Downloaded 11 times















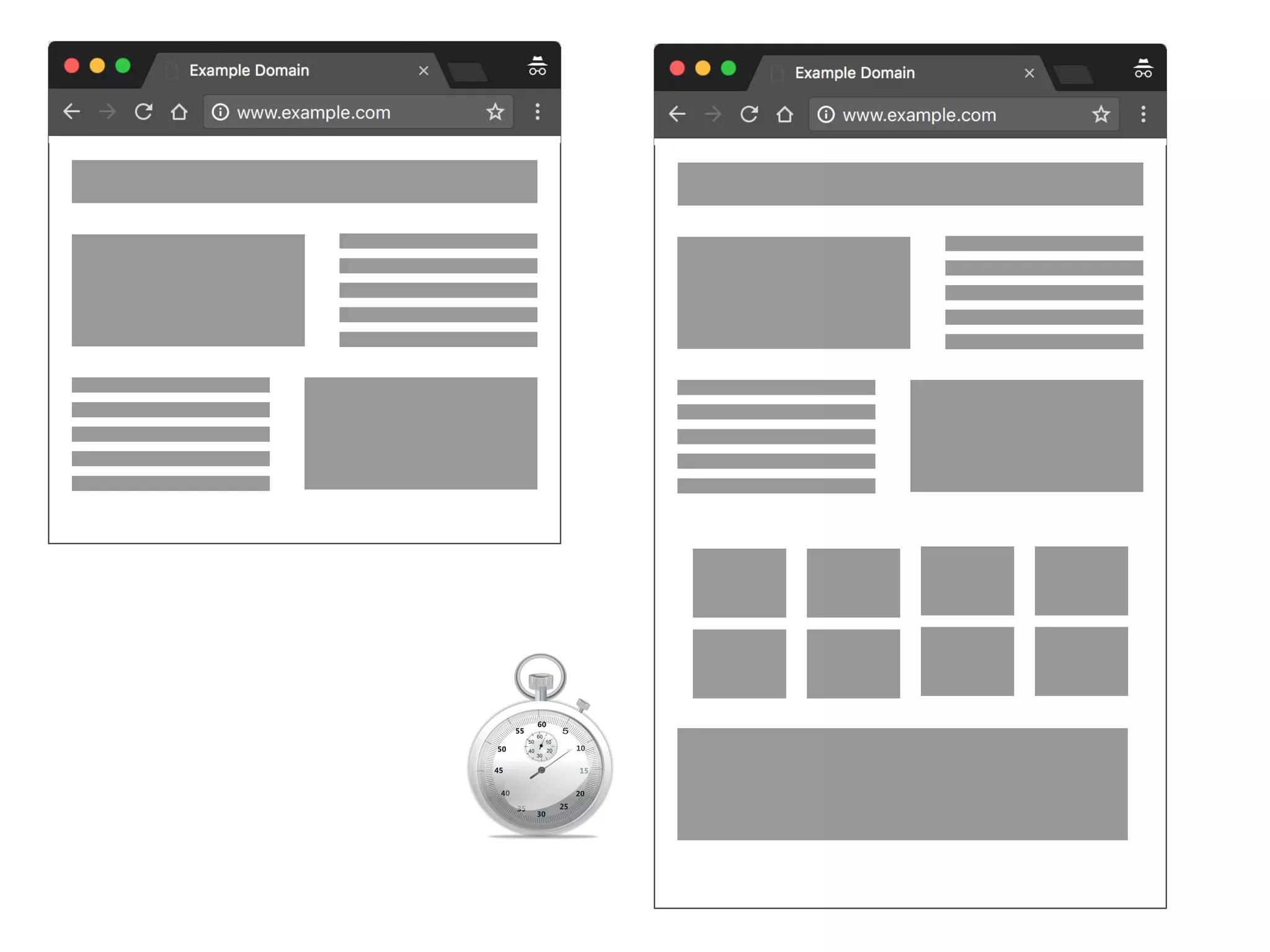





![is the core of the problem we
have to solve [...] legitimately difficult problems.
is all the stuff that doesn’t
necessarily relate directly to the solution, but that we
