More Related Content

PPTX

PPTX

PPTX

PDF
PostgreSQLのトラブルシューティング@第5回中国地方DB勉強会 
PPTX

PPTX

PDF

PDF
PostgreSQLアーキテクチャ入門(PostgreSQL Conference 2012) What's hot

PDF
PacemakerのMaster/Slave構成の基本と事例紹介(DRBD、PostgreSQLレプリケーション) @Open Source Confer... 
PDF

PDF

PDF
PostgreSQL安定運用のコツ2009 @hbstudy#5 
PDF

PDF

PDF
5ステップで始めるPostgreSQLレプリケーション@hbstudy#13 
PDF
明日から使えるPostgre sql運用管理テクニック(監視編) 
PDF

PDF
ゆるふわLinux-HA 〜PostgreSQL編〜 
PDF
OSS-DB Goldへの第一歩~実践!運用管理~ 
PDF
PostgreSQL Query Cache - "pqc" 
PDF
PostgreSQLアーキテクチャ入門(INSIGHT OUT 2011) 
PDF
Pacemaker + PostgreSQL レプリケーション構成(PG-REX)のフェイルオーバー高速化 
PDF

PDF
「今そこにある危機」を捉える ~ pg_stat_statements revisited 
PDF
perfを使ったpostgre sqlの解析(後編) 
PDF
C16 45分でわかるPostgreSQLの仕組み by 山田努 
PDF
PostgreSQLのパラレル化に向けた取り組み@第30回(仮名)PostgreSQL勉強会 
PDF
Osc2015 hokkaido postgresql-semi-stuructured-datatype Viewers also liked

PDF
CloudFront構築事例 ハートビーツ 20121025 
PDF

PPTX
OSSで実現するハイブリッドクラウド4ノードクラスタ ~Pacemakerのチケット機能で災害対策~ 
PDF
宣伝費ゼロで累計200万DLに至った経緯 - 写真加工スマホアプリMy Heart Camera と Pico Sweet 
PDF

PDF

PDF

PDF
物理サーバとクラウドの運用管理の違い 2010 03 24 馬場 
PDF
プロジェクトとプロジェクトマネジメントの基本 
PDF
著名PHPアプリの脆弱性に学ぶセキュアコーディングの原則 
PDF

PDF
Similar to hbstudy#06

PDF
C22 Oracle Database を監視しようぜ! by 山下正/内山義夫 
PDF
オープンソース統合監視ソフトウェア Zabbix 2.0によるクラウド監視 
PDF

PDF
オープンソースでシステム監視!統合監視ソフトウェアZabbix 
PDF
オープンソース統合運用管理ツール『Hinemos』 --- その利便性及びインシデント管理について --- 
PDF

PDF
![[AWS Summit 2012] クラウドデザインパターン#6 CDP クラウド監視編](https://cdn.slidesharecdn.com/ss_thumbnails/aws-summit-cdp-06-121001114848-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[AWS Summit 2012] クラウドデザインパターン#6 CDP クラウド監視編 
PDF
【セミナー講演資料】オープンクラウドソリューションのご紹介 
PDF
第1回『いまさら聞けない!システム運用・管理のコツ』 『クラウド管理・運用サービス「E.C.O」のご紹介』 
PDF

