Download to read offline


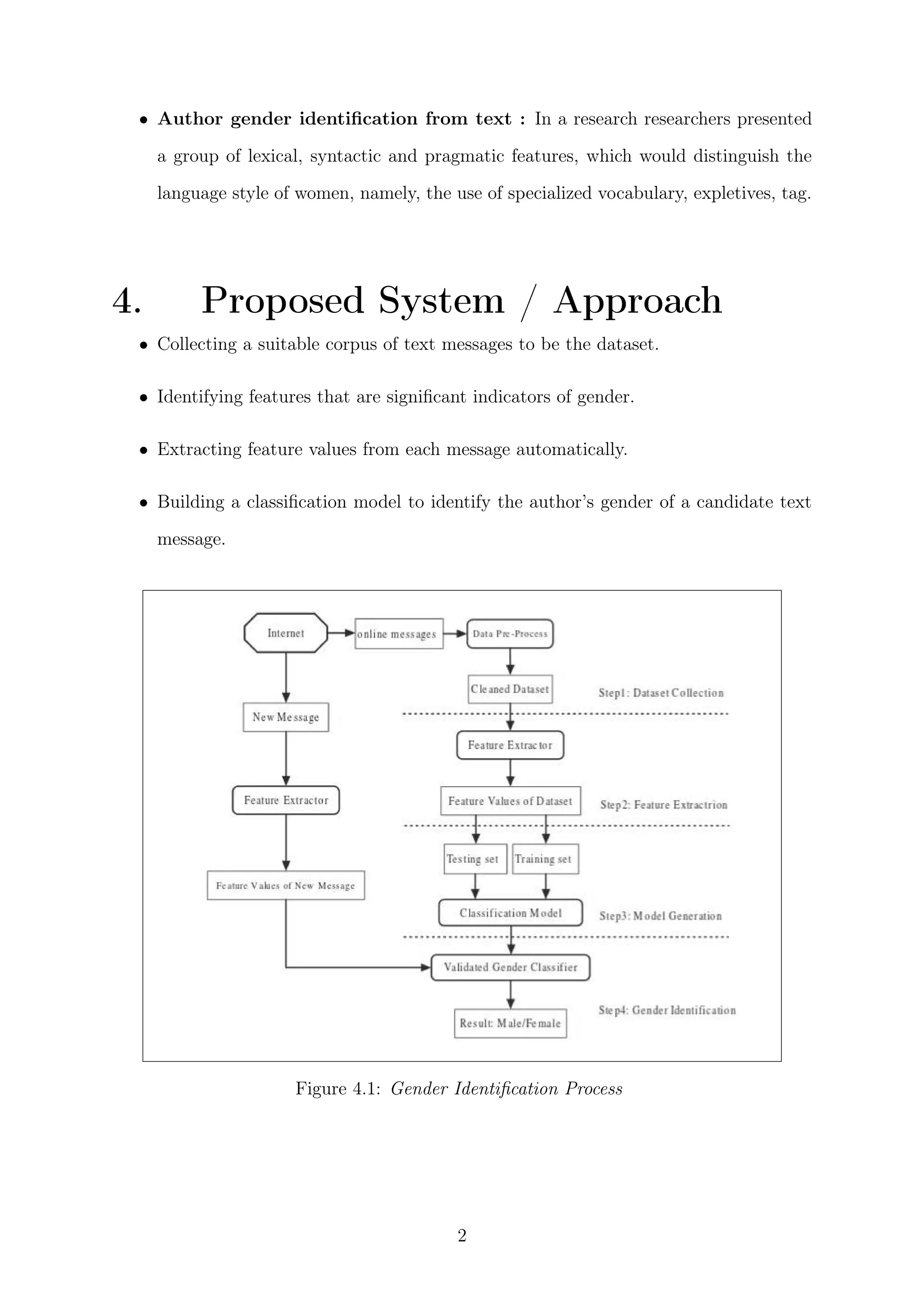


This document summarizes a project on gender detection in blogs. The project aimed to identify whether a blog post was written by a male or female author based on linguistic features. Three machine learning algorithms were tested on a dataset of blog posts and tweets, with support vector machines achieving the highest accuracy of 85.1% at gender identification. The proposed approach involved collecting a dataset, identifying gender-indicative features, extracting feature values, and building a classification model. Evaluation on different sized training sets showed accuracy improved with more training data. The conclusion was that word-based, functional, and structural features help identify gender, and performance increases with more training documents and words per document.




























![Gender Detection In Blogs [Information Retrival and Extraction]](https://cdn.slidesharecdn.com/ss_thumbnails/ireproject2-160414075505-thumbnail.jpg?width=640&height=640&fit=bounds)












