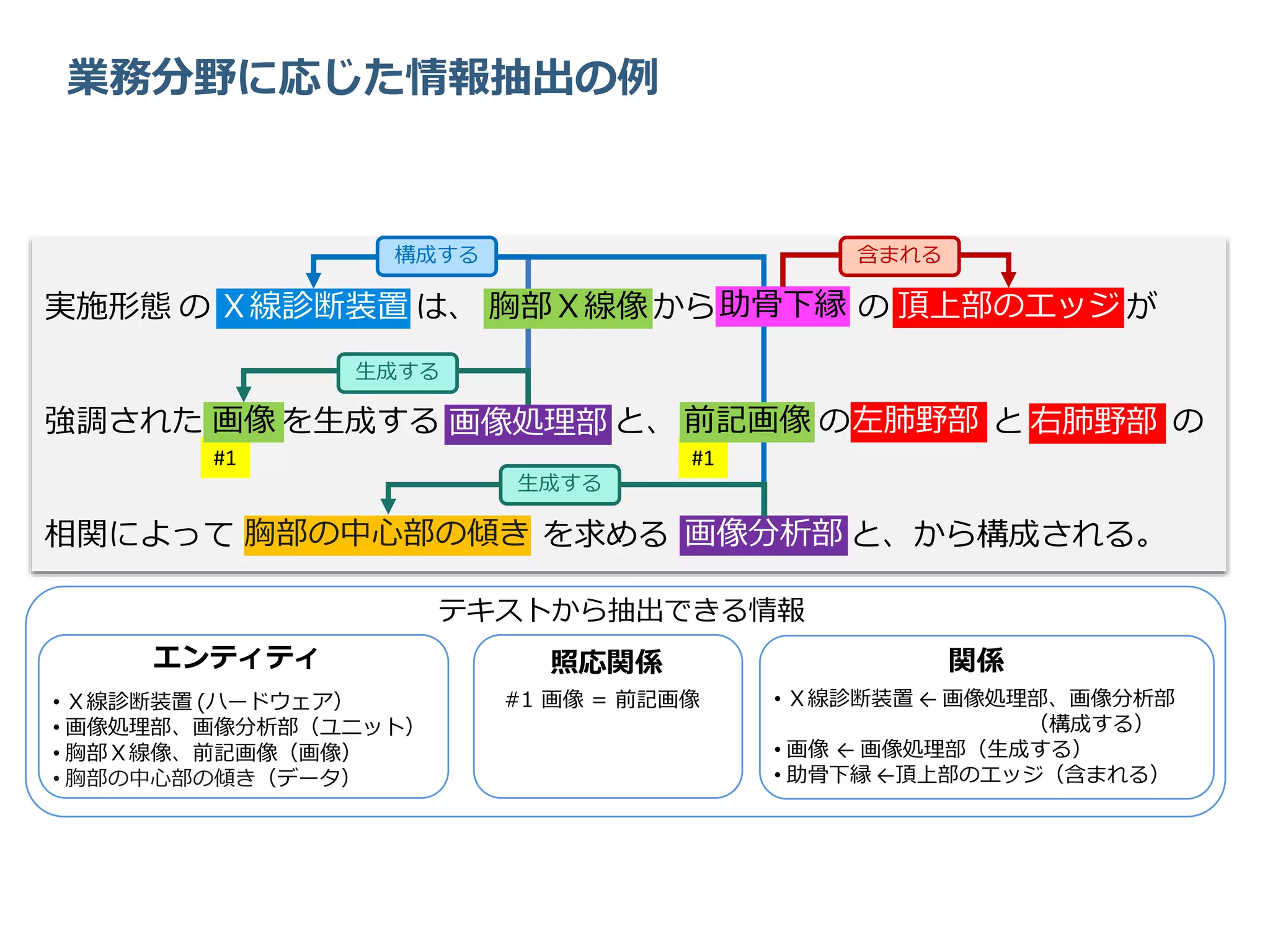
業務分野に応じた情報抽出の例 この文章から抽出したい情報 • 構成するハードウエアやユニット • 対象となる部位 •
生成される画像やデータ 分析したい用語や関係に応じた 業務分野の情報抽出器が必要! 実施形態 の X線診断装置 は、 胸部X線像 から 助骨下縁 の 頂上部のエッジ が 強調された 画像 を生成する 画像処理部 と、 前記画像 の 左肺野部 と 右肺野部 の 相関によって 胸部の中心部の傾き を求める 画像分析部 と、から構成される。
15.
業務分野に応じた情報抽出の例 実施形態 の X線診断装置
は、 胸部X線像 から 助骨下縁 の 頂上部のエッジ が 強調された 画像 を生成する 画像処理部 と、 前記画像 の 左肺野部 と 右肺野部 の 相関によって 胸部の中心部の傾き を求める 画像分析部 と、から構成される。画像分析部胸部の中心部の傾き #1#1 前記画像画像 画像処理部 左肺野部 右肺野部 X線診断装置 胸部X線像 頂上部のエッジ助骨下縁 エンティティ • X線診断装置 (ハードウェア) • 画像処理部、画像分析部(ユニット) • 胸部X線像、前記画像(画像) • 胸部の中心部の傾き(データ) 関係 • X線診断装置 ← 画像処理部、画像分析部 (構成する) • 画像 ← 画像処理部(生成する) • 助骨下縁 ←頂上部のエッジ(含まれる) 照応関係 #1 画像 = 前記画像 テキストから抽出できる情報 構成する 生成する 生成する 含まれる
16.
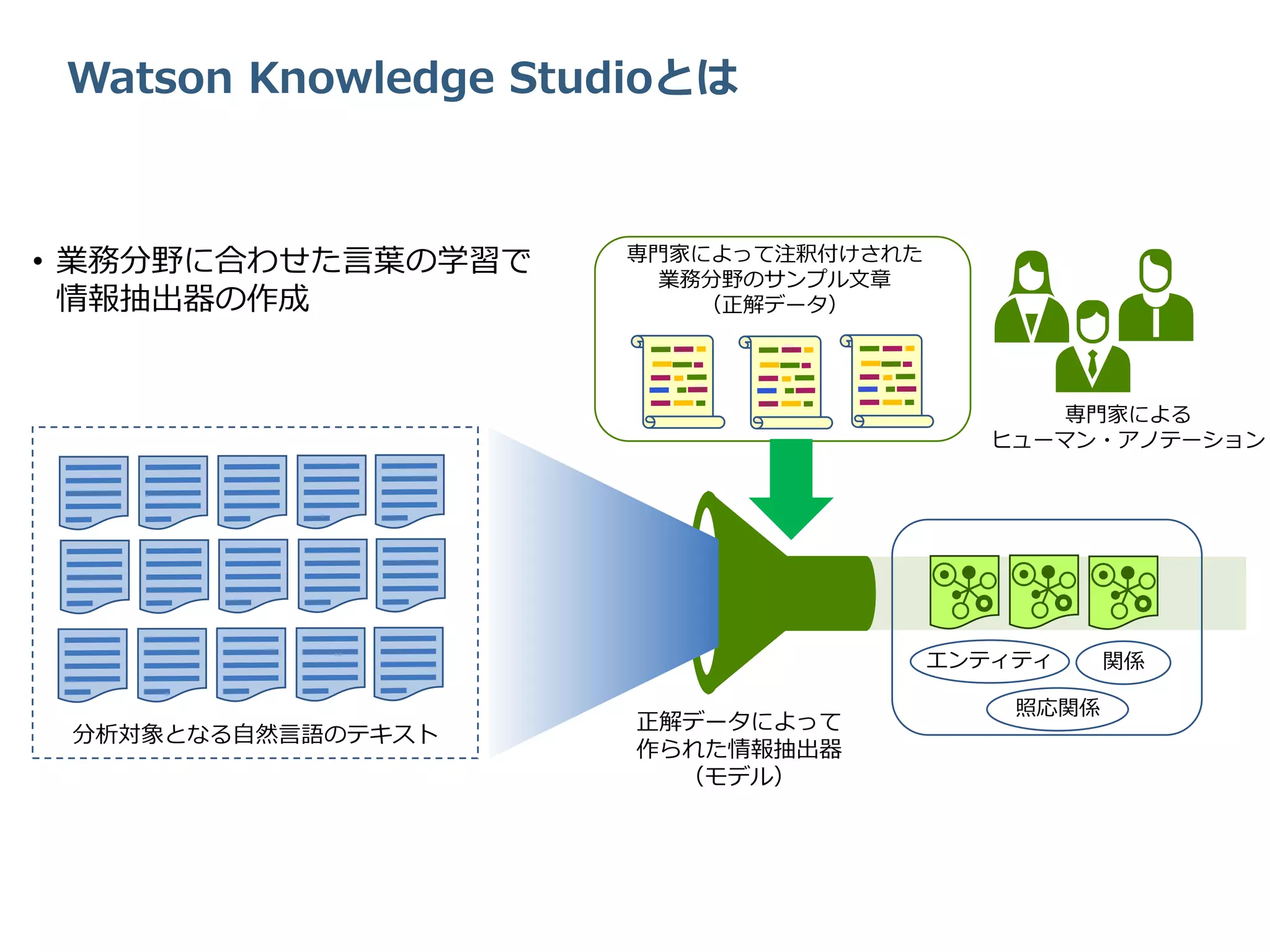
Watson Knowledge Studioとは エンティティ
関係 照応関係 正解データによって 作られた情報抽出器 (モデル) 専門家によって注釈付けされた 業務分野のサンプル文章 (正解データ) 分析対象となる自然言語のテキスト 専門家による ヒューマン・アノテーション • 業務分野に合わせた言葉の学習で 情報抽出器の作成
17.
© 2017 International
Business Machines Corporation Natural Language Understanding (日本語未対応) 17
18.
© 2017 International
Business Machines Corporation Natural Language Understanding 東京ソフトウェア&システム開発研究所 18 自然言語のテキストを分析し、エンティティーやその関係と いった構造化データ、キーワード、カテゴリー、コンセプト、 好感度や喜怒哀楽のような感情、意味役割、メタデータを抽 出します。 –内蔵する自然言語処理モデルは学習済で、追加学習なしで解析結果を取得 できる。 –Watson Knowledge Studioによって業務分野特有のエンティティティや 関係を学習させることも可能。
19.
© 2017 International
Business Machines Corporation Natural Language Understanding での 自然言語テキストの分析項目 19東京ソフトウェア&システム開発研究所 分析項目 説明 エンティティ Entities 入力テキストに含まれる人物、場所、組織などのアイテムを抽出。 関係 Relations 入力テキストの文中の主題、動作、および対象物の関係を識別。 キーワード Keywords 入力テキストに含まれる主要な用語を抽出。 カテゴリ分類 Categories 入力されたコンテンツを最大5レベルの階層分類に分類し、その分類結果を3 つ返します。 コンセプト Concepts テキストに含まれる概念やエンティティから関連するコンセプトを識別。 テキストで直接参照されていない概念を識別することが可能。 感情(好感度) Sentiment コンテンツ全体やエンティティのレベルで好意的か否定的かの度合いを分析。 感情(喜怒哀楽) Emotion コンテンツで示される怒り、嫌悪感、恐怖、喜び、悲しみを検出。 主題役割 Semantic Roles Parse sentences into subject-action-object form, and identify entities and keywords that are subjects or objects of an action. メタデータ Metadata For HTML and URL input, get the author of the webpage, the page title, and the publication date.
20.
© 2017 International
Business Machines Corporation Natural Language Understanding - デモ 東京ソフトウェア&システム開発研究所 20 URL –https://natural-language-understanding-demo.mybluemix.net/ 入力テキストを分析します。
21.
© 2017 International
Business Machines Corporation Natural Language Classifier 東京ソフトウェア&システム開発研究所 21
22.
© 2017 International
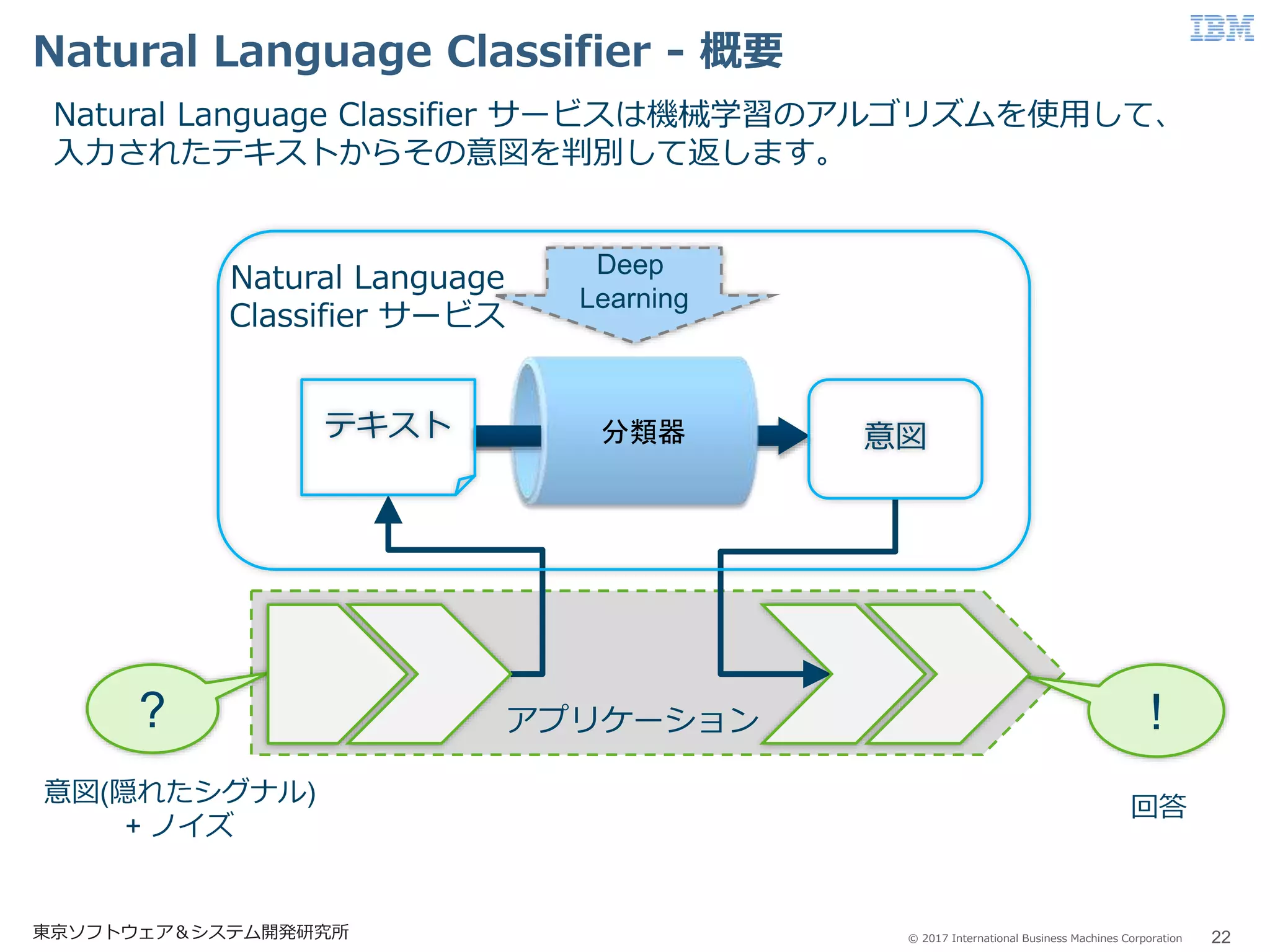
Business Machines Corporation Natural Language Classifier - 概要 22東京ソフトウェア&システム開発研究所 Natural Language Classifier サービスは機械学習のアルゴリズムを使用して、 入力されたテキストからその意図を判別して返します。 アプリケーション Deep Learning ? ! 意図(隠れたシグナル) + ノイズ 分類器 意図テキスト 回答 Natural Language Classifier サービス
23.
© 2017 International
Business Machines Corporation Natural Language Classifier - 概要 東京ソフトウェア&システム開発研究所 23 意図とは –言語に含まれるノイズを取り除いて、それが何を言おうとしているか、あ るいは何を聞こうとしているのかということ –例: • 「銀行口座はどうやって開けますか?」 • 「銀行で口座を開くために必要なものを教えてください。」 どちらの質問も「銀行で口座を開く」と言う同じ意図を持っている。 しくみ –あらかじめ大量の文章を読み込みこんで、自然言語の基礎知識(base knowledge)を持つ。 –適用業務分野 に応じた分類済のサンプルのテキストを集めたトレーニン グデータで学習し、学習モデル(分類器)を作成。 –分類器は、新たなテキストを分類してその意図を認識。
24.
© 2017 International
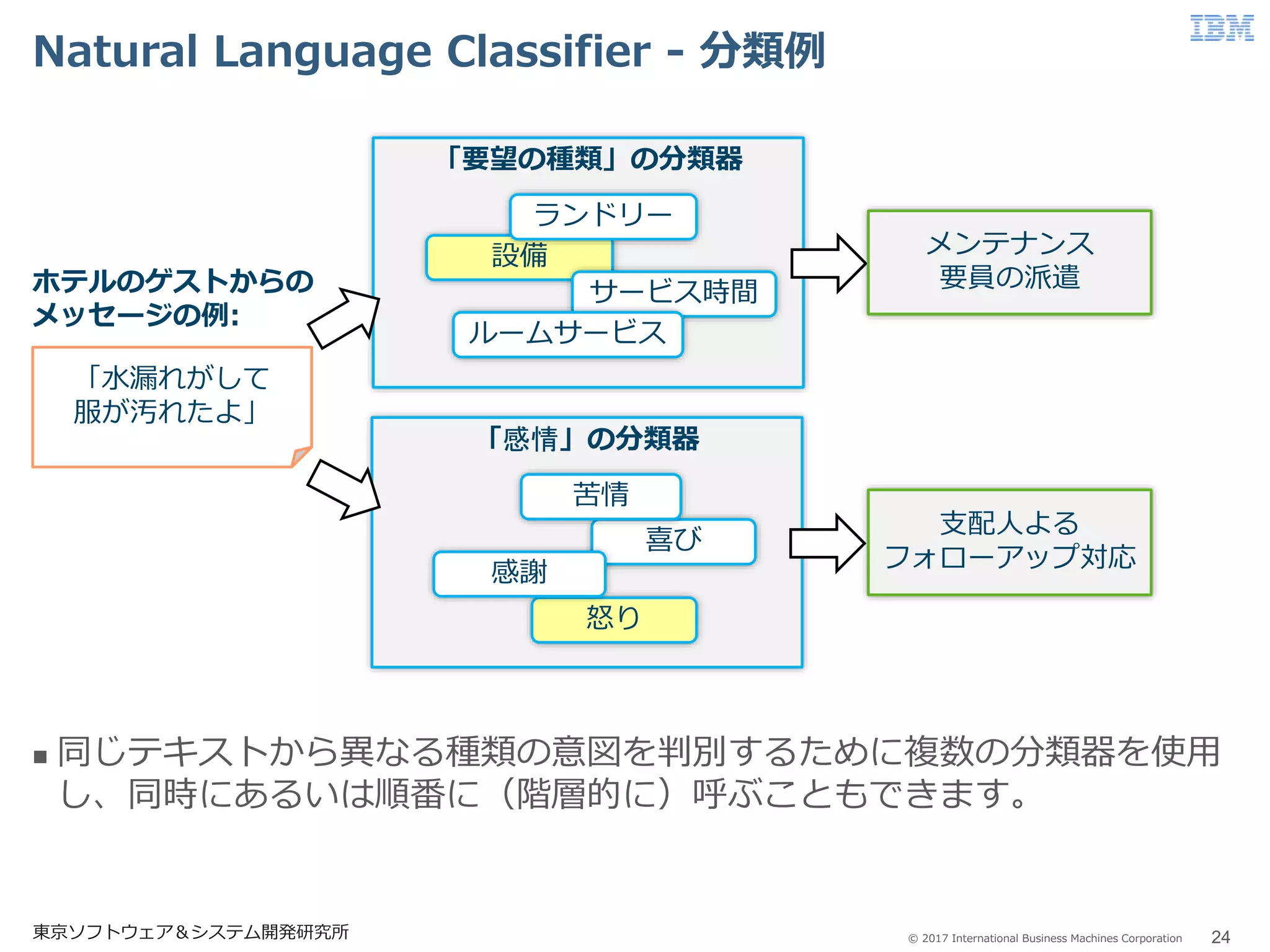
Business Machines Corporation Natural Language Classifier - 分類例 24東京ソフトウェア&システム開発研究所 同じテキストから異なる種類の意図を判別するために複数の分類器を使用 し、同時にあるいは順番に(階層的に)呼ぶこともできます。 「要望の種類」の分類器 「水漏れがして 服が汚れたよ」 メンテナンス 要員の派遣 支配人よる フォローアップ対応 ホテルのゲストからの メッセージの例: 設備 サービス時間 ルームサービス ランドリー 「感情」の分類器 怒り 喜び 感謝 苦情
25.
© 2017 International
Business Machines Corporation Natural Language Classifier - 利用シーン 東京ソフトウェア&システム開発研究所 25 質問に回答するシナリオ → ユーザーからの質問の内容を分類しその回答を提供する。 仮想エージェントによるユーザー支援 → 問合せに対して顧客の状況や求めるものを特定して対応する ツィッター/SMS メッセージの分類 → ツィッターのメッセージの意図をくみ取りアラートをあげる。 感情分析 → メッセージに含まれるその人の感情を特定して情報として提供する。
26.