PDF

PDF
Zabbix2.0の新機能と今後の開発ロードマップ 
PDF

PDF
20100520 【qpstudy01】 チームでトライ!インフラ構築のススメ 
PDF
Amazon Ec2 S3実践セミナー 2009.07 
PDF
オープンソースでシステム監視!統合監視ソフトウェアZabbix 
PDF
System Center Operations Managerによる仮想環境の高度な管理 
PDF
Heroshima "Cloud & Security Day" and Night 
PPTX
hbstudy#06
- 1.
- 2.
agenda
インフラエンジニアのお仕事
監視とは
なぜ監視が必要なのか
どうやって監視するか
監視チームを作る
- 3.
誰?
坂口利樹 ( さかぐちとしき )
twitter : tsakaguchi
Mail : sakaguchi.toshiki@gmail.com
インフラエンジニア
エンジニア歴 2 年半 ( しんそつ )
PostgreSQL Confarence 2009 Tokyo/Fall 実行委員
- 4.
インフラエンジニアのお仕事
定例業務
定例業務 非定例業務
設計、アーキテクト
●
管理
● ●
ボトルネックの解析・ログ解析
●
機器・設定情報の管理 高負荷プロセスの分析
●
リソース管理 ●
運用方法・監視方法の検討・提案
●
バックアップ
●
権限・セキュリティ管理 選定
●
●
ネットワーク・サーバ
監視
●
OS ・アプリケーション
●
システム・機器の稼働状況、 iDC ・回線等の選定
リソース状況・ログ出力、改竄検知 ●
負荷テスト
●
障害対応
構築
●
問い合わせ対応・サポート
● ●
