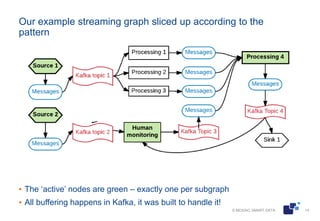
The document discusses the architecture of streaming analytics using asynchronous Python and Kafka, focusing on the benefits and challenges of structuring systems as streaming graphs. It highlights the importance of clear code, scalability, and efficient message scheduling, comparing 'push' and 'pull' approaches to message handling. The presentation concludes with a proposed lightweight design that leverages asyncio and Kafka to manage complex data streams effectively.








































![[March sn meetup] apache pulsar + apache nifi for cloud data lake](https://cdn.slidesharecdn.com/ss_thumbnails/marchsnmeetupapachepulsarapachenififorclouddatalake-220311125943-thumbnail.jpg?width=640&height=640&fit=bounds)
































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)