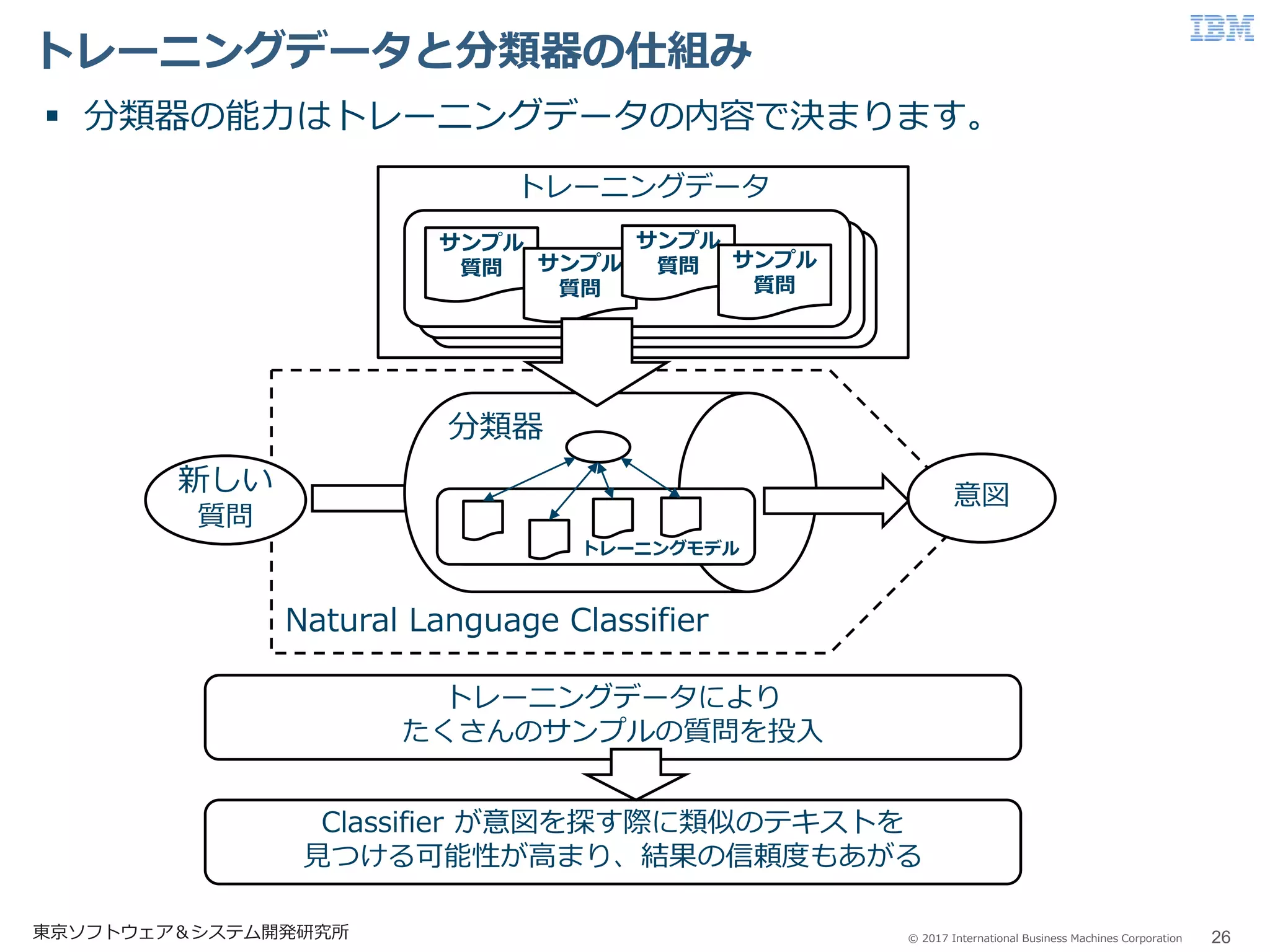
© 2017 International
Business Machines Corporation トレーニングデータと分類器の仕組み 26東京ソフトウェア&システム開発研究所 トレーニングデータにより たくさんのサンプルの質問を投入 Classifier が意図を探す際に類似のテキストを 見つける可能性が高まり、結果の信頼度もあがる Natural Language Classifier 意図 分類器の能力はトレーニングデータの内容で決まります。 トレーニングデータ サンプル 質問 サンプル 質問 サンプル 質問 サンプル 質問 新しい 質問 トレーニングモデル 分類器
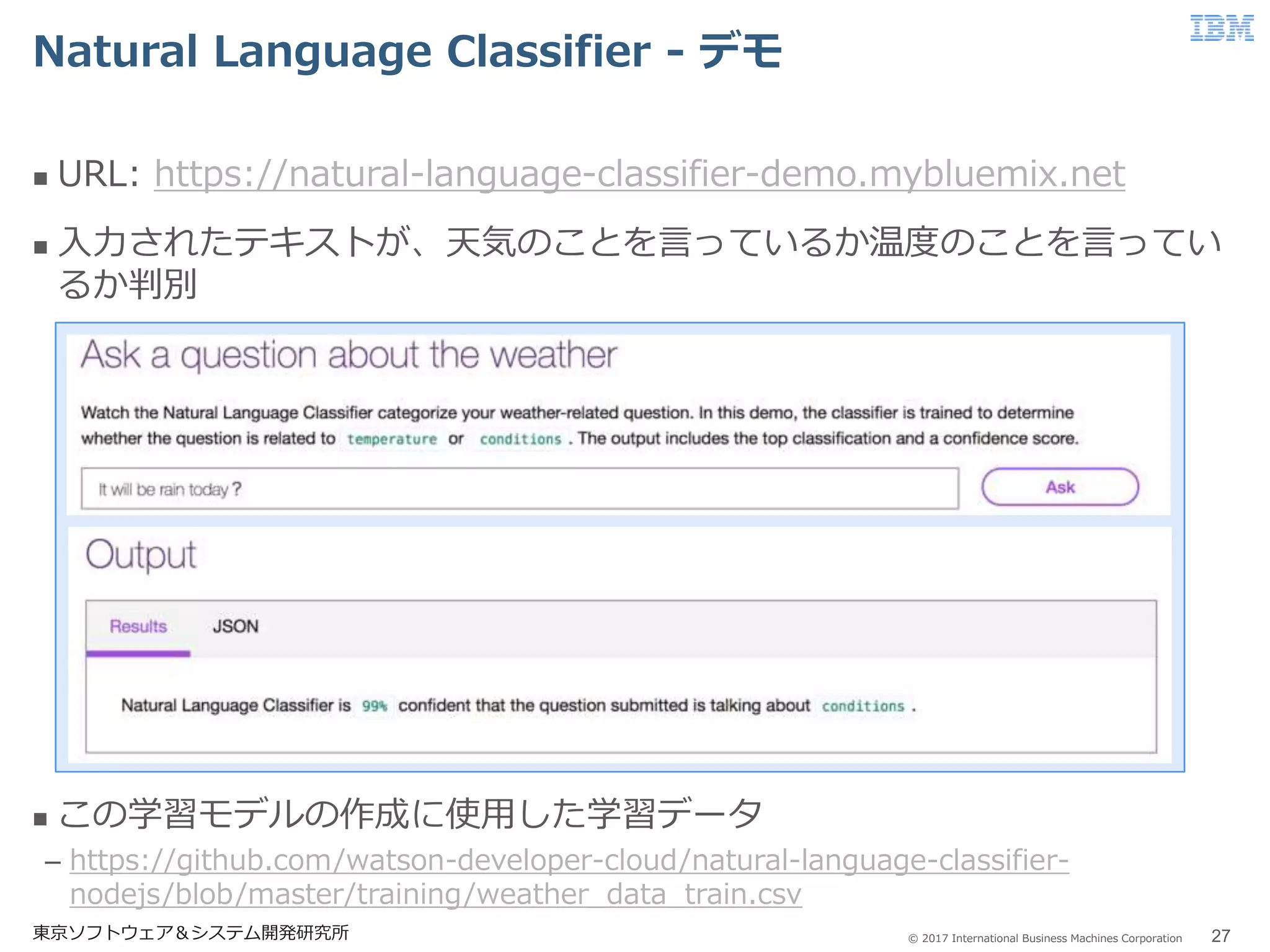
27.
© 2017 International
Business Machines Corporation Natural Language Classifier - デモ 東京ソフトウェア&システム開発研究所 27 URL: https://natural-language-classifier-demo.mybluemix.net 入力されたテキストが、天気のことを言っているか温度のことを言ってい るか判別 この学習モデルの作成に使用した学習データ – https://github.com/watson-developer-cloud/natural-language-classifier- nodejs/blob/master/training/weather_data_train.csv
28.
© 2017 International
Business Machines Corporation 質問応答サービスとしてのWatson 東京ソフトウェア&システム開発研究所 28
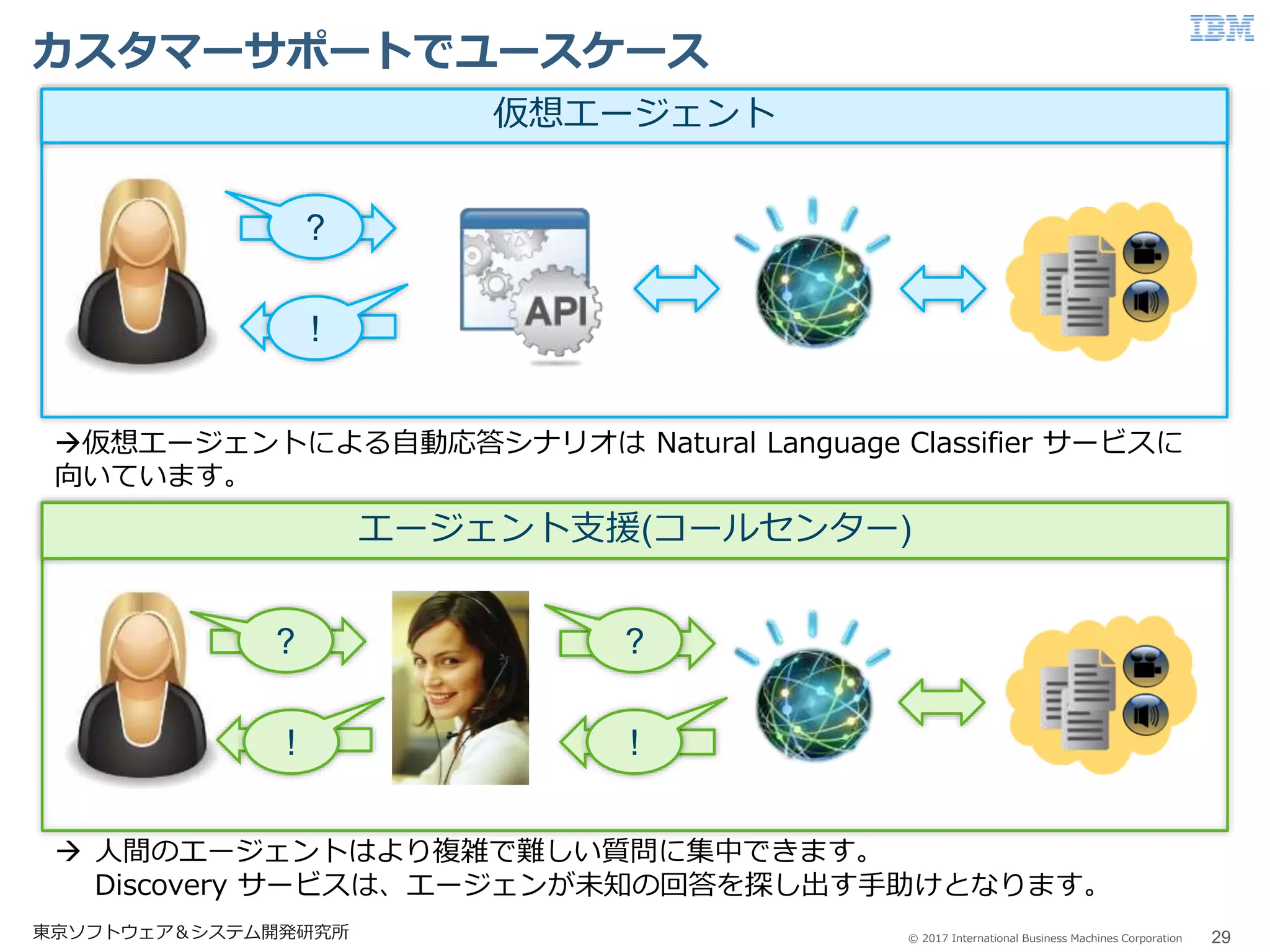
29.
© 2017 International
Business Machines Corporation カスタマーサポートでユースケース 29東京ソフトウェア&システム開発研究所 ? ! 仮想エージェント ? ! ? ! エージェント支援(コールセンター) 仮想エージェントによる自動応答シナリオは Natural Language Classifier サービスに 向いています。 人間のエージェントはより複雑で難しい質問に集中できます。 Discovery サービスは、エージェンが未知の回答を探し出す手助けとなります。
30.
© 2017 International
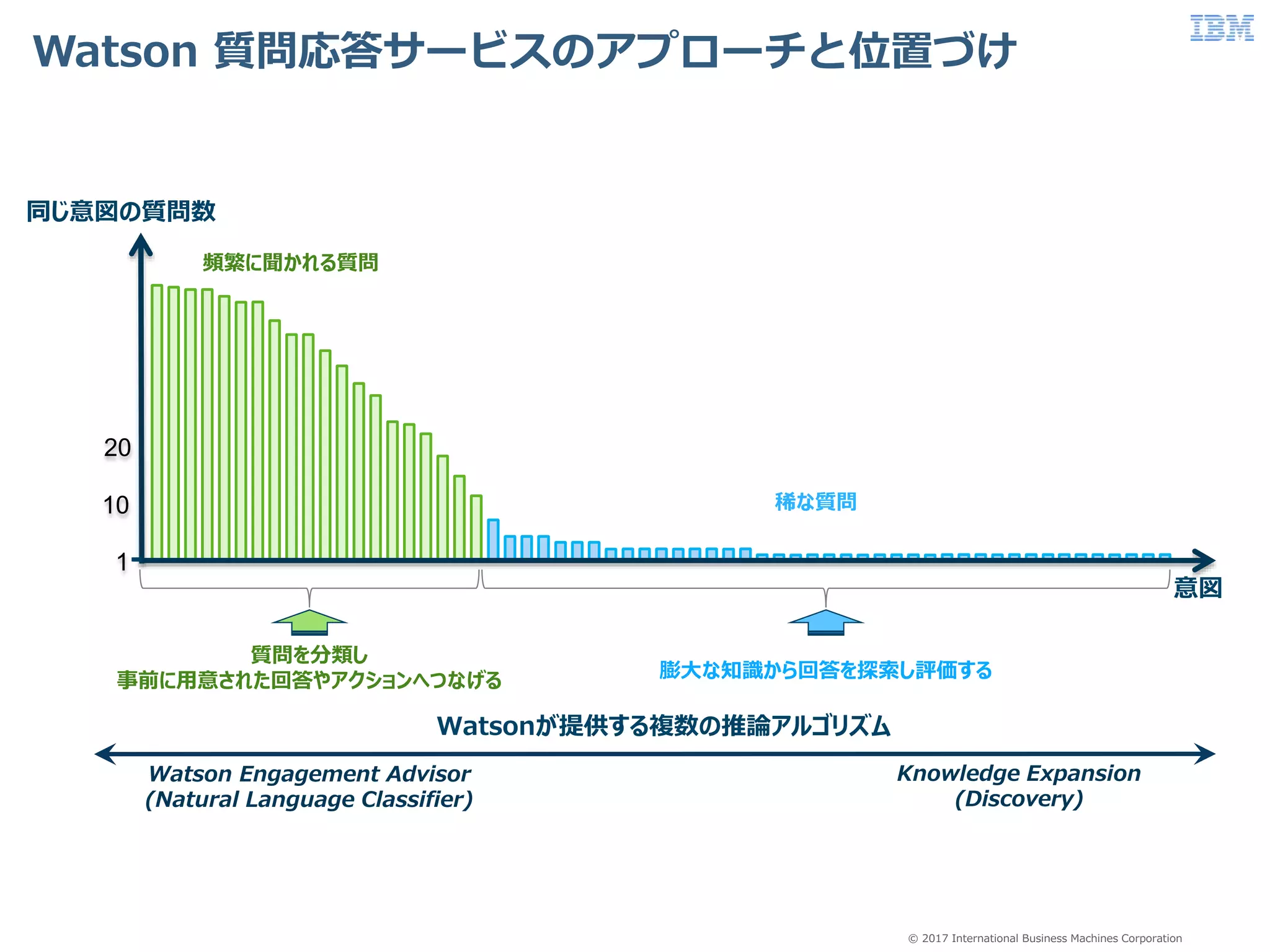
Business Machines Corporation Watson 質問応答サービスのアプローチと位置づけ 意図 同じ意図の質問数 1 10 20 頻繁に聞かれる質問 稀な質問 質問を分類し 事前に用意された回答やアクションへつなげる 膨大な知識から回答を探索し評価する Watsonが提供する複数の推論アルゴリズム Watson Engagement Advisor (Natural Language Classifier) Knowledge Expansion (Discovery)
31.
© 2017 International
Business Machines Corporation Watson の言語処理サービス 東京ソフトウェア&システム開発研究所 31 Natural Language Classifier –入力テキスト含まれる発言者の意図を解釈して分類します。この分類結果 をもとに、質問に回答したり要求を対応したりするなどのアクションを取 ることができます。 –適用する業務分野に応じて作成した学習データによる機械学習で分類器 (学習モデル)が作られます。 Conversation –人間とシステムが対話するチャット・ボットを開発するプラットフォーム です。 Discovery –非構造化データである文書の中の情報を抽出し意味付け(エンリッチ化) をして、検索可能なデータとして保持します。 –簡易クエリ言語を使用して意味づけされた内容で検索や分析ができます。 –機械学習によって検索結果の最適化を行います。
32.
© 2017 International
Business Machines Corporation Conversation 32東京ソフトウェア&システム開発研究所
33.
© 2017 International
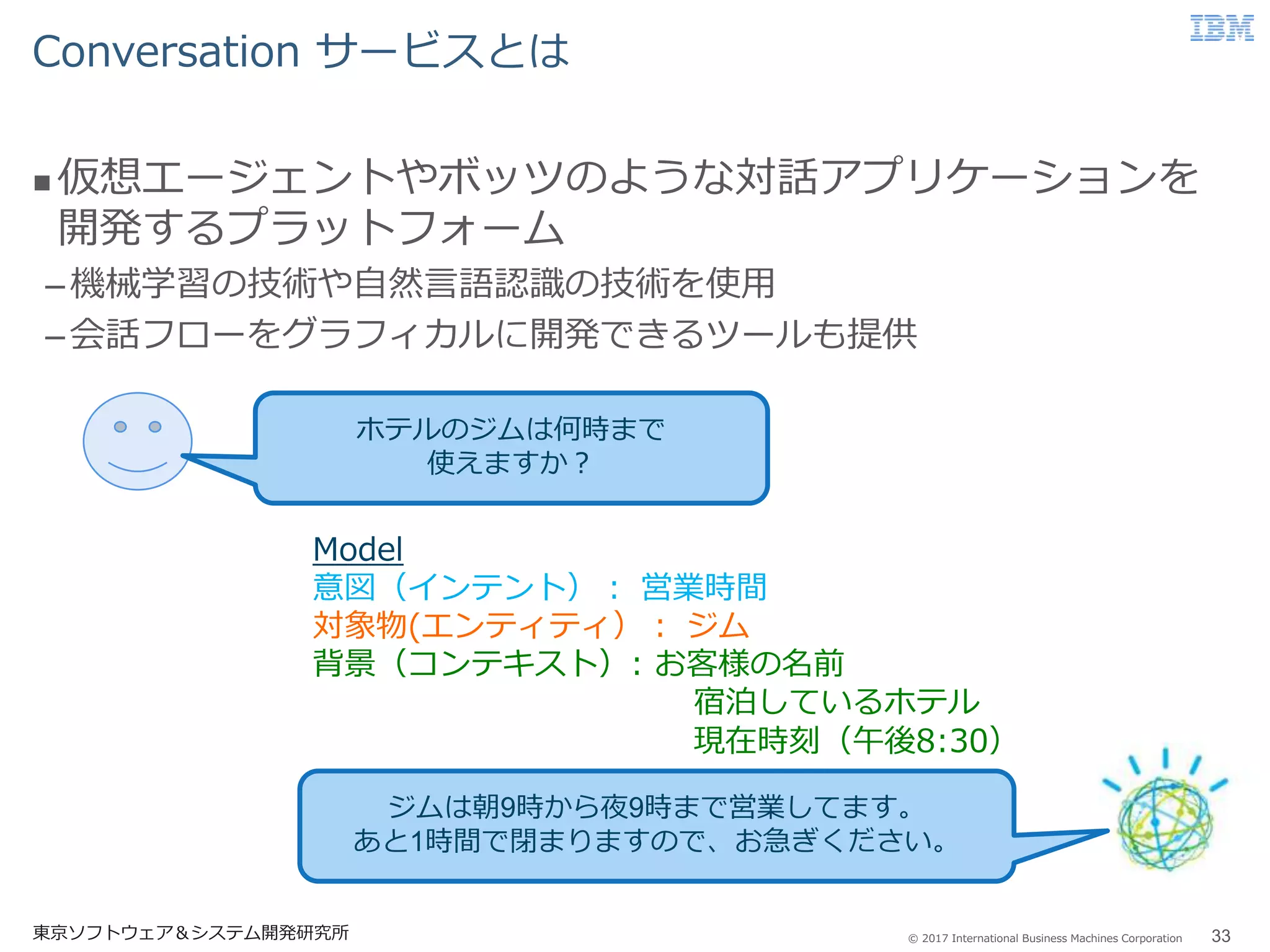
Business Machines Corporation Conversation サービスとは 東京ソフトウェア&システム開発研究所 33 仮想エージェントやボッツのような対話アプリケーションを 開発するプラットフォーム –機械学習の技術や自然言語認識の技術を使用 –会話フローをグラフィカルに開発できるツールも提供 ホテルのジムは何時まで 使えますか? ジムは朝9時から夜9時まで営業してます。 あと1時間で閉まりますので、お急ぎください。 Model 意図(インテント): 営業時間 対象物(エンティティ): ジム 背景(コンテキスト): お客様の名前 宿泊しているホテル 現在時刻(午後8:30)
34.
