Download as PDF, PPTX


![Recurrent Neural Network
• Connec4onist Temporal Classifica4on (CTC) [Alex Graves,
ICML’06][Alex Graves, ICML’14][Haşim Sak, Interspeech’15][Jie Li,
Interspeech’15][Andrew Senior, ASRU’15]
好
φ
φ
棒
φ
φ
φ
φ
好
φ
φ
棒
φ
棒
φ
φ
“好棒”
“好棒棒”
Add an extra symbol
“φ” represen4ng “null”](https://image.slidesharecdn.com/random-160717002419/85/slide-6-320.jpg)
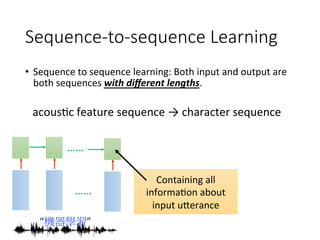
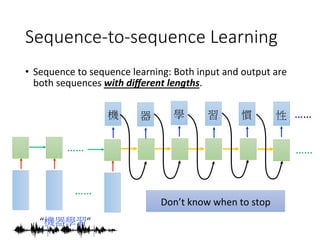
![Sequence-to-sequence Learning
• Sequence to sequence learning: Both input and output are
both sequences with different lengths.
……
……
“機器學習”
機
習
器
學
Add a symbol “。 “ (句點)
[Ilya Sutskever, NIPS’14][Dzmitry Bahdanau, arXiv’15]
。](https://image.slidesharecdn.com/random-160717002419/85/slide-9-320.jpg)
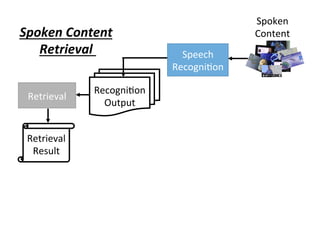

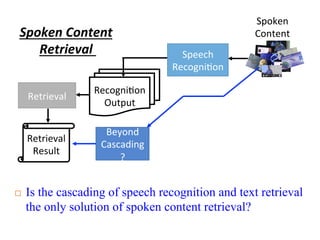


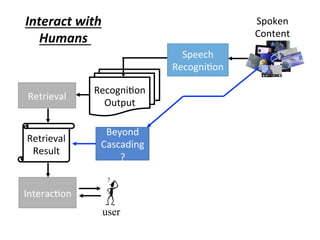
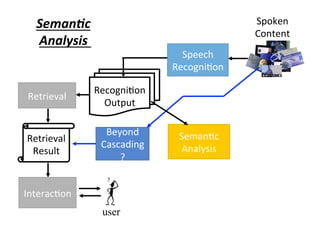

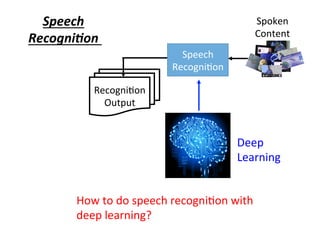
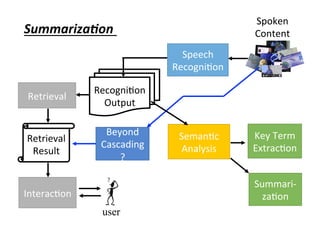
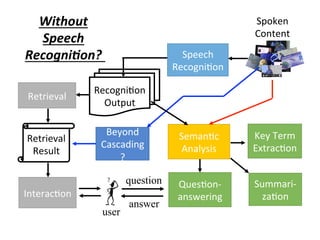
![Spoken
Content
Speech
Recogni4on
Beyond
Cascading
?
Recogni4on
Output
Retrieval
Seman4c
Analysis
Key Term
Extrac4on
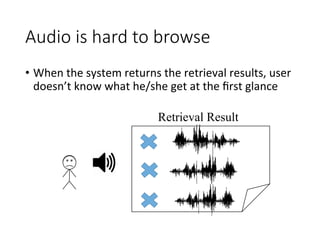
Retrieval
Result
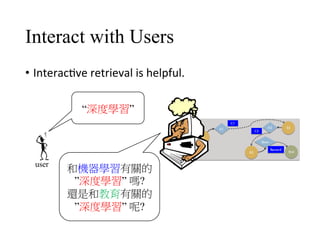
Interac4on
user
Key Term
Extrac,on
[Interspeech
2015]
(with 沈昇勳)](https://image.slidesharecdn.com/random-160717002419/85/slide-22-320.jpg)


