


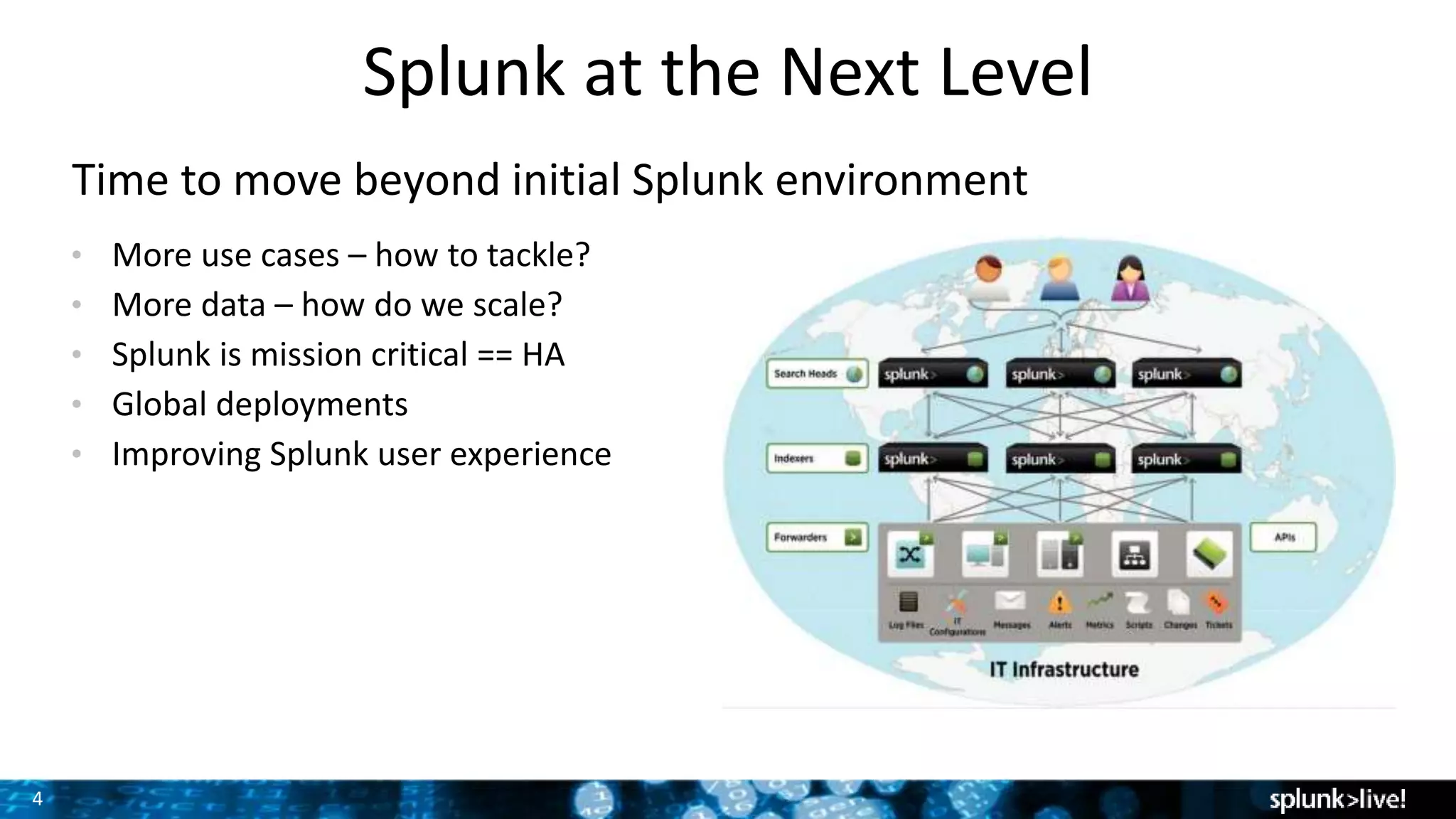


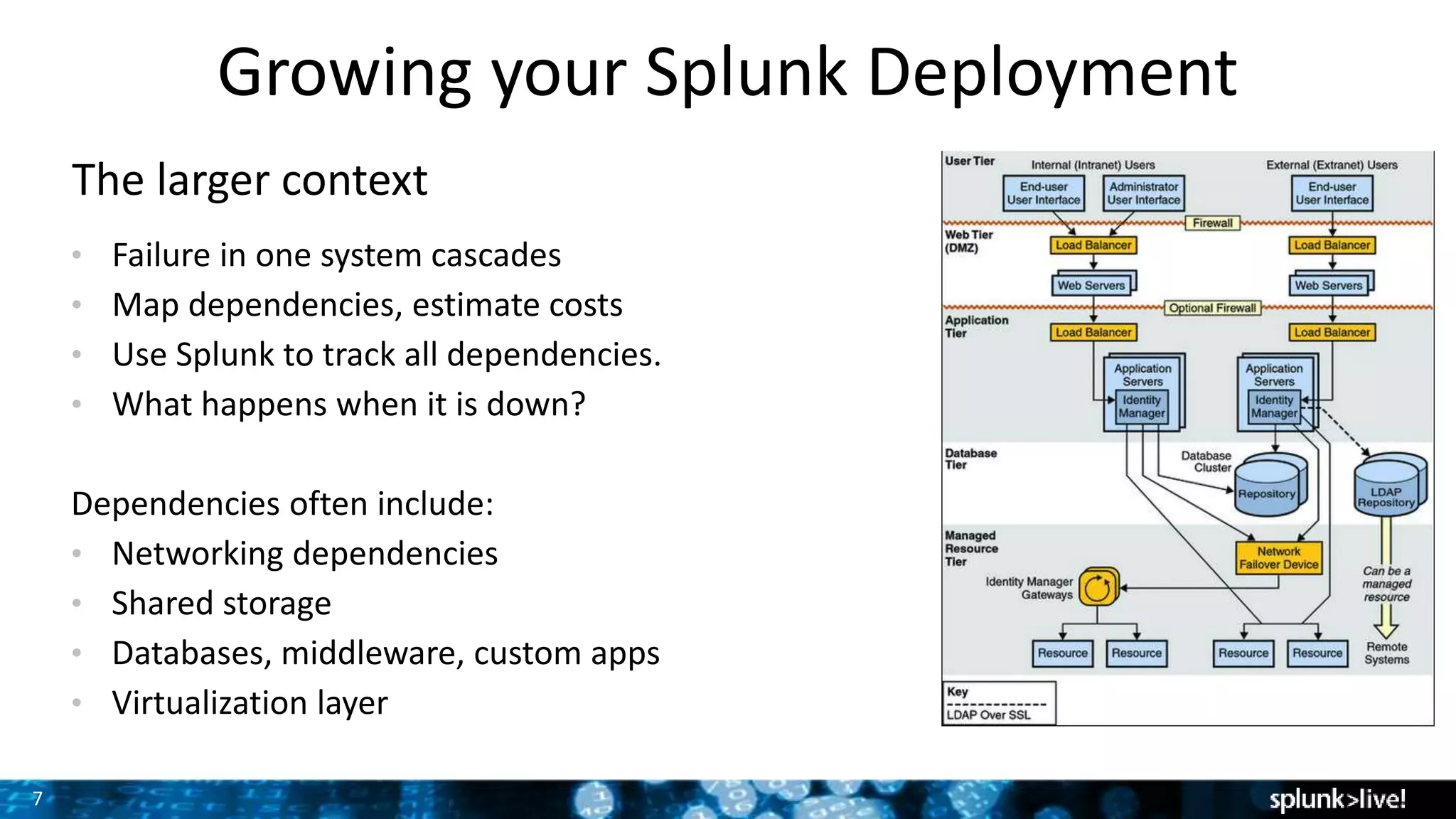

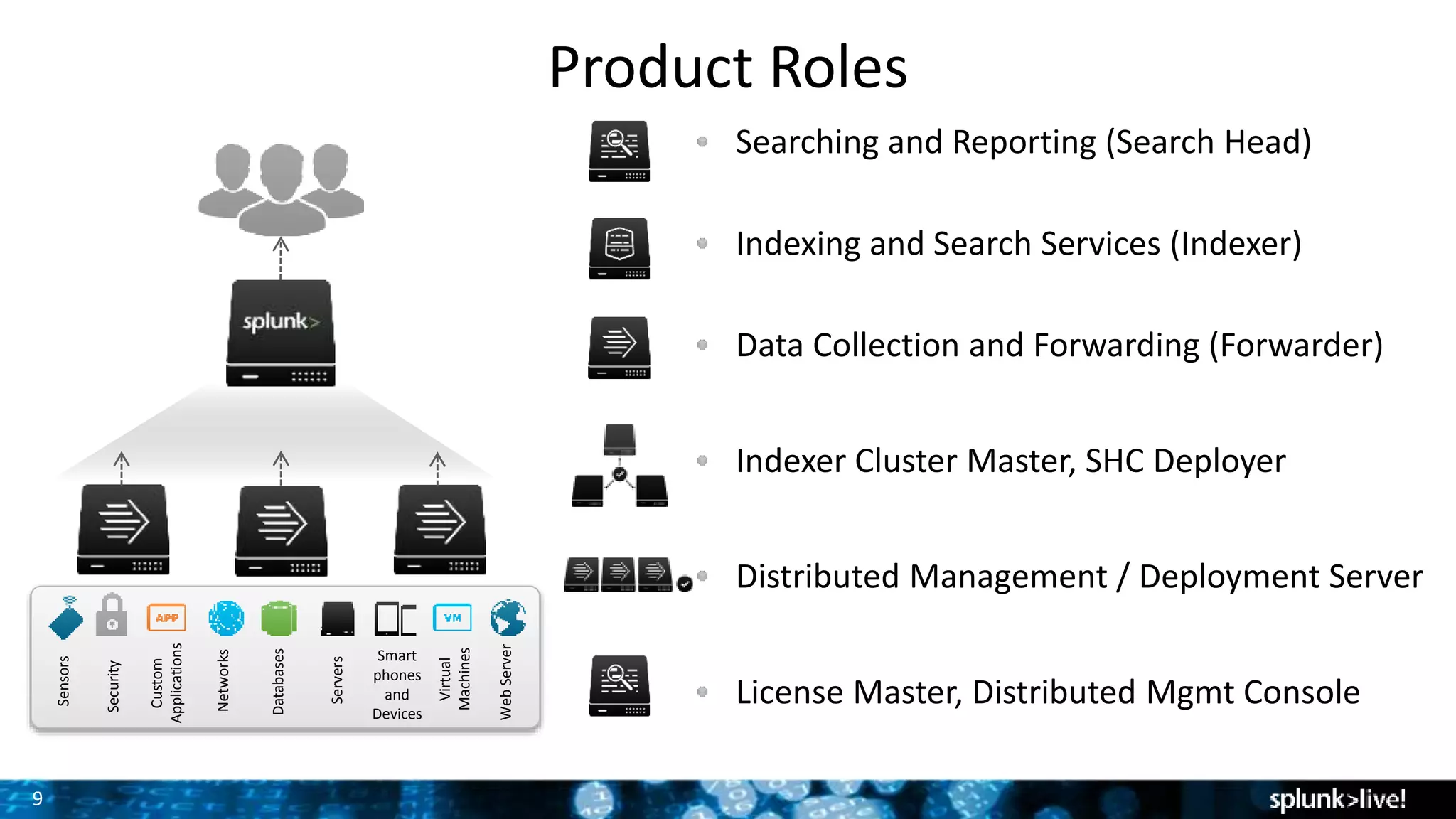