© 2017 International
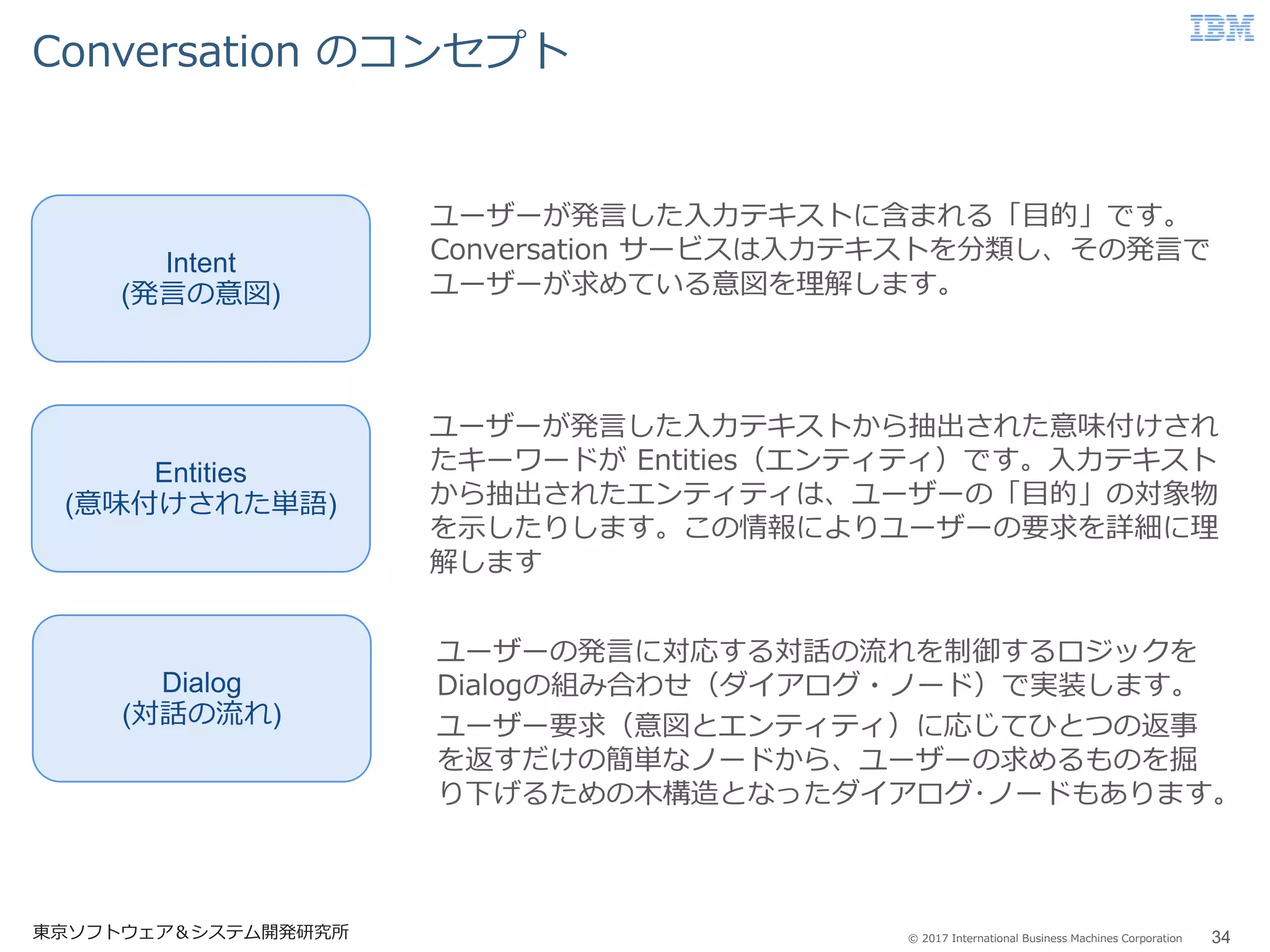
Business Machines Corporation Conversation のコンセプト 34東京ソフトウェア&システム開発研究所 Intent (発言の意図) Entities (意味付けされた単語) Dialog (対話の流れ) ユーザーが発言した入力テキストに含まれる「目的」です。 Conversation サービスは入力テキストを分類し、その発言で ユーザーが求めている意図を理解します。 ユーザーが発言した入力テキストから抽出された意味付けされ たキーワードが Entities(エンティティ)です。入力テキスト から抽出されたエンティティは、ユーザーの「目的」の対象物 を示したりします。この情報によりユーザーの要求を詳細に理 解します ユーザーの発言に対応する対話の流れを制御するロジックを Dialogの組み合わせ(ダイアログ・ノード)で実装します。 ユーザー要求(意図とエンティティ)に応じてひとつの返事 を返すだけの簡単なノードから、ユーザーの求めるものを掘 り下げるための木構造となったダイアログ・ノードもあります。
35.
© 2017 International
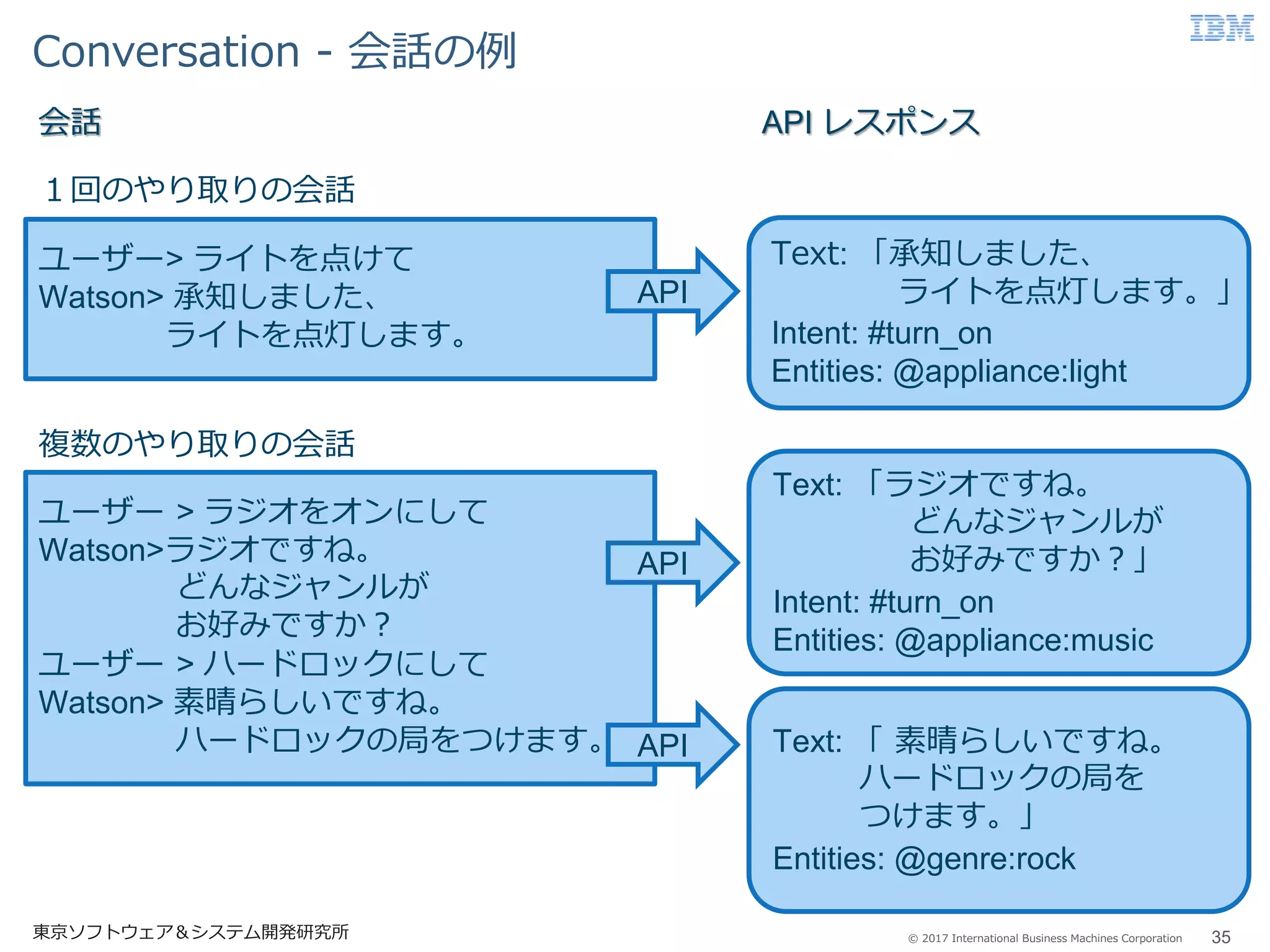
Business Machines Corporation Conversation - 会話の例 35東京ソフトウェア&システム開発研究所 ユーザー> ライトを点けて Watson> 承知しました、 ライトを点灯します。 1回のやり取りの会話 ユーザー > ラジオをオンにして Watson>ラジオですね。 どんなジャンルが お好みですか? ユーザー > ハードロックにして Watson> 素晴らしいですね。 ハードロックの局をつけます。 複数のやり取りの会話 Text: 「承知しました、 ライトを点灯します。」 Intent: #turn_on Entities: @appliance:light API Text: 「ラジオですね。 どんなジャンルが お好みですか?」 Intent: #turn_on Entities: @appliance:music API Text: 「 素晴らしいですね。 ハードロックの局を つけます。」 Entities: @genre:rock API API レスポンス会話
36.
© 2017 International
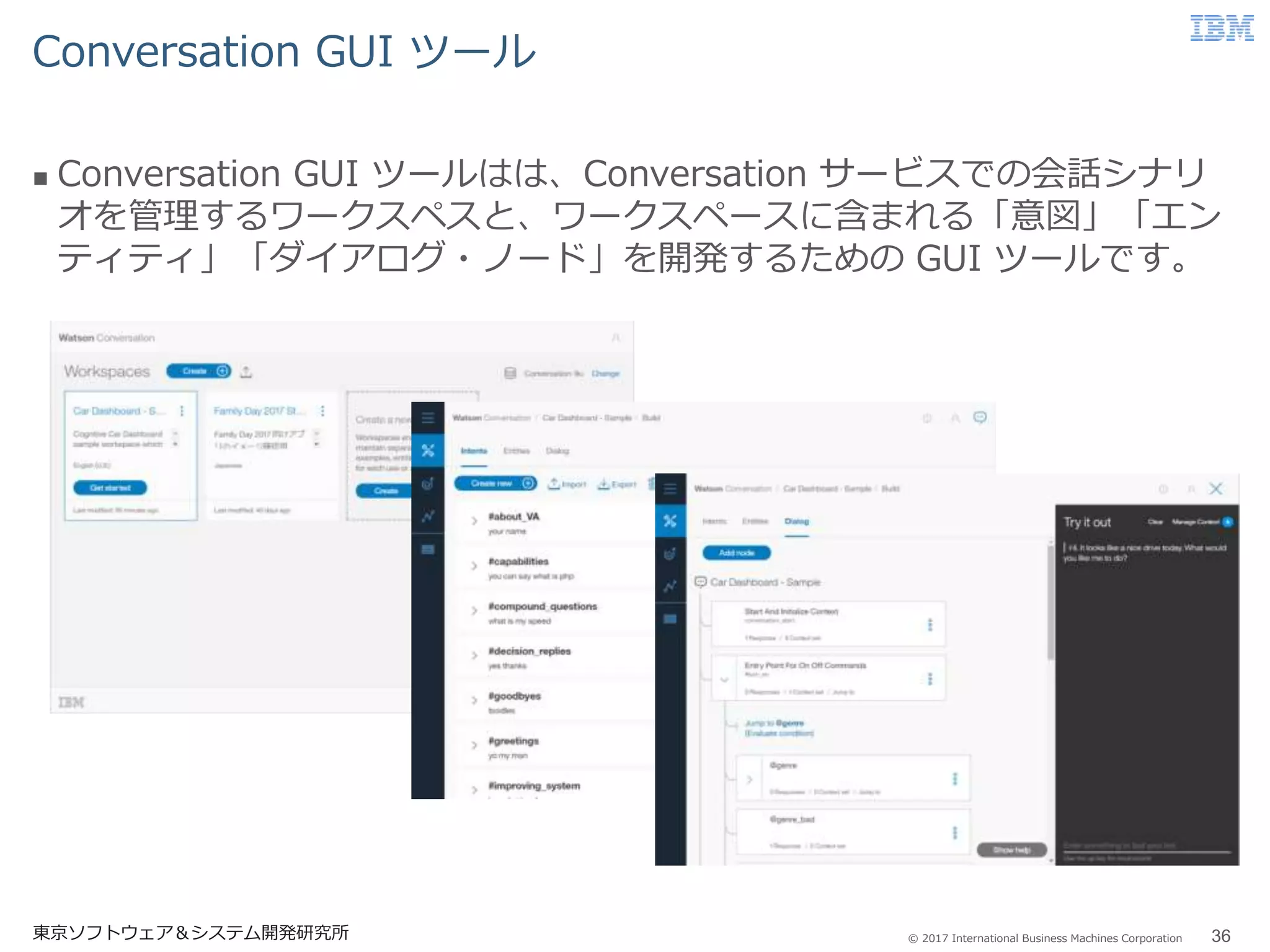
Business Machines Corporation Conversation GUI ツール 東京ソフトウェア&システム開発研究所 36 Conversation GUI ツールはは、Conversation サービスでの会話シナリ オを管理するワークスペスと、ワークスペースに含まれる「意図」「エン ティティ」「ダイアログ・ノード」を開発するための GUI ツールです。
37.
© 2017 International
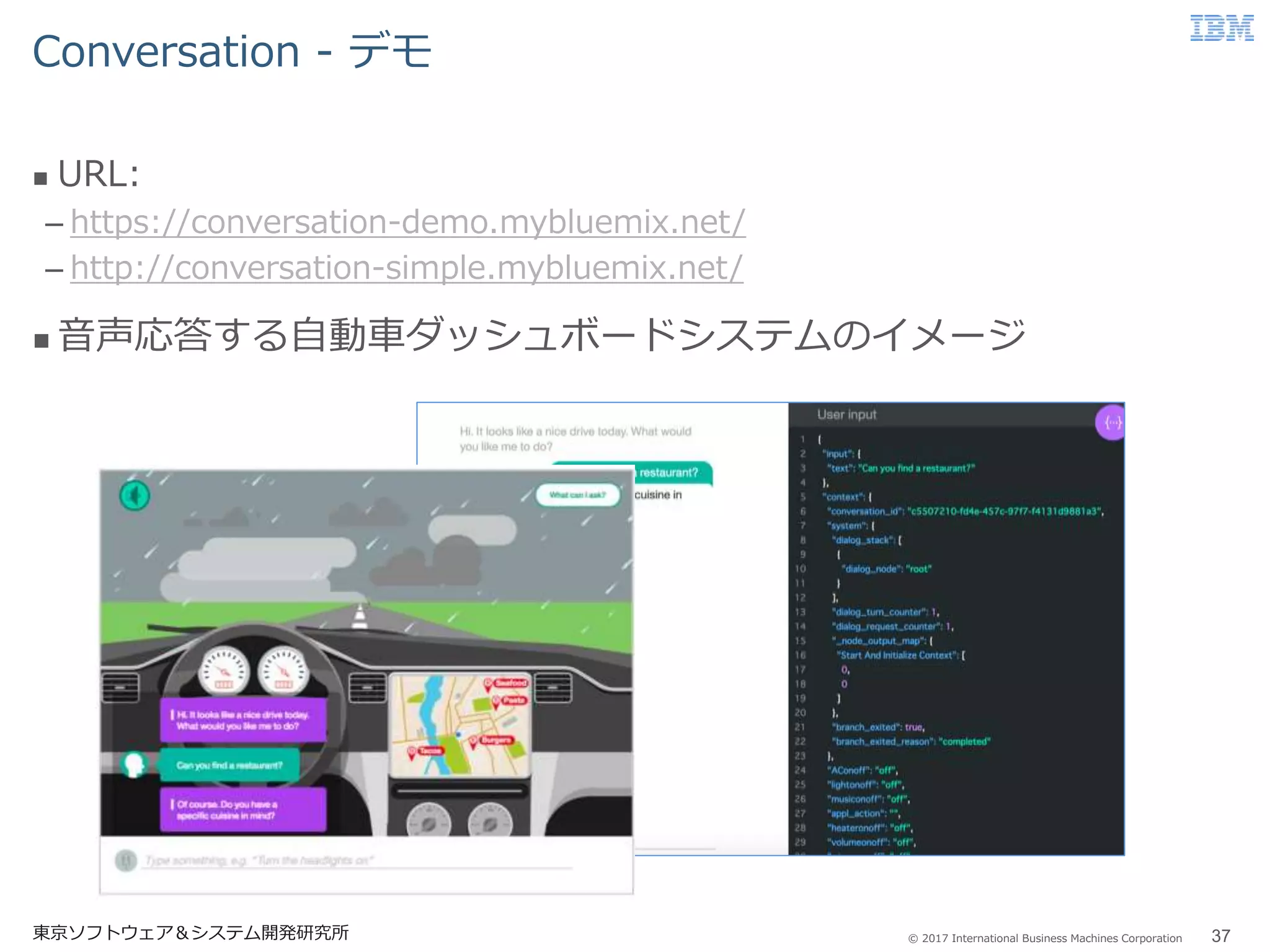
Business Machines Corporation Conversation - デモ 東京ソフトウェア&システム開発研究所 37 URL: – https://conversation-demo.mybluemix.net/ – http://conversation-simple.mybluemix.net/ 音声応答する自動車ダッシュボードシステムのイメージ
38.
© 2017 International
Business Machines Corporation Discovery (日本語未対応) 東京ソフトウェア&システム開発研究所 38
39.
© 2017 International
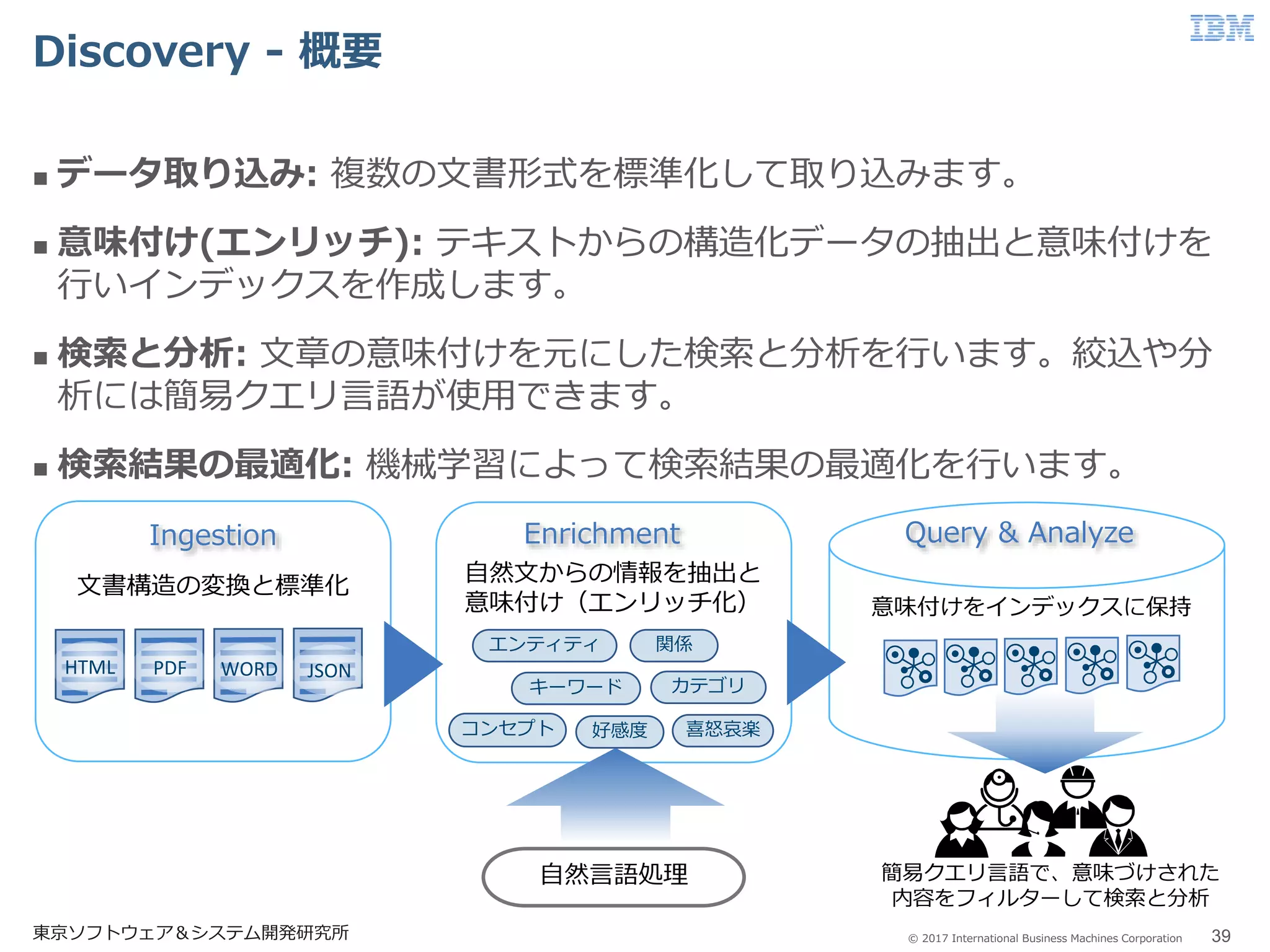
Business Machines Corporation Discovery - 概要 東京ソフトウェア&システム開発研究所 39 データ取り込み: 複数の文書形式を標準化して取り込みます。 意味付け(エンリッチ): テキストからの構造化データの抽出と意味付けを 行いインデックスを作成します。 検索と分析: 文章の意味付けを元にした検索と分析を行います。絞込や分 析には簡易クエリ言語が使用できます。 検索結果の最適化: 機械学習によって検索結果の最適化を行います。 簡易クエリ言語で、意味づけされた 内容をフィルターして検索と分析 文書構造の変換と標準化 HTML PDF WORD JSON 自然文からの情報を抽出と 意味付け(エンリッチ化) キーワード エンティティ カテゴリ コンセプト 関係 好感度 喜怒哀楽 意味付けをインデックスに保持 Ingestion Enrichment Query & Analyze 自然言語処理
40.
