- The document discusses debiasing techniques for Markov chain Monte Carlo (MCMC) algorithms.
- It introduces the concept of "fishy functions" which are solutions to Poisson's equation and can be used for control variates to reduce bias and variance in MCMC estimators.
- The document outlines different sections including revisiting unbiased estimation through Poisson's equation, asymptotic variance estimation using a novel "fishy function" estimator, and experiments on different examples.





![Markov chain Monte Carlo
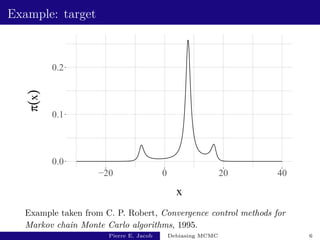
Target probability distribution π.
Example: posterior distribution.
Test function h, with expectation with respect to π:
π(h) = Eπ[h(X)] =
Z
h(x)π(dx).
Example: h(x) = 1(x > t), π(h) = Pπ(X > t).
Pierre E. Jacob Debiasing MCMC 3](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-5-320.jpg)
![Markov chain Monte Carlo
Target probability distribution π.
Example: posterior distribution.
Test function h, with expectation with respect to π:
π(h) = Eπ[h(X)] =
Z
h(x)π(dx).
Example: h(x) = 1(x > t), π(h) = Pπ(X > t).
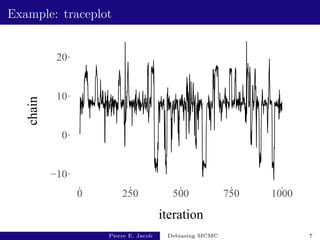
MCMC: X0 ∼ π0, then Xt|Xt−1 ∼ P(Xt−1, ·) for t ≥ 1.
P is constructed to be π-invariant.
MCMC estimator of π(h): t−1 Pt−1
s=0 h(Xs).
Pierre E. Jacob Debiasing MCMC 3](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-6-320.jpg)
![Markov chain Monte Carlo
Target probability distribution π.
Example: posterior distribution.
Test function h, with expectation with respect to π:
π(h) = Eπ[h(X)] =
Z
h(x)π(dx).
Example: h(x) = 1(x > t), π(h) = Pπ(X > t).
MCMC: X0 ∼ π0, then Xt|Xt−1 ∼ P(Xt−1, ·) for t ≥ 1.
P is constructed to be π-invariant.
MCMC estimator of π(h): t−1 Pt−1
s=0 h(Xs).
Pt
(x, ·): distribution of Xt given X0 = x.
πt = π0Pt
: marginal distribution of Xt.
Pt
h(x) = E[h(Xt)|X0 = x]: conditional expectation after t steps.
Pierre E. Jacob Debiasing MCMC 3](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-7-320.jpg)



























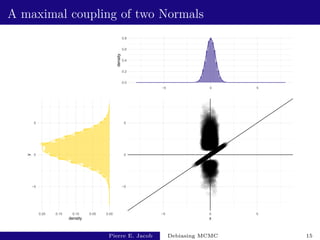

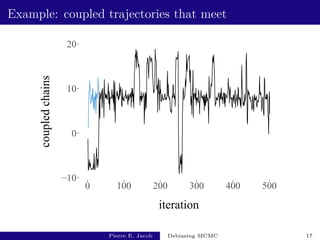

![Assumption on meeting time
Main assumption. For some κ 1, Eπ⊗π[τκ] ∞.
Equivalent to P(τ t) being smaller than t−κ as t → ∞.
Holds for all κ 1 if tails are Geometric.
Pierre E. Jacob Debiasing MCMC 19](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-41-320.jpg)