サーバ、機器のセットアップ
●
社内外からの問い合わせ ラックマウント・ケーブリング
SSL 証明書取得・設定
- 5.
インフラエンジニアのお仕事
定例業務
定例業務 非定例業務
設計、アーキテクト
●
管理
● ●
ボトルネックの解析・ログ解析
●
機器・設定情報の管理 高負荷プロセスの分析
●
リソース管理 ●
運用方法・監視方法の検討・提案
●
バックアップ
●
権限・セキュリティ管理 選定
●
●
ネットワーク・サーバ
監視
●
OS ・アプリケーション
●
システム・機器の稼働状況、 iDC ・回線等の選定
リソース状況・ログ出力、改竄検知 ●
負荷テスト
●
障害対応
構築
●
問い合わせ対応・サポート
● ●
サーバ、機器のセットアップ
●
社内外からの問い合わせ ラックマウント・ケーブリング
SSL 証明書取得・設定
- 6.
- 8.
監視とは
システムやネットワークの状況変化を
知るための情報収集活動
- 9.
- 10.
なぜ監視が必要なのか
大前提:ビジネス・サービスが動いている
高可用性が求められる
すべての障害を予期することは困難
機能停止 性能低下
機能監視 性能把握
- 11.
監視の種類を分類
機能監視 性能把握
●
L1 〜 L3 ネットワーク
●
L4 〜 L7 サービス
● HTTP(S) システムリソース
●
POP3(S)
CPU 使用量
●
●
● SMTP(S)
● IMAP(S) ●
メモリ使用量
DNS
Disk I/O
●
●
● SSH
● (S)FTP ●
Network( 遅延・帯域 )
●
DB への接続状態 ●
DB の内部状態
●
プロセス死活
●
ログ出力
● RAID
- 12.
監視の種類を分類