© 2017 International
Business Machines Corporation Discovery の意味付け(エンリッチ化) 40東京ソフトウェア&システム開発研究所 意味付けの項目 説明 エンティティ抽出 Entity extraction 入力テキストに含まれる人物、場所、組織などのアイテムを抽出。 関係抽出 Relation extraction 入力された内容の中の文中の主題、動作、および対象物の関係を識別。 キーワード抽出 Keyword extraction データのインデックス作成やタグクラウドの生成、あるいは検索の際に一般 的に使用される、コンテンツの重要なトピックを抽出。 カテゴリ分類 Taxonomy classification 入力されたコンテンツを最大5レベルの階層分類に分類します。 コンセプトタギング Concept tagging テキストに含まれる概念やエンティティから関連するコンセプトを識別。 テキストで直接参照されていない概念を識別することが可能。 感情(好感度)分析 Sentiment analysis コンテンツ全体やエンティティのレベルで好意的か否定的かの度合いを分析。 感情(喜怒哀楽)分析 Emotion analysis コンテンツで示される怒り、嫌悪感、恐怖、喜び、悲しみを検出。
41.
顧客サポート –日々増えてくる回答候補の文書資料の中で、顧客への回答を瞬時に探す必 要があります。 フィールドの技術者 –オンラインで技術情報の収集に利用します。
プロフェッショナル検索 –業務 に特化した検索 Discovery の典型的な利用例 41 2017/8/31
42.
© 2017 International
Business Machines Corporation Discovery News 東京ソフトウェア&システム開発研究所 42 Discovery の技術をもとに、世界のニュース記事を検索・分 析できるサービス –参照専用の公開コレクションでデータ登録の必要なしにすぐに活用可能 –Discoveryの使い方を習熟することができる –IBM が選定した10万のニュースソース –TOP 8000のニュースソースに関しては10分に1回クロール実施 –1日当たり30万件以上の記事
43.
© 2017 International
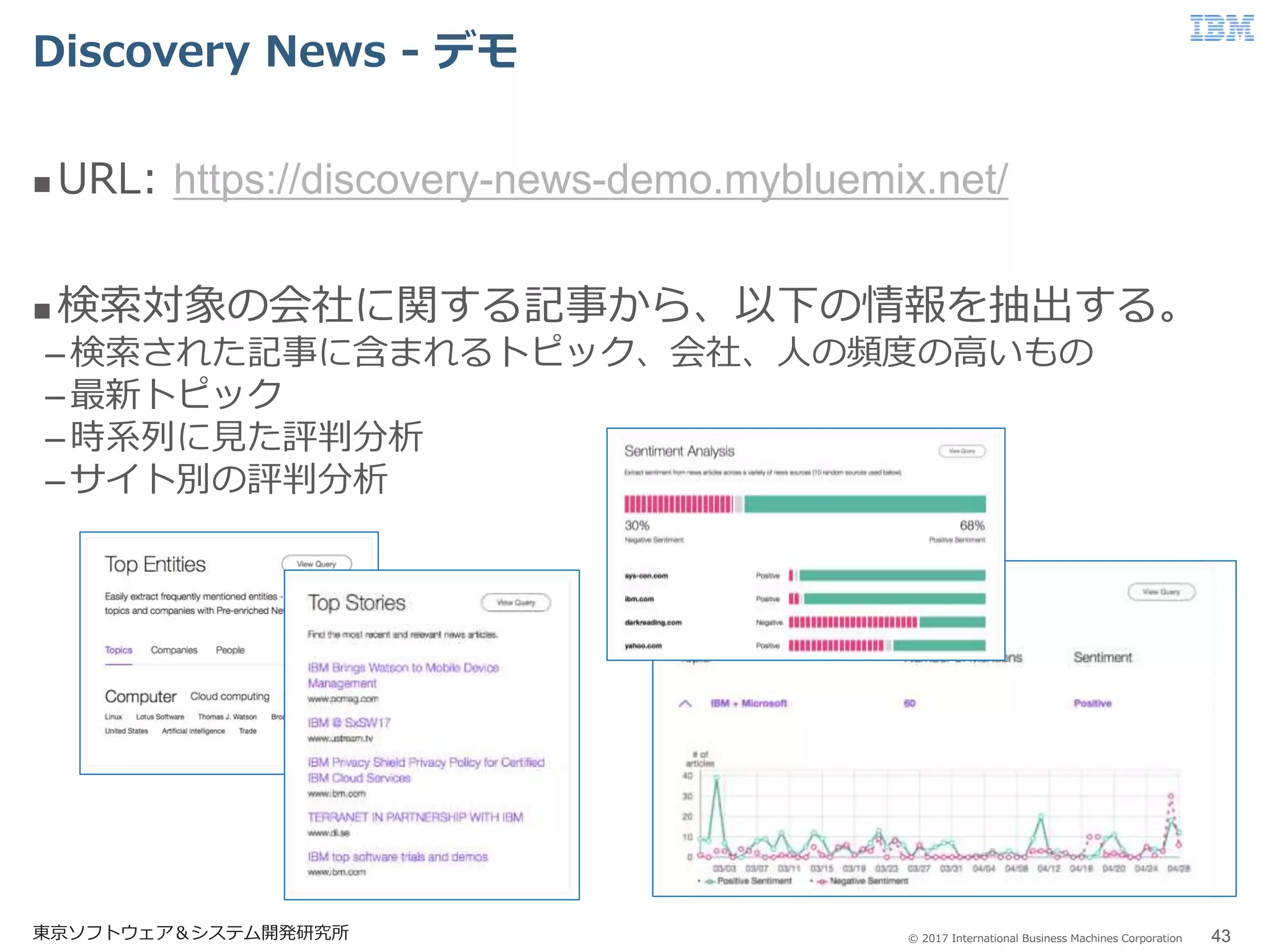
Business Machines Corporation Discovery News - デモ 東京ソフトウェア&システム開発研究所 43 URL: https://discovery-news-demo.mybluemix.net/ 検索対象の会社に関する記事から、以下の情報を抽出する。 –検索された記事に含まれるトピック、会社、人の頻度の高いもの –最新トピック –時系列に見た評判分析 –サイト別の評判分析
44.
© 2017 International
Business Machines Corporation Retrieve and Rank 東京ソフトウェア&システム開発研究所 44
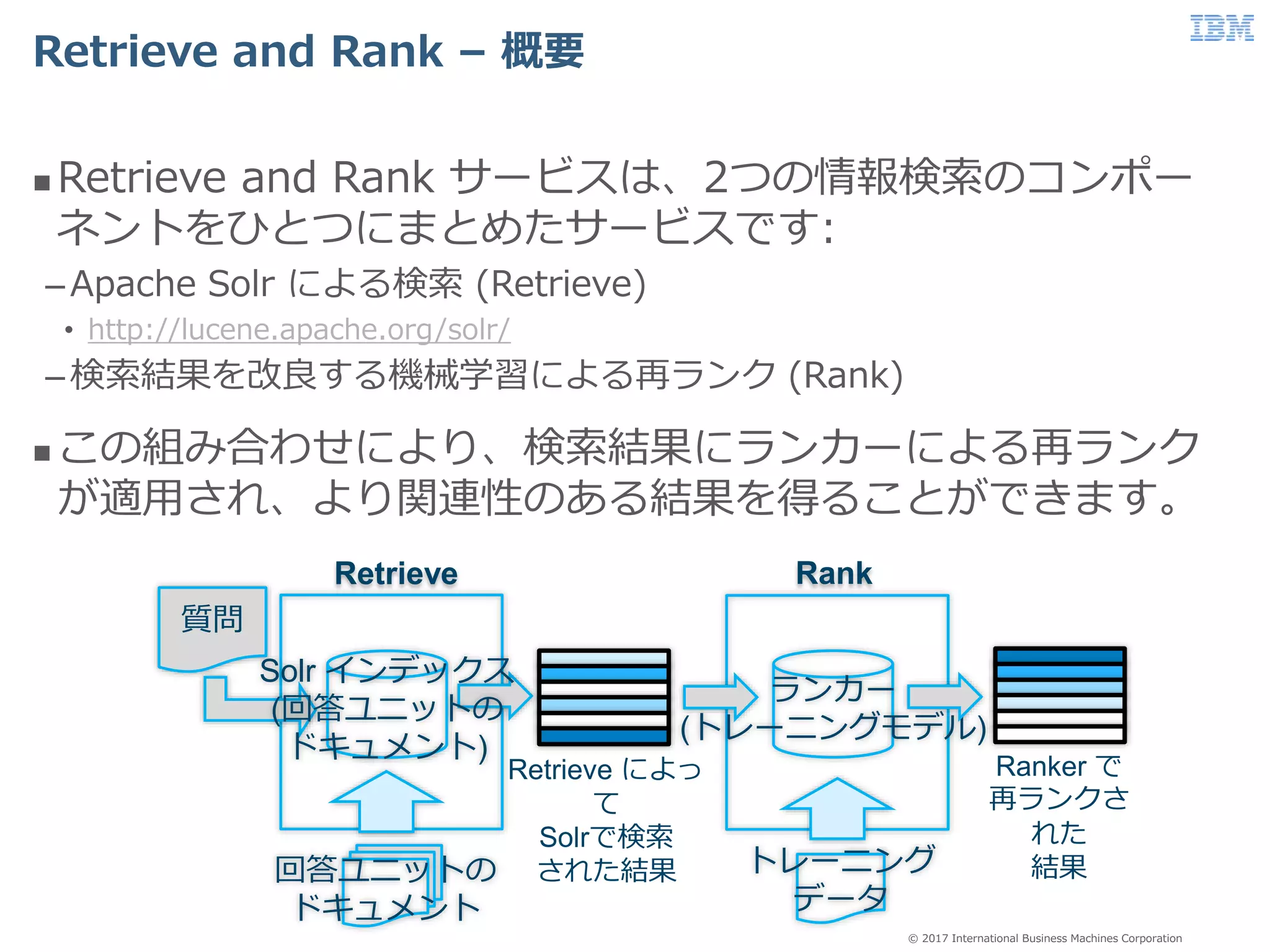
45.
© 2017 International
Business Machines Corporation Retrieve and Rank – 概要 Retrieve and Rank サービスは、2つの情報検索のコンポー ネントをひとつにまとめたサービスです: –Apache Solr による検索 (Retrieve) • http://lucene.apache.org/solr/ –検索結果を改良する機械学習による再ランク (Rank) この組み合わせにより、検索結果にランカーによる再ランク が適用され、より関連性のある結果を得ることができます。 Retrieve Rank ランカー (トレーニングモデル) 質問 Retrieve によっ て Solrで検索 された結果 Ranker で 再ランクさ れた 結果回答ユニットの ドキュメント トレーニング データ Solr インデックス (回答ユニットの ドキュメント)
46.
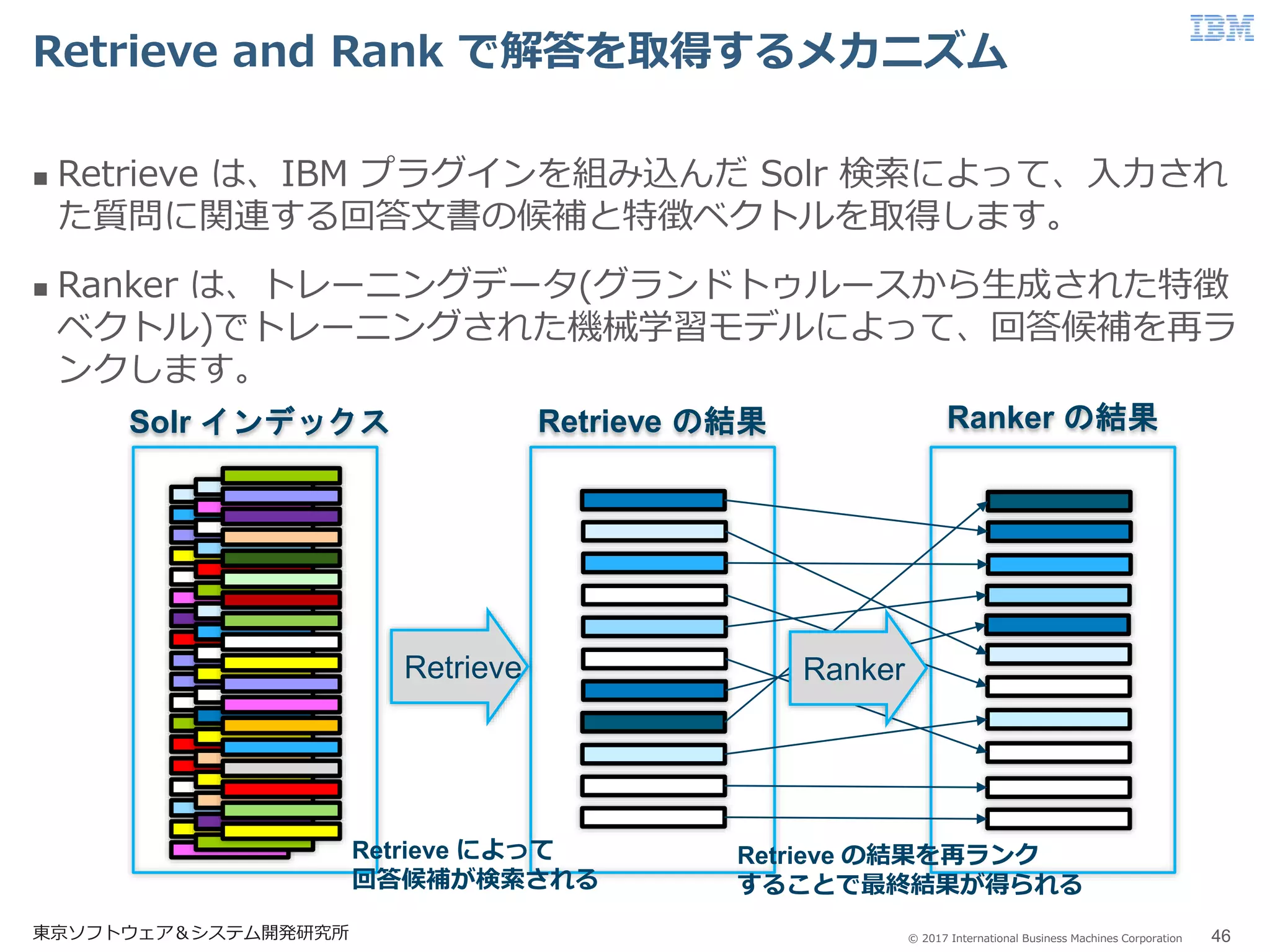
© 2017 International
Business Machines Corporation Retrieve and Rank で解答を取得するメカニズム 東京ソフトウェア&システム開発研究所 46 Retrieve は、IBM プラグインを組み込んだ Solr 検索によって、入力され た質問に関連する回答文書の候補と特徴ベクトルを取得します。 Ranker は、トレーニングデータ(グランドトゥルースから生成された特徴 ベクトル)でトレーニングされた機械学習モデルによって、回答候補を再ラ ンクします。 Solr インデックス Retrieve の結果 Ranker の結果 Retrieve Ranker Retrieve によって 回答候補が検索される Retrieve の結果を再ランク することで最終結果が得られる
47.
© 2017 International
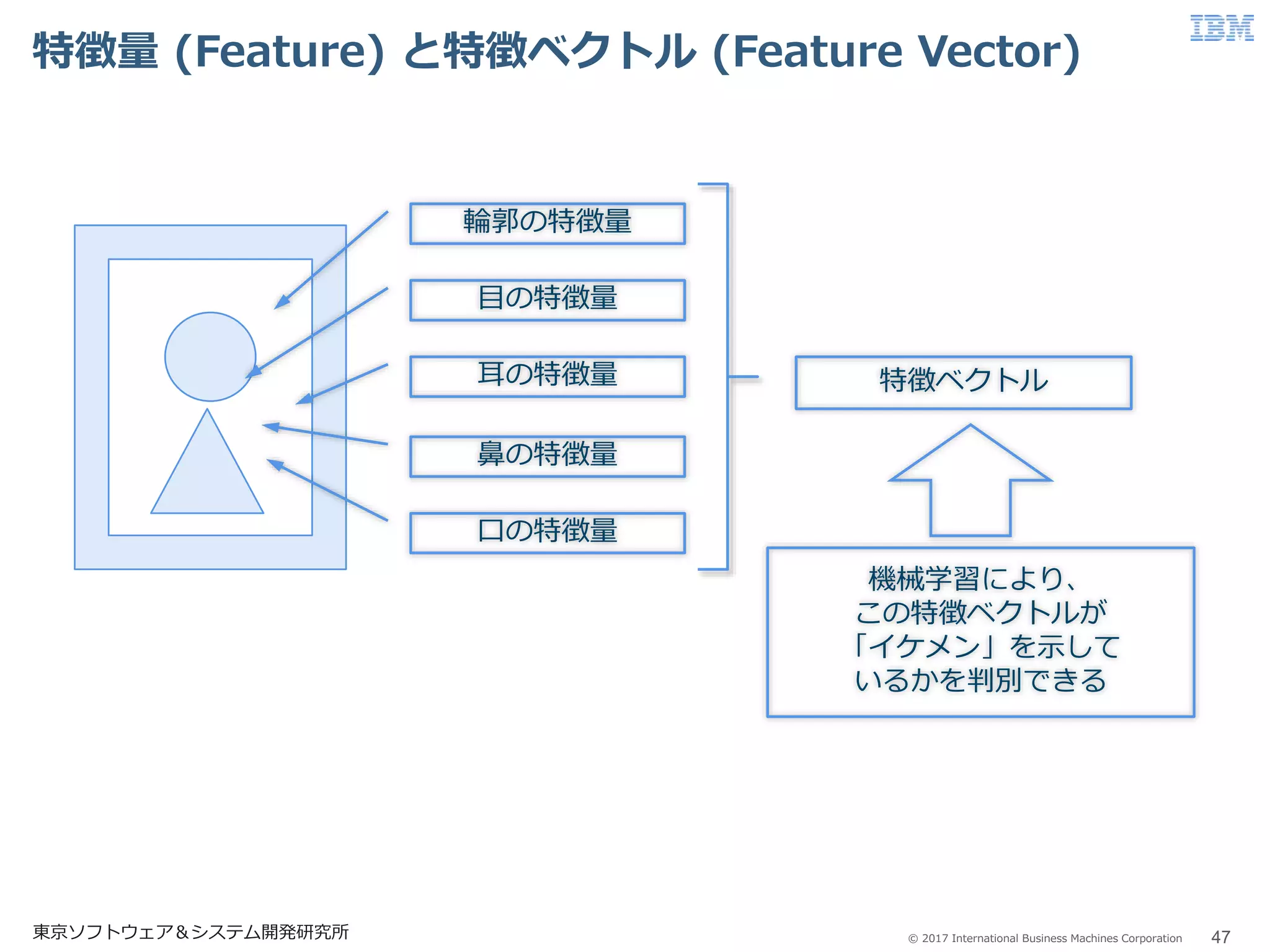
Business Machines Corporation 特徴量 (Feature) と特徴ベクトル (Feature Vector) 47東京ソフトウェア&システム開発研究所 輪郭の特徴量 目の特徴量 耳の特徴量 鼻の特徴量 口の特徴量 特徴ベクトル 機械学習により、 この特徴ベクトルが 「イケメン」を示して いるかを判別できる
48.
© 2017 International
Business Machines Corporation ランカーの内部メカニズム 東京ソフトウェア&システム開発研究所 48 Learn to Rank として知られている情報検索システムでの研究をベースに しています。 Learning to rank – https://en.Wikipedia.org/wiki/Learning_to_rank • Learning to rank or machine-learned ranking (MLR) is the application of machine learning, typically supervised, semi-supervised or reinforcement learning, in the construction of ranking models for information retrieval systems. Training data consists of lists of items with some partial order specified between items in each list. This order is typically induced by giving a numerical or ordinal score or a binary judgment (e.g. "relevant" or "not relevant") for each item. The ranking model's purpose is to rank, i.e. produce a permutation of items in new, unseen lists in a way which is "similar" to rankings in the training data in some sense. – Based on Yahoo competition in 2010 • From RankNet to LambdaRank to LambdaMART: An Overview – http://research.microsoft.com/en-us/um/people/cburges/tech_reports/MSR-TR-2010- 82.pdf • Yahoo! Learning to Rank Challenge (Archive) – http://archive.is/sr8r Learning to Rank あるいは「機械学習によるランク (machine-learned ranking: MLR)」 は、情報検索システムでのランキング モデルの作成にあたり、多くの場合には専門家の管理下で、ときには部分的な管理や強化アルゴリズムによって学習が行 われる、機械学習のアプリケーションです。リスト内で順位付けされたアイテムで構成されたリストがトレーニングデー タになります。この順位付けは大抵は、それぞれのアイテムに対して(関連があるか無いかどうかを示す)数値や序列の スコアや相対値によって定義されます。ランキングモデルの目的はランクをすることで、新たに与えられた「はじめて見 る」一連のアイテムを、トレーニングデータのランキングと意味的にで「同じように」なるように並べ替えすることです。
49.
