Downloaded 49 times








![ Step 1:compare p[1] with S[1]
S a b c a b a a b c a b a c
p
a b a a
Step 2: compare p[2] with S[2]
a b c a b a a b c a b a c
a b a a](https://image.slidesharecdn.com/stringmatching-131227122620-phpapp02/85/STRING-MATCHING-9-320.jpg)
![ Step 3: compare p[3] with S[3]
S
a b c a b a a b c a b a c
P
a b a a
Mismatch occurs here..
Since mismatch is detected, shift ‘p’ one position to the left and
perform steps analogous to those from step 1 to step 3.](https://image.slidesharecdn.com/stringmatching-131227122620-phpapp02/85/STRING-MATCHING-10-320.jpg)







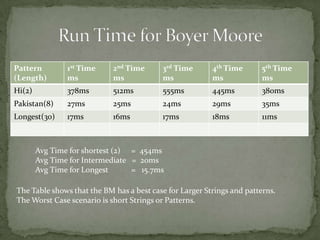






The document discusses two string matching algorithms: Knuth-Morris-Pratt (KMP) and Boyer-Moore (BM). KMP runs in linear time but checks every character, while BM can be sub-linear as it does not need to check every character. The document provides pseudocode examples and comparisons of the running times of KMP and BM on different length patterns, finding that BM performs best on longer patterns while KMP has better performance on shorter patterns. Both algorithms have widespread applications in areas like web search engines, spam filters, and natural language processing.





































![Gp 27[string matching].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/gp27stringmatching-230422183348-6f0879e9-thumbnail.jpg?width=640&height=640&fit=bounds)





