機能監視 性能把握
●
L1 〜 L3 ネットワーク
●
L4 〜 L7 サービス
● HTTP(S) システムリソース
●
POP3(S)
CPU 使用量
●
●
● SMTP(S)
● IMAP(S) ●
メモリ使用量
DNS
Disk I/O
●
●
● SSH
● (S)FTP ●
Network( 遅延・帯域 )
●
DB への接続状態 ●
DB の内部状態
●
プロセス死活
●
ログ出力
● RAID
- 13.
- 14.
どうやって監視するか
監視ツールを使う
メリット
既に欲しい機能が作り込まれている
オープンソース
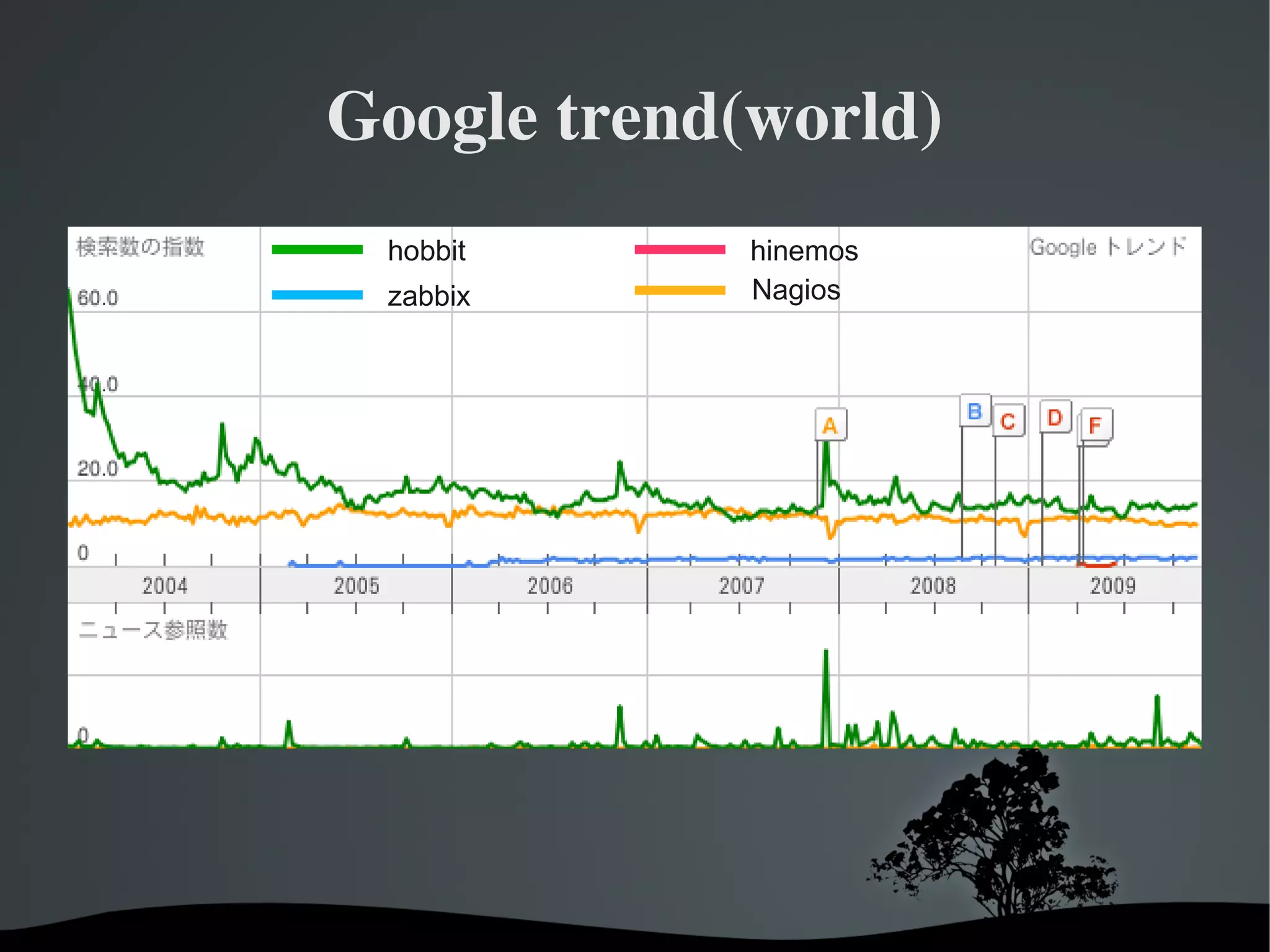
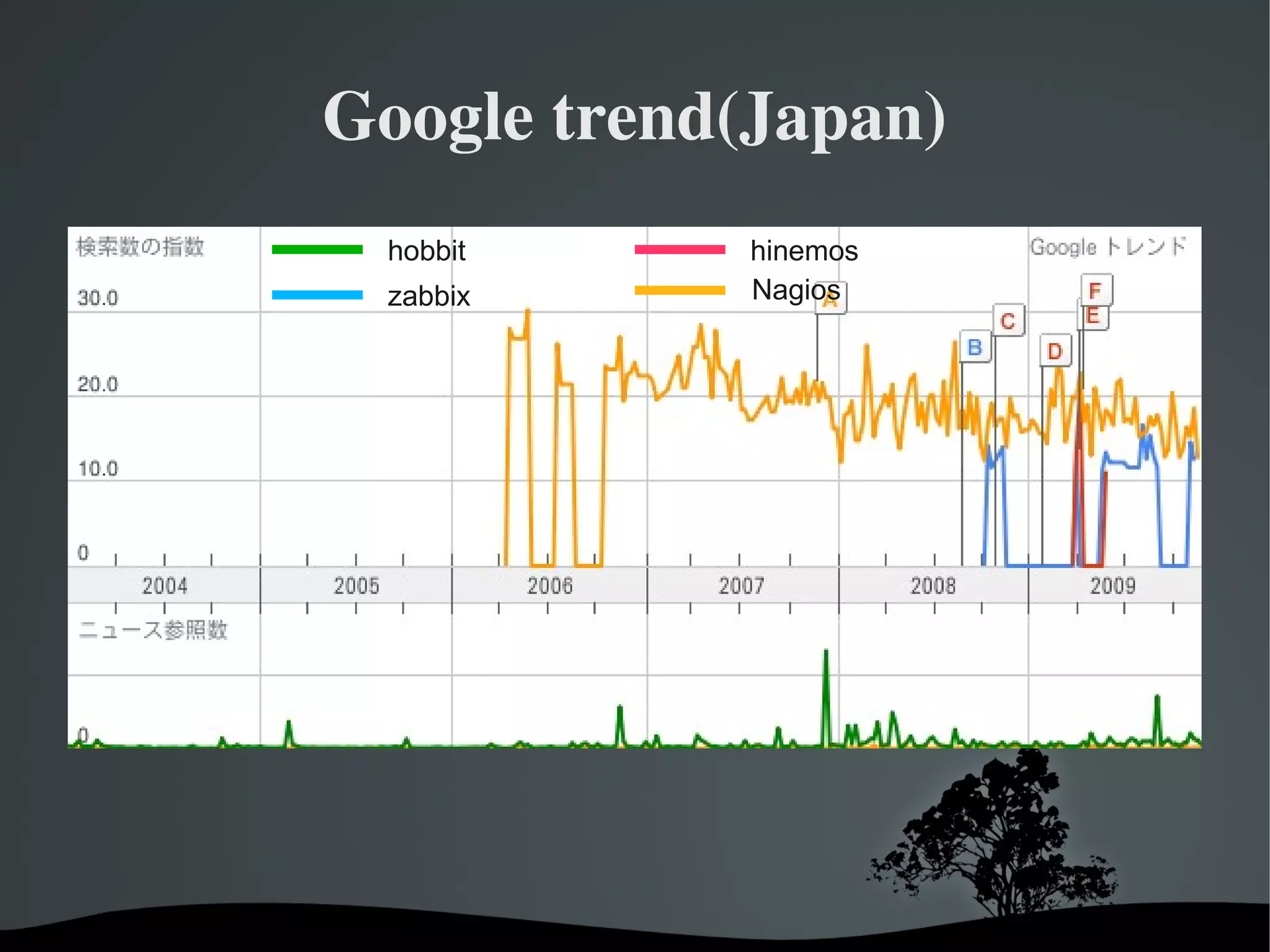
ZABBIX
Hinemos
Nagios
hobbit(Xymon)
- 15.
- 16.
- 17.
監視ツール選定 (1)
機能
スケジューリング
人間のスケジュールに合わせた運用
例:バッチ処理時間帯はある程度の負荷を許容
柔軟性
プラグインで拡張可能か!?
Nagios の場合、プラグインの exit code で判定
0: OK
1: WARNING
2: CRITICAL
- 18.
監視ツール選定 (2)
性能
Nagios の場合、 3 年前のマシン 1 台で 400 台く
らいが目安
Pentium4 3GHz, mem 1GB で検証→ 400 台、 4000 項目程度は OK
Nagios は AMQP と組み合わせてスケールアウト
もできるらしい ( 未検証 )
- 19.
監視ツール選定 (3)
運用
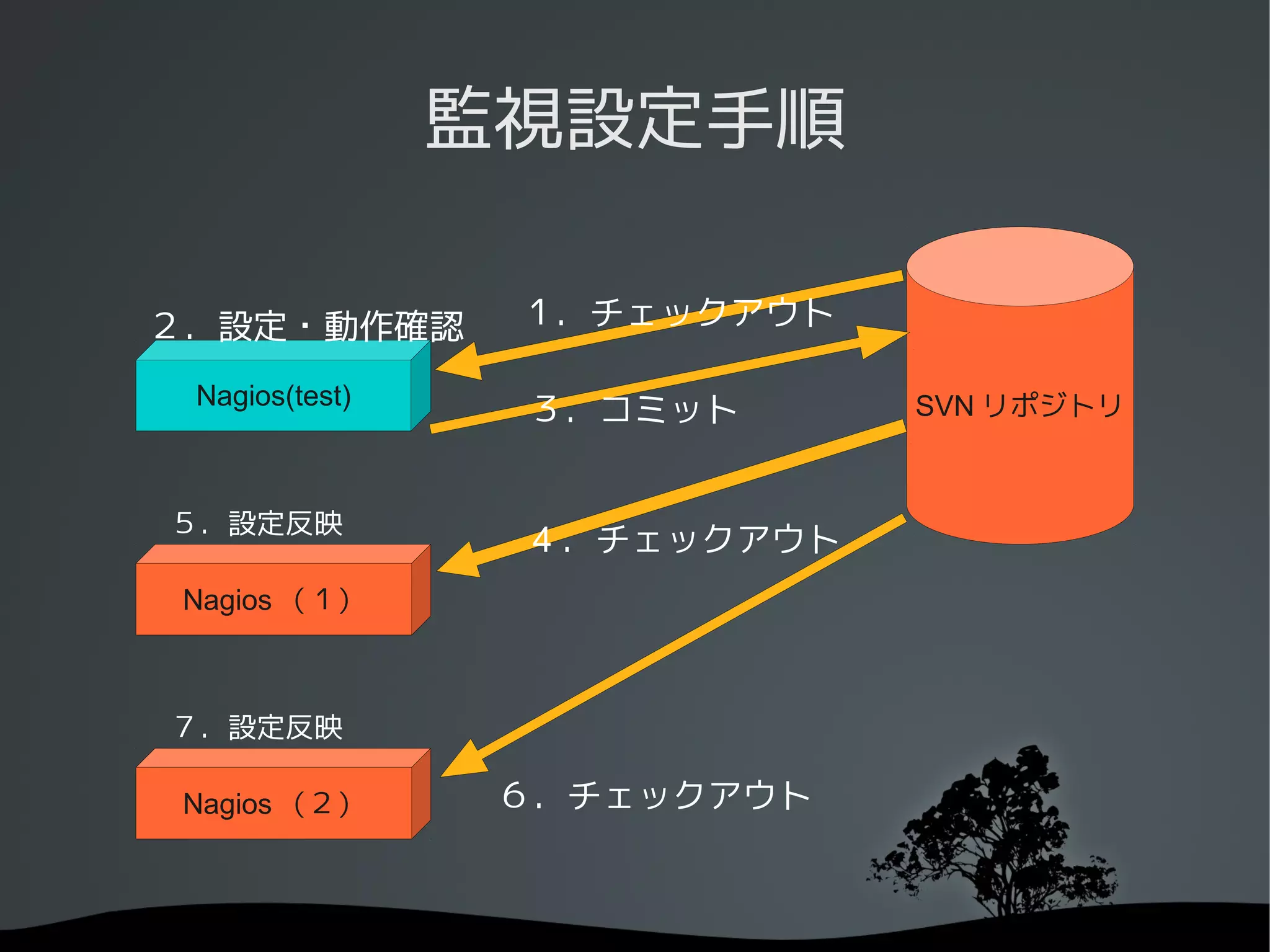