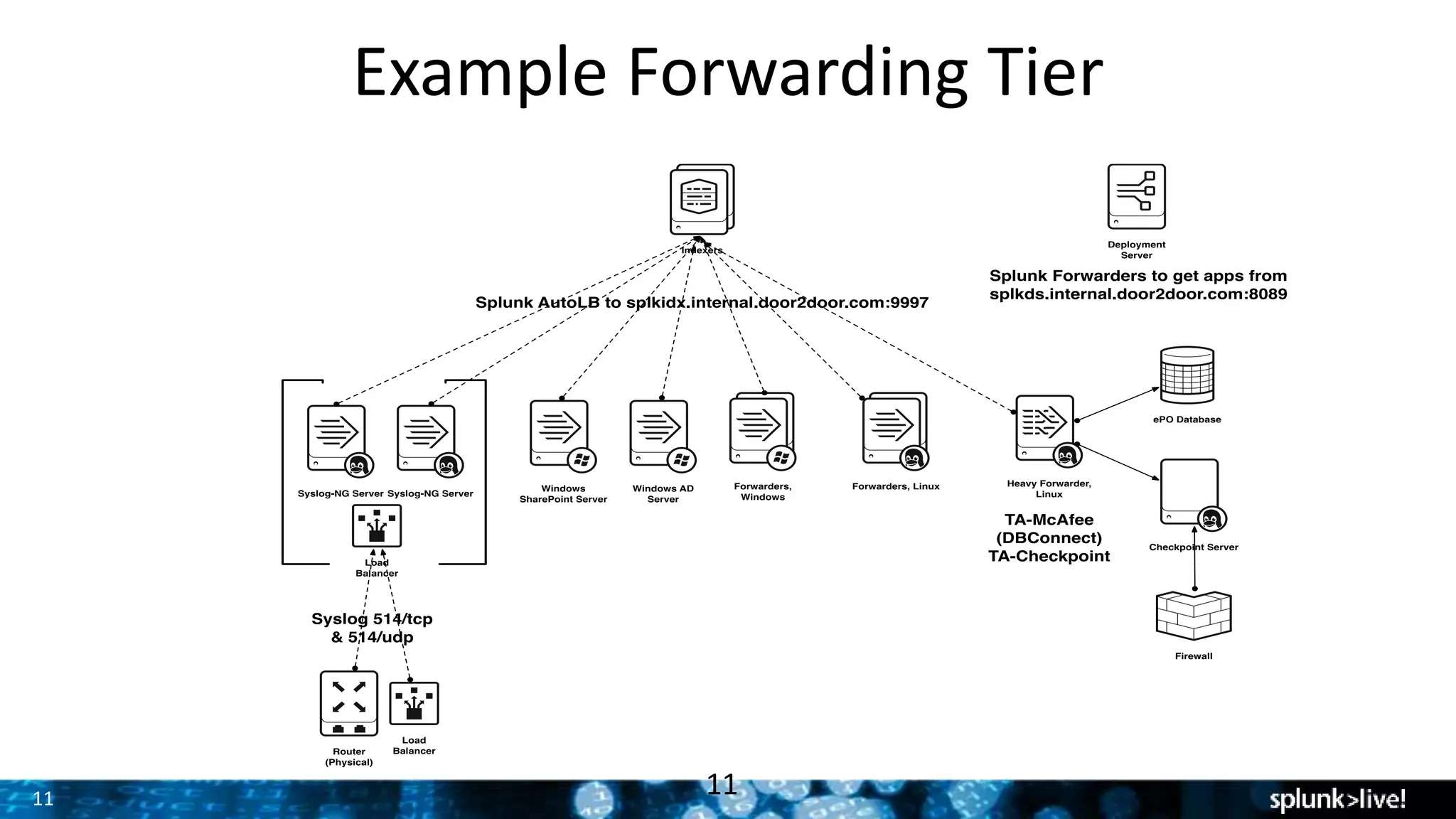

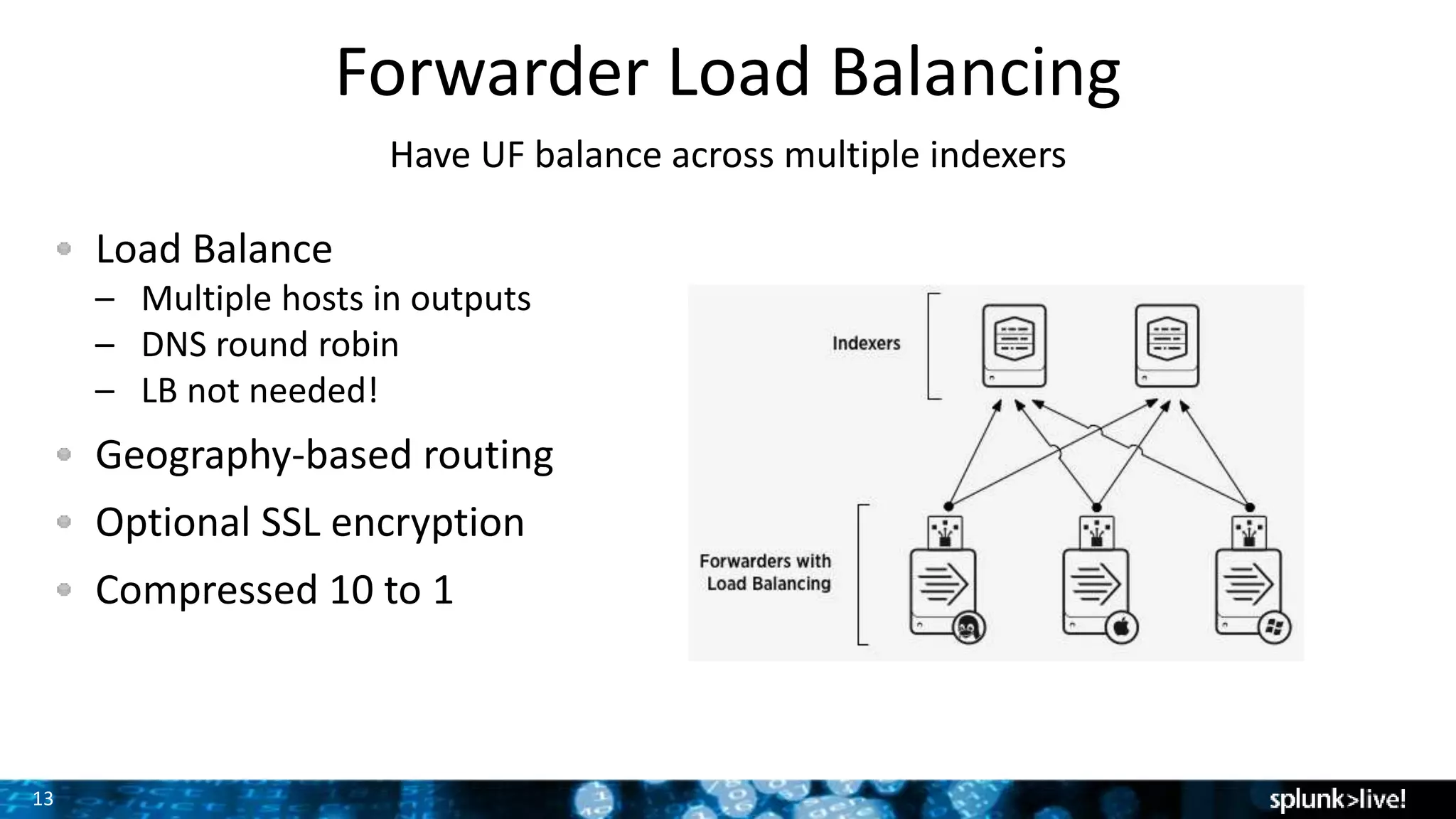









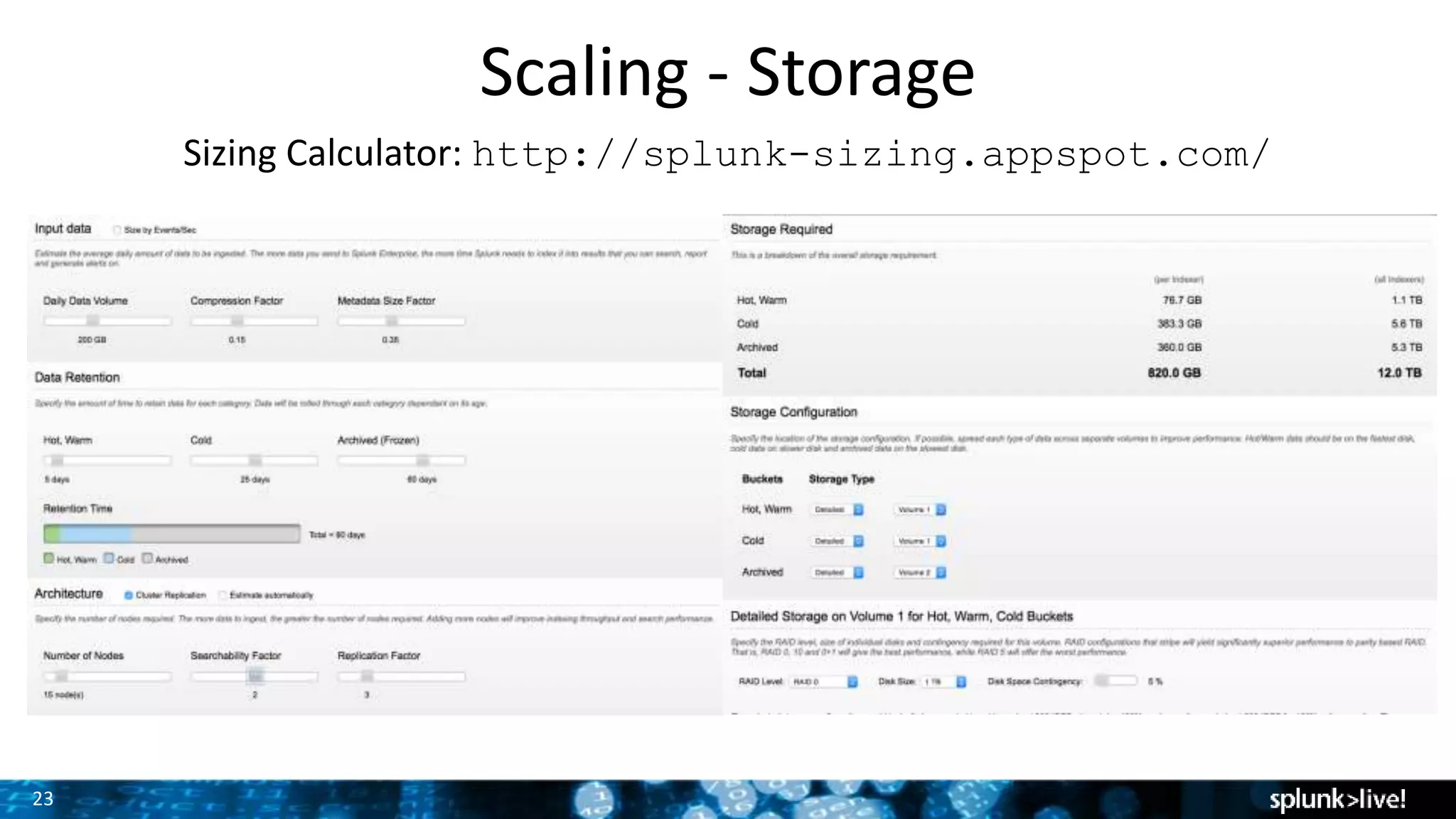


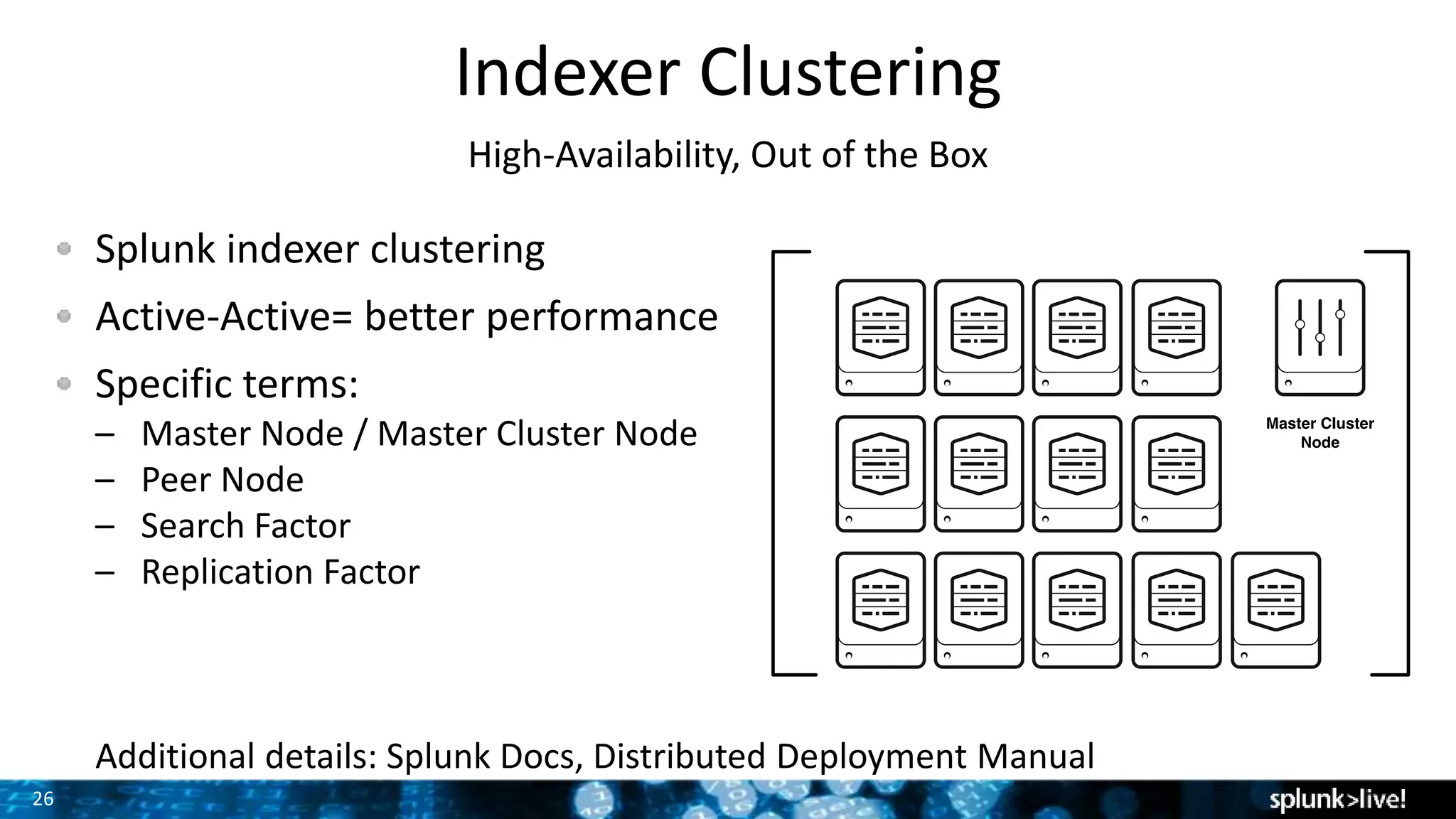
