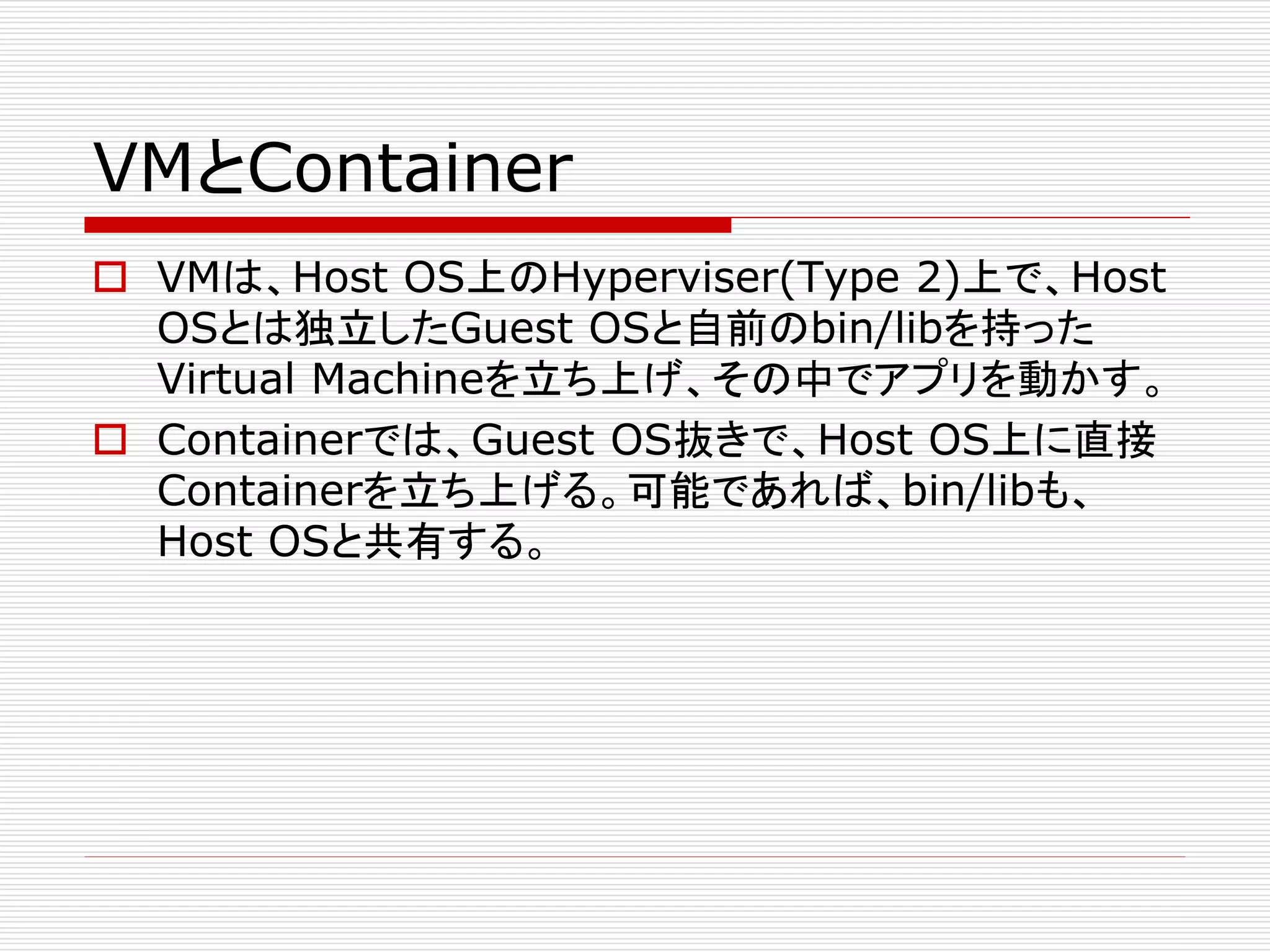
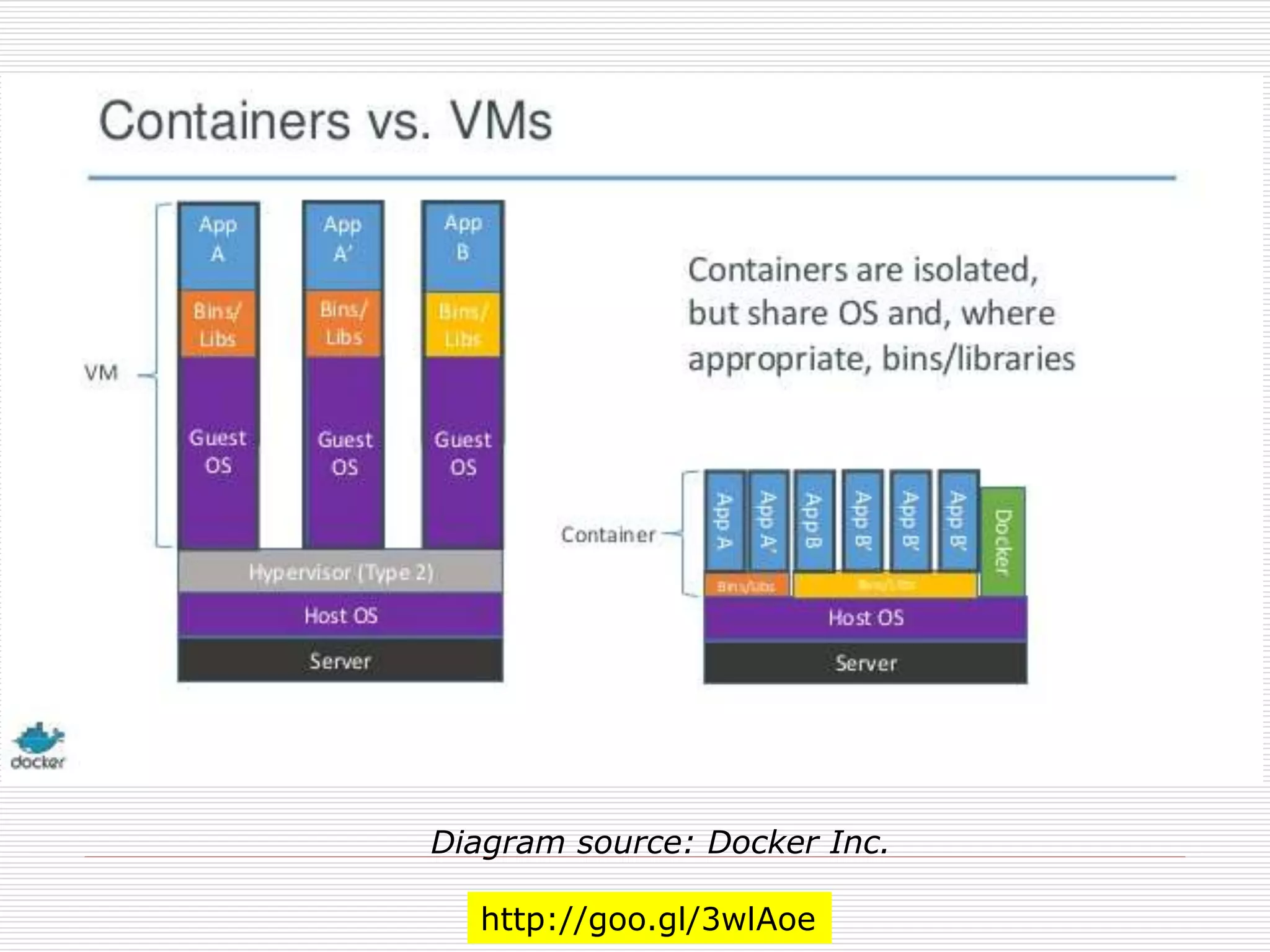
Docker and KernelSecurity
Systems
Linuxのホスト・システムのセキュリティを強固なものにす
るために、kernelのセキュルティ・システムが存在する。
それには、 Linux capabilitiesとLinux Security
Module (LSM)が含まれる。 Linux capabilitiesは、そ
れぞれのプロセスに与えられた特権を制限し、LSMは、
Linux kernelが、異なったセキュリティ・モデルをサポー