have to deal with anyway.
Neal Ford, Investigating Architecture and Design (2009)](https://image.slidesharecdn.com/tenpracticalwaystoimprovefront-endperformance-170623135008/75/Ten-practical-ways-to-improve-front-end-performance-26-2048.jpg)



























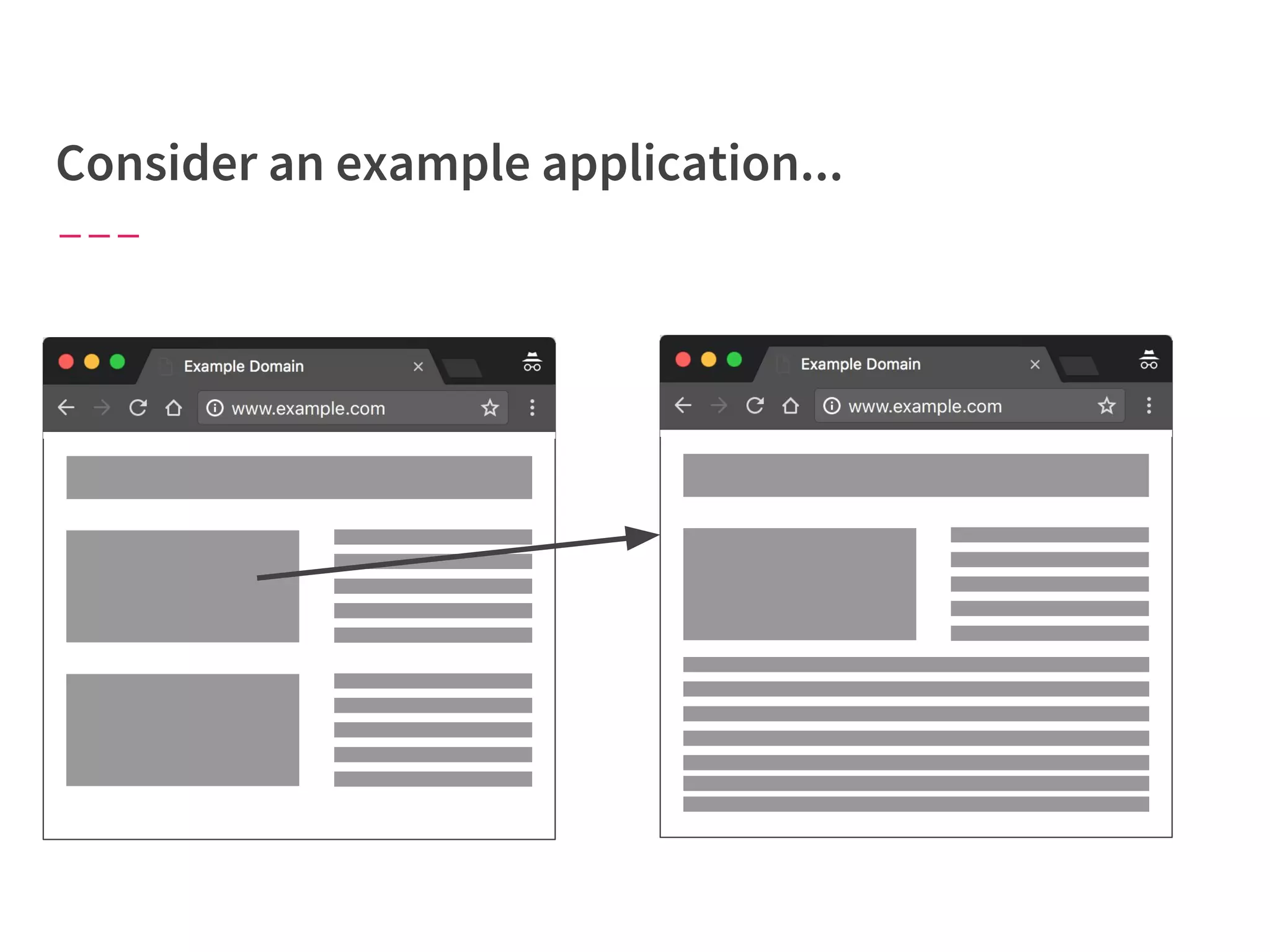
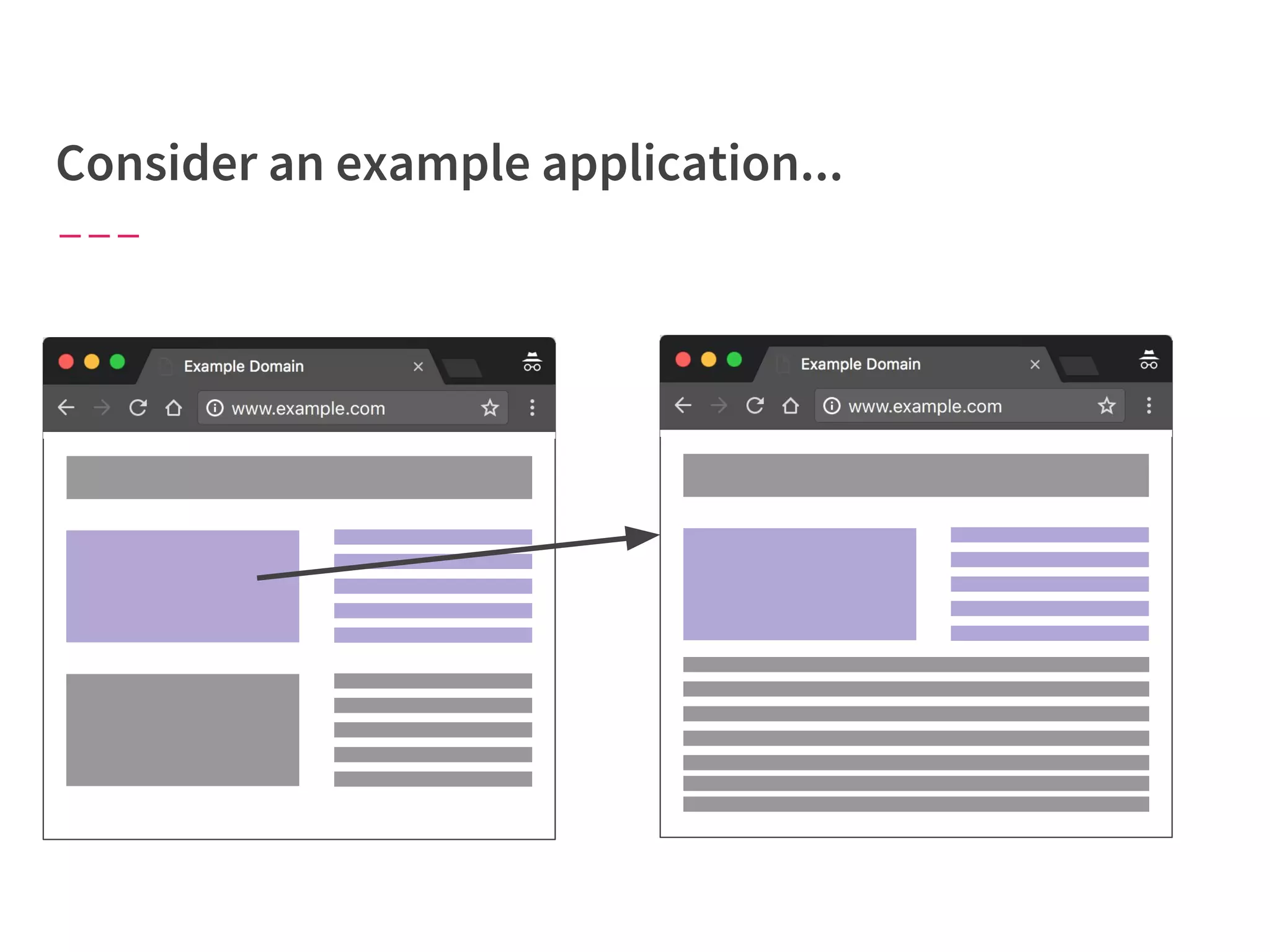

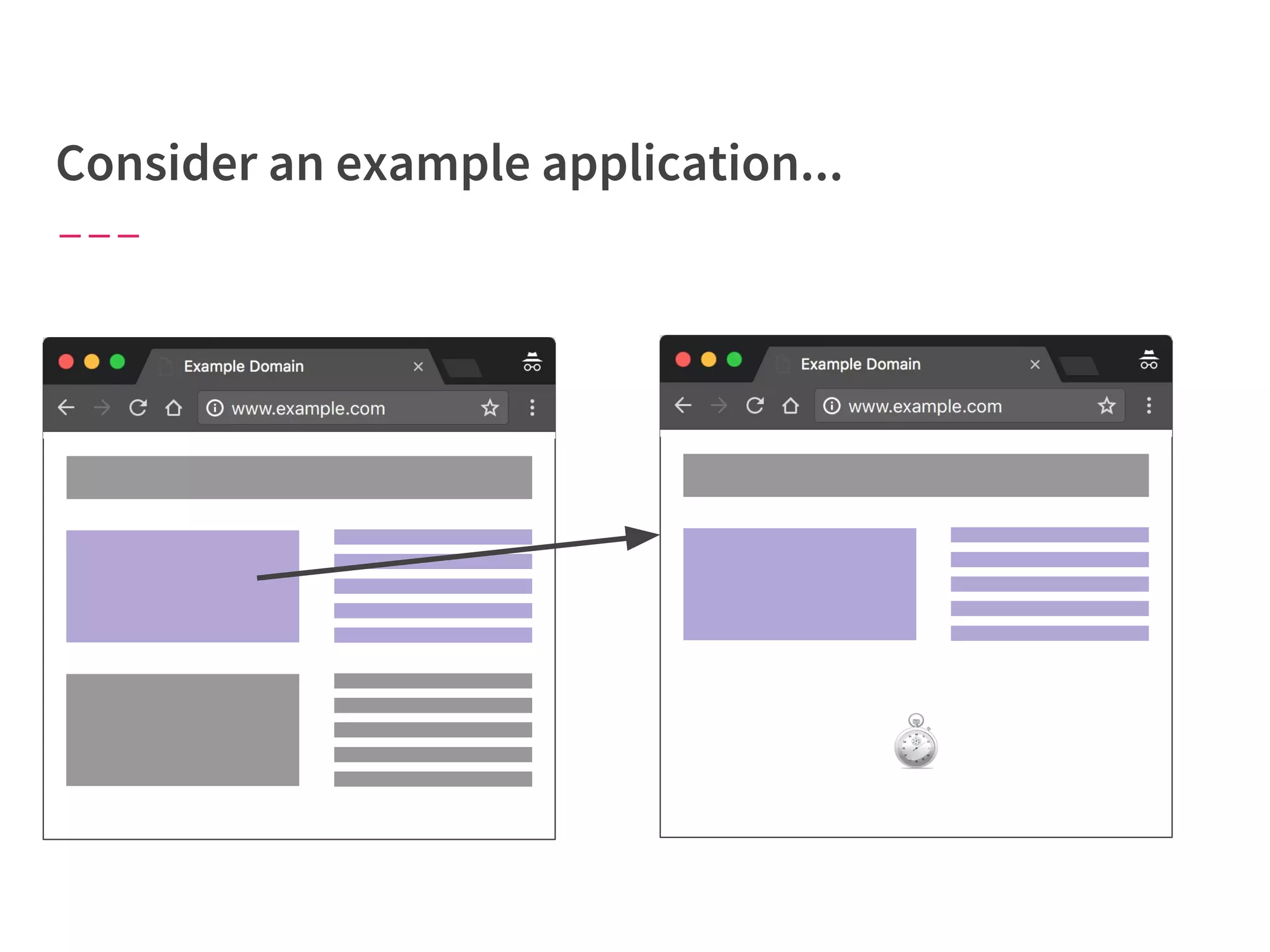
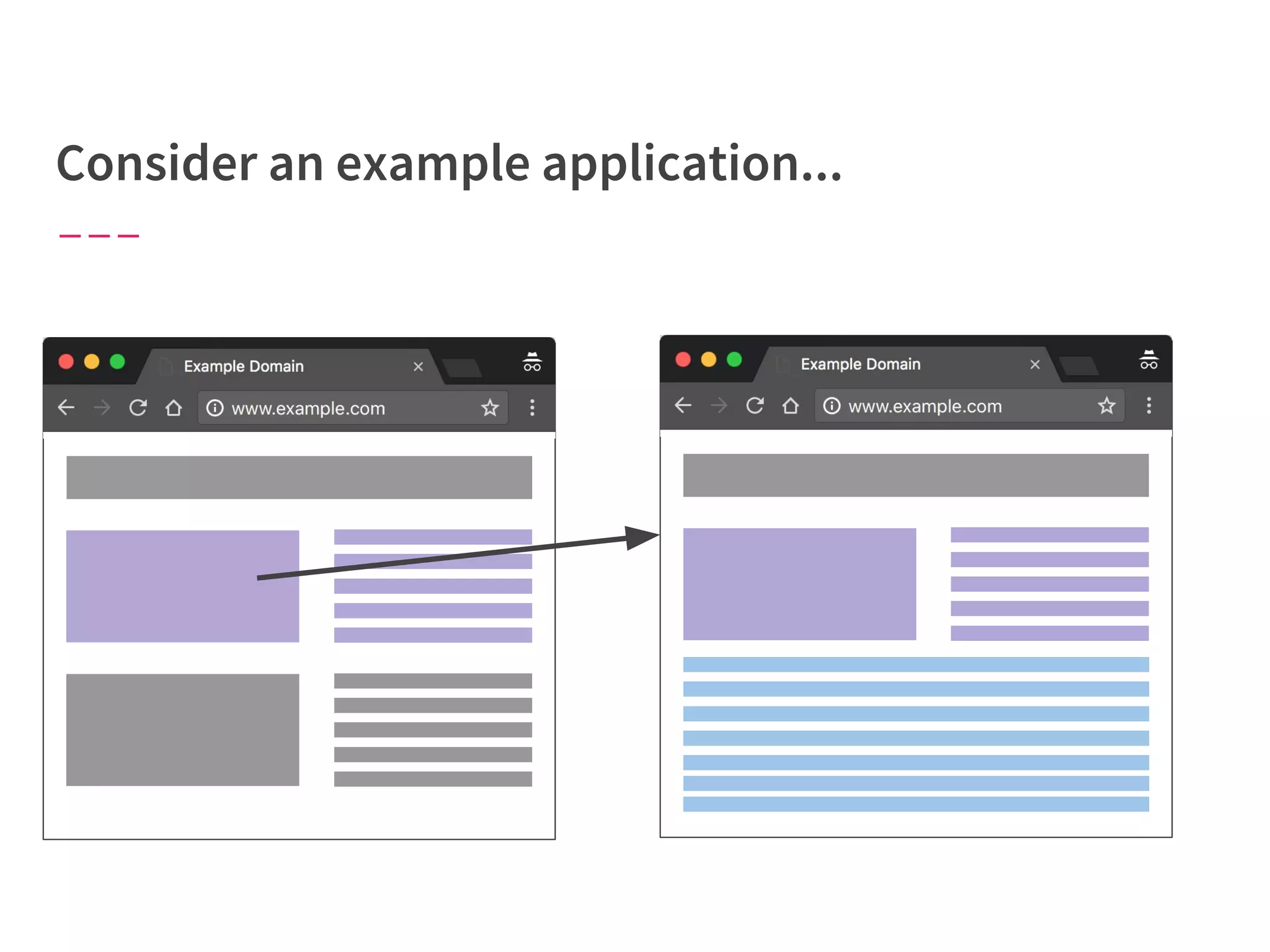