設定内容の管理
バージョン管理システム ( ハートビーツでは SVN)
で管理できると楽
テスト環境の用意
バージョン管理システムと組み合わせて
テスト環境を構築しています
テスト環境はメールが一切飛ばないようにしています
- 20.
監視設定手順
2.設定・動作確認 1.チェックアウト
Nagios(test)
3.コミット SVN リポジトリ
5.設定反映
4 .チェックアウト
Nagios (1)
7.設定反映
Nagios (2) 6.チェックアウト
- 21.
監視のポイント
何のサービスが動いているか
最適な監視
必要なところ ( 使っているところ )
監視項目をむやみに増やしすぎない
使う側の視点
- 22.
監視サーバのネットワーク
2拠点から監視
別キャリアのネットワーク
Nagios(1)
Internet 監視対象サーバ
Nagios(2)
- 23.
監視項目例 (Web サイト)
外部
内部
HTTP/HTTPS LoadAverage
表示されるまでの時間
メモリ
文字列
プロセス総数
ログイン
ログ出力
シナリオ
プロセス稼働状況
回線使用状況
DB レプリケーション
Disk 残容量
Disk I/O
- 24.
監視項目例 (JavaVM)
プロセス死活
ヒープ域不足 (Out of Memory)
OOM Killer によりプロセスが Kill される
Tomcat/Jboss プロセスサイズ
ログ監視
- 25.
監視項目例 (MySQL)
Mysql Status の取得
Web サーバから DB サーバへの接続
レプリケーションの状況
テーブルを作成して削除
- 26.
システム監視だけじゃない!