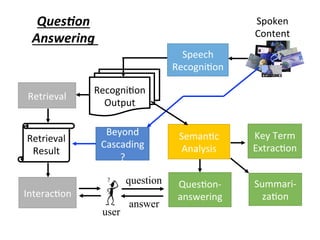




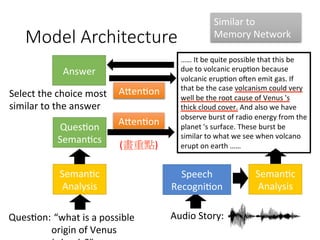
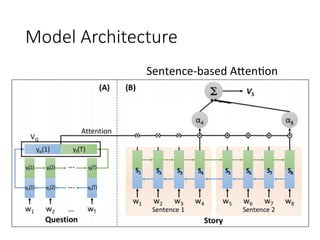
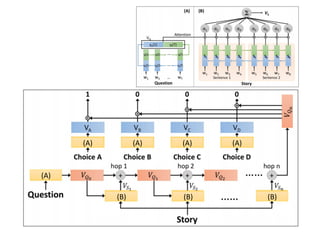


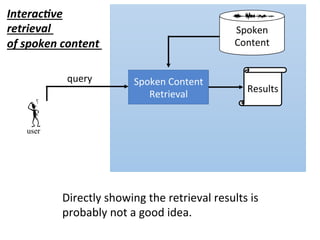
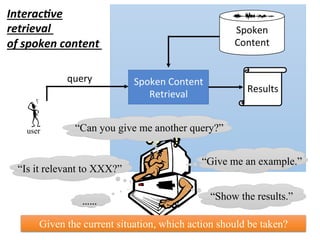
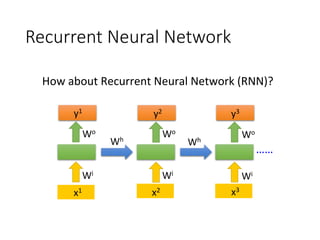
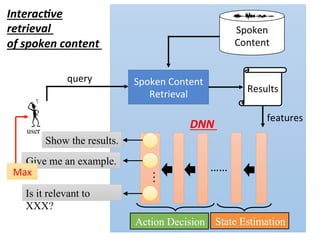
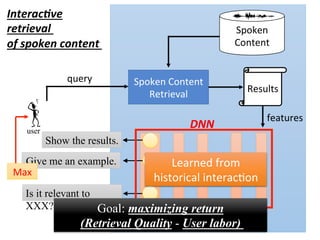
![user
Spoken Content
Retrieval
Results
Spoken
Content
Interac,ve
retrieval
of spoken content
query
State
Es4ma4on
Ac4on
Decision
state
The degree of
clarity from the
retrieval results
ac4on
features
¤ The policy π(s) is a function
¤ Input: state s, output: action a
Decide the actions by intrinsic
policy π(S)
[Interspeech 2012][ICASSP 2013]](https://image.slidesharecdn.com/random-160717002419/85/slide-43-320.jpg)



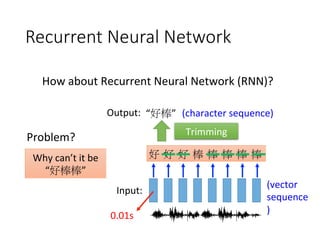
![Spoken Content Retrieval without
Speech Recognition
user
“US President”
spoken query
[Hazen, ASRU 09]
[Zhang Glass, ASRU 09]
[Chan Lee, Interspeech 10]
[Zhang Glass, ICASSP 11]
[Gupta, Interspeech 11]
[Zhang Glass, Interspeech 11]
[Zhang Glass, ASRU 09]
[Huijbregts, ICASSP 11]
[Chan Lee, Interspeech 11]
Computing similarity between spoken queries and audio
files on signal level
Spoken Content
Handheld
device](https://image.slidesharecdn.com/random-160717002419/85/slide-58-320.jpg)