© 2017 International
Business Machines Corporation Personality Insight
50.
© 2017 International
Business Machines Corporation Personality Insights 電子メール、テキスト・メッセージ、ツイートやフォーラムの書き込みを 分析し、作成者のパーソナリティーを判定します。 入力データ – 分析対象者が一人で書いた、最少で1000語の自然文。 – 統計学的に有意な結果を得るためには、 少なくとも3500語以上、理想的には6000語以上 の長さのテキストが必要。 – Twitter のつぶやきでも分析可能。 – 5因子モデルによる性格分析 • Openness (知的好奇心) • Extraversion(外向性) • Agreeableness(調和性) • Emotional range(情緒不安定性) • Conscientiousness (誠実性) – 欲求 • 実用主義、社会性、調和 • 自由主義、親密 – 価値 • 自己超越、変化許容性、自己増進 • 快楽主義、現状維持 想定ユースケース • 個客対応型マーケティング、おすすめ商品の提示。 • 人と人、人と組織のマッチング。
51.
Personal Insight デモページ 51 https://personality-insights-livedemo.mybluemix.net/
52.
Personal Insight デモページ 52 結果(性格のサマリー)の例 道草
- 夏目漱石 (日本語) • 熱くなりやすいタイプであり、ひどく陽 気なタイプであり、また慣例にとらわれ ないタイプです. • 大胆なタイプです: 時間をかけて慎重に検 討するよりもむしろ即座に行動を起こし ます. 圧力を受けても冷静なタイプです: 冷静で、予期しない出来事にも効果的に 対処します. また、自主性の高いタイプで す: 自分の時間を大切にしたいという強い 願望があります. • 組織への帰属を意識して意思決定するタ イプです. • 自主性があなたの行動に大きな影響を与 えています: 最高の成果が得られるよう、 自分自身で目標を設定する傾向がありま す. 成功することにはあまりこだわりませ ん: 自分の才能を誇示することにあまり拘 らず意思決定します.
53.
© 2017 International
Business Machines Corporation Tone Analyzer (日本語未対応) 53
54.
© 2017 International
Business Machines Corporation Tone Analyzer テキスト分析を通じて、ユーザーの感情、言語スタイル、社 会的傾向を分析します。 分析内容 利用シーン –コールセンターやチャットボットなどで顧客の反応を分析評価したり、そ の分析結果で対応を変えるなどの利用ができます。 社会的傾向: • 開放的(openness) • 良心性 (conscientiousness) • 外反(extraversion)、 • 了解(agreeableness) • 感情的(emotional) 感情分析: • 喜び(joy) • 恐れ(fear) • 悲しみ(sad) • 怒り(anger) • 嫌悪(disgust) 言語スタイル: • 分析的(analytical) • 自信のある (confident) • 暫定的(tentative)
55.
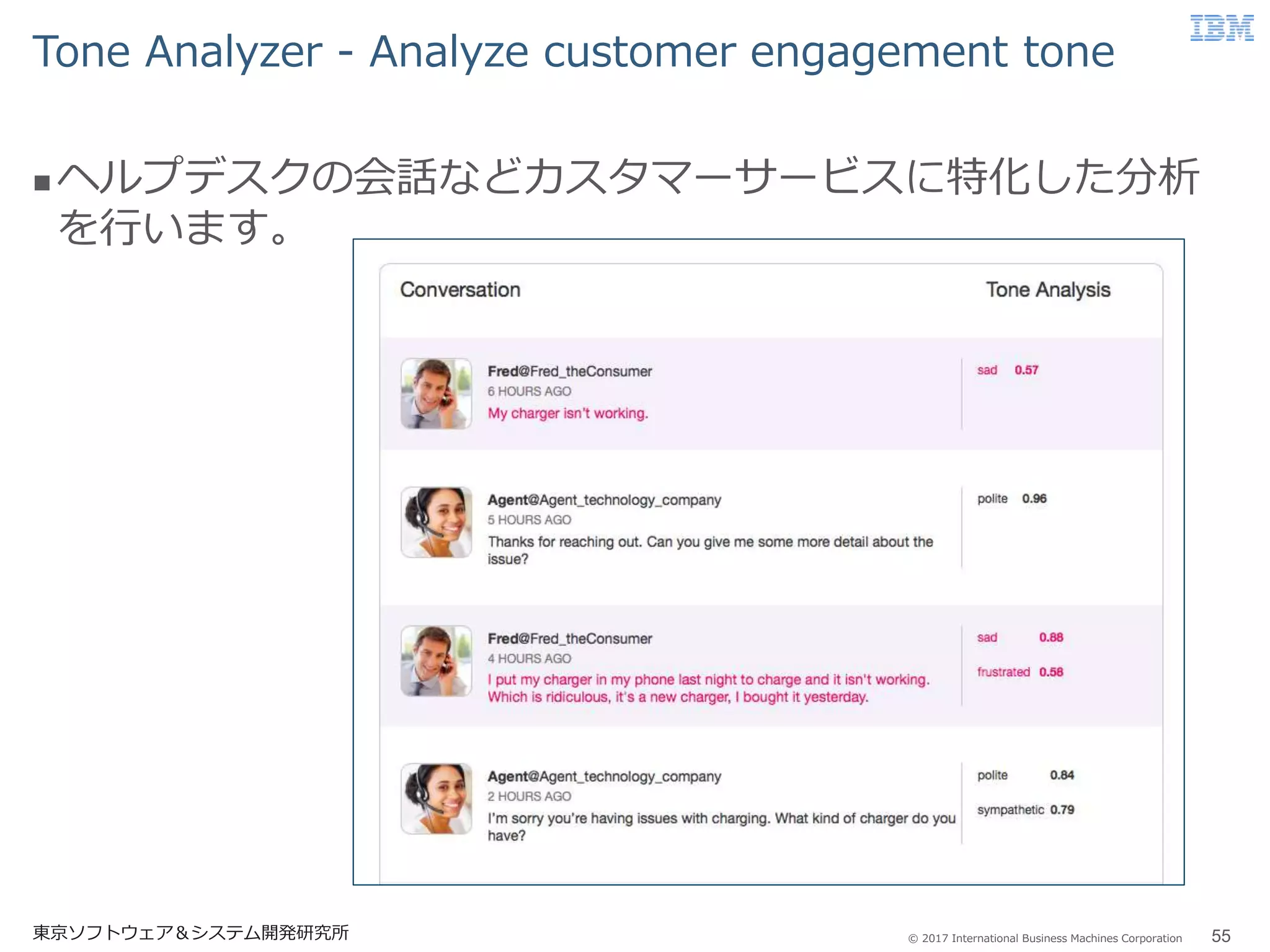
© 2017 International
Business Machines Corporation Tone Analyzer - Analyze customer engagement tone 東京ソフトウェア&システム開発研究所 55 ヘルプデスクの会話などカスタマーサービスに特化した分析 を行います。
56.
© 2017 International
Business Machines Corporation Tone Analyzer - デモ 56東京ソフトウェア&システム開発研究所 分析結果サンプル 個別の文章単位での分析
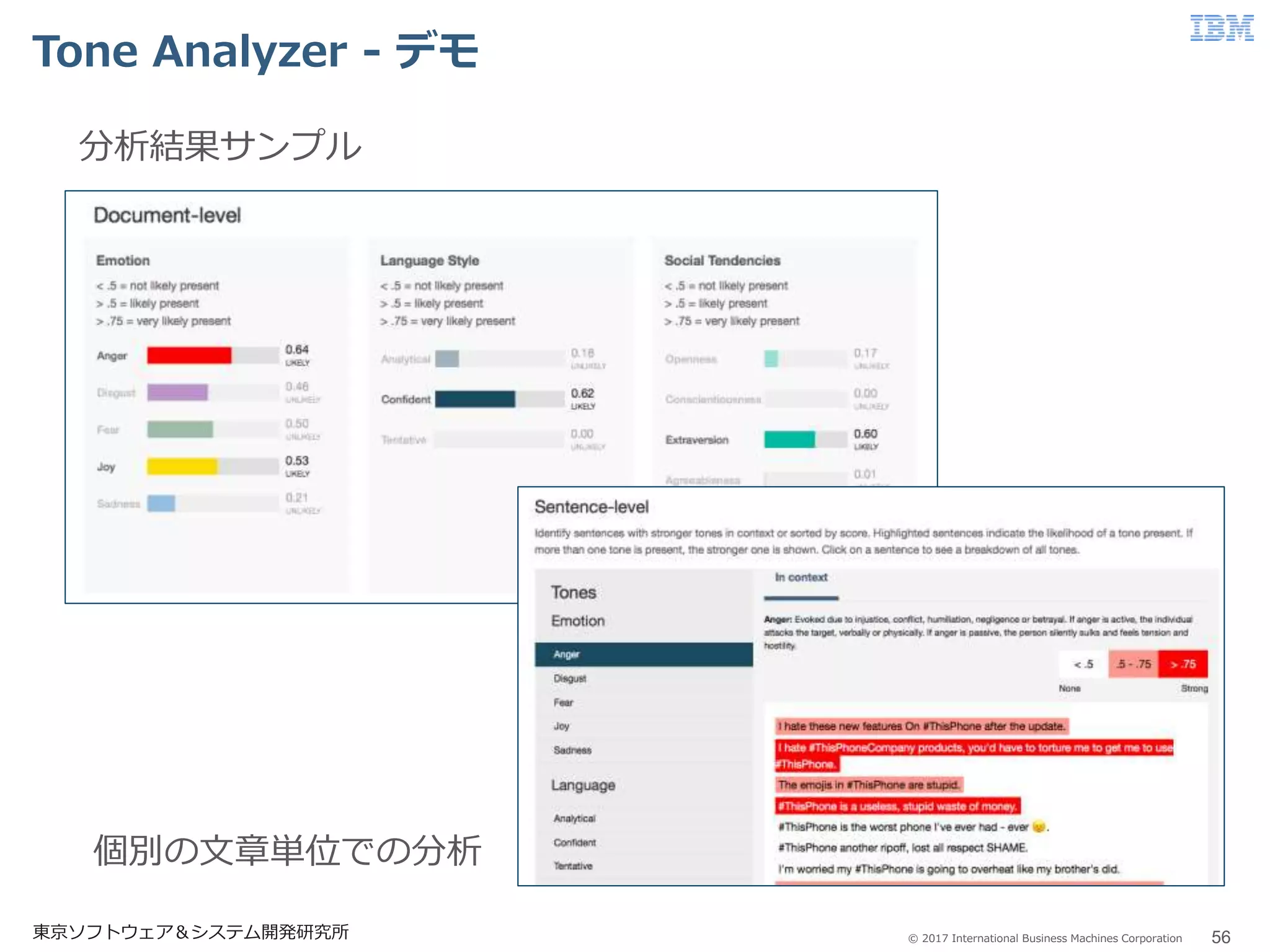
57.
© 2017 International
Business Machines Corporation Watsonの音声処理サービス 東京ソフトウェア&システム開発研究所 57 Speech to Text Text to Speech
58.
© 2017 International
Business Machines Corporation Speech to Text 東京ソフトウェア&システム開発研究所 58
59.
© 2017 International
Business Machines Corporation Speech to Text – 概要 東京ソフトウェア&システム開発研究所 59 音声信号の構成と文法や言語の構造を用いて、音声データを テキストデータに変換 –特定のキーワードの検出(開始と終了時間) –カスタム学習 • カスタム辞書の登録による特殊用語の検出 • カスタム文書の登録による業界固有の用語の入った音声の認識 –話者認識機能による複数話者の音声からの話者の特定 活用シーン –コールセンター: 会話ログ記録と分析、オペレーター支援 –ロボット、組み込み機器: 自動応答、音声コントロール 入出力 –入力:ファイルまたはストリーム形式の音声データ –出力:音声から認識されたテキスト
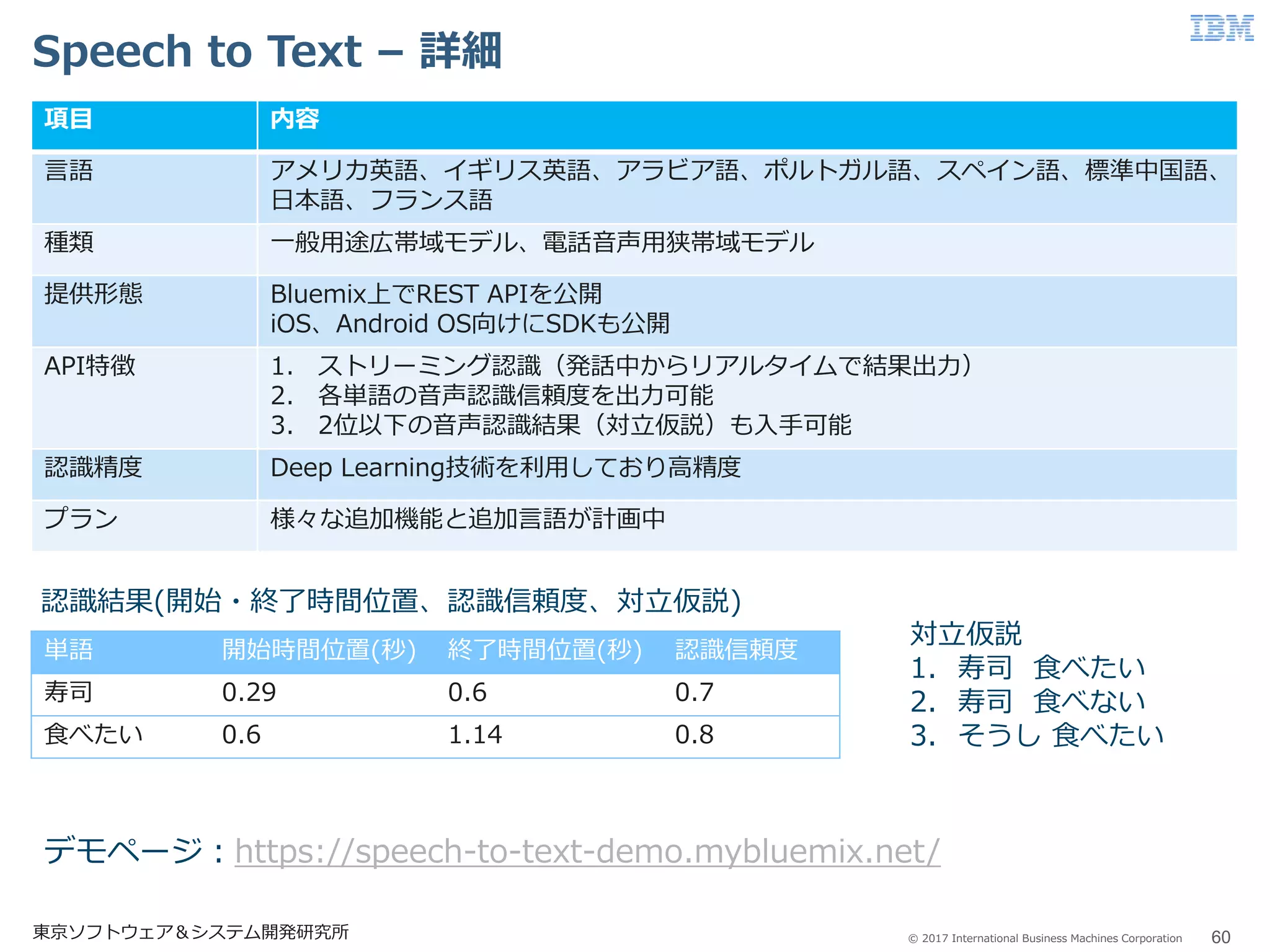
60.
© 2017 International
Business Machines Corporation Speech to Text – 詳細 60東京ソフトウェア&システム開発研究所 項目 内容 言語 アメリカ英語、イギリス英語、アラビア語、ポルトガル語、スペイン語、標準中国語、 日本語、フランス語 種類 一般用途広帯域モデル、電話音声用狭帯域モデル 提供形態 Bluemix上でREST APIを公開 iOS、Android OS向けにSDKも公開 API特徴 1. ストリーミング認識(発話中からリアルタイムで結果出力) 2. 各単語の音声認識信頼度を出力可能 3. 2位以下の音声認識結果(対立仮説)も入手可能 認識精度 Deep Learning技術を利用しており高精度 プラン 様々な追加機能と追加言語が計画中 単語 開始時間位置(秒) 終了時間位置(秒) 認識信頼度 寿司 0.29 0.6 0.7 食べたい 0.6 1.14 0.8 対立仮説 1. 寿司 食べたい 2. 寿司 食べない 3. そうし 食べたい 認識結果(開始・終了時間位置、認識信頼度、対立仮説) デモページ:https://speech-to-text-demo.mybluemix.net/
61.
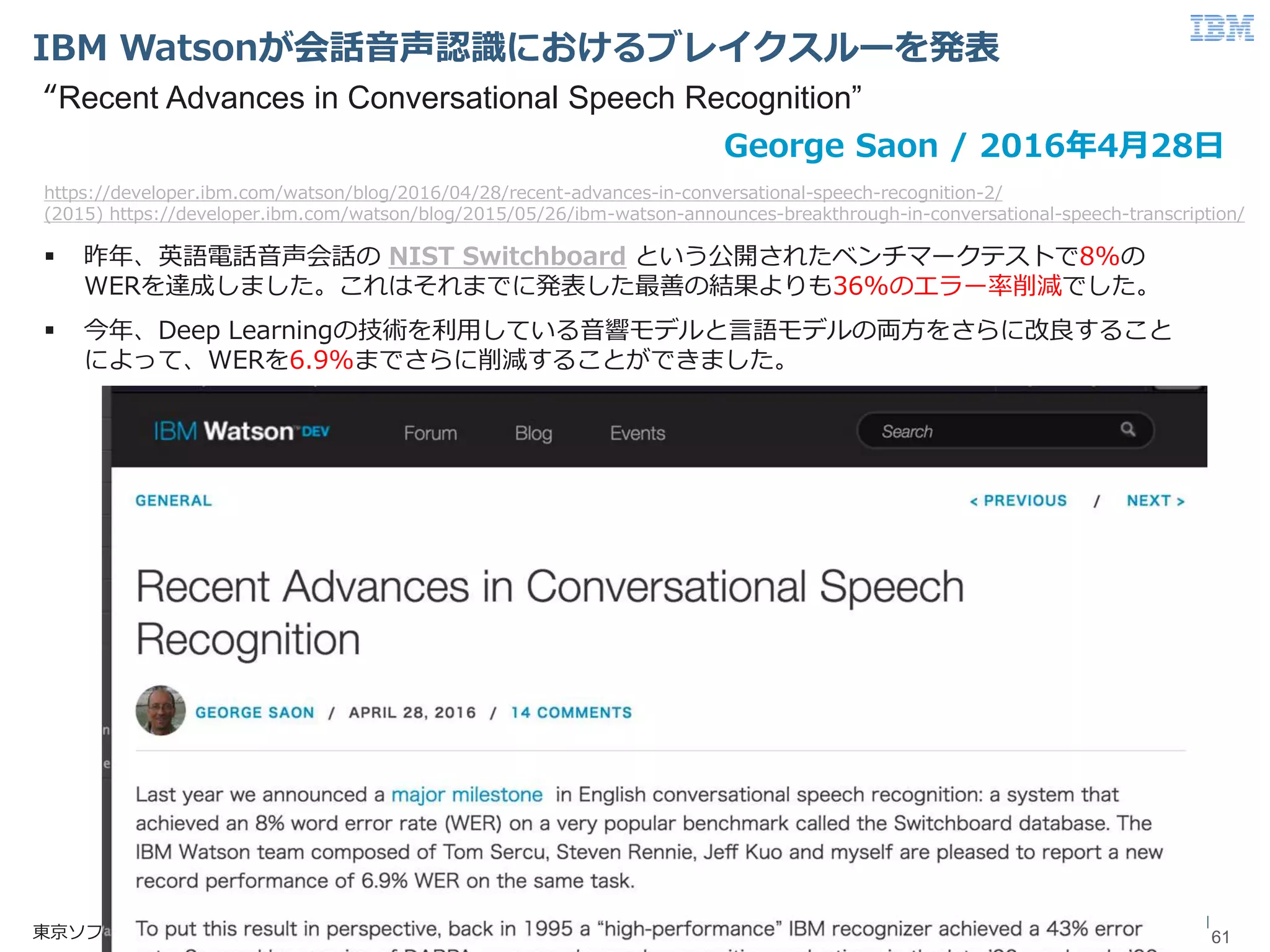
© 2017 International
Business Machines Corporation IBM Watsonが会話音声認識におけるブレイクスルーを発表 61東京ソフトウェア&システム開発研究所 61 昨年、英語電話音声会話の NIST Switchboard という公開されたベンチマークテストで8%の WERを達成しました。これはそれまでに発表した最善の結果よりも36%のエラー率削減でした。 今年、Deep Learningの技術を利用している音響モデルと言語モデルの両方をさらに改良すること によって、WERを6.9%までさらに削減することができました。 George Saon / 2016年4月28日 https://developer.ibm.com/watson/blog/2016/04/28/recent-advances-in-conversational-speech-recognition-2/ (2015) https://developer.ibm.com/watson/blog/2015/05/26/ibm-watson-announces-breakthrough-in-conversational-speech-transcription/ “Recent Advances in Conversational Speech Recognition”
62.