大事なのはビジネスなので、そのレイヤーまで見る!
IBM 用語で「センス アンド レスポンド」というそうです
例えば・・・
システムのログインユーザ数を監視 (DB へのクエリ結
果)
広告からのサイト流入量を監視 (DB へのクエリ結果 )
- 27.
閾値の調整
閾値の決定ポリシー
サービスによって様々
運用しながら
誤報
なくすことはできない(宿命)
減らすことはできる
リトライチェック
根本的な解決を !
- 28.
誤報撲滅!
遠い場合 (EC2 、中国にあるサーバ )
パケットロスは容認
リトライ回数を増やす
対応しないアラートは誤報と同じ
「アラートを無視する習慣」につながるので、重点
的になくす!
「アラートを無視する習慣」がついたら一巻の終わ
り
- 29.
閾値の調整例
どこまでが正常なのか
サイト表示: 3 秒〜 5 秒 ( 目標値 )
LoadAverage : CPU のコア数
SWAP : 20%
プロセス総数
Web サーバ (Apacheprefork) の場合
稼働中のプロセス総数
+
(MaxClients 稼働中の httpd プロセス数 )
- 30.
対応の自動化
イベントハンドラの活用
LB から切り離す
落とし穴に注意
例: Apache の自動再起動スクリプト
セマフォによるリソース管理の上限で Apache が自動起動されず、
web サービスが復旧しない
Apache 管理ユーザのセマフォの削除を手動で行い解決
- 31.
監視の種類を分類
障害監視 性能監視
●
L1 〜 L3 ネットワーク死活
●
L4 〜 L7 サービス監視
● HTTP(S)
POP3(S)
システムリソース
●
● SMTP(S) ●
● IMAP(S)
● DNS ● CPU