トすることを可能にするフレームワークを提供する。公式
のLinux kernekに統合されたLSMには、
AppArmor 、SELinux、Seccompが含まれる。
35.
Linux Capabilities
Linuxcapabilitiesのマニュアル・ページで述べられてい
るように、伝統的には、Unixシステムは、プロセスを二つ
のカテゴリーに分類する。(スーパー・ユーザーすなわち
rootに所有される)特権プロセスと、(通常のユーザーに
所有される)非特権プロセスである。
kernelは、特権プロセスについては、すべてのパーミッ
ション・チェックをスキップし、非特権プロセスについては
完全なパーミッション・チェックを行う。しかしながら、
Linux kernelは、バージョン 2.2以降は、スーパーユー
ザーの特権をCapabilityに分割し、kernelは、それを、
それぞれ独立に、有効にしたり無効にできる。
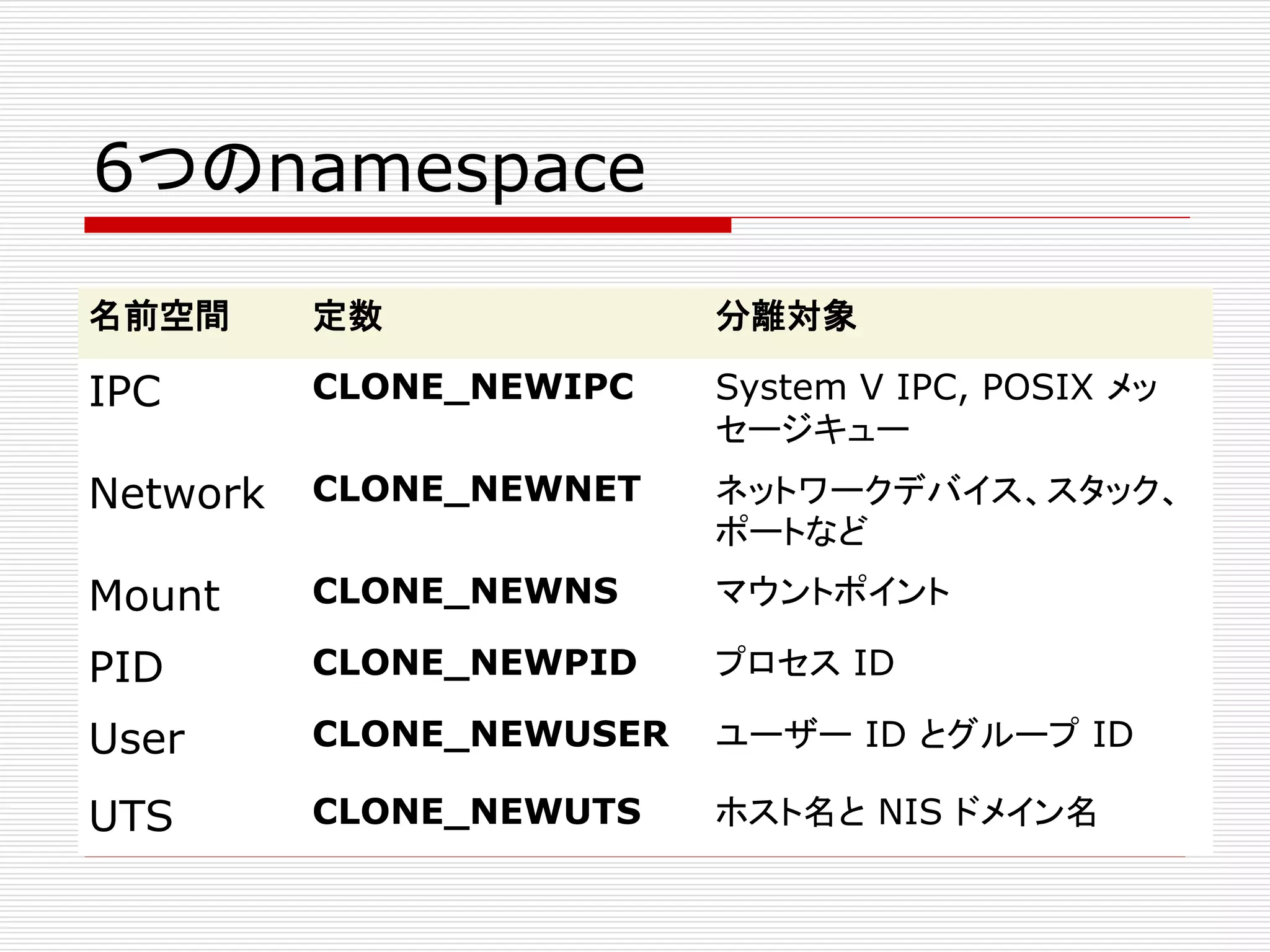
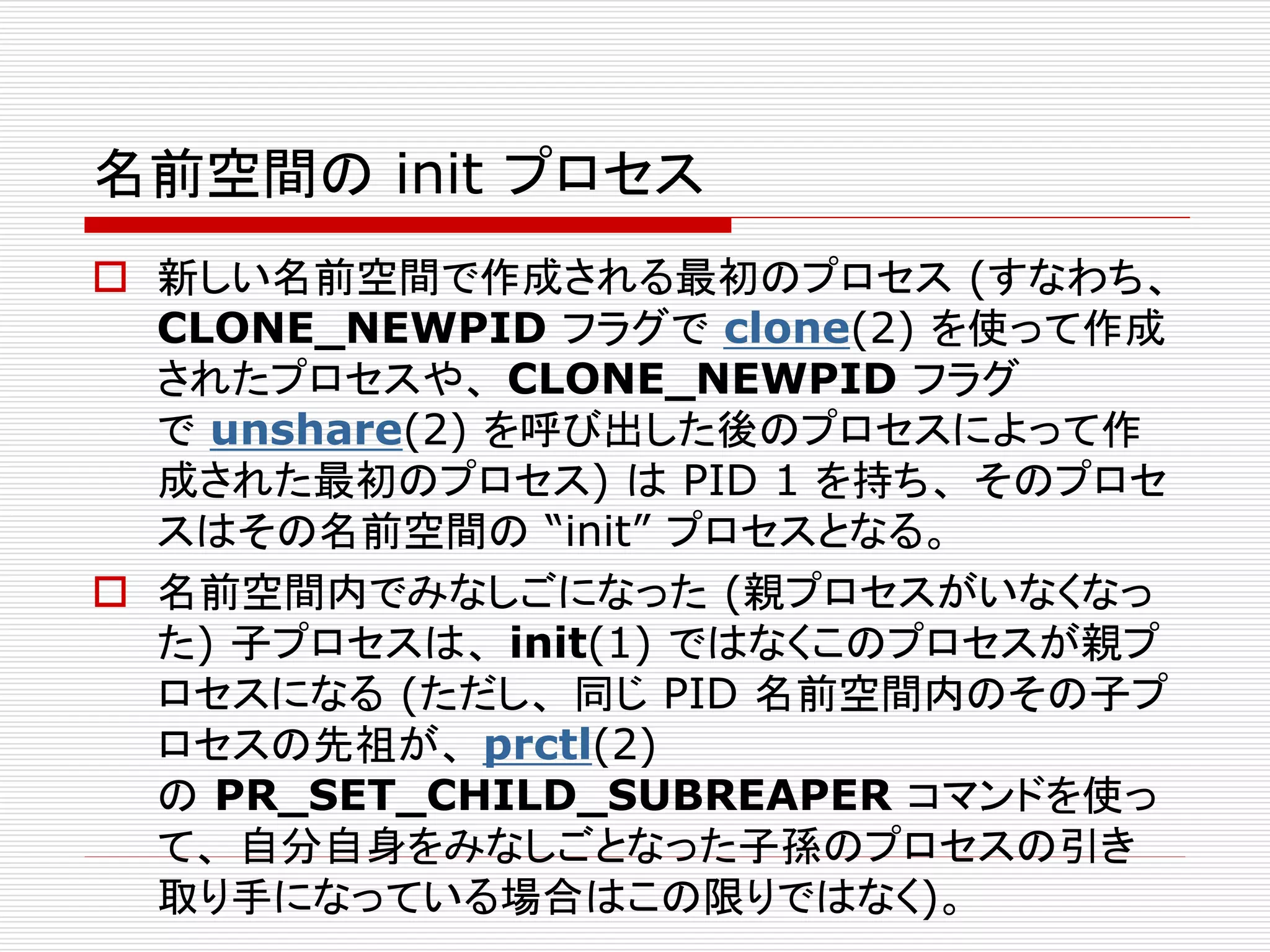
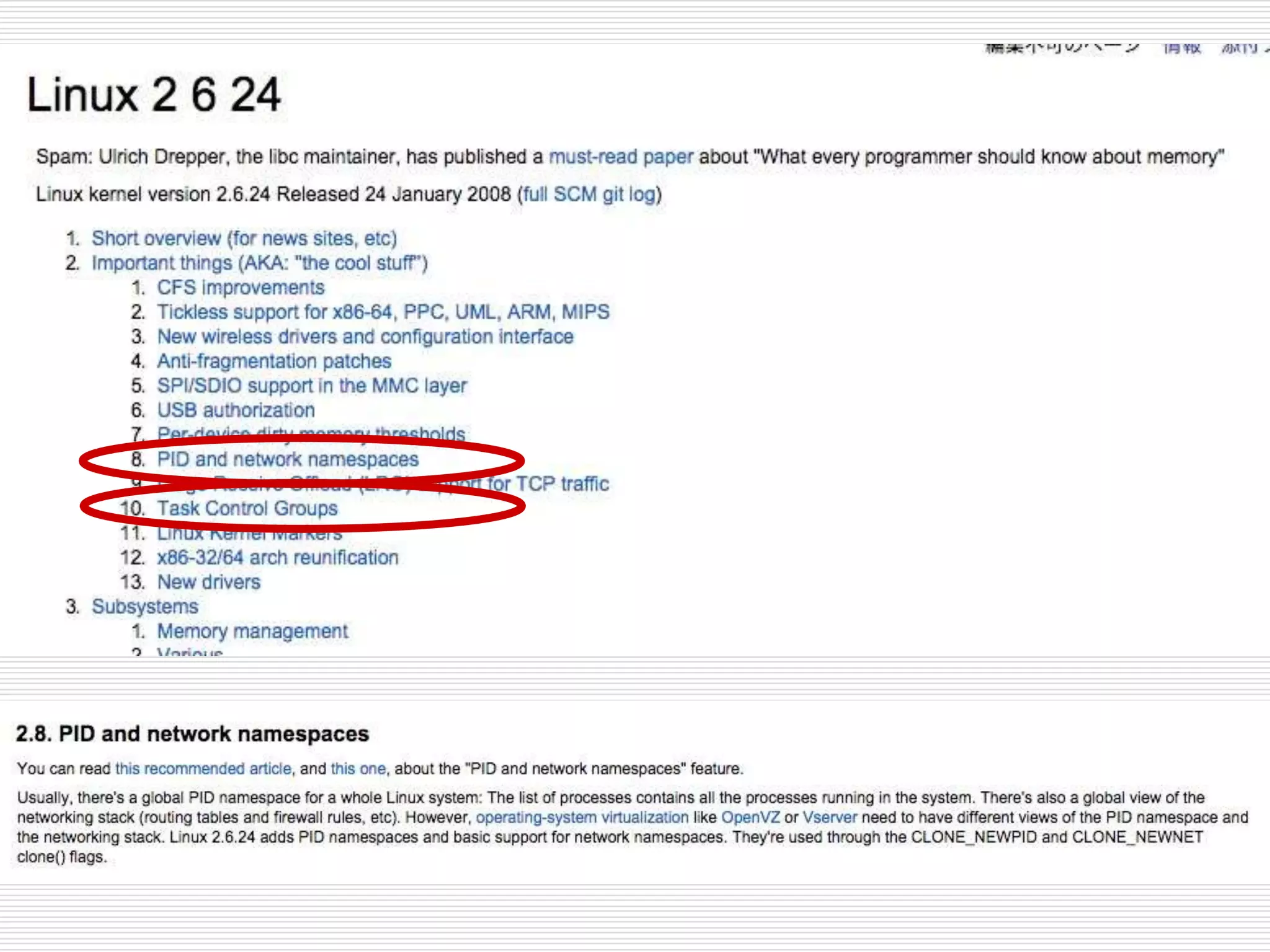
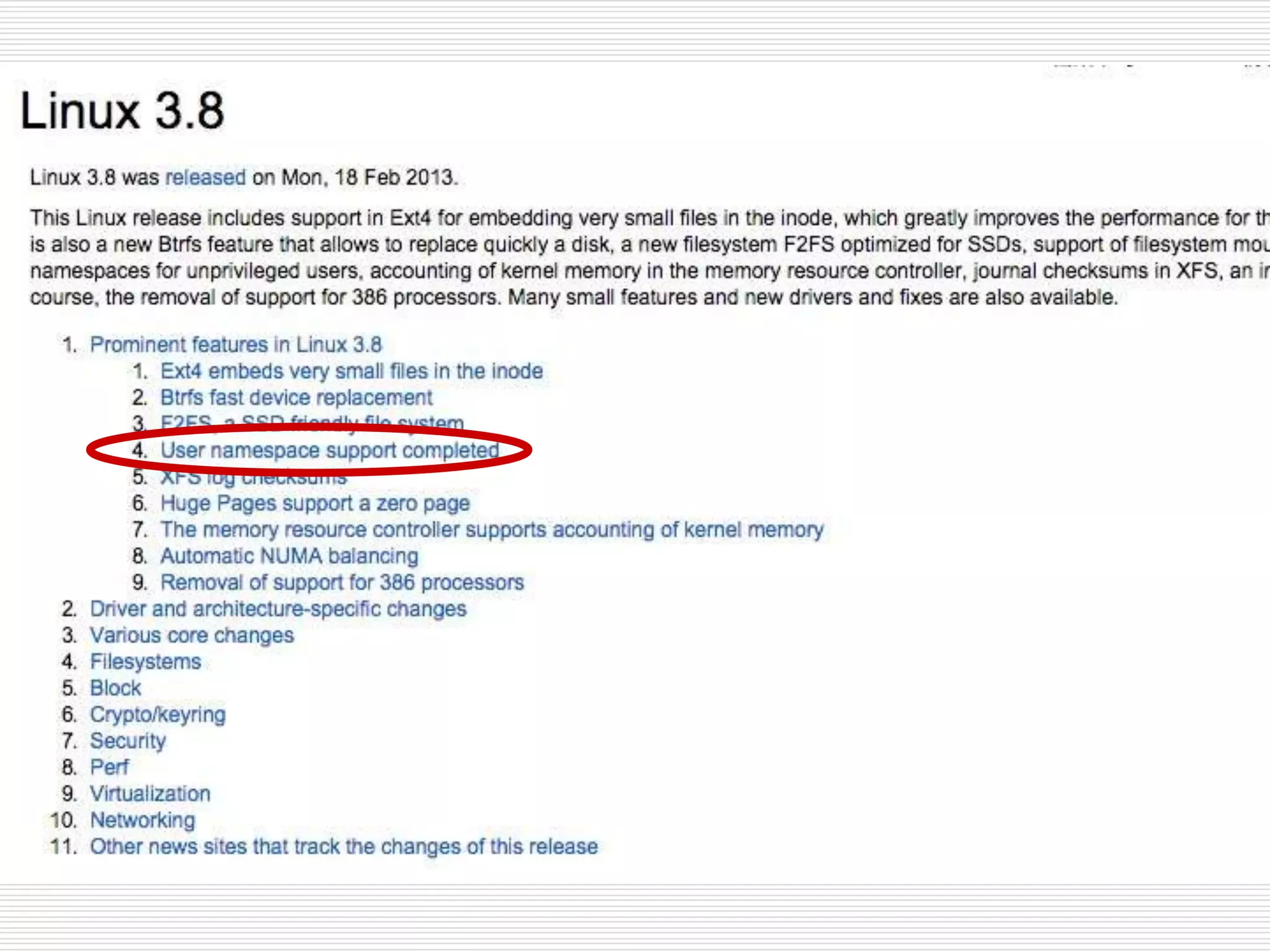
6つのnamespace
名前空間 定数 分離対象