© 2017 International
Business Machines Corporation 音声でのキーワードの検出(Keyword Spotting) 62東京ソフトウェア&システム開発研究所 ルノワールを検出するよう構成した例 { "results": [ { "keywords_result": { "ルノワール": [ { "normalized_text": "ルノワール", "start_time": 0.44, "confidence": 0.885, "end_time": 1.02 } ] }, "alternatives": [ { "confidence": 0.835, "transcript": "ルノワール 展 見て きた " } <後略> } 検出された 開始時間 終了時間
63.
© 2017 International
Business Machines Corporation Speech to Text - デモ 東京ソフトウェア&システム開発研究所 63 URL –https://speech-to-text-demo.mybluemix.net/ 言語モデルを使用しての音声認識とキーワード検出
64.
© 2017 International
Business Machines Corporation Text to Speech 東京ソフトウェア&システム開発研究所 64
65.
© 2017 International
Business Machines Corporation Text to Speech – 概要 東京ソフトウェア&システム開発研究所 65 テキストから自然なリズムやイントネーションを再現した音 声ストリームを生成 –9言語の男女で合計13音声モデルを用意 –SSML(音声合成用のマークアップ言語)で一定時間のポースを入れたり、k 感情表現を入れた音声合成も可能(一部言語のみ) –カスタム辞書による特殊用語の発声 活用シーン –コールセンター: 音声案内 –ロボット、組み込み機器: 自動応答 入出力 –入力:平文のテキストか SSML –出力:Ogg, WAV, MP3 などのメディア・タイプ
66.
© 2017 International
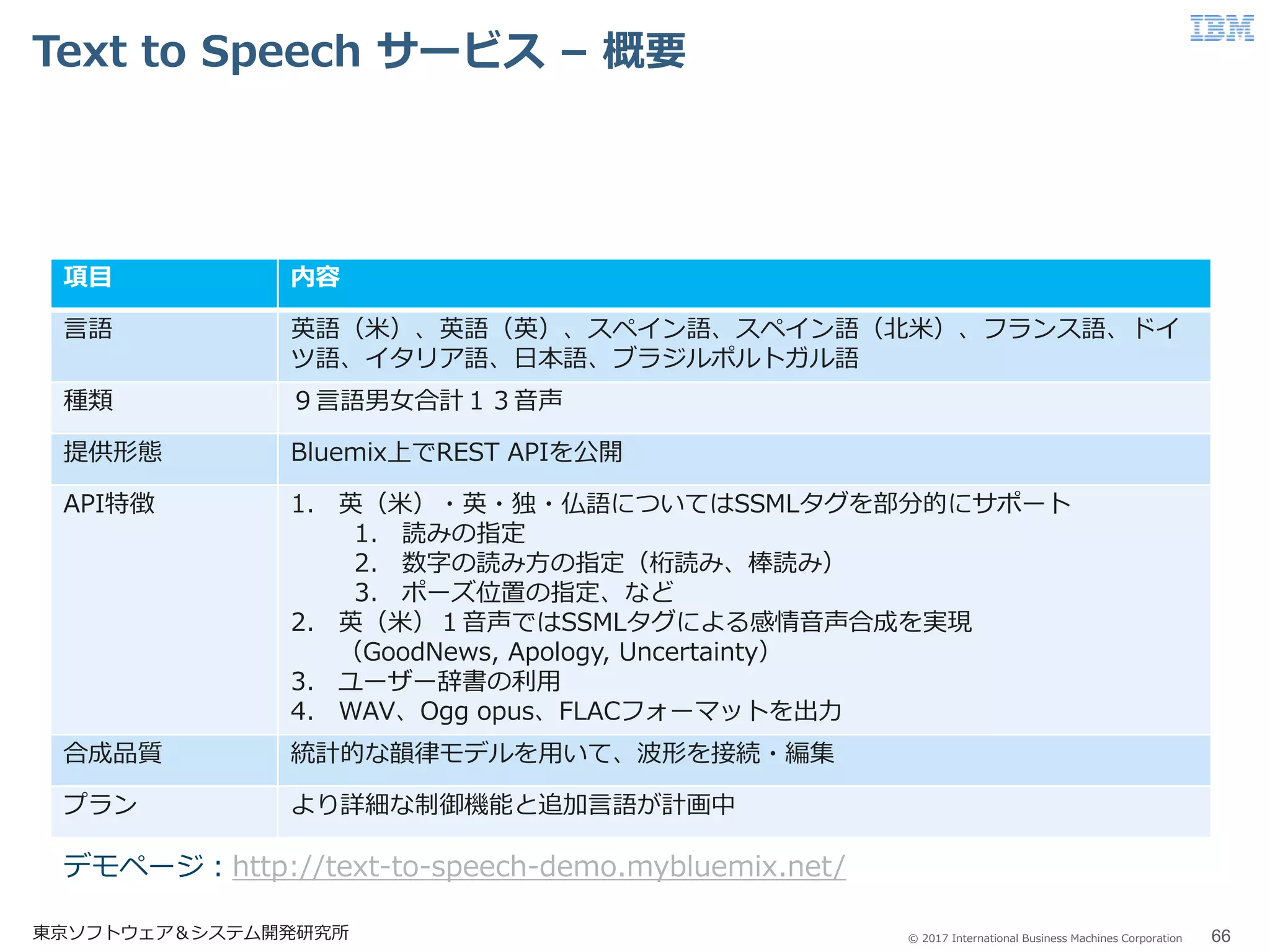
Business Machines Corporation Text to Speech サービス – 概要 東京ソフトウェア&システム開発研究所 66 項目 内容 言語 英語(米)、英語(英)、スペイン語、スペイン語(北米)、フランス語、ドイ ツ語、イタリア語、日本語、ブラジルポルトガル語 種類 9言語男女合計13音声 提供形態 Bluemix上でREST APIを公開 API特徴 1. 英(米)・英・独・仏語についてはSSMLタグを部分的にサポート 1. 読みの指定 2. 数字の読み方の指定(桁読み、棒読み) 3. ポーズ位置の指定、など 2. 英(米)1音声ではSSMLタグによる感情音声合成を実現 (GoodNews, Apology, Uncertainty) 3. ユーザー辞書の利用 4. WAV、Ogg opus、FLACフォーマットを出力 合成品質 統計的な韻律モデルを用いて、波形を接続・編集 プラン より詳細な制御機能と追加言語が計画中 デモページ:http://text-to-speech-demo.mybluemix.net/
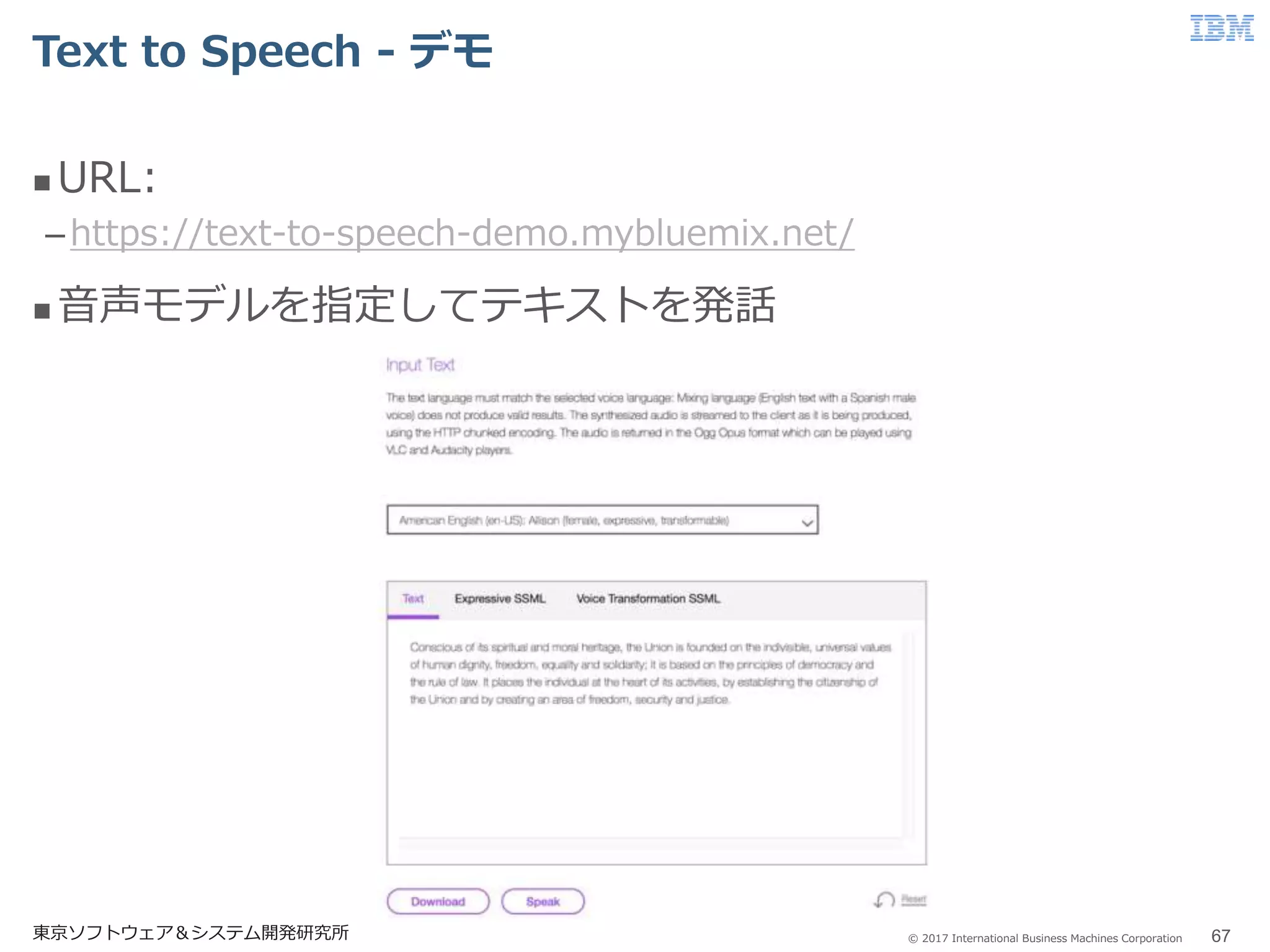
67.
© 2017 International
Business Machines Corporation Text to Speech - デモ 東京ソフトウェア&システム開発研究所 67 URL: –https://text-to-speech-demo.mybluemix.net/ 音声モデルを指定してテキストを発話
68.
© 2017 International
Business Machines Corporation Watsonの画像認識サービス 東京ソフトウェア&システム開発研究所 68 Visual Recognition
69.
© 2017 International
Business Machines Corporation Visual Recognition 69東京ソフトウェア&システム開発研究所
70.
© 2017 International
Business Machines Corporation Visual Recognition – 概要 東京ソフトウェア&システム開発研究所 70 深層学習アルゴリムで画像に含まれる顔や内容を分析。 活用シーン –画像データをカテゴリーごとに整理 –ソーシャルメディアの写真からユーザーの興味をセグメント化 –特定のコンテンツに関連した画像を探す 標準分類器による 画像の分類 カスタム分類器に よる画像の分類 類似画像検索 顔認識 画像に含まれる顔を検知し、性別と年連を判別します。 有名人については人物の特定もします。 事前登録した画像から類似画像を検索します。 画像に含まれる内容を分析し、事前学習しているカテゴリ に確信度付きで分類します。 利用目的に応じて作成された学習データをもとにカスタマイ ズされた分類器を作成して、画像を分類します。
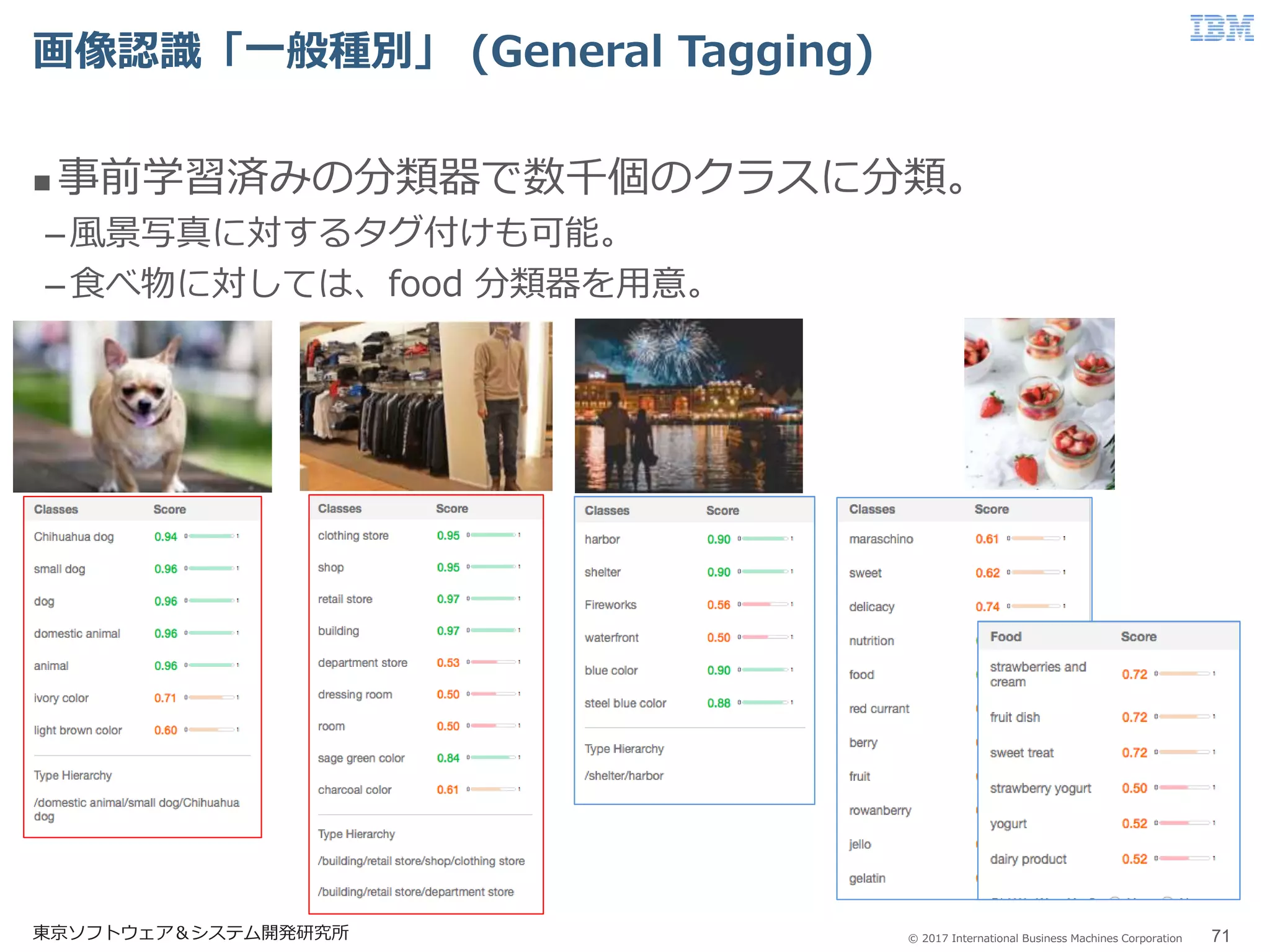
71.
© 2017 International
Business Machines Corporation 画像認識「一般種別」 (General Tagging) 東京ソフトウェア&システム開発研究所 71 事前学習済みの分類器で数千個のクラスに分類。 –風景写真に対するタグ付けも可能。 –食べ物に対しては、food 分類器を用意。
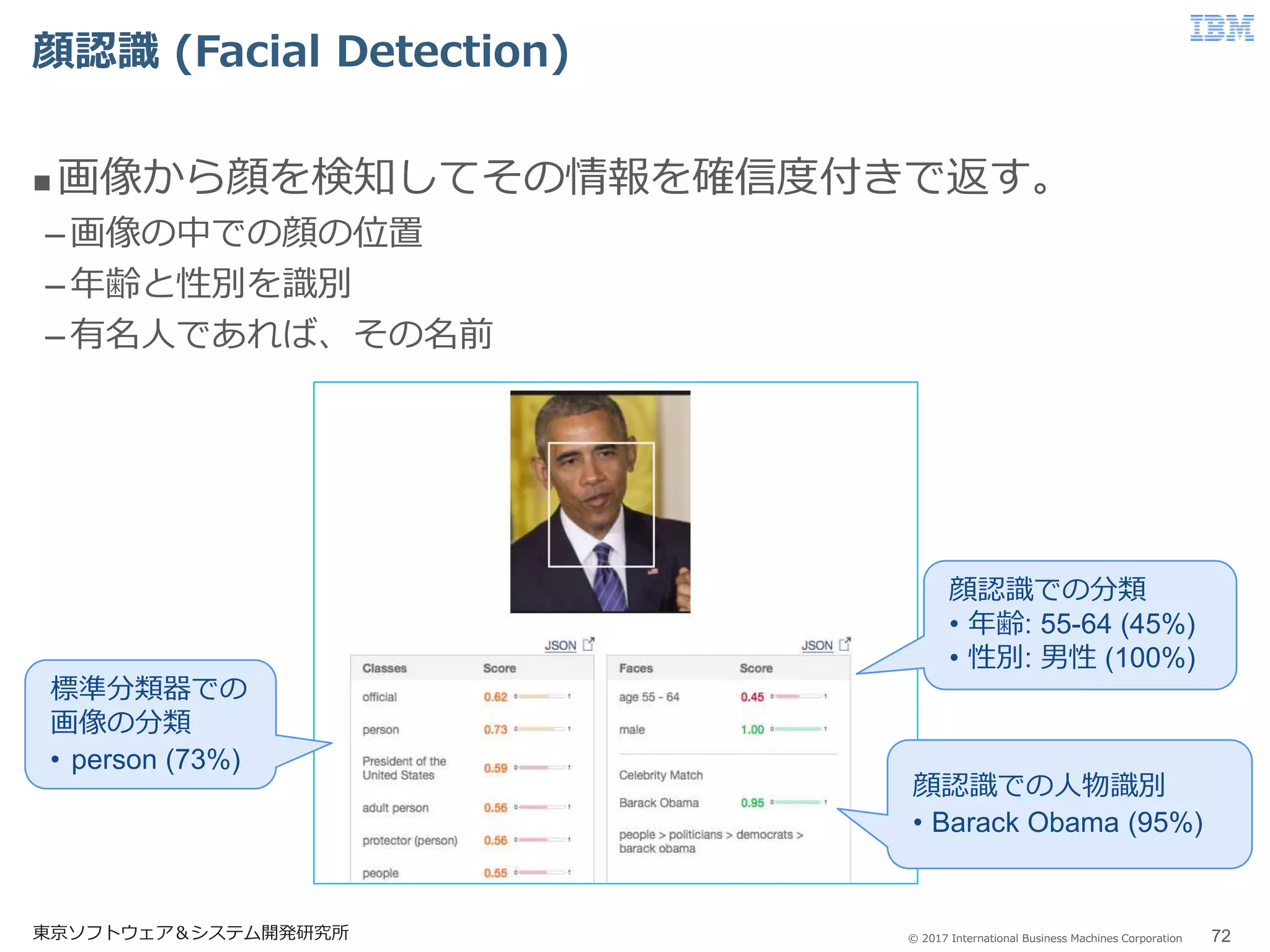
72.
© 2017 International
Business Machines Corporation 顔認識 (Facial Detection) 東京ソフトウェア&システム開発研究所 72 画像から顔を検知してその情報を確信度付きで返す。 –画像の中での顔の位置 –年齢と性別を識別 –有名人であれば、その名前 標準分類器での 画像の分類 • person (73%) 顔認識での分類 • 年齢: 55-64 (45%) • 性別: 男性 (100%) 顔認識での人物識別 • Barack Obama (95%)
73.