SSH
メモリ使用量
●
● (S)FTP ●
DB への接続状態・内部
● Disk I/O
●
●
システムリソース
●
ログインユーザ数 ● Network
プロセス死活
DB の内部状態
●
●
● CPU
●
Memory 使用量
●
SWAP 使用量
●
ディスク空き容量
●
ログ出力
- 32.
なぜ監視するか
変化の把握
ボトルネックの把握
チューニング
スケールアウト / スケールアップ
後々必要になってくるので早い段階からの実装
キャパシティプランニング
このシステムでどれだけこなせるか
どのタイミングで増設が必要になるか
- 33.
どうやって監視するか
ツールを使う
MRTG
Cacti
Munin
ZABBIX
Hinemos
- 34.
- 35.
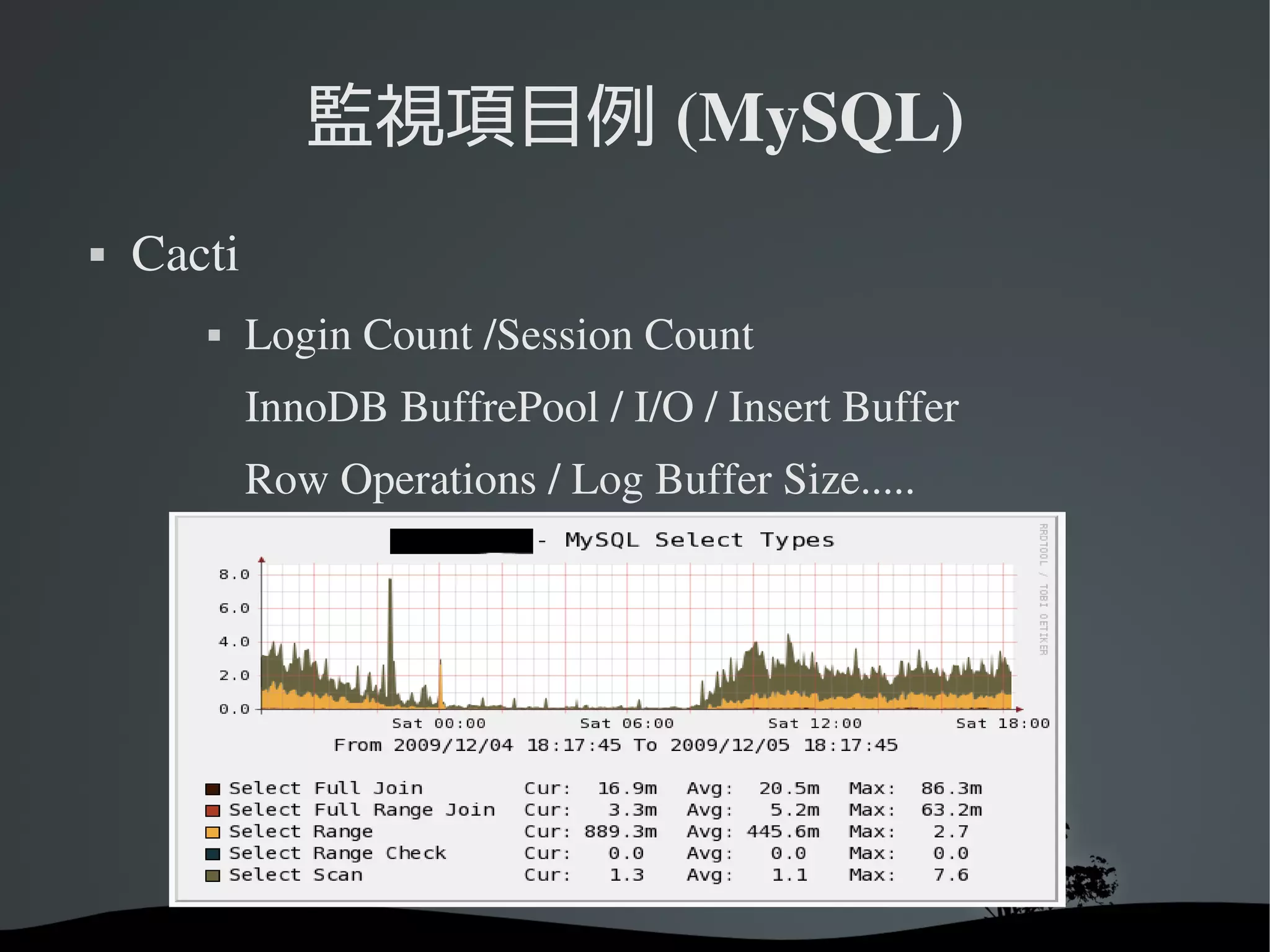
監視項目例 (MySQL)
Cacti
Login Count /Session Count
InnoDB BuffrePool / I/O / Insert Buffer
Row Operations / Log Buffer Size.....
- 36.
- 37.
監視チームを作る
監視と障害対応は切り離せない
一人ではやりきれない
夜間の障害対応
複数同時の障害
精神的・労務的な問題
24 時間 365 日
4 人は最低必要 ( 休み無し )
- 38.
情報共有
アラートメールの送信先
インフラ担当だけでなく開発や企画担当の人も
ドキュメント ( 監視仕様書 )
人を育てるのにも有効
- 39.
ドキュメントの書き方のコツ
ネットワーク構成図
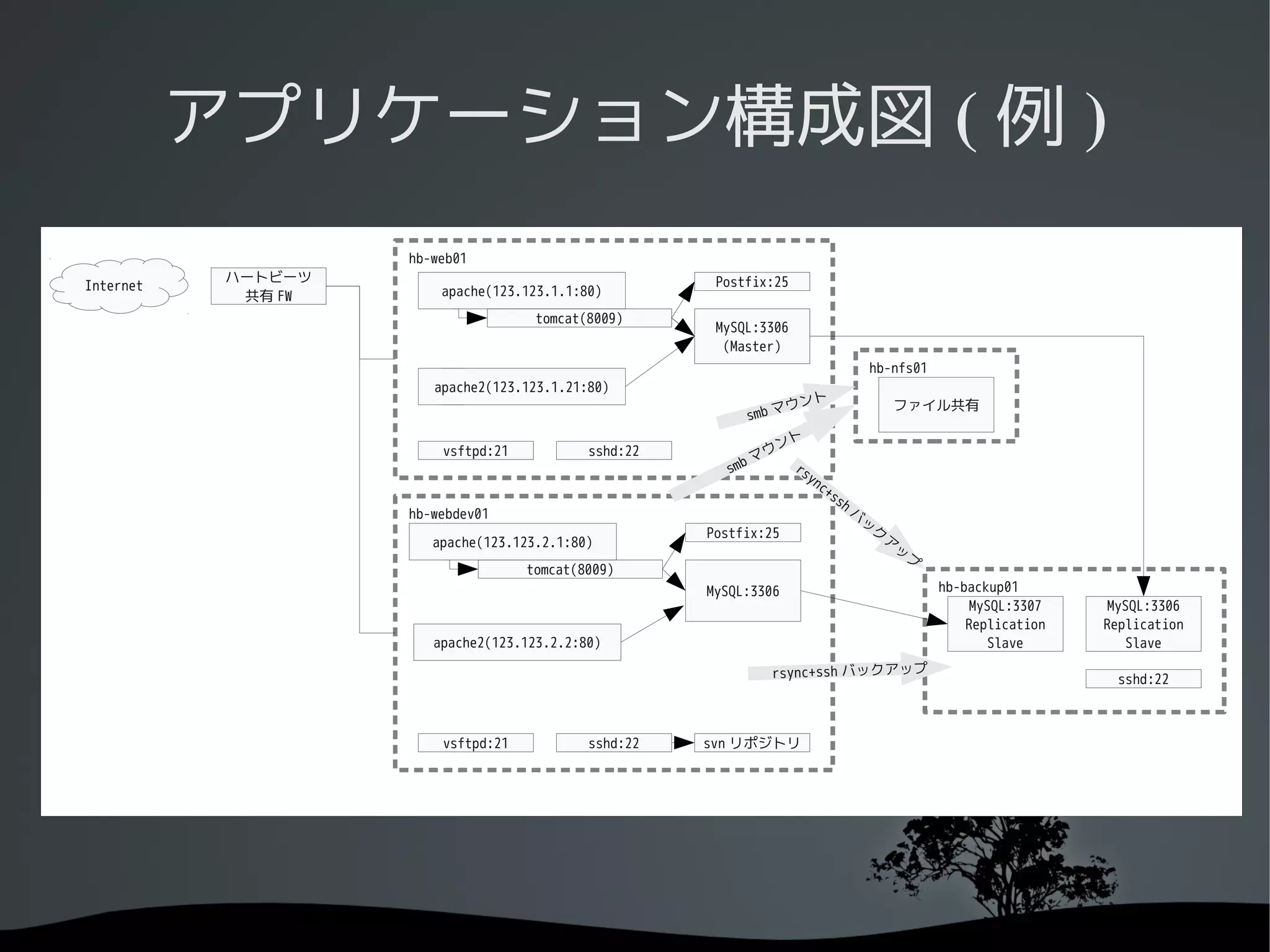