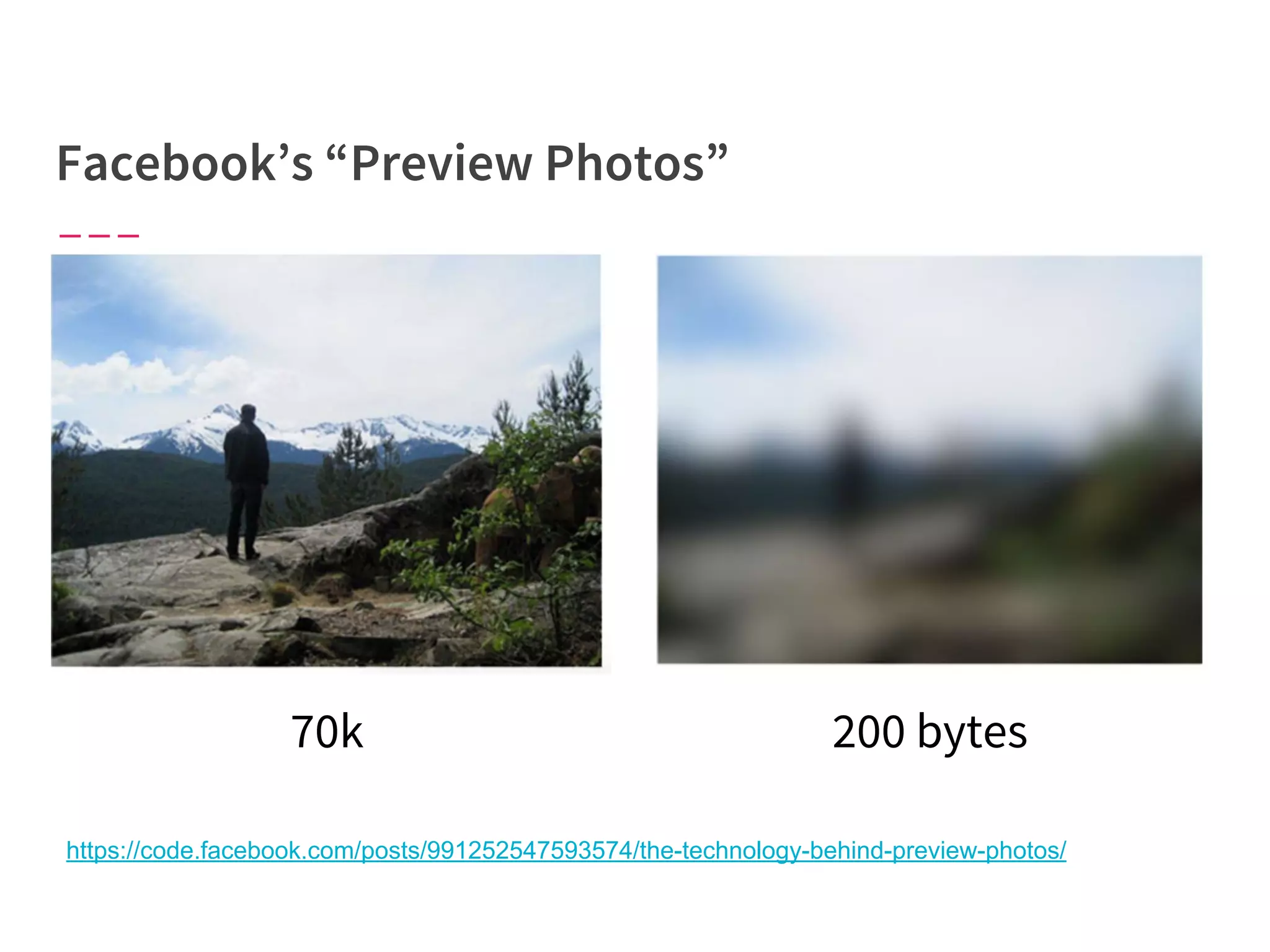










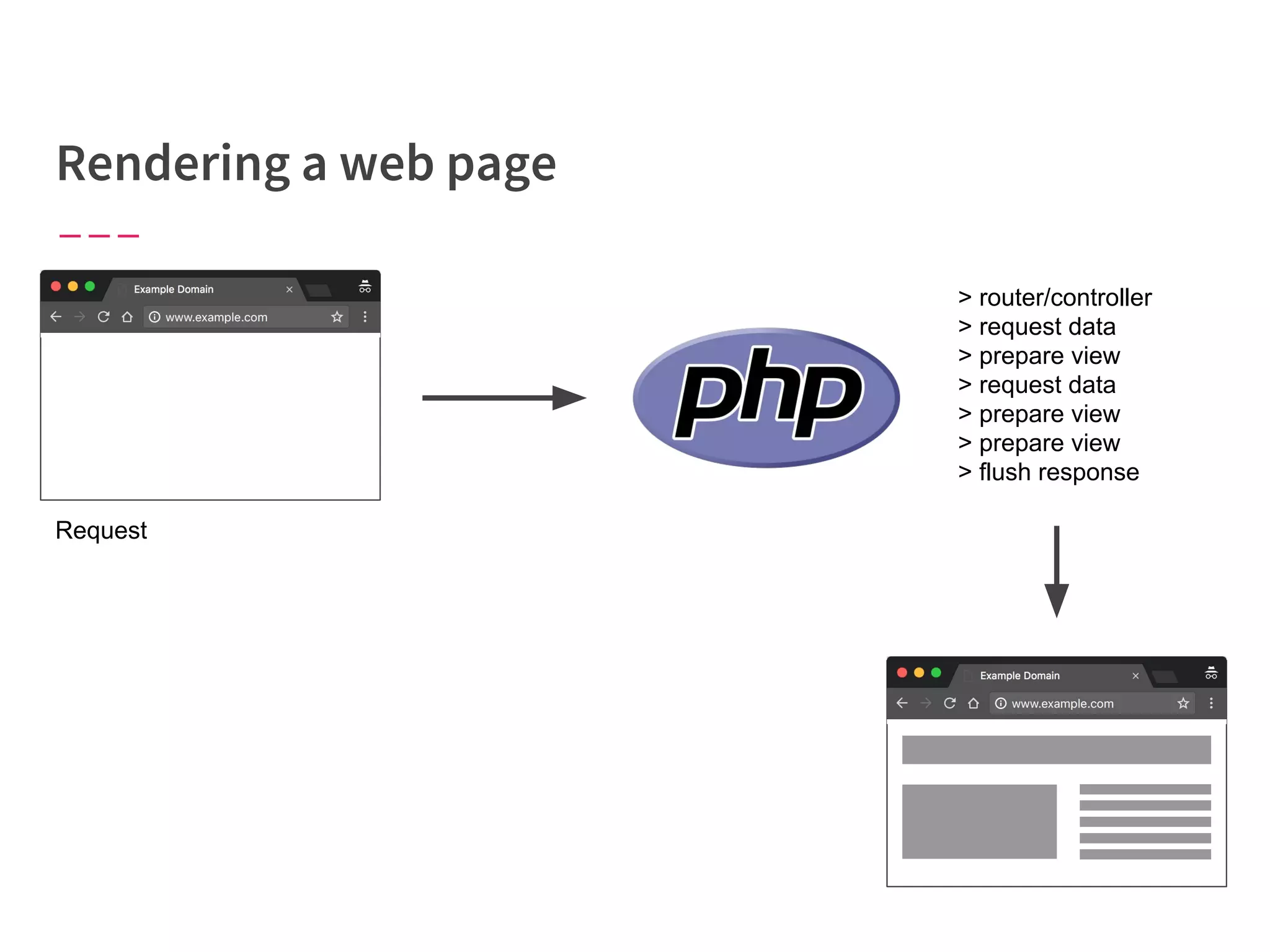



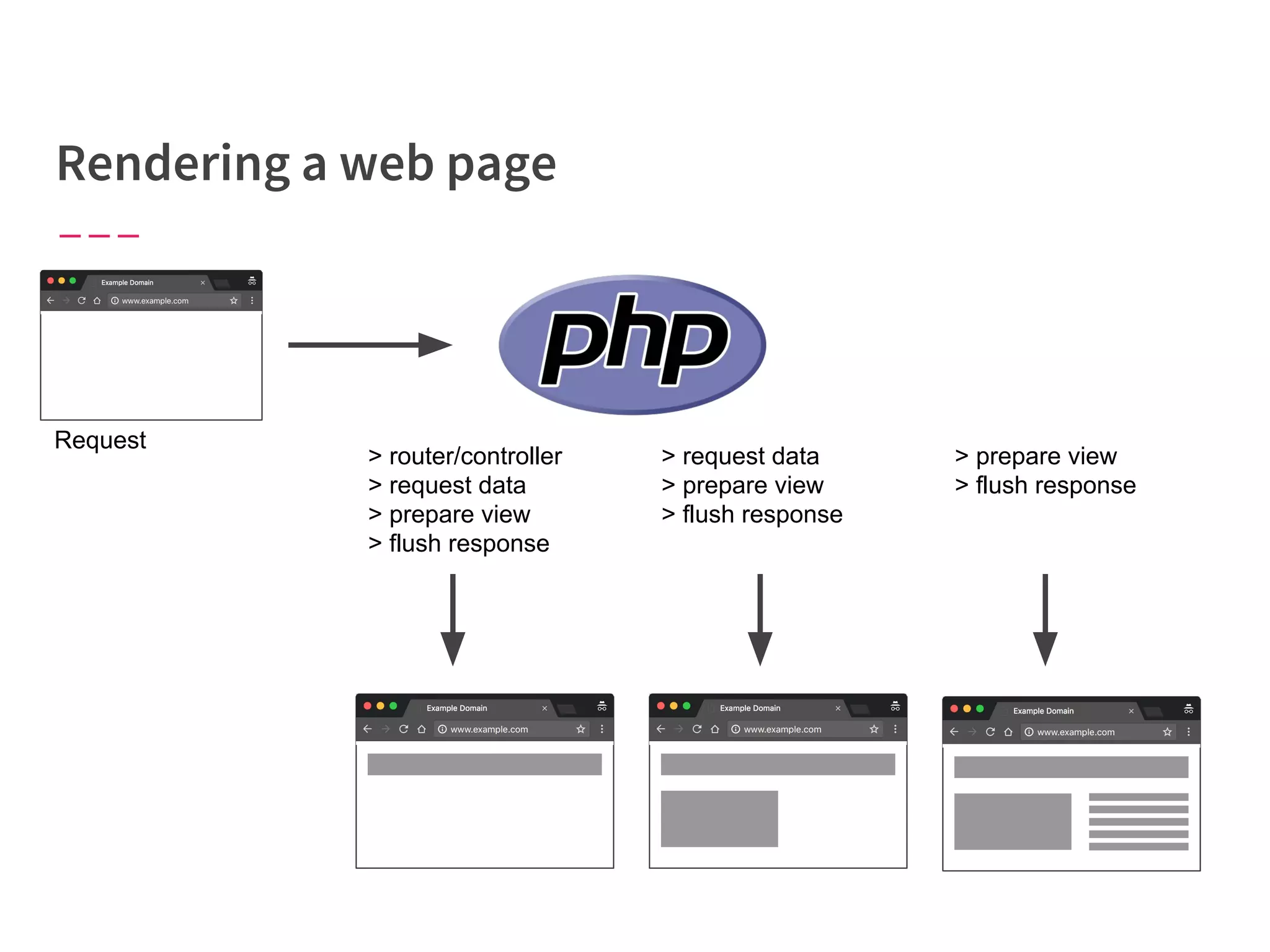

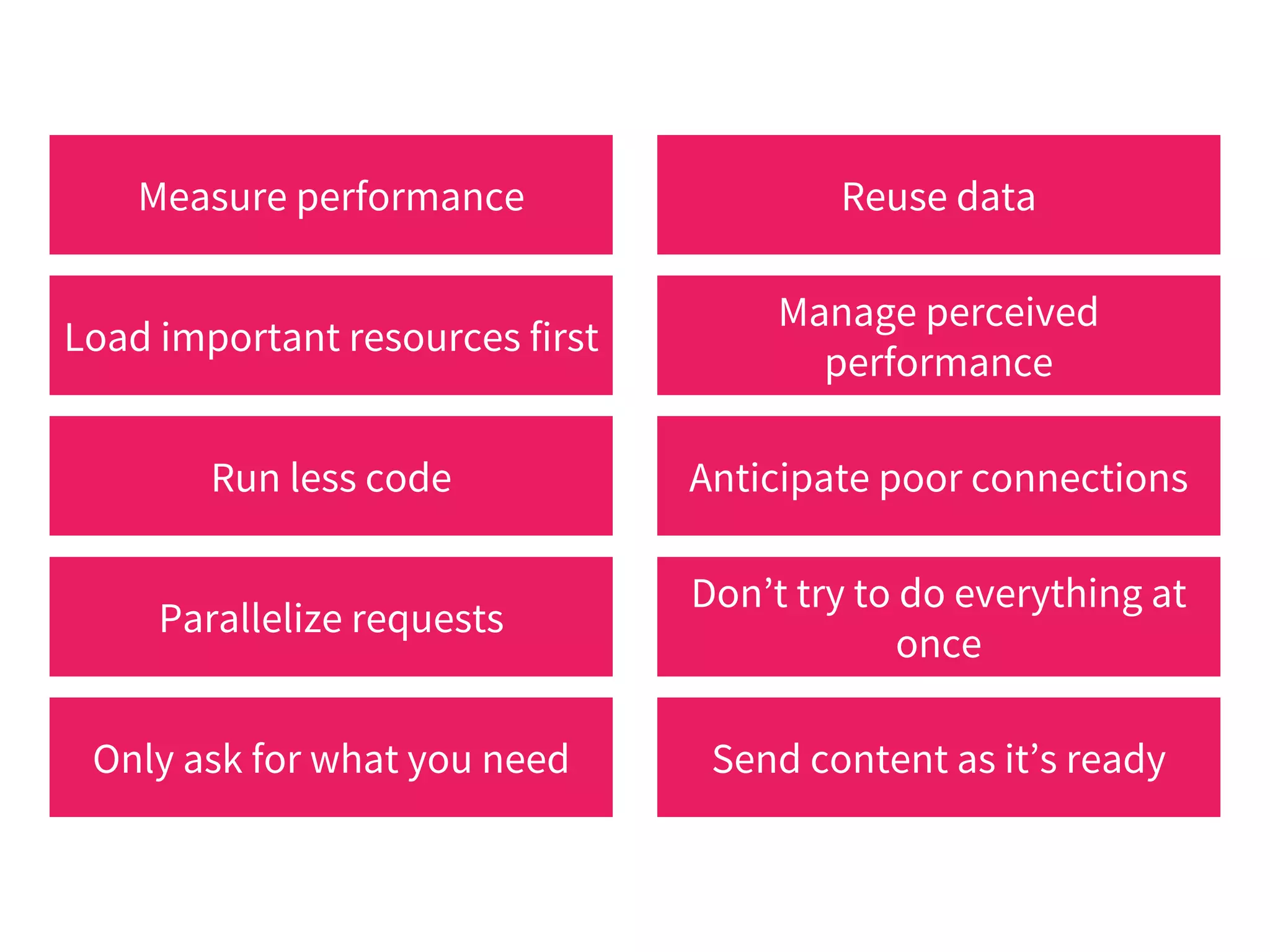






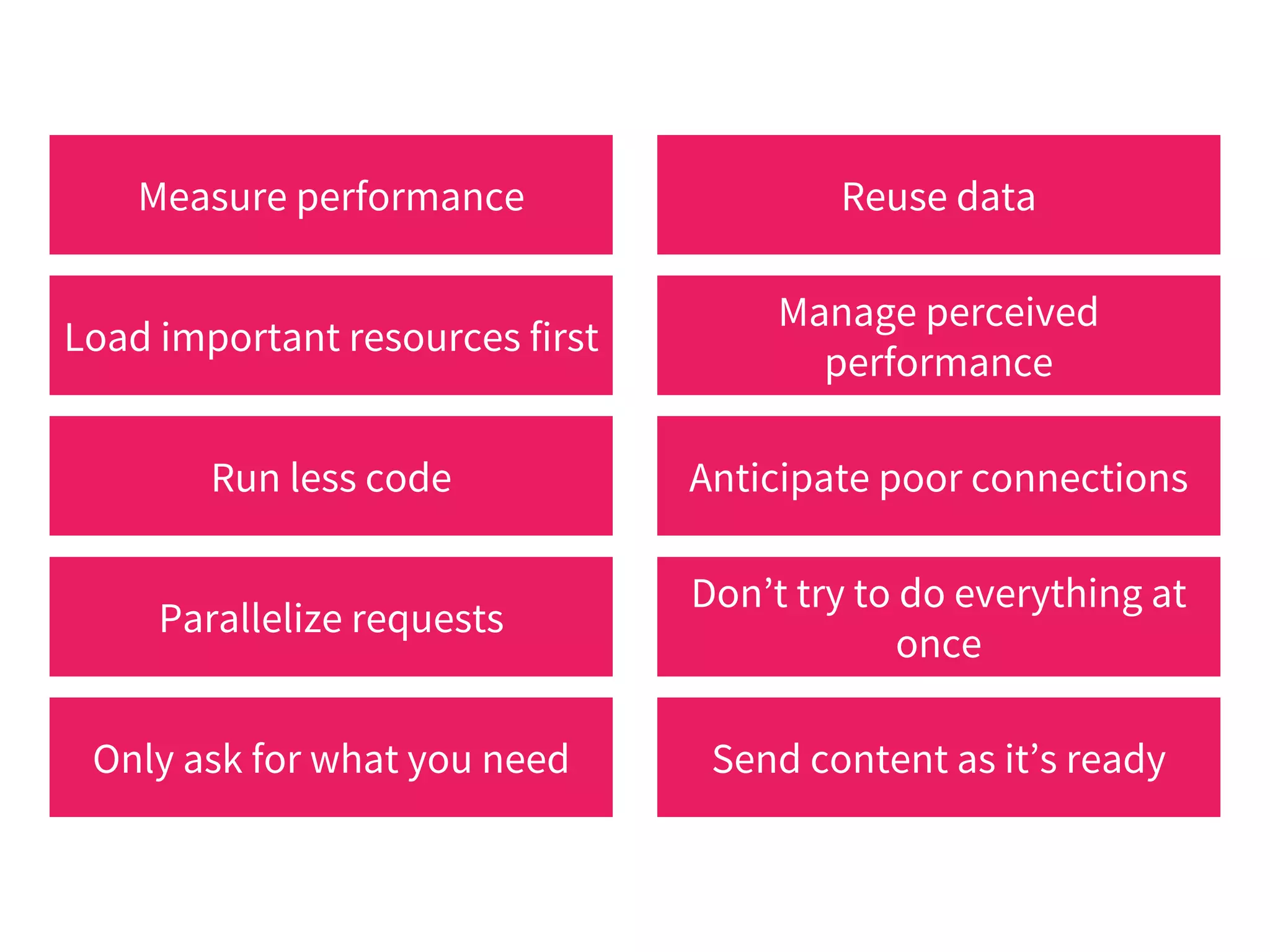