IPCCLONE_NEWIPC System V IPC, POSIX メッ
セージキュー
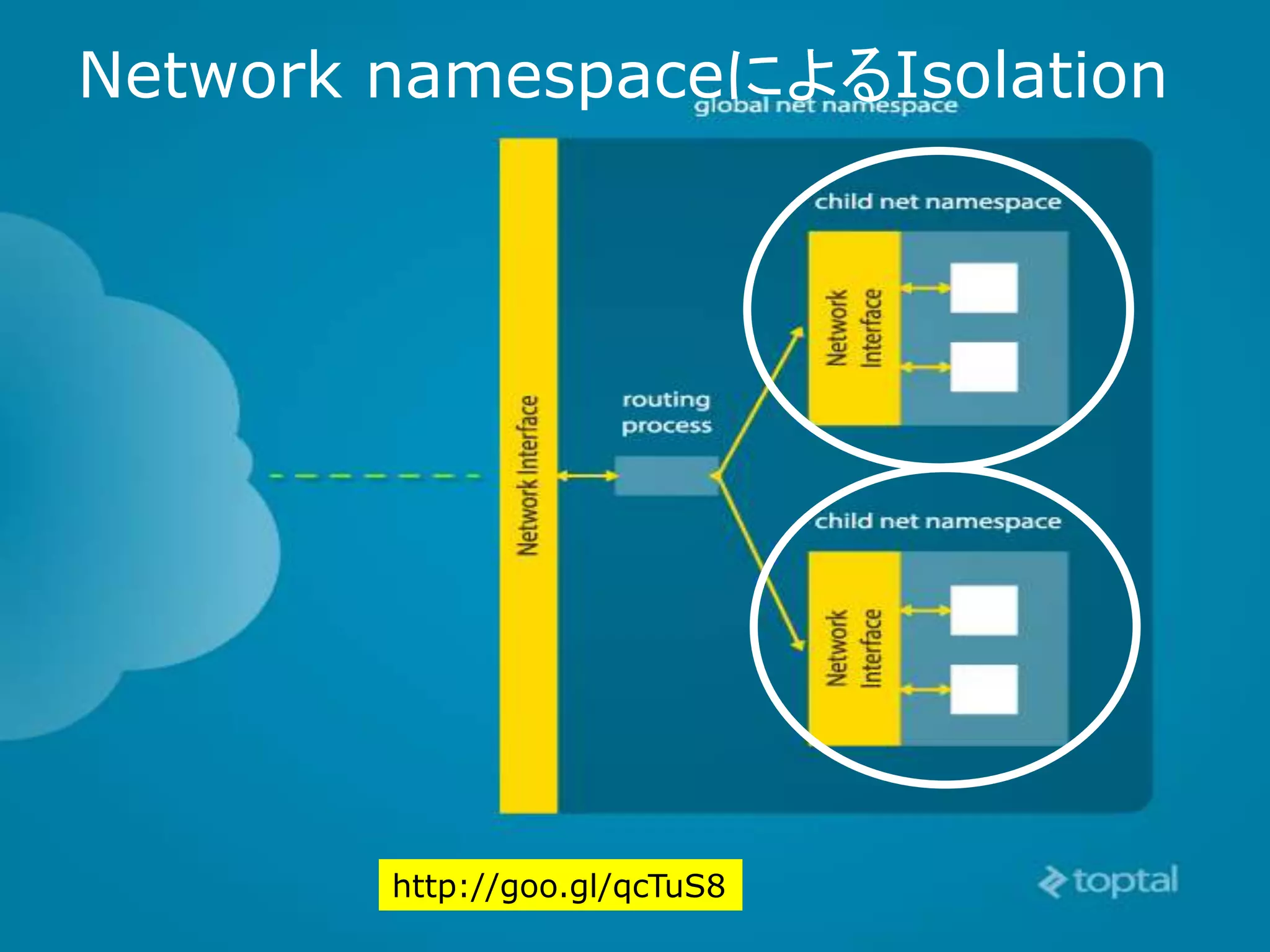
Network CLONE_NEWNET ネットワークデバイス、スタック、
ポートなど
Mount CLONE_NEWNS マウントポイント
PID CLONE_NEWPID プロセス ID
User CLONE_NEWUSER ユーザー ID とグループ ID
UTS CLONE_NEWUTS ホスト名と NIS ドメイン名
サンプル
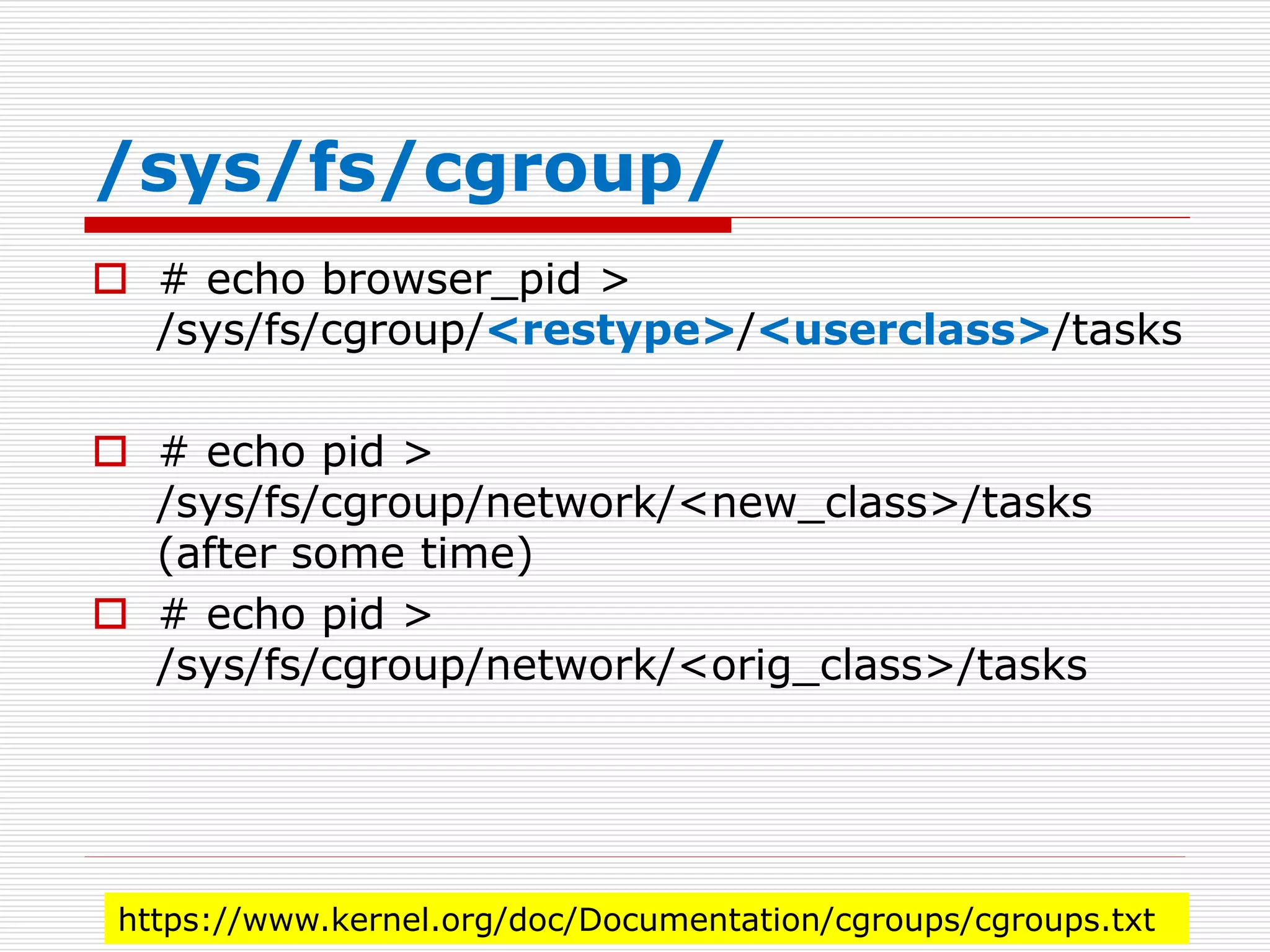