アプリケーション構成図
対応フローの確定
監視項目ごとの状況確認方法
監視項目ごとの対応方法
- 40.
アプリケーション構成図 ( 例)
hb-web01
ハートビーツ Postfix:25
Internet apache(123.123.1.1:80)
共有 FW
tomcat(8009)
MySQL:3306
(Master)
hb-nfs01
apache2(123.123.1.21:80)
ト
ウン ファイル共有
smb マ
ト
vsftpd:21 sshd:22 ウン
sm bマ rs
yn
c+
ss
h
hb-webdev01 バ
ッ
Postfix:25 ク
apache(123.123.2.1:80) ア
ッ
プ
tomcat(8009)
MySQL:3306 hb-backup01
MySQL:3307 MySQL:3306
Replication Replication
apache2(123.123.2.2:80) Slave Slave
rsync+ssh バックアップ sshd:22
vsftpd:21 sshd:22 svn リポジトリ
- 41.
- 42.
- 43.
- 44.
- 45.
対応する人の決定の補足
お見合いが一番怖い
ダウンタイムだけが伸びたら・・・ビジネスに影響大!
誰がボールを持っているか、常に明確に!
アラート同報だと誰がボールを持っているか不明確
深夜の場合、ボールを受け取った後や、対応中にホストダウン ( 居
眠り ) の可能性も・・・
ハートビーツの場合、ひとりずつ電話をかけるのでボールの持ち
主は明確になります
対応完了のご連絡をいただけない場合、ベストエフォートでリ
マインドもできます
- 46.