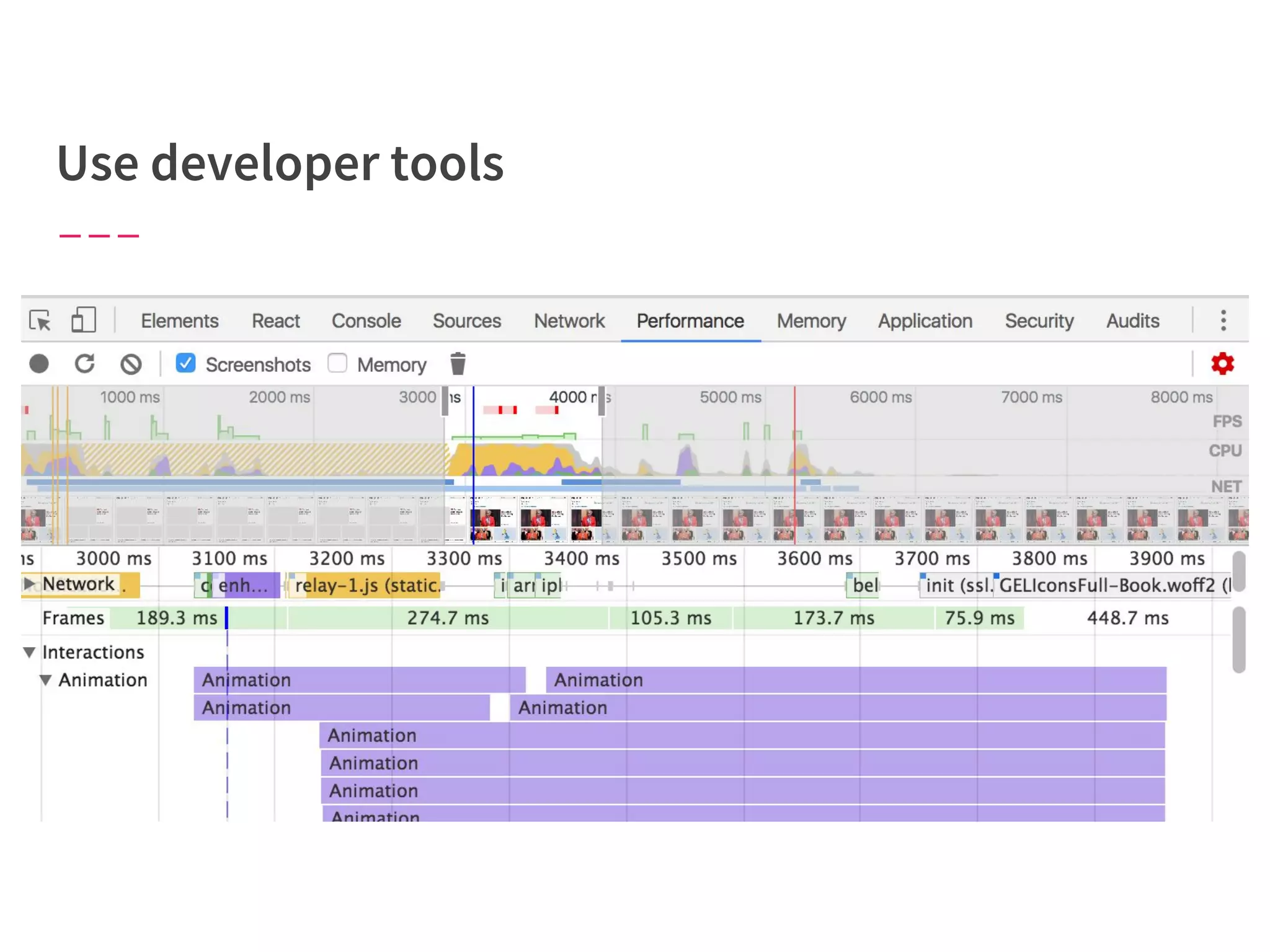
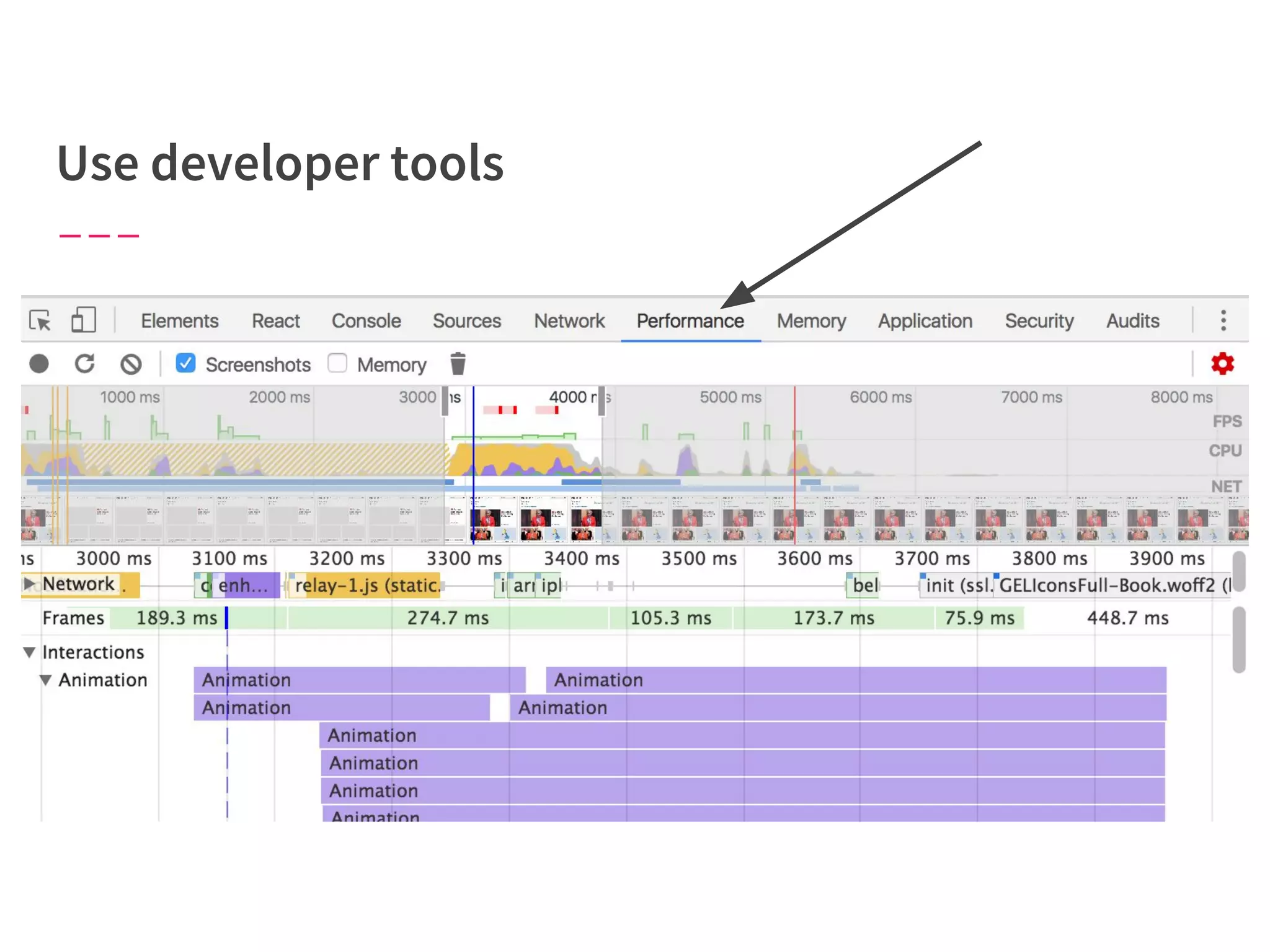
The document discusses modern web performance strategies, emphasizing the need for interactive applications to prioritize speed and efficient resource management. It outlines performance testing methods, resource prioritization, and the importance of user-centered design while detailing the benefits of technologies like HTTP/2 and Service Workers. Additionally, it presents techniques for optimizing data requests and improving perceived performance through progressive web applications and clever caching mechanisms.












![Let Grunt do the work, focus on the fun! [Open Web Camp 2013]](https://cdn.slidesharecdn.com/ss_thumbnails/2013-gruntjs-openwebcamp-130715113721-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







































