![Example: verifying the assumption
ηi|θ ∼ Exponential
1 + (θ − xi)2
2
!
∀i = 1, . . . , n
θ0
|η1, . . . , ηn ∼ Normal
Pn
i=1 ηixi
Pn
i=1 ηi + σ−2
,
1
Pn
i=1 ηi + σ−2
.
For θ(1) 6= θ(2), consider next draws.
Means of Normals are always in [− max |xi|, + max |xi|].
Pierre E. Jacob Debiasing MCMC 21](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-45-320.jpg)
![Example: verifying the assumption
ηi|θ ∼ Exponential
1 + (θ − xi)2
2
!
∀i = 1, . . . , n
θ0
|η1, . . . , ηn ∼ Normal
Pn
i=1 ηixi
Pn
i=1 ηi + σ−2
,
1
Pn
i=1 ηi + σ−2
.
For θ(1) 6= θ(2), consider next draws.
Means of Normals are always in [− max |xi|, + max |xi|].
0 ≤ ηi ≤ −2 log Ui almost surely for both chains.
Pierre E. Jacob Debiasing MCMC 21](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-46-320.jpg)
![Example: verifying the assumption
ηi|θ ∼ Exponential
1 + (θ − xi)2
2
!
∀i = 1, . . . , n
θ0
|η1, . . . , ηn ∼ Normal
Pn
i=1 ηixi
Pn
i=1 ηi + σ−2
,
1
Pn
i=1 ηi + σ−2
.
For θ(1) 6= θ(2), consider next draws.
Means of Normals are always in [− max |xi|, + max |xi|].
0 ≤ ηi ≤ −2 log Ui almost surely for both chains.
Variances of Normals simultaneously within (c, d) ⊂ (0, ∞)
with probability ≥ quantity independent of θ(1), θ(2).
Pierre E. Jacob Debiasing MCMC 21](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-47-320.jpg)
![Example: verifying the assumption
ηi|θ ∼ Exponential
1 + (θ − xi)2
2
!
∀i = 1, . . . , n
θ0
|η1, . . . , ηn ∼ Normal
Pn
i=1 ηixi
Pn
i=1 ηi + σ−2
,
1
Pn
i=1 ηi + σ−2
.
For θ(1) 6= θ(2), consider next draws.
Means of Normals are always in [− max |xi|, + max |xi|].
0 ≤ ηi ≤ −2 log Ui almost surely for both chains.
Variances of Normals simultaneously within (c, d) ⊂ (0, ∞)
with probability ≥ quantity independent of θ(1), θ(2).
TV between such Normals ≤ 1 − with 0.
Pierre E. Jacob Debiasing MCMC 21](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-48-320.jpg)
![Example: verifying the assumption
ηi|θ ∼ Exponential
1 + (θ − xi)2
2
!
∀i = 1, . . . , n
θ0
|η1, . . . , ηn ∼ Normal
Pn
i=1 ηixi
Pn
i=1 ηi + σ−2
,
1
Pn
i=1 ηi + σ−2
.
For θ(1) 6= θ(2), consider next draws.
Means of Normals are always in [− max |xi|, + max |xi|].
0 ≤ ηi ≤ −2 log Ui almost surely for both chains.
Variances of Normals simultaneously within (c, d) ⊂ (0, ∞)
with probability ≥ quantity independent of θ(1), θ(2).
TV between such Normals ≤ 1 − with 0.
Assumption satisfied for all κ 1.
Pierre E. Jacob Debiasing MCMC 21](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-49-320.jpg)


![Estimation of fishy function evaluations
friendly fish evaluation: gy(x) =
∞
X
t=0
{Pt
h(x) − Pt
h(y)}
its estimator: Gy(x) =
∞
X
t=0
{h(Xt) − h(Yt)}
Let h ∈ Lm(π) for some m κ/(κ − 1).
For π ⊗ π-almost all (x, y), E [Gy(x)] = gy(x),
and for p ≥ 1 such that 1
p 1
m + 1
κ , E [|Gy(x)|p
] ∞.
Pierre E. Jacob Debiasing MCMC 23](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-52-320.jpg)
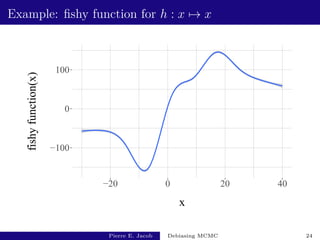



![Poisson equation → unbiased estimation
For any x ∈ X, let X1 ∼ P(x, ·), and let Gy(x0) be an unbiased
estimator of gy(x0), for π-almost any x0, y.
Then
Ex[Gx(X1)] = Ex[g?(X1) − g?(x)]
= Pg?(x) − g?(x).
Thus Gx(X1) is an unbiased estimator of π(h) − h(x).
Pierre E. Jacob Debiasing MCMC 26](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-57-320.jpg)
![Poisson equation → unbiased estimation
For any x ∈ X, let X1 ∼ P(x, ·), and let Gy(x0) be an unbiased
estimator of gy(x0), for π-almost any x0, y.
Then
Ex[Gx(X1)] = Ex[g?(X1) − g?(x)]
= Pg?(x) − g?(x).
Thus Gx(X1) is an unbiased estimator of π(h) − h(x).
We can randomize x: X0
0 ∼ π0, Y 0
0 ∼ π0, and X0
1 ∼ P(X0
0, ·),
E[GY 0
0
(X0
1)] = π(h) − π0(h).
Glynn Rhee, Exact Estimation for Markov Chain Equilibrium
Expectations, 2014.
Pierre E. Jacob Debiasing MCMC 26](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-58-320.jpg)



