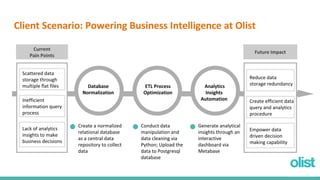
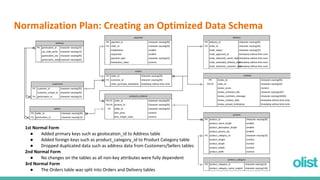
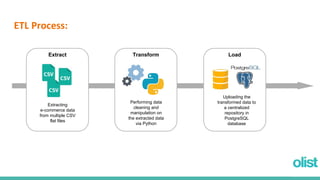
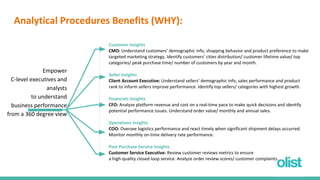
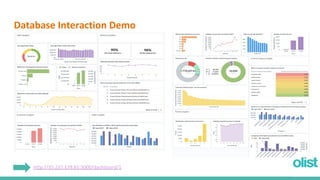
This document discusses optimizing the analytics process for a Brazilian e-commerce company called Olist. It begins with an overview of the client scenario and scattered data. The goals are to normalize the data, optimize the ETL process, and automate analytics insights. The document describes plans to normalize the data into tables, extract data from CSV files, transform and clean the data, and load it into a PostgreSQL database. It discusses how analytical procedures and a dashboard can provide insights for different departments. Finally, it demonstrates the database interaction through a Metabase dashboard.






![References
Data Sources:
1. Kaggle (Brazilian E-Commerce Public Dataset by Olist),
https://www.kaggle.com/olistbr/brazilian-ecommerce/home
2. Silberschatz, A., Korth, H. F., and Sudarshan, S. (2011). Database System Concepts (6th Edition). McGraw-Hill.
ISBN-13: 978-0073523323
Code - Data sampling [Link]
Code - Create database & Extract, Transform, Load in Python [Link]](https://image.slidesharecdn.com/projectteam1slides2-190113233614/85/Team-project-Data-visualization-on-Olist-company-data-12-320.jpg)





























![[Provided Data - US] ChiQuyen Dinh](https://cdn.slidesharecdn.com/ss_thumbnails/datastorytellingwithawsquicksightquyendinhpdf-211019041142-thumbnail.jpg?width=640&height=640&fit=bounds)































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)




![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