/sys/fs/cgroup/cpuset/Charlie
mount -t tmpfscgroup_root /sys/fs/cgroup
mkdir /sys/fs/cgroup/cpuset
mount -t cgroup cpuset -ocpuset /sys/fs/cgroup/cpuset
cd /sys/fs/cgroup/cpuset
mkdir Charlie
cd Charlie
/bin/echo 2-3 > cpuset.cpus
/bin/echo 1 > cpuset.mems
/bin/echo $$ > tasks
sh
https://www.kernel.org/doc/Documentation/cgroups/cgroups.txt
81.
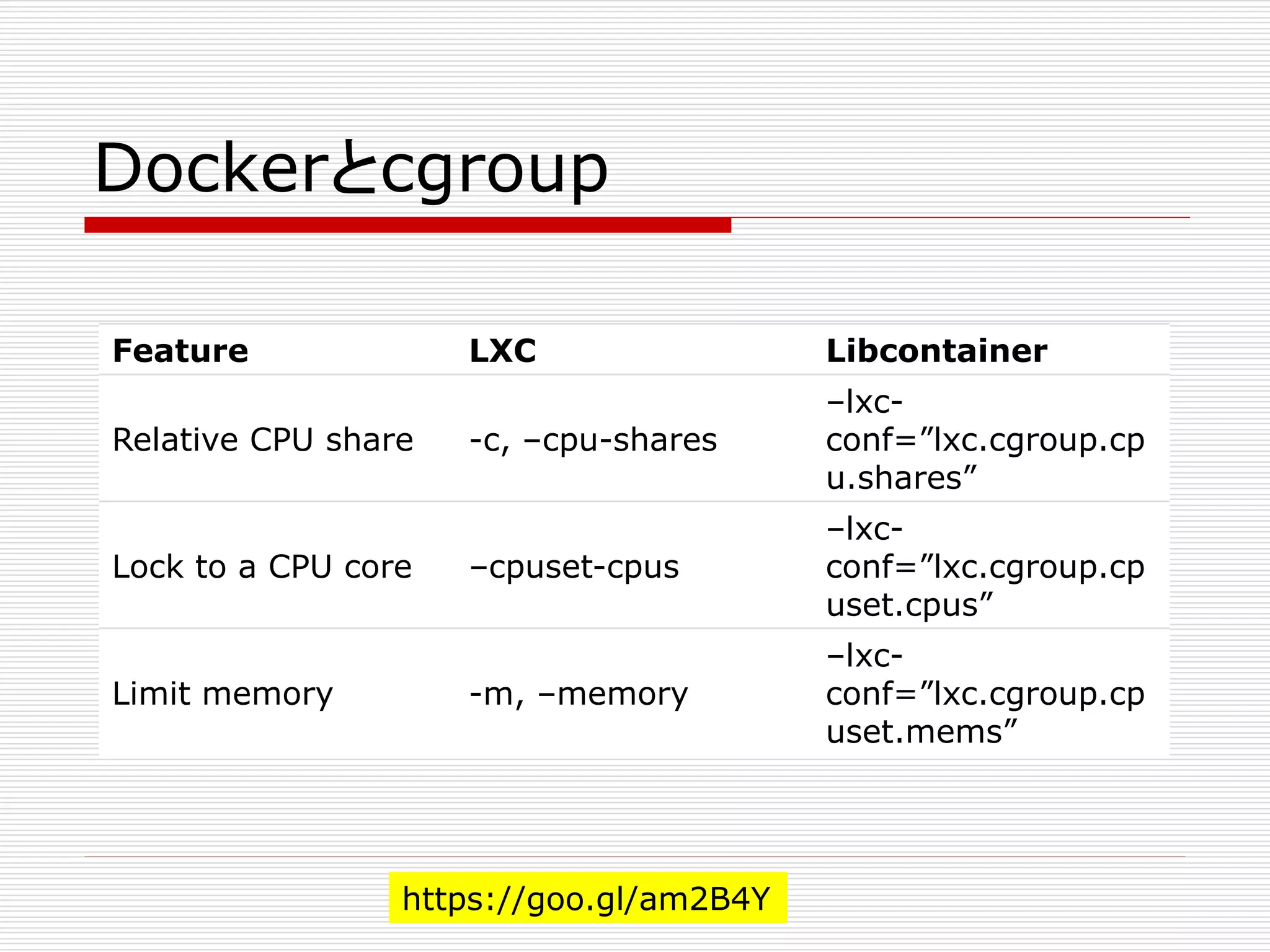
Dockerとcgroup
# Withthe LXC driver
$ docker run -d --name='lxc_test'
--lxc-conf="lxc.cgroup.cpu.shares=50"
busybox
# With the libcontainer driver
$ docker run -d --name='libcontainer_test'
--cpu-shares=50
busybox
https://goo.gl/am2B4Y
82.