![Results
Estimator H
(L)
k:` , pronounced “H
(L)
k:` ” (in French “
(L)
k:` ”).
Tuning parameters: “burn-in” k, length `, lag L.
H
(L)
k:` = standard MCMC estimator + bias correction term.
Let h ∈ Lm(π) for some m κ/(κ − 1), and dπ0/dπ ≤ M.
Then for any k, ` ∈ N with ` ≥ k, E[H
(L)
k:` ] = π(h),
and for p ≥ 1 such that 1
p 1
m + 1
κ , E[|H
(L)
k:` |p]
1
p ∞.
Pierre E. Jacob Debiasing MCMC 28](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-62-320.jpg)



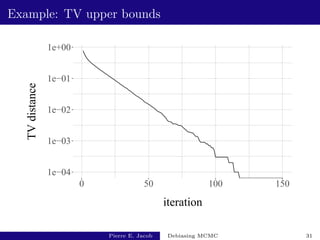







![Central limit theorem
Markov kernel P, target π, test function h,
√
t t−1
t−1
X
s=0
h(Xs) − π(h)
!
→ Normal(0, v(P, h)),
where v(P, h) is the asymptotic variance.
The limit of V[t−1/2 Pt−1
s=0 h(Xs)] as t → ∞ is
v(P, h) = V(h(X0)) + 2
∞
X
t=1
Cov(h(X0), h(Xt)).
Estimate v(P, h): well-known problem but still difficult.
Spectral variance, batch means, initial sequence. . .
Pierre E. Jacob Debiasing MCMC 33](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-74-320.jpg)
![Central limit theorem
Using the Poisson equation to establish a CLT for Markov chain
ergodic averages, leads to the following equivalent expression
v(P, h) = Eπ[{g(X1) − Pg(X0)}2
].
Pierre E. Jacob Debiasing MCMC 34](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-75-320.jpg)
![Central limit theorem
Using the Poisson equation to establish a CLT for Markov chain
ergodic averages, leads to the following equivalent expression
v(P, h) = Eπ[{g(X1) − Pg(X0)}2
].
By simple manipulations, using h − π(h) = g − Pg, we can write
v(P, h) = 2π({h − π(h)}g) − (π(h2
) − π(h)2
).
Pierre E. Jacob Debiasing MCMC 34](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-76-320.jpg)
![Central limit theorem
Using the Poisson equation to establish a CLT for Markov chain
ergodic averages, leads to the following equivalent expression
v(P, h) = Eπ[{g(X1) − Pg(X0)}2
].
By simple manipulations, using h − π(h) = g − Pg, we can write
v(P, h) = 2π({h − π(h)}g) − (π(h2
) − π(h)2
).
We can obtain unbiased approximations π̂ =
PN
n=1 ωnδZn of π,
and we can estimate g unbiasedly with G, point-wise.
Pierre E. Jacob Debiasing MCMC 34](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-77-320.jpg)









![Results
Let h ∈ Lm(π) for some m 2κ/(κ − 2).
Assume ξk = 1/N for k ∈ {1, . . . , N}.
Then for any R ≥ 1 and π-almost all y, E [v̂(P, h)] = v(P, h),
and for p ≥ 1 such that 1
p 2
m + 2
κ , E [|v̂(P, h)|p
] ∞.
Pierre E. Jacob Debiasing MCMC 38](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-87-320.jpg)