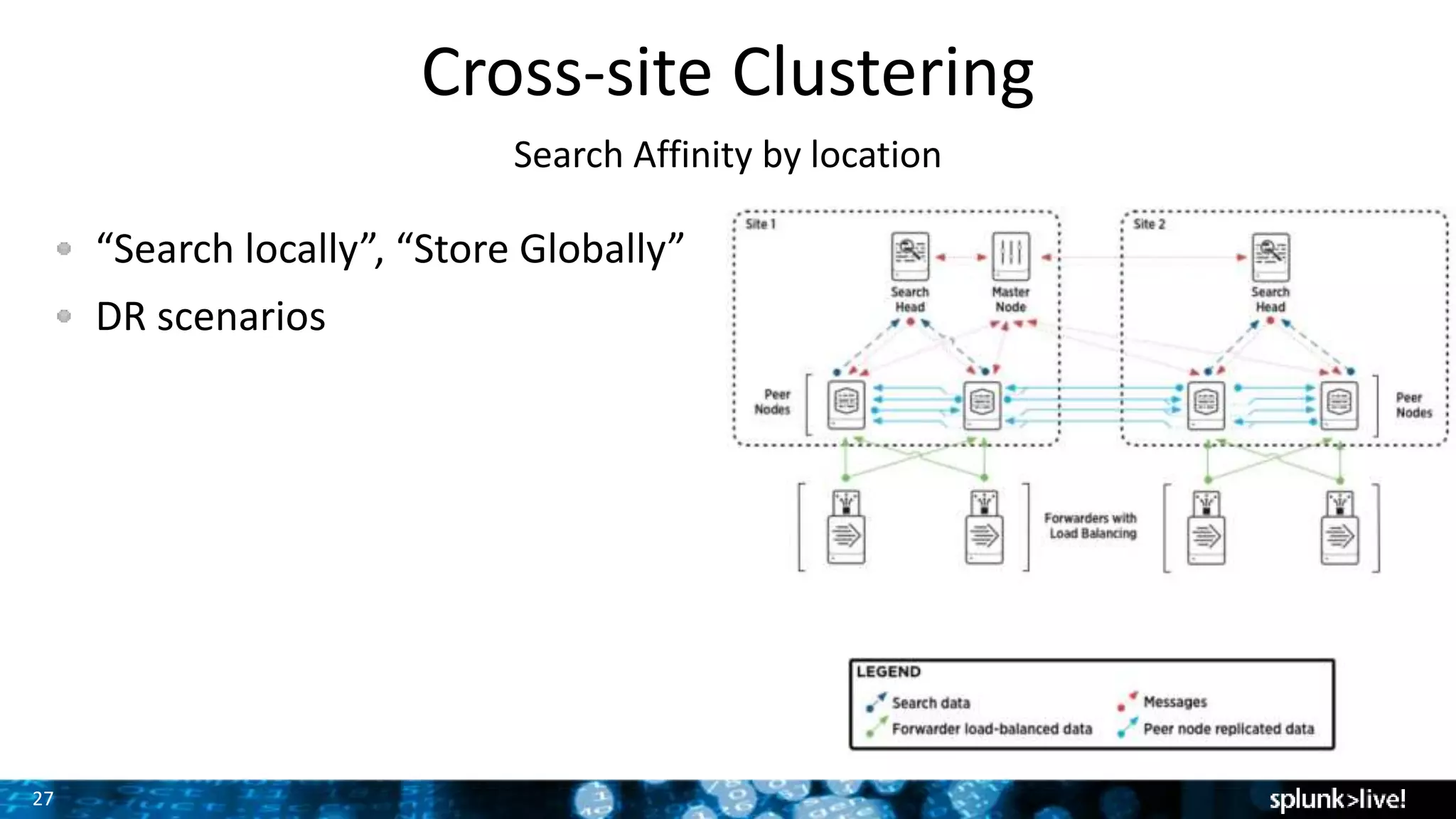

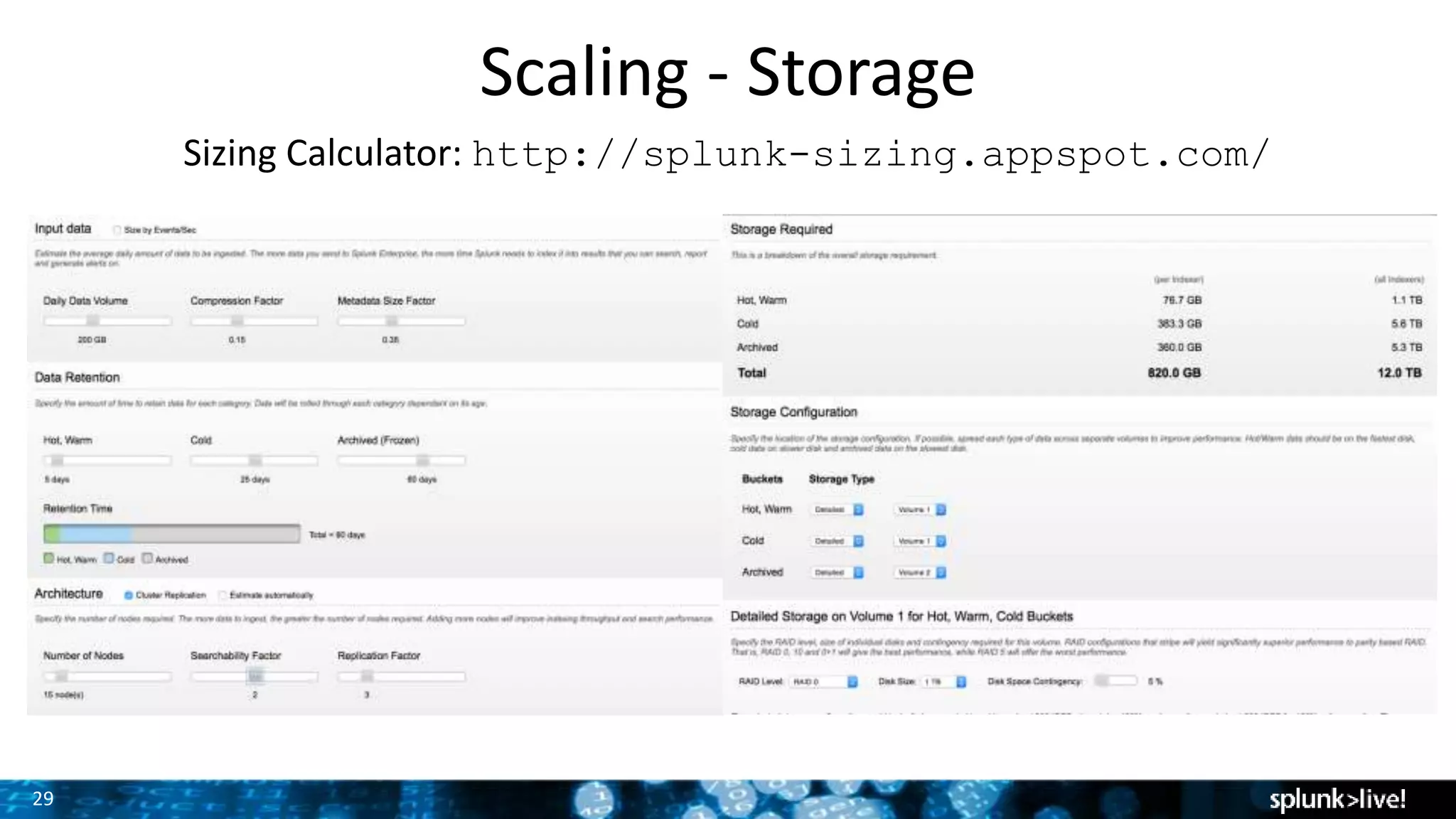






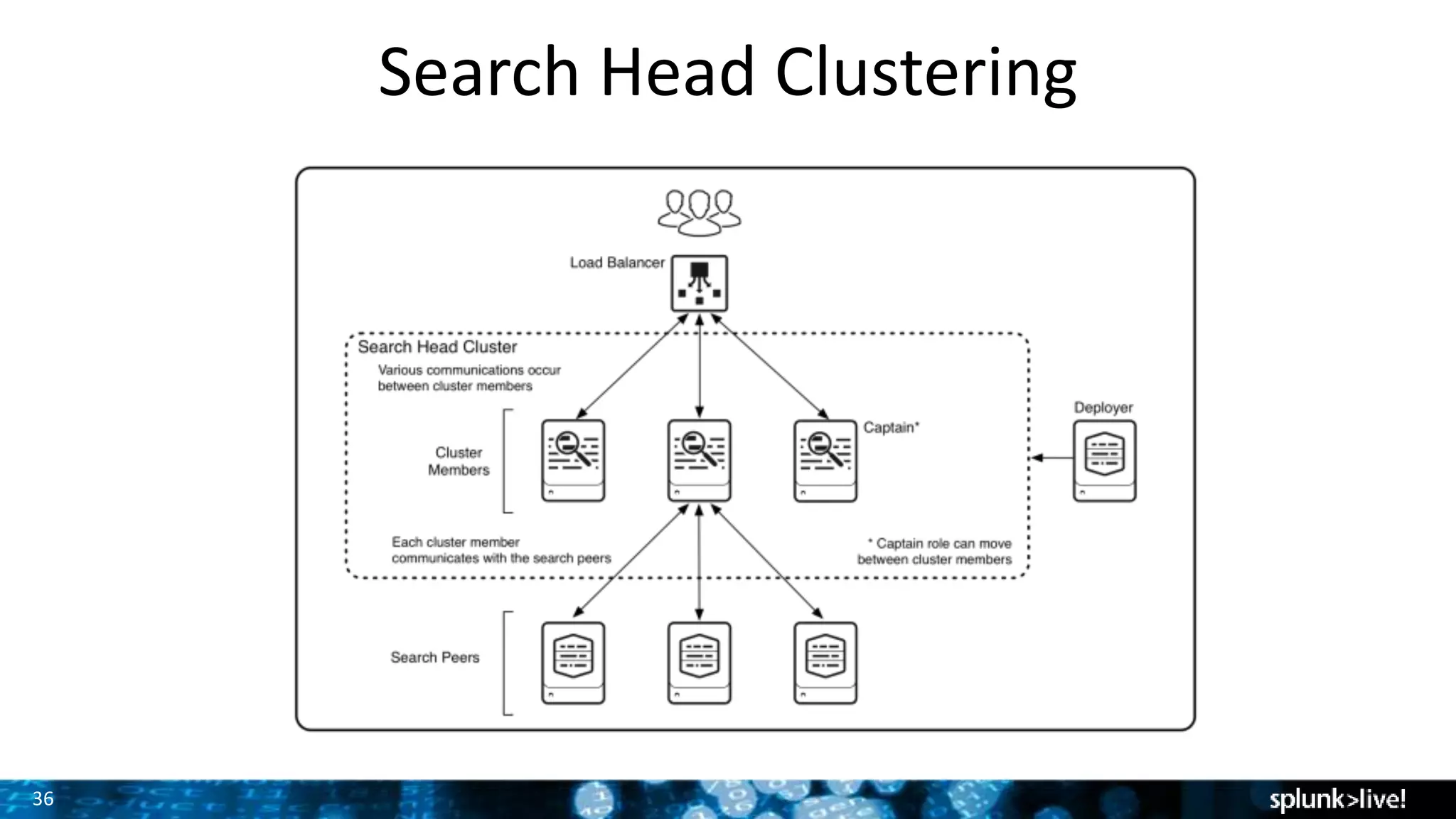