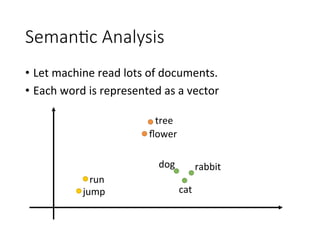
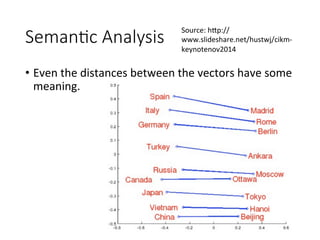
The document discusses the application of deep learning techniques in speech processing, highlighting challenges and advancements in speech recognition and spoken content retrieval. It covers methods such as recurrent neural networks, sequence-to-sequence learning, and semantic retrieval, as well as the integration of speech recognition and text retrieval systems. Additionally, it explores unsupervised learning and interactive retrieval systems to improve accuracy in understanding spoken content.










![[DL輪読会]Parallel WaveNet: Fast High-Fidelity Speech Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/0105-180105000252-thumbnail.jpg?width=640&height=640&fit=bounds)





































![[台灣人工智慧學校] 人工智慧技術發展與應用](https://cdn.slidesharecdn.com/ss_thumbnails/version5-final-190319060225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/openingsw-190315170512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 工業 4.0 與智慧製造的發展趨勢與挑戰](https://cdn.slidesharecdn.com/ss_thumbnails/20190316jyh-horngchou-190315170336-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 開創台灣產業智慧轉型的新契機](https://cdn.slidesharecdn.com/ss_thumbnails/aiotforaiabytedchangho-190227081005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 開創台灣產業智慧轉型的新契機](https://cdn.slidesharecdn.com/ss_thumbnails/aiinhealthcare-20190216victoria-v6-190227081004-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 台北總校第三期結業典禮 - 執行長談話](https://cdn.slidesharecdn.com/ss_thumbnails/tp3closingsw-190126030359-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] AI 引爆新工業革命,智慧機械首都台中轉型論壇](https://cdn.slidesharecdn.com/ss_thumbnails/aia-chen-190116063635-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] 2019 台灣數位轉型 與產業升級趨勢觀察](https://cdn.slidesharecdn.com/ss_thumbnails/to-sheng-190116063620-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] 智慧製造成真! 產線導入AI的致勝關鍵](https://cdn.slidesharecdn.com/ss_thumbnails/thu-hsu-190116063619-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 從經濟學看人工智慧產業應用](https://cdn.slidesharecdn.com/ss_thumbnails/1-the-application-of-ai-industry-from-economics-190108064940-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 台中分校第二期開學典禮 - 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/tc2-opening1-compressed-190107034100-thumbnail.jpg?width=640&height=640&fit=bounds)

![[台中分校] 第一期結業典禮 - 執行長談話](https://cdn.slidesharecdn.com/ss_thumbnails/sw-ppt-181217031715-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 工業4.0潛力新應用! 多模式對話機器人](https://cdn.slidesharecdn.com/ss_thumbnails/20181206004-181210031031-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] AI整合是重點! 竹科的關鍵轉型思維](https://cdn.slidesharecdn.com/ss_thumbnails/20181206002-181210031031-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 2019 台灣數位轉型與產業升級趨勢觀察](https://cdn.slidesharecdn.com/ss_thumbnails/20181206-001-181210031002-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 深度學習與Kaggle實戰](https://cdn.slidesharecdn.com/ss_thumbnails/20181206003-181210031001-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] Bridging AI to Precision Agriculture through IoT](https://cdn.slidesharecdn.com/ss_thumbnails/hc-2nd-openingai-school-181206104858-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] 產業經驗分享: 如何用最少的訓練樣本,得到最好的深度學習影像分析結果,減少一半人力,提升一倍品質 / 李明達](https://cdn.slidesharecdn.com/ss_thumbnails/lee-181130104127-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] 啟動物聯網新關鍵 - 未來由你「喚」醒 / 沈品勳](https://cdn.slidesharecdn.com/ss_thumbnails/20181117shengfn-181130083931-thumbnail.jpg?width=640&height=640&fit=bounds)



