![Cauchy-Normal: performance
Gibbs sampler:
R estimate total cost fishy cost variance of estimator inefficiency
1 [736 - 992] [1049 - 1054] [32 - 36] [3e+06 - 6.4e+06] [3.1e+09 - 6.7e+09]
10 [835 - 923] [1349 - 1363] [332 - 345] [4.7e+05 - 5.9e+05] [6.4e+08 - 8e+08]
50 [849 - 903] [2686 - 2713] [1667 - 1696] [1.7e+05 - 2.1e+05] [4.7e+08 - 5.6e+08]
100 [856 - 903] [4379 - 4423] [3361 - 3406] [1.4e+05 - 1.7e+05] [6.3e+08 - 7.4e+08]
Pierre E. Jacob Debiasing MCMC 40](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-90-320.jpg)
![Cauchy-Normal: performance
Gibbs sampler:
R estimate total cost fishy cost variance of estimator inefficiency
1 [736 - 992] [1049 - 1054] [32 - 36] [3e+06 - 6.4e+06] [3.1e+09 - 6.7e+09]
10 [835 - 923] [1349 - 1363] [332 - 345] [4.7e+05 - 5.9e+05] [6.4e+08 - 8e+08]
50 [849 - 903] [2686 - 2713] [1667 - 1696] [1.7e+05 - 2.1e+05] [4.7e+08 - 5.6e+08]
100 [856 - 903] [4379 - 4423] [3361 - 3406] [1.4e+05 - 1.7e+05] [6.3e+08 - 7.4e+08]
Random walk “Metropolis–Rosenbluth–Teller–Hastings”:
R estimate total cost fishy cost variance of estimator inefficiency
1 [299 - 388] [786 - 788] [23 - 25] [4e+05 - 7.3e+05] [3.2e+08 - 5.8e+08]
10 [331 - 364] [996 - 1003] [233 - 240] [6.2e+04 - 7.9e+04] [6.3e+07 - 7.8e+07]
50 [333 - 351] [1947 - 1966] [1185 - 1203] [1.9e+04 - 2.3e+04] [3.8e+07 - 4.6e+07]
100 [335 - 349] [3139 - 3168] [2376 - 2405] [1.3e+04 - 1.6e+04] [4.2e+07 - 5e+07]
Based on 103 independent replicates, with y = 0.
Pierre E. Jacob Debiasing MCMC 40](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-91-320.jpg)
![Cauchy-Normal: selection probabilities
algorithm selection ξ fishy cost variance of estimator inefficiency
Gibbs uniform [332 - 345] [4.7e+05 - 5.9e+05] [6.4e+08 - 8e+08]
Gibbs optimal [408 - 422] [2.2e+05 - 2.8e+05] [3.1e+08 - 4e+08]
MRTH uniform [233 - 240] [6.2e+04 - 7.8e+04] [6.2e+07 - 7.8e+07]
MRTH optimal [190 - 196] [2.2e+04 - 2.7e+04] [2.1e+07 - 2.6e+07]
Based on 103 independent replicates, using R = 10.
Pierre E. Jacob Debiasing MCMC 41](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-92-320.jpg)


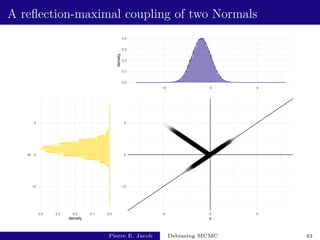
![AR(1) example
R estimate total cost fishy cost variance of estimator inefficiency
1 [8178 - 10364] [5234 - 5261] [145 - 168] [2.4e+08 - 4.8e+08] [1.3e+12 - 2.5e+12]
10 [9414 - 10250] [6676 - 6756] [1585 - 1667] [4e+07 - 5.5e+07] [2.6e+11 - 3.7e+11]
50 [9748 - 10206] [13148 - 13350] [8069 - 8256] [1.2e+07 - 1.5e+07] [1.6e+11 - 2e+11]
100 [9840 - 10240] [21259 - 21558] [16163 - 16475] [9.2e+06 - 1.1e+07] [2e+11 - 2.4e+11]
Here v(P, h) = 104.
Based on 103 independent replicates, with y = 0.
Pierre E. Jacob Debiasing MCMC 44](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-96-320.jpg)
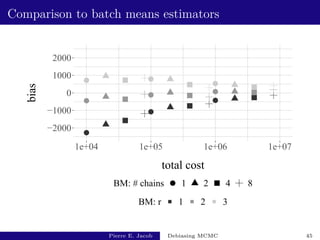
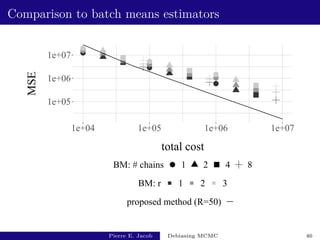
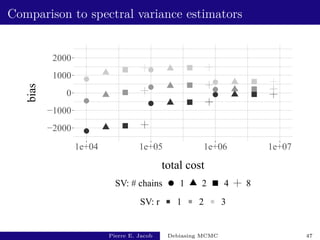
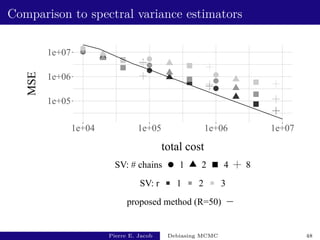