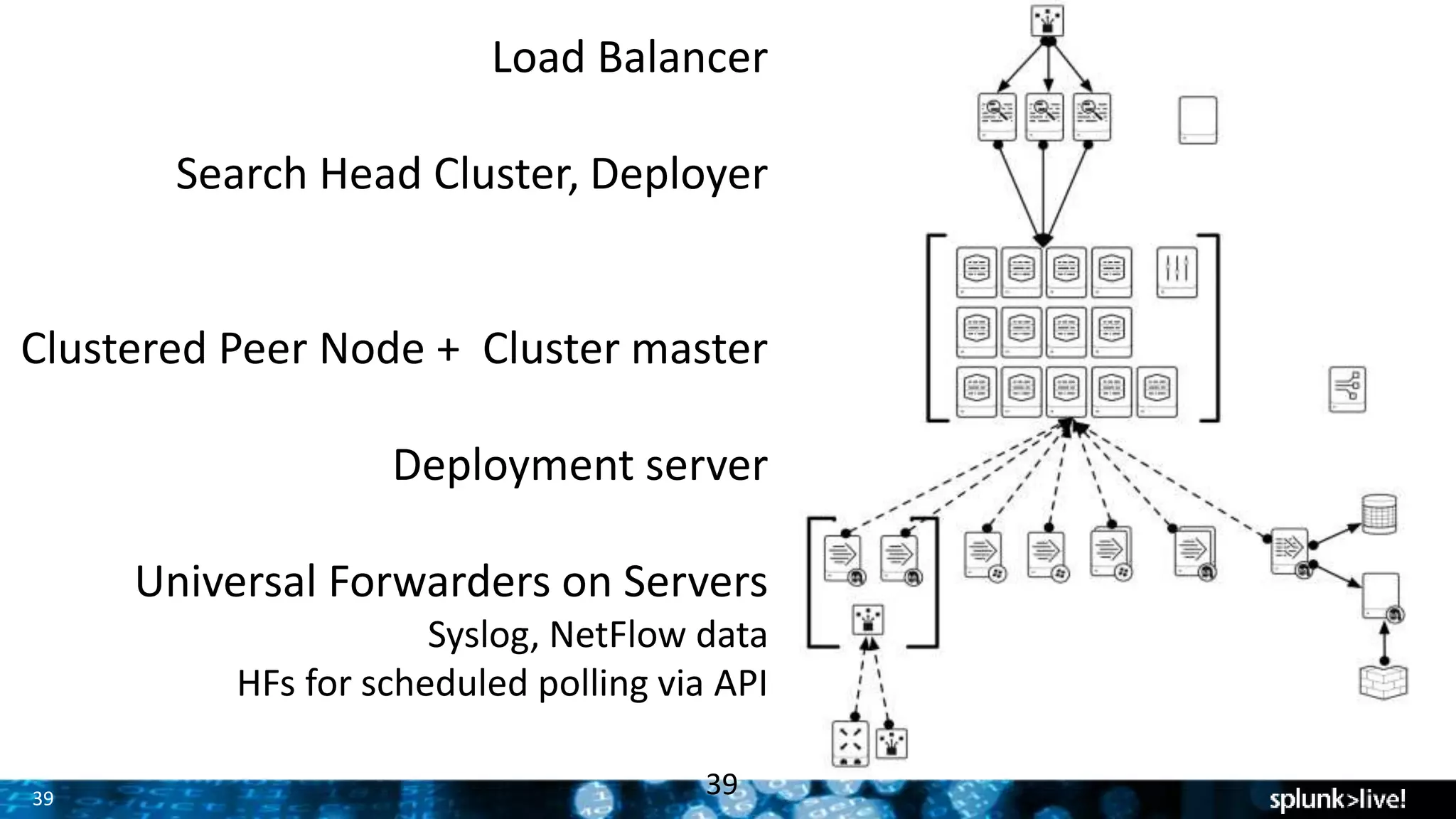
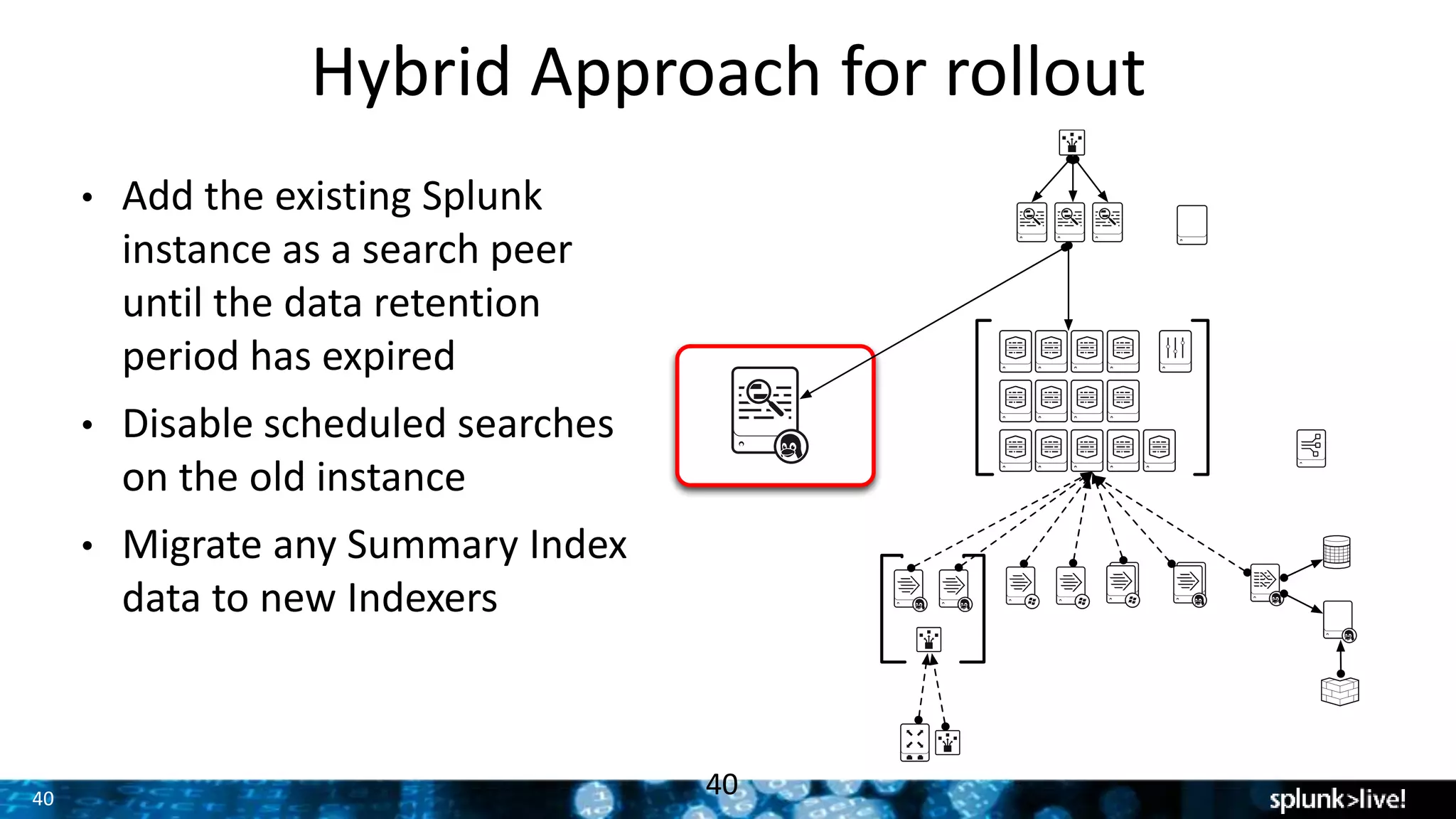







The document presents a comprehensive guide for advancing Splunk deployments, focusing on technical architecture, scaling strategies, and the importance of dependencies and data management. It covers various roles within Splunk, such as forwarders, indexers, and search heads, while emphasizing the significance of high availability and performance in mission-critical environments. Best practices for deployment, storage, and system configurations are also outlined to enhance the user experience and operational efficiency.

![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)



























































































