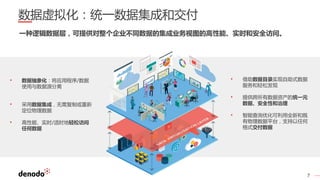
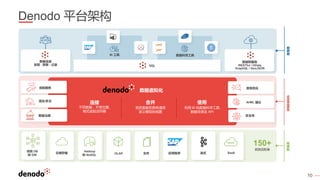
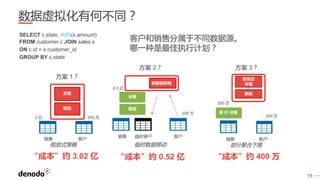
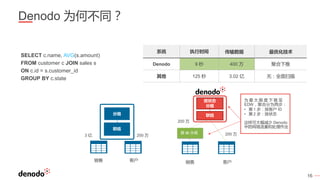
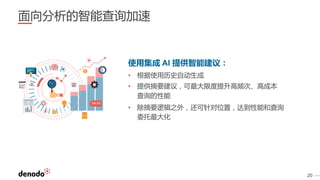
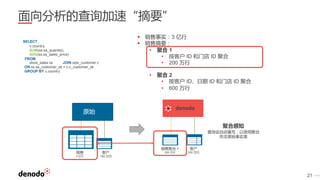
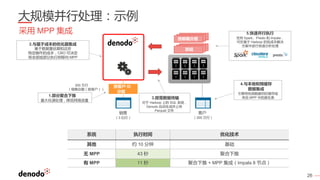
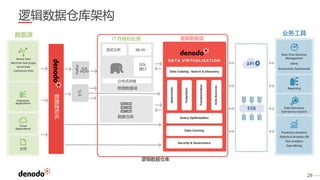
Denodo是一家全球领先的数据虚拟化公司,客户超过800家,涵盖各行业,年增长率超过60%。数据虚拟化提供数据的集成视图,简化查询逻辑,并打破数据之间的隔阂,同时还可以通过智能查询优化提升性能并降低系统负载。常见的误区包括数据虚拟化不是简单的数据联合,且具备强大的实时和非实时数据处理能力。










































![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)


















