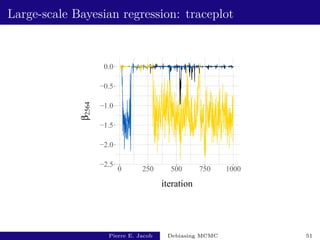
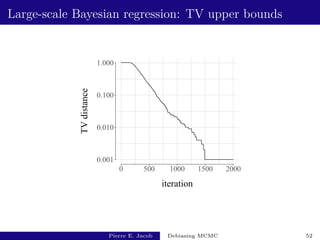
![Large-scale Bayesian regression: performance
R estimate total cost fishy cost variance of estimator inefficiency
1 [77 - 97] [12308 - 12384] [1521 - 1594] [2.2e+04 - 3.3e+04] [2.7e+08 - 4.1e+08]
5 [78 - 87] [18470 - 18634] [7684 - 7844] [5.4e+03 - 6.8e+03] [9.9e+07 - 1.3e+08]
10 [78 - 85] [26209 - 26444] [15442 - 15656] [2.6e+03 - 3.1e+03] [6.7e+07 - 8.2e+07]
Test function: h : x 7→ β2564.
Based on 103 independent replicates, y ∼ prior.
With k = 500, L = 500, ` = 2500, unbiased MCMC estimators
of π(h) have a mean cost of 5400, and a variance of 0.020,
leading to an inefficiency of 108: not much more than v(P, h).
Pierre E. Jacob Debiasing MCMC 53](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-108-320.jpg)

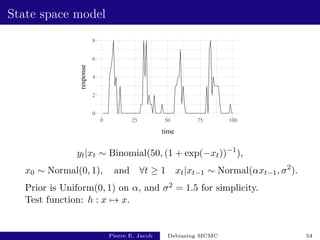
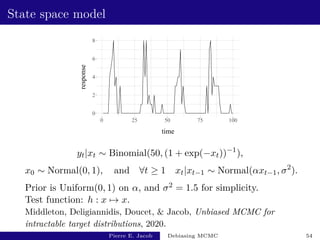
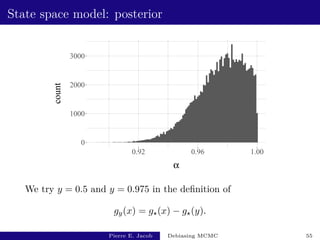
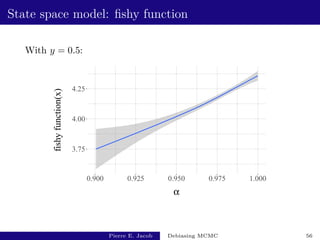
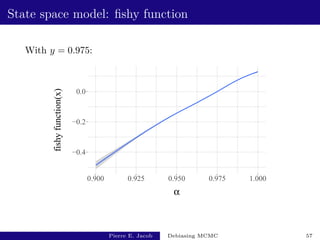
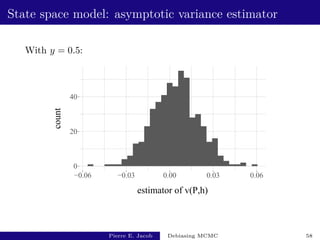
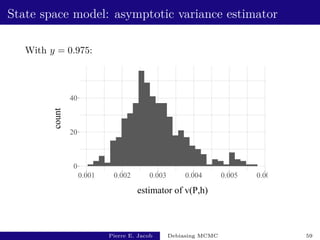
![State space model: performance
y estimate fishy cost variance of estimator inefficiency
0.5 [2.64e-03 - 5.32e-03] [3.62e+03 - 3.67e+03] [2.2e-04 - 2.8e-04] [1.9e+00 - 2.5e+00]
0.975 [2.85e-03 - 2.99e-03] [1.01e+03 - 1.05e+03] [5.4e-07 - 7.4e-07] [3.3e-03 - 4.5e-03]
Based on 500 independent replicates.
The choice of y has an impact on the performance.
Unbiased MCMC has an inefficiency of 3.8 × 10−3:
not much more than v(P, h).
Pierre E. Jacob Debiasing MCMC 60](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-117-320.jpg)











![Nested targets
target π(x1, x2) = π1(x1)π2(x2|x1)
Obtain π̂1 =
PN1
k=1 ω1,kδX1,k
approximating π1.
Draw K uniformly in {1, . . . , N1}.
Obtain π̂2 =
PN2
n=1 ω2,nδX2,n approximating π2(·|X1,K).
Then E[N1ω1,K
N2
X
n=1
ω2,nh(X1,K, X2,n)]
= E[E[N1ω1,K
N2
X
n=1
ω2,nh(X1,K, X2,n)|π̂1]]
= E[
N1
X
k=1
ω1,k
Z
h(X1,k, x2)π2(dx2|X1,k)] = π(h).
Pierre E. Jacob Debiasing MCMC 66](https://image.slidesharecdn.com/pjacob-cirm-fusion-oct2022-221028142658-9ac3c875/85/Talk-at-CIRM-on-Poisson-equation-and-debiasing-techniques-130-320.jpg)


































