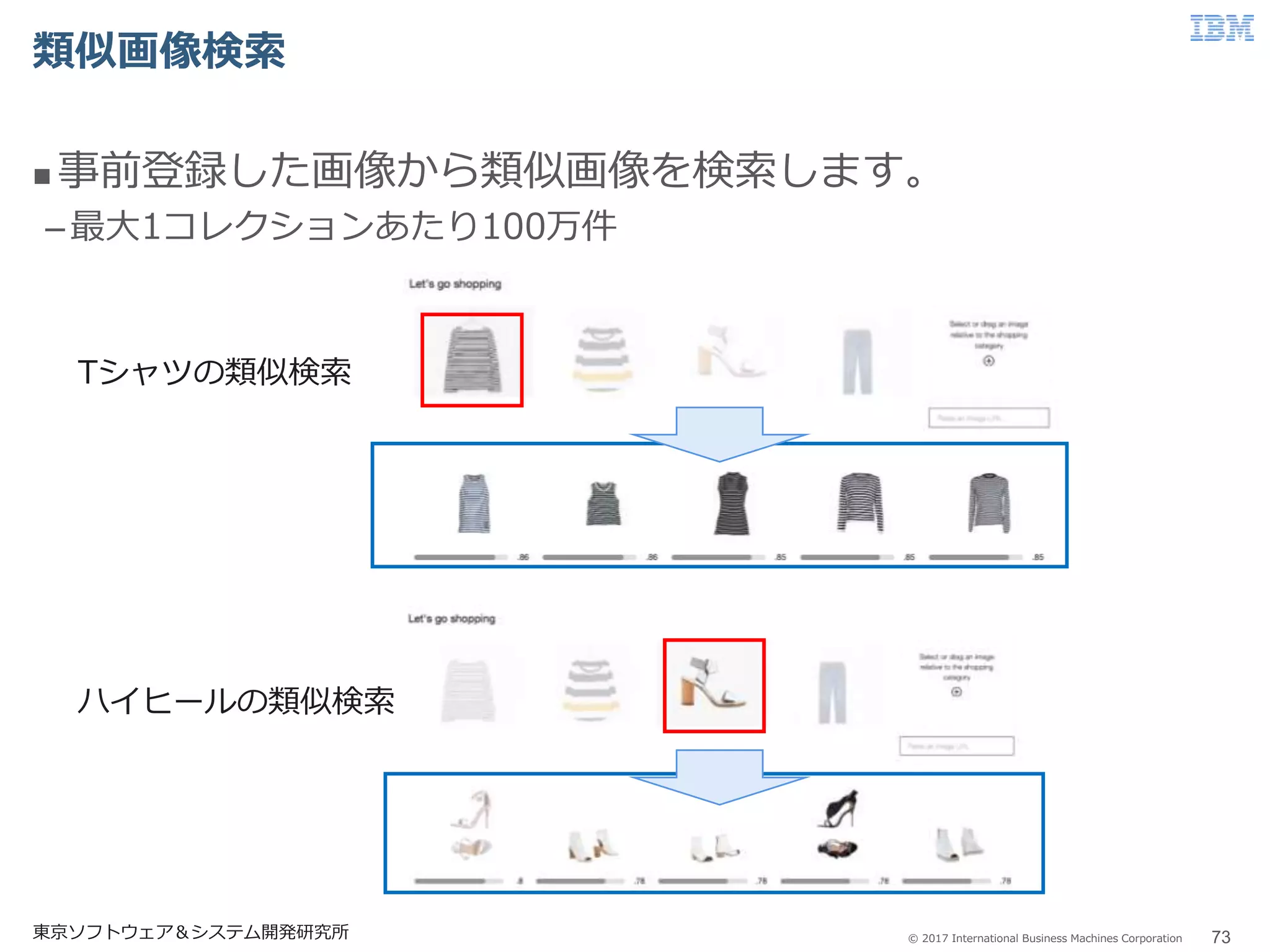
© 2017 International
Business Machines Corporation 類似画像検索 73東京ソフトウェア&システム開発研究所 事前登録した画像から類似画像を検索します。 –最大1コレクションあたり100万件 ハイヒールの類似検索 Tシャツの類似検索
74.
© 2017 International
Business Machines Corporation カスタム分類器の作成 東京ソフトウェア&システム開発研究所 74 Visual Recognitionを適用する業務分野に応じた分類が可能。 利用シーン –不適切な画像のフィルタリング –画像選択での事前分類 –商品や製作物の品質確認 学習データ –分類すべきクラスごとに最低10枚の画像(50枚以上が推奨) –どのクラスにも該当しないネガティブな最低10枚の画像 分類器 Apple クラス (ポジティブ) Banana クラス (ポジティブ) Orange クラス (ポジティブ) Vegetable (ネガティブ) Apple !
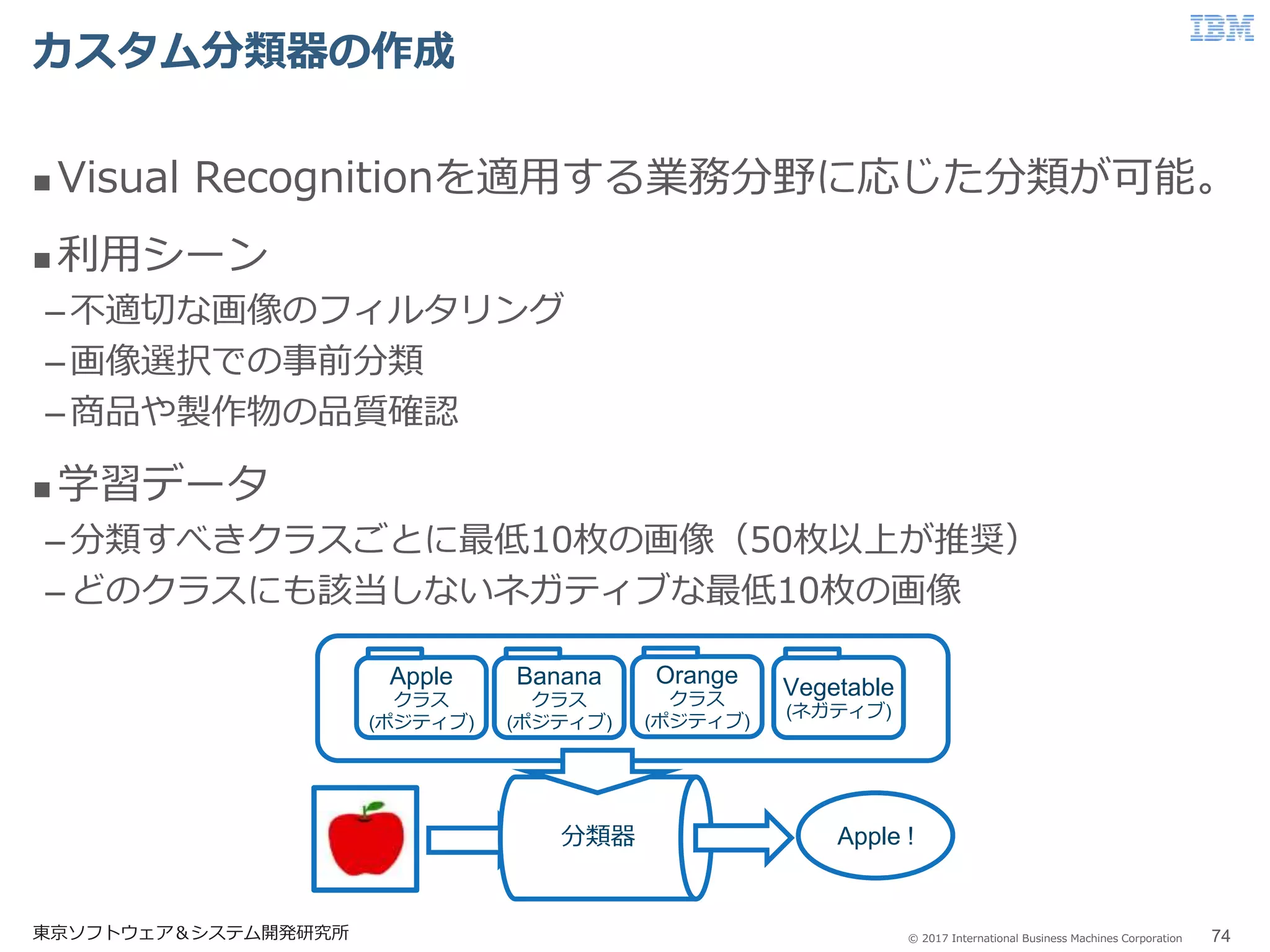
75.
© 2017 International
Business Machines Corporation 参考文献:フライドチキンとラブラドールを識別する 東京ソフトウェア&システム開発研究所 75 参考リンク: –http://qiita.com/VegaSato/items/863b614cd5ab88cf2d44 学習データ –ネット上で集めたラブラドゥードルとフライドチキンの写真約200枚ずつ。 検証結果 全問正解 –すべての写真について確信度に10倍程度の差がついており、確実に分類 できていることがわかる。
76.
© 2017 International
Business Machines Corporation Visual Recognition - デモ 東京ソフトウェア&システム開発研究所 76 URL: –https://visual-recognition-demo.mybluemix.net/ あらかじめ用意された分類器とカスタム分類器での画像分類 を試す。
77.
© 2017 International
Business Machines Corporation IBM Bluemix と Watson サービスの関係 77東京ソフトウェア&システム開発研究所
78.
© 2017 International
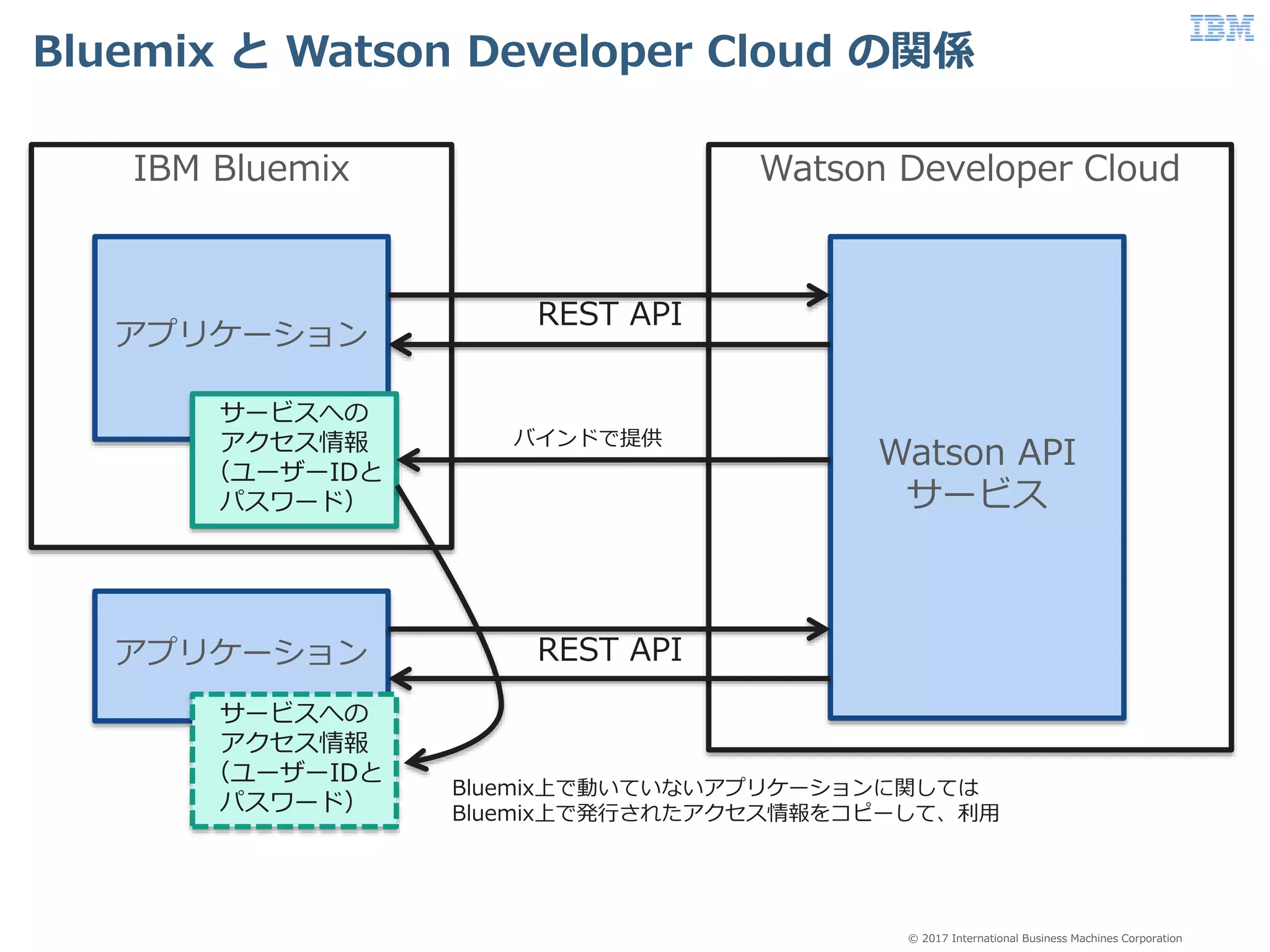
Business Machines Corporation Bluemix と Watson Developer Cloud の関係 IBM Bluemix アプリケーション Watson Developer Cloud Watson API サービス REST API サービスへの アクセス情報 (ユーザーIDと パスワード) アプリケーション サービスへの アクセス情報 (ユーザーIDと パスワード) REST API Bluemix上で動いていないアプリケーションに関しては Bluemix上で発行されたアクセス情報をコピーして、利用 バインドで提供
79.
Watson Developer
Cloud は Watson コグニティブサービスを提供する クラウド環境です。 • https://www.ibm.com/watson/developer/ –Watson サービスを提供するクラウドサーバー –クラウドで利用できる様々な Watson サービスのポータル • サービス利用のためのリンク • サービスのドキュメント • デモンストレーション • Webinars、Blog、Videos • サンプルコードやスターターキット • 開発者向けのコミュニテイへのリンク(IBM developerWorks) IBM Watson Developers Cloud 79 東京ソフトウェア&システム開発研究所
80.
© 2017 International
Business Machines Corporation Watson API サービスの使い方 80
81.
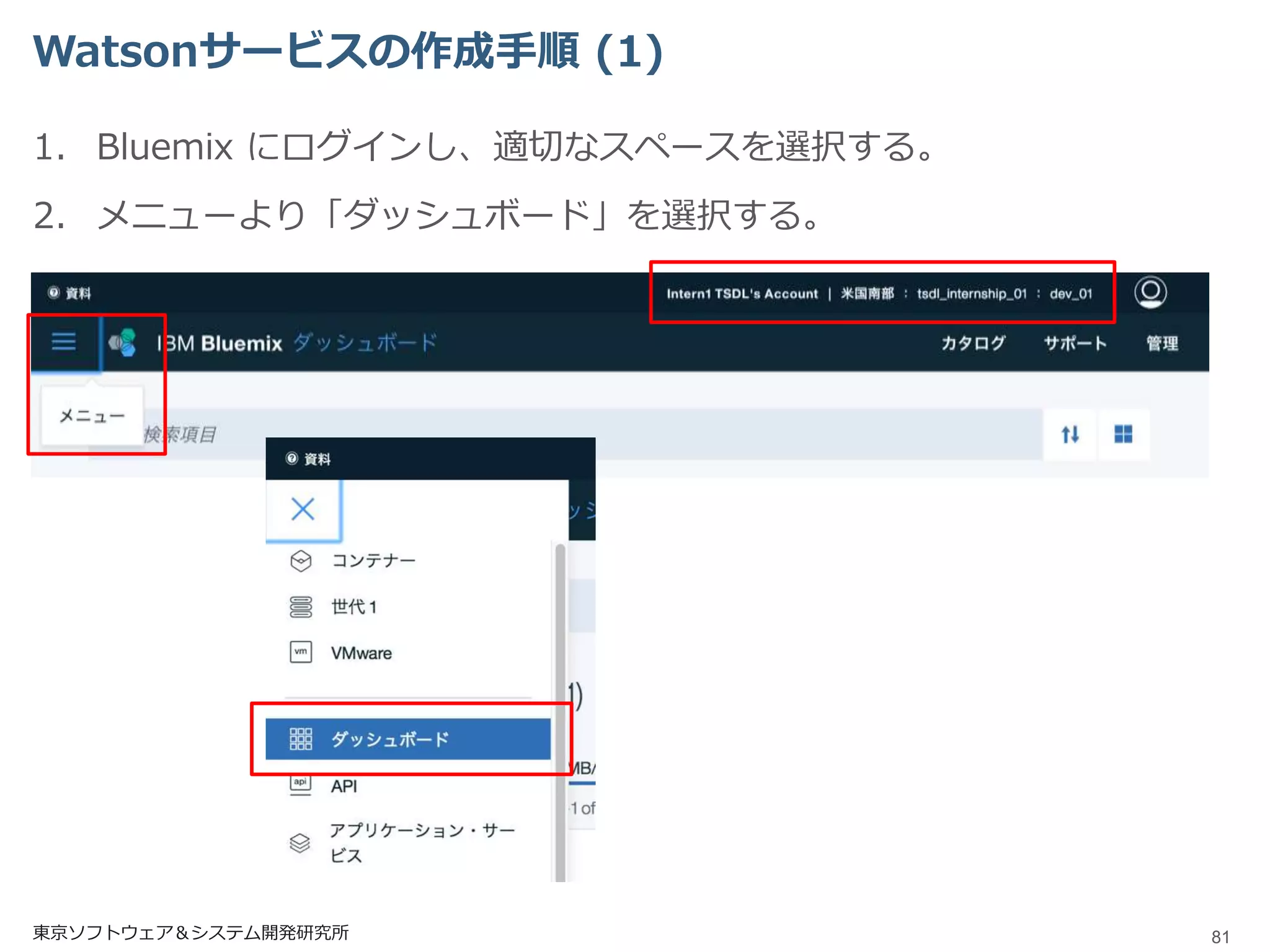
Watsonサービスの作成手順 (1) 1. Bluemix
にログインし、適切なスペースを選択する。 2. メニューより「ダッシュボード」を選択する。 東京ソフトウェア&システム開発研究所 81
82.
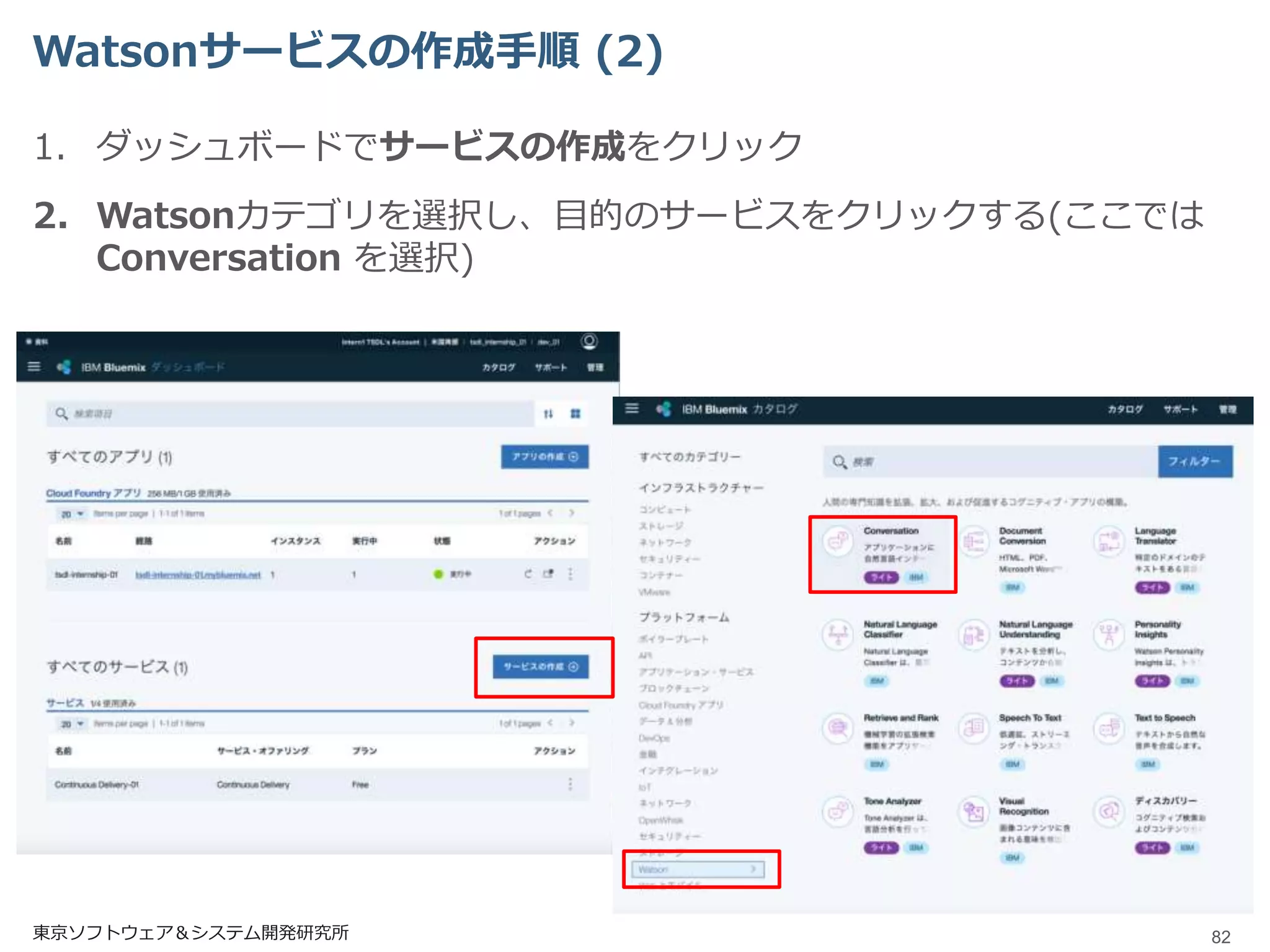
Watsonサービスの作成手順 (2) 1. ダッシュボードでサービスの作成をクリック 2.
Watsonカテゴリを選択し、目的のサービスをクリックする(ここでは Conversation を選択) 東京ソフトウェア&システム開発研究所 82
83.