Dockerとcgroup
Feature LXC Libcontainer
RelativeCPU share -c, –cpu-shares
–lxc-
conf=”lxc.cgroup.cp
u.shares”
Lock to a CPU core –cpuset-cpus
–lxc-
conf=”lxc.cgroup.cp
uset.cpus”
Limit memory -m, –memory
–lxc-
conf=”lxc.cgroup.cp
uset.mems”
https://goo.gl/am2B4Y
83.
Available Subsystems in
RedHat Enterprise Linux
blkio — this subsystem sets limits on input/output
access to and from block devices such as physical drives
(disk, solid state, USB, etc.).
cpu — this subsystem uses the scheduler to provide
cgroup tasks access to the CPU.
cpuacct — this subsystem generates automatic reports
on CPU resources used by tasks in a cgroup.
cpuset — this subsystem assigns individual CPUs (on a
multicore system) and memory nodes to tasks in a
cgroup.
devices — this subsystem allows or denies access to
devices by tasks in a cgroup.
freezer — this subsystem suspends or resumes tasks in
a cgroup.
https://goo.gl/EHpRNb
84.
Available Subsystems in
RedHat Enterprise Linux
memory — this subsystem sets limits on memory use
by tasks in a cgroup, and generates automatic reports
on memory resources used by those tasks.
net_cls — this subsystem tags network packets with a
class identifier (classid) that allows the Linux traffic
controller (tc) to identify packets originating from a
particular cgroup task.
net_prio — this subsystem provides a way to
dynamically set the priority of network traffic per
network interface.
ns — the namespace subsystem
https://goo.gl/EHpRNb
参考文献
Analysis ofDocker Security
http://arxiv.org/pdf/1501.02967v1.pdf
Separation Anxiety: A Tutorial for Isolating
Your System with Linux Namespaces
http://www.toptal.com/linux/separation-anxiety-
isolating-your-system-with-linux-namespaces
PID namespaces in the 2.6.24 kernel
http://lwn.net/Articles/259217/
Bringing new security features to Docker
https://opensource.com/business/14/9/security-for-
docker
100.
Linux Manual Page
Namespaces
http://linuxjm.osdn.jp/html/LDP_man-
pages/man7/namespaces.7.html
PID namespaces
http://linuxjm.osdn.jp/html/LDP_man-
pages/man7/pid_namespaces.7.html
User namespaces
http://linuxjm.osdn.jp/html/LDP_man-
pages/man7/user_namespaces.7.html
Capability
http://linuxjm.osdn.jp/html/LDP_man-
pages/man7/capabilities.7.html
101.
Linux Manual Page
LXC
http://linux.die.net/man/7/lxc
CGROUPS
https://www.kernel.org/doc/Documentation/cgroups/cgr
oups.txt








































![namespace API setns
setns(2) システムコールを使うと、呼び出したプロセス
を既存の名前空間に参加させることができる。 参加する
名前空間は、 以下で説明する/proc/[pid]/ns ファイル
のいずれか一つを参照するファイルディスクリプターを
使って指定する。](https://image.slidesharecdn.com/isolation-160405232454/75/Container-Name-Space-Isolation-44-2048.jpg)

![/proc/[pid]/ns/ ディレクトリ
各プロセスには /proc/[pid]/ns/ サブディレクトリがあり、
このサブディレクトリには setns(2) での操作がサポート
されている名前空間単位にエントリーが存在する。
一つ一つのプロセスごとに、6つのnamespaceが、対応
