KMP pattern searching allows efficient searching of a pattern within text by taking advantage of prefix matches. It works by pre-processing the pattern to construct a prefix table indicating the length of matching prefix for all prefixes of the pattern. During searching, when a mismatch occurs, it uses the prefix table to "skip" already compared prefix matches, avoiding repeating comparisons and allowing it to run in linear time O(n+m).






![Pre-processing
Let’s say we’re matching the pattern “abababca” against the text
“bacbababaabcbab”.
Here’s our prefix match table : i.e. prefix-table[i]
index 0 1 2 3 4 5 6 7
char a b a b a b c a
value 0 0 1 2 3 4 0 1
Matching prefix i.e. a
Matching prefix i.e. ab
Matching prefix i.e. aba
Matching prefix i.e. abab
No matching prefix](https://image.slidesharecdn.com/asekmpsearch-201024193733/85/KMP-Pattern-Search-7-320.jpg)
![Pre-processing - cont.
• partial_match_length = length of the matched pattern in a step.
• prefix-table = pre-processed prefix table
• If prefix-table[ partial_match_length ] > 1
we may skip ahead
partial_match_length - prefix-table[ partial_match_length – 1 ] characters.
// Used to skip, already compared prefix match in the pattern.](https://image.slidesharecdn.com/asekmpsearch-201024193733/85/KMP-Pattern-Search-8-320.jpg)
![Searching
b a c b a b a b a a b c b a b
a b a b a b c a
Text
Pattern
b a c b a b a b a a b c b a b
a b a b a b c a
Text
Pattern
This is a partial match length of 1
The value at prefix-table[partial_match_length - 1] (or prefix-table[0]) is 0.
so we don’t get to skip ahead any.](https://image.slidesharecdn.com/asekmpsearch-201024193733/85/KMP-Pattern-Search-9-320.jpg)
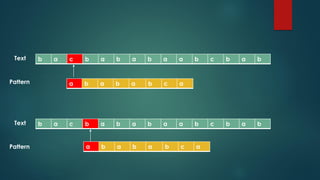

![But in KMP approach, we can directly skip Step 1
b a c b a b a b a a b c b a b
a b a b a b c a
Text
Pattern
X X
b a c b a b a b a a b c b a b
a b a b a b c a
Text
Pattern
This is a partial match length of 5
The value at prefix-table[partial_match_length - 1] (or prefix-table[4]) is 3.
That means we get to skip ahead
partial_match_length – prefix-table[partial_match_length - 1] (or 5 - table[4] = 5 - 3 = 2) characters:
We skip comparing “b”. The next comparison starts at next “ab” i.e. the prefix match.](https://image.slidesharecdn.com/asekmpsearch-201024193733/85/KMP-Pattern-Search-12-320.jpg)
![In KMP we can directly skip comparing “ab”
This is a partial match length of 3
The value at prefix-table[partial_match_length - 1] (or prefix-table[2]) is 1.
That means we get to skip ahead
partial_match_length – prefix-table[partial_match_length - 1] (or 3 - table[2] = 3 - 1 = 2) characters:
b a c b a b a b a a b c b a b
a b a b a b c a
Text
Pattern
b a c b a b a b a a b c b a b
a b a b a b c a
Text
Pattern X X
We skip comparing “b”. The next comparison starts at next “a” i.e. the prefix match.](https://image.slidesharecdn.com/asekmpsearch-201024193733/85/KMP-Pattern-Search-13-320.jpg)









































![Gp 27[string matching].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/gp27stringmatching-230422183348-6f0879e9-thumbnail.jpg?width=640&height=640&fit=bounds)


