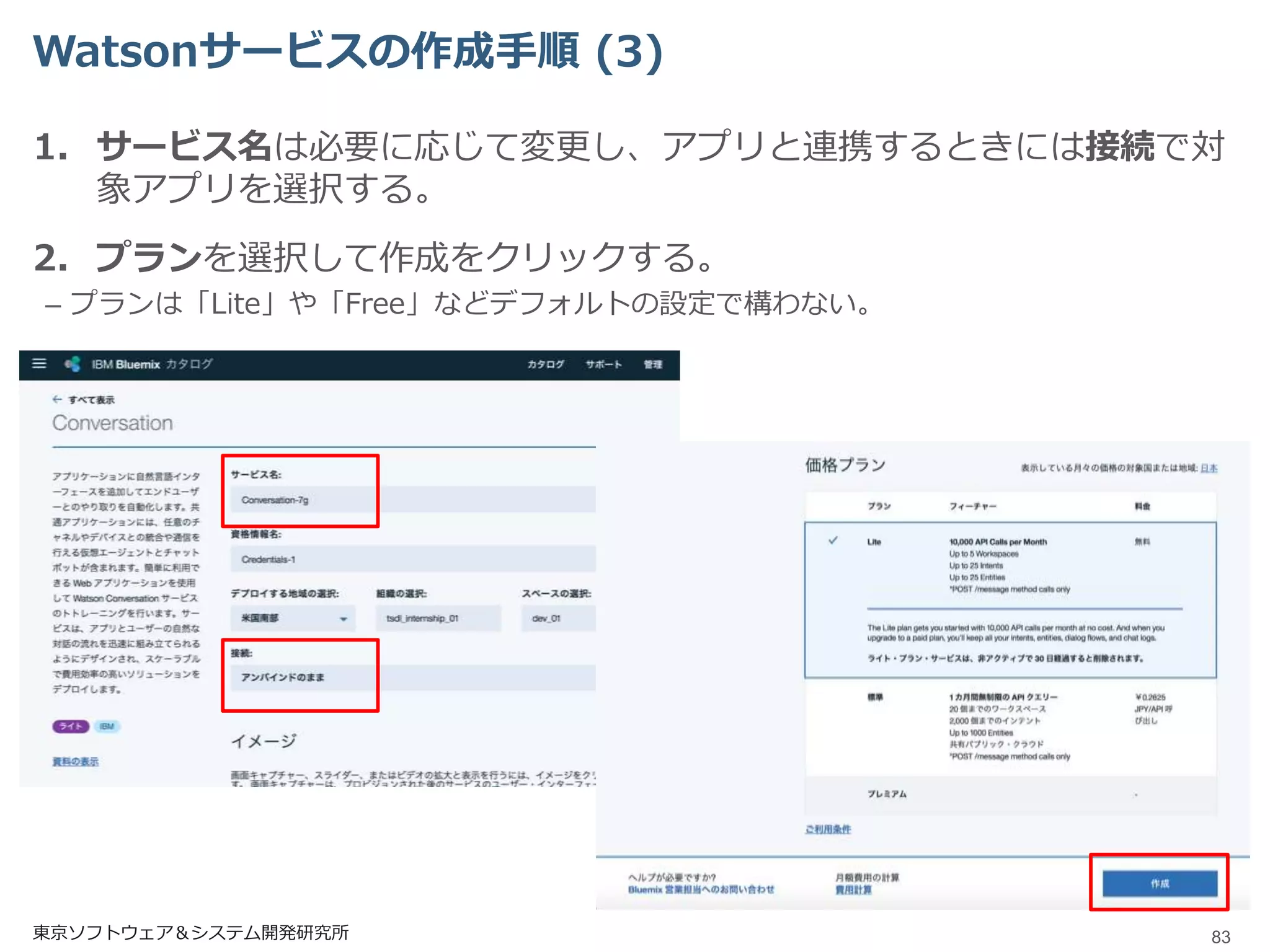
Watsonサービスの作成手順 (3) 1. サービス名は必要に応じて変更し、アプリと連携するときには接続で対 象アプリを選択する。 2.
プランを選択して作成をクリックする。 – プランは「Lite」や「Free」などデフォルトの設定で構わない。 東京ソフトウェア&システム開発研究所 83
84.
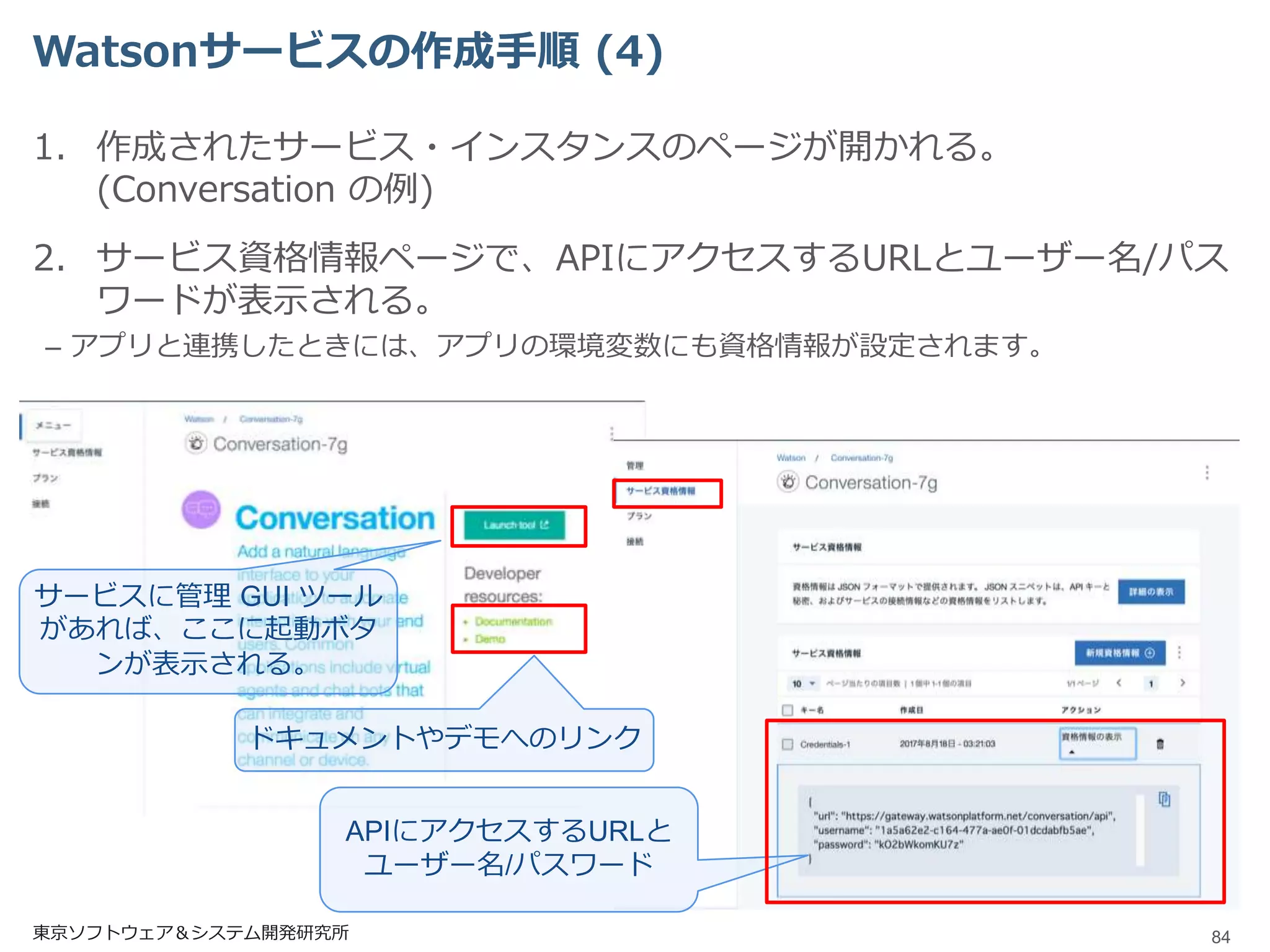
Watsonサービスの作成手順 (4) 1. 作成されたサービス・インスタンスのページが開かれる。 (Conversation
の例) 2. サービス資格情報ページで、APIにアクセスするURLとユーザー名/パス ワードが表示される。 – アプリと連携したときには、アプリの環境変数にも資格情報が設定されます。 東京ソフトウェア&システム開発研究所 84 サービスに管理 GUI ツール があれば、ここに起動ボタ ンが表示される。 APIにアクセスするURLと ユーザー名/パスワード ドキュメントやデモへのリンク
85.
© 2017 International
Business Machines Corporation Watson サービスの利用方法 すべての Watson サービスは REST API から利用可能 –アクセスには、作成したサービスインスタンスで発行される認証情報を使 用する。 –REST API をラップした簡易な呼び出し方法もある。 • Watson API explorer、SDK Library Watson サービスによっては、トレーニングとテスト用の簡 易 GUI ツールも用意している。 –Natural Language Classifier –Conversation –Discovery 東京ソフトウェア&システム開発研究所 85
86.
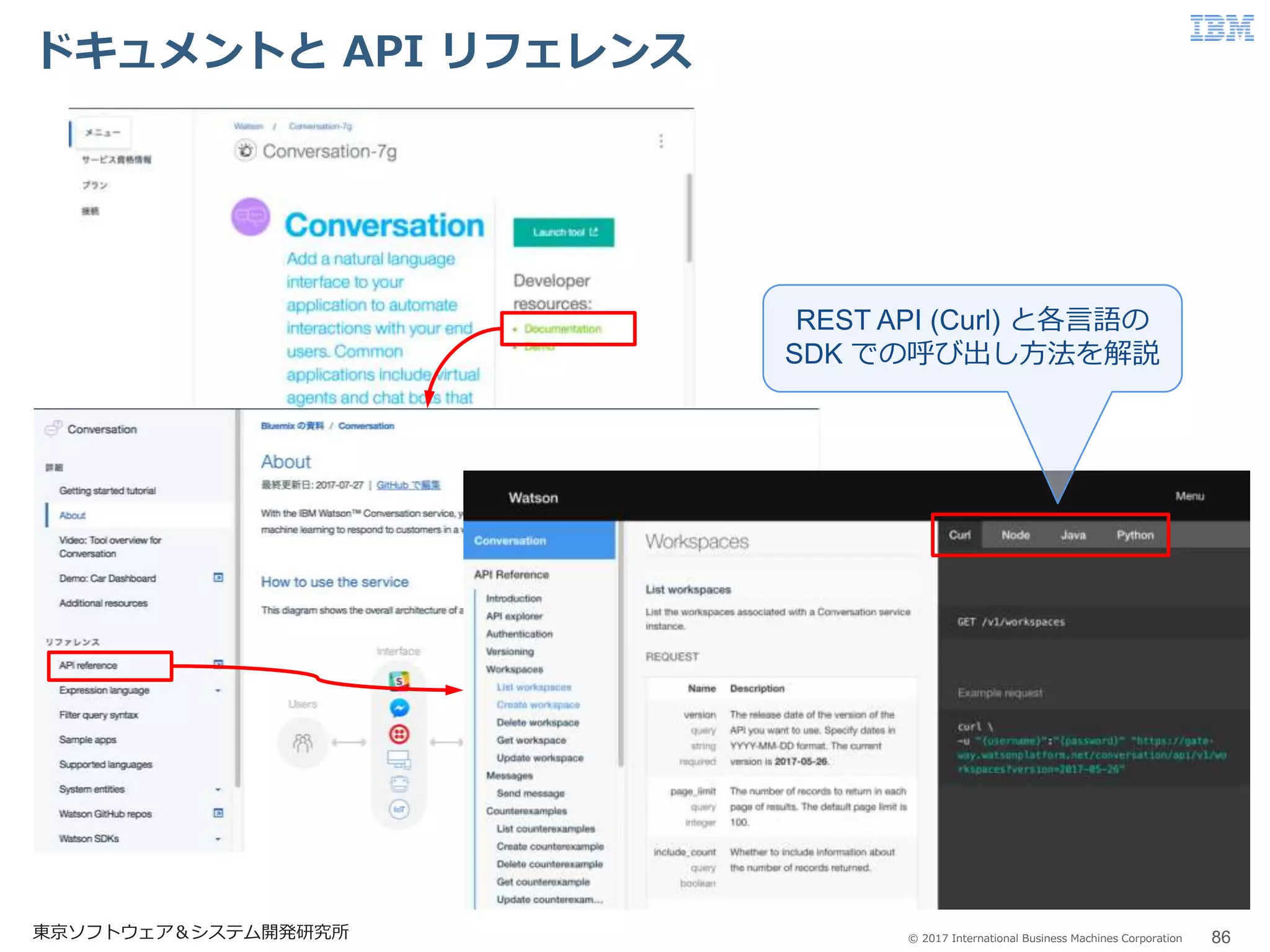
© 2017 International
Business Machines Corporation ドキュメントと API リフェレンス 86東京ソフトウェア&システム開発研究所 REST API (Curl) と各言語の SDK での呼び出し方法を解説
87.
© 2017 International
Business Machines Corporation Watson APIの利用方法 とりあえずWatson APIの機能を試す –curlコマンド: • RESTで公開されているWatson APIを呼び出す –Watson API explorer: • APIドキュメントに組み込まれた簡易API呼出しGUI – https://watson-api-explorer.mybluemix.net/ 簡易開発環境による利用 –Node-RED • Bluemixで利用できるビジュアル・プログラミング・ツール –OpenWhisk • Bluemixでサポートしているサーバーレスのプログラム実行環境 プログラム言語を用いた開発 –Node.js / Python / Java用にSDK Libraryを提供 東京ソフトウェア&システム開発研究所 87
88.
© 2017 International
Business Machines Corporation 【実習】APIからWatsonサービスを使用する 88 Natural Language Classifier Discovery (日本語未対応) Conversation Personality Insights Natural Language Understanding (日本語未対応) Tone Analyzer (日本語未対応) Speech to Text / Text to Speech Visual Recognition
89.
© 2017 International
Business Machines Corporation 実習内容 公開されている Tutorial や記事にしたがって、興味のある Watson サービスのトレーニングから利用までを体験します。 自分の Bluemix トライアルアカウントを使用してください。 対象となる Watson サービス –すべての Watson サービスが対象ですが、特に以下のサービスのいずれ かを試してください。 • Natural Language Classifier • Discovery (英語のみ) • Conversation • Personality Insight • Natural Language Understanding (英語のみ) • Tone Analyzer (英語のみ) • Speech to Text と Text to Speech • Visual Recognition 東京ソフトウェア&システム開発研究所 89
90.
© 2017 International
Business Machines Corporation 【実習】Natural Language Classifier 東京ソフトウェア&システム開発研究所 90 ツールキットを使用して NLC の分類器の作成と動作確認を行 います。サンプルの学習データは英語です。 –Natural Language Classifier / 独自データの使用 • https://console.bluemix.net/docs/services/natural-language-classifier/using-your-data.html –Natural Language Classifier /ツールキットを使用した分類子の管理 • https://console.bluemix.net/docs/services/natural-language-classifier/tool-overview.html#managing-toolkit –日本語に翻訳した学習データが以下にあります。 • https://ibm.co/2hYvqJy
91.
© 2017 International
Business Machines Corporation 【実習】Discovery (英語のみ) 東京ソフトウェア&システム開発研究所 91 Curl で REST API を呼び出して、Discovery の使い方を実習 します。(英語) –Discovery / Getting started with the Discovery API • https://www.ibm.com/watson/developercloud/doc/discovery/getting-started.html GUI ツールで Discovery の使い方を実習します。(英語) –Getting started with the Discovery tooling • https://www.ibm.com/watson/developercloud/doc/discovery/getting-started-tool.html 【推奨】 Discovery New を GUI で試します。 –developerWorks 記事: Watson Discovery を利用してニュースを探索し、 さまざまな洞察を引き出す – https://www.ibm.com/developerworks/jp/library/cc-watson-discovery-service- bluemix-explore/index.html
92.
© 2017 International
Business Machines Corporation 【実習】Conversation 東京ソフトウェア&システム開発研究所 92 Conversation での対話システムの開発実習です。(英語) –Conversation / Tutorial: Building a complex dialog • https://console.bluemix.net/docs/services/conversation/tutorial.html#tutorial Conversation の作成手順をビデオにまとめた資料です。 –Watson 「Conversation Service」を使用した会話フローの開発方法デ モンストレーション (ビデオ、13分54秒) – https://www.ibm.com/watson/jp-ja/developercloud/conversation.html Conversation での対話システムの開発実習です。1年前に作 成されたので内容がやや古いですが日本語です。 –Conversation サービスでの会話フロー作成実 • https://ibm.co/2hXQrUq
93.
© 2017 International
Business Machines Corporation 【実習】Personality Insight 東京ソフトウェア&システム開発研究所 93 Curl で REST API を呼び出して、Personality Insight の使 い方を実習します。(英語) –Personality Insight / Getting started • https://www.ibm.com/watson/developercloud/doc/personality-insights/getting-started.html
94.
© 2017 International
Business Machines Corporation 【実習】Natural Language Understanding (英語のみ) 東京ソフトウェア&システム開発研究所 94 Curl で REST API を呼び出して、Natural Language Understanding の使い方を実習します。(英語) –Natural Language Understanding / Getting started • https://www.ibm.com/watson/developercloud/doc/natural-language-understanding/getting- started.html
95.
© 2017 International
Business Machines Corporation 【実習】Tone Analyzer (英語のみ) 東京ソフトウェア&システム開発研究所 95 Curl で REST API を呼び出して、Tone Analyzer の使い方を 実習します。(英語) –Tone Analyzer / Getting started • https://www.ibm.com/watson/developercloud/doc/tone-analyzer/getting-started.html Tone Analyzerを使用した Python Web アプリの開発を解説 した記事です。 –developerWorks 記事: ツイートのテキストから感情を分析する • https://www.ibm.com/developerworks/jp/cognitive/library/cc-ask-watson-part2- bluemix-trs/index.html –
96.
© 2017 International
Business Machines Corporation 【実習】Speech to Text (STT) と Text to Speech (TTS) 東京ソフトウェア&システム開発研究所 96 API Explorer で REST API を呼び出して STT/TTS の使い方 を実習します。 –デモ:Watsonの音声認識APIで英語の発声練習アプリを構築(STT/TTS) • https://www.youtube.com/watch?v=iTlDipSXaUI SDK を使用して STT/TTS を試す Web ページを作成します。 Node.js アプリに STT/TTS を組み込む際の参考資料です。 –speech-javascript-sdk を試す • https://ibm.co/2hXxrp6 STT/TTS のカスタマイズの方法をまとめた記事です。 –Text to Speech サービス > 音声合成でのカスタムモデルの使用 • https://ibm.co/2hXUfoG –Speech to Text サービス > 音声認識でのカスタムモデルの使用 • https://ibm.co/2hZEzl8
97.
© 2017 International
Business Machines Corporation 【実習】Visual Recognition 東京ソフトウェア&システム開発研究所 97 フライトチキンとラブラドールを識別するカスタム分類器の 作成を紹介した記事です。 –Qiita: Visual Recognition V3利用時の考慮事項~フライドチキンと犬の 再評価からわかったこと~ • http://qiita.com/VegaSato/items/863b614cd5ab88cf2d44 Visual Recognition デモページでのカスタム分類器の作成す ることもできます。 • https://visual-recognition-demo.mybluemix.net/ Curl で REST API を呼び出して、 Visual Recognition の使 い方を実習します。(英語) –Visual Recognition / Tutorial: Creating a custom classifier • https://www.ibm.com/watson/developercloud/doc/visual-recognition/tutorial-custom-classifier.html –Visual Recognition / Tutorial: Finding similar images • https://www.ibm.com/watson/developercloud/doc/visual-recognition/tutorial-collections.html
98.
© 2017 International
Business Machines Corporation End of Document 98
Editor's Notes
#15
こちらの特許文書を例に、Watson Knowledge Studio で業務文者の情報を Watson に教え込む方法をご説明します。 この特許文書は、医療における画像診断装置の特許の例文です。専門家でないと何が書かれているのかよくわかりません。このような文書から得たい情報は、ここに書かれているように 構成するハードウエアやユニット 対象となる部位 生成される画像やデータ といったことです。これらには非常に専門性の高い用語が含まれており、標準の Watson の自然言語処理では十分な分析ができないかもしれません。 そこで、分析したい用語や関係に応じた業務分野の情報抽出器が必要となります。 まずはじめに、サンプルの文章でどのような情報、つまりエンティティや関係を抽出したいかを Watson に教えます。これはプログラマーというよりはその業務分野の専門家に行っていただく仕事です。
#16
そして、それらのエンティティの関係、ハードウェアを構成するユニットや、ユニットとそこから生成される画像やデータと言った関係を重要です。 このような抽出すべき情報の例を、その業務分野の専門家があらかじめサンプル文書で Watson に教育し、機械学習を行った Watson がそこから抽出すべき情報を学び、新たに受け取る文書の分析を行うようになります。
#17
このように専門家によってあらかじめエンティティや関係などを注釈つけされたサンプル文書、つまり正解データを作ります。 それらを元に機械学習を行うことで、業務分野の専門用語を分析する情報抽出器を生成することができます。 そしてこのように生成された情報抽出機を使って、業務分野の大量の文書を処理することで、その文書に含まれるエンティティや関係の情報を抽出して、文章に含まれる知見を見出すことが可能となります。 この情報抽出器を実際に使用するのが、今日ご紹介する Watson Discovery であったり、Natural Language Understanding や Watson Explorer です。
Download


































![© 2017 International Business Machines Corporation
音声でのキーワードの検出(Keyword Spotting)
62東京ソフトウェア&システム開発研究所
ルノワールを検出するよう構成した例
{
"results": [
{
"keywords_result": {
"ルノワール": [
{
"normalized_text": "ルノワール",
"start_time": 0.44,
"confidence": 0.885,
"end_time": 1.02
}
]
},
"alternatives": [
{
"confidence": 0.835,
"transcript": "ルノワール 展 見て きた "
}
<後略>
}
検出された
開始時間
終了時間](https://image.slidesharecdn.com/ibmwatsonapi20170824-170831134902/75/Ibm-watson-api-62-2048.jpg)







































![[2017年11月22日] Call Center Watsonのご紹介(日本IBM GTS Innovation Forum 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/innovationforum09callcenterwatson20171122-171122123546-thumbnail.jpg?width=640&height=640&fit=bounds)



