していることに、注意。
$ ls -l /proc/$$/ns
total 0
lrwxrwxrwx. 1 mtk mtk 0 Jan 14 01:20 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 mtk mtk 0 Jan 14 01:20 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 mtk mtk 0 Jan 14 01:20 net -> net:[4026531956]
lrwxrwxrwx. 1 mtk mtk 0 Jan 14 01:20 pid -> pid:[4026531836]
lrwxrwxrwx. 1 mtk mtk 0 Jan 14 01:20 user -> user:[4026531837]
lrwxrwxrwx. 1 mtk mtk 0 Jan 14 01:20 uts -> uts:[4026531838]](https://image.slidesharecdn.com/isolation-160405232454/75/Container-Name-Space-Isolation-46-2048.jpg)
![/proc/[pid]/ns/ ディレクトリ
このディレクトリ内のファイルのいずれかをファイルシステ
ムの他のどこかにバインドマウント (mount(2) 参照)
することで、 その名前空間のすべてのプロセスが終了し
た場合でも、 pid で指定したプロセスの対応する名前空
間を保持することができる。
このディレクトリ内のファイルのいずれか (またはこれらの
ファイルのいずれかにバインドマウントされたファイル) を
オープンすると、 pid で指定されたプロセスの対応する
名前空間に対するファイルハンドルが返される。 このファ
イルディスクリプターがオープンされている限り、 その名
前空間のすべてのプロセスが終了した場合であっても、
その名前空間は存在し続ける。 このファイルディスクリプ
ターは setns(2) に渡すことができる。](https://image.slidesharecdn.com/isolation-160405232454/75/Container-Name-Space-Isolation-47-2048.jpg)


![Mount namespace
(CLONE_NEWNS)
マウント名前空間はファイルシステムのマウントポイントの
集合を分離する。 つまり、別のマウント名前空間のプロセ
スには別のファイルシステム階層が見えるということであ
る。 マウント名前空間内のマウントの集合
は mount(2) と umount(2) で変更される。
/proc/[pid]/mounts ファイル (Linux 2.4.19 以降に
存在) は、 そのプロセスのマウント名前空間で現在マウ
ントされている全ファイルシステムの一覧を表示する。 こ
のファイルのフォーマットは fstab(5) に記載されている。](https://image.slidesharecdn.com/isolation-160405232454/75/Container-Name-Space-Isolation-51-2048.jpg)























![cgroups
cgroups (control groups) とは、プロセスグルー
プのリソース(CPU、メモリ、ディスクI/Oなど)の利用
を制限・隔離するLinuxカーネルの機能。“process
containers” という名称で Rohit Seth が2006年
9月から開発を開始し[1]、2007年に cgroups と名
称変更され、2008年1月に Linux カーネル 2.6.24
にマージされた[2]。それ以来、多くの機能とコントロー
ラが追加された。
https://ja.wikipedia.org/wiki/Cgroups](https://image.slidesharecdn.com/isolation-160405232454/75/Container-Name-Space-Isolation-76-2048.jpg)







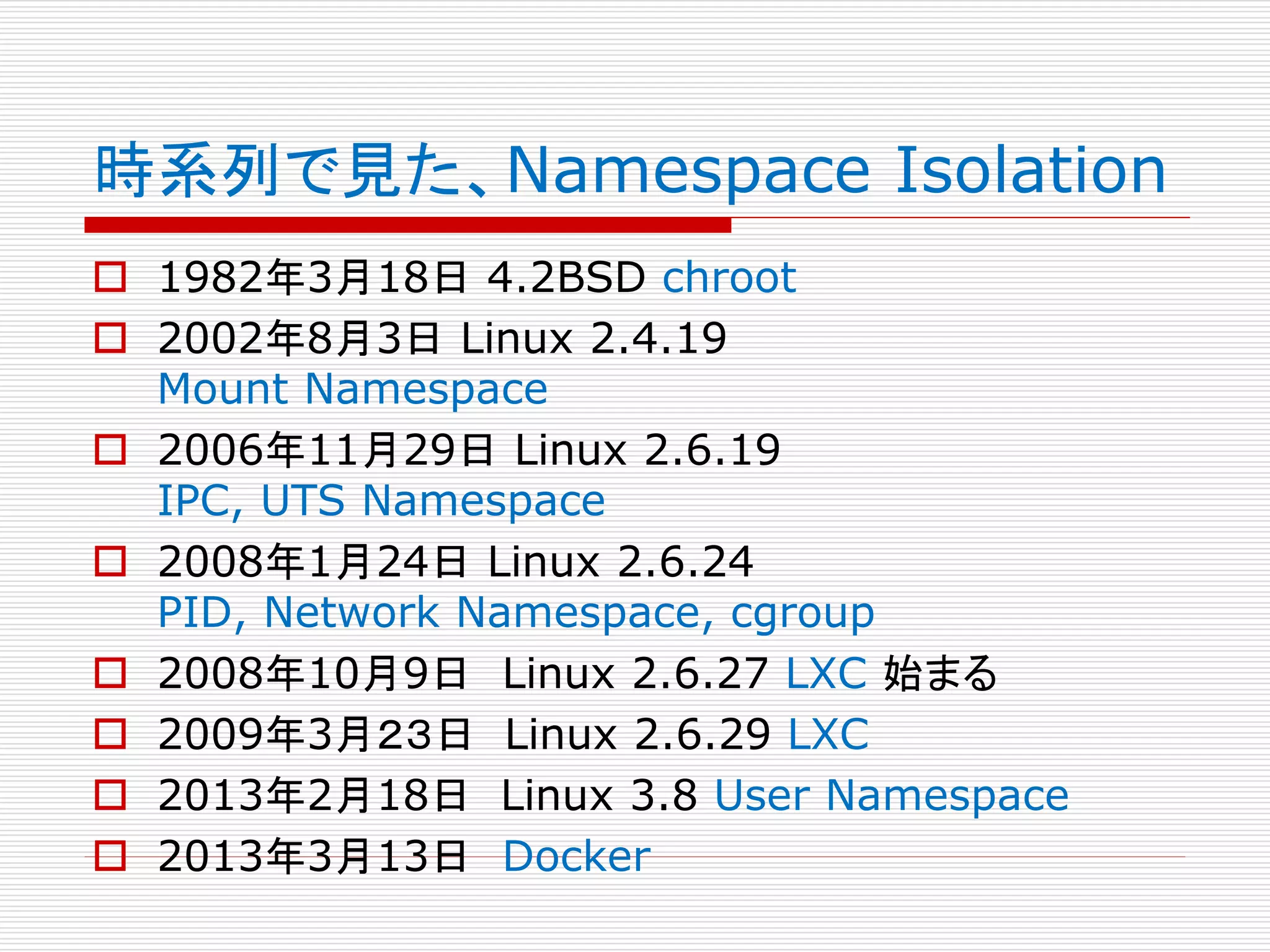
![Linux 2.4.19 (2002年8月3日)
Mount Namespace
まず、Linux 2.4.19 (2002年8月3日リリース) で、
mountのnamespaceが初めて登場する。13年以上昔
の話だ。ソースをダウンロードしたのだが、当時のLinux
は、tar.gzで32Mしかなかった。CHANGESも読んでみ
たが、namespaceの話は、全然、登場しない。ひっそりと
世に出た。
この時のnamespace.h, namaspace.c は、もっぱら、
(Virtual) File Systemの mount, umountに関わっ
たものだった。面白いのは、こうした役割と構成が、現
バージョンのLinuxの namespace,[hc]でも受け継が
れているように見えること。もっとも、ここでのmount,
umountは、きちんとContainer用のNamespaceに対
応しているのだが。](https://image.slidesharecdn.com/isolation-160405232454/75/Container-Name-Space-Isolation-86-2048.jpg)















![[社内勉強会]ELBとALBと数万スパイク負荷テスト](https://cdn.slidesharecdn.com/ss_thumbnails/elbalb-160822022623-thumbnail.jpg?width=640&height=640&fit=bounds)

























































![8a1#19[はじめてのdocker] 公開版](https://cdn.slidesharecdn.com/ss_thumbnails/8a117docker-150313082448-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)


























