Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Kitamura Laboratory
PPTX, PDF
510 views
調波打撃音分離の時間周波数マスクを用いた線形ブラインド音源分離
大藪宗一郎, "調波打撃音分離の時間周波数マスクを用いた線形ブラインド音源分離," 香川高等専門学校電気情報工学科 卒業研究論文, 47 pages, 2020年2月.
Engineering
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Downloaded 13 times
1
/ 17
2
/ 17
3
/ 17
4
/ 17
5
/ 17
6
/ 17
7
/ 17
8
/ 17
9
/ 17
10
/ 17
11
/ 17
12
/ 17
13
/ 17
14
/ 17
15
/ 17
16
/ 17
17
/ 17
More Related Content
PDF
独立深層学習行列分析に基づく多チャネル音源分離(Multichannel audio source separation based on indepen...
by
Daichi Kitamura
PPTX
独立性に基づくブラインド音源分離の発展と独立低ランク行列分析 History of independence-based blind source sep...
by
Daichi Kitamura
PDF
ICASSP 2019での音響信号処理分野の世界動向
by
Yuma Koizumi
PPTX
音源分離における音響モデリング(Acoustic modeling in audio source separation)
by
Daichi Kitamura
PPTX
調波打撃音モデルに基づく線形多チャネルブラインド音源分離
by
Kitamura Laboratory
PDF
音源分離 ~DNN音源分離の基礎から最新技術まで~ Tokyo bishbash #3
by
Naoya Takahashi
PPTX
独立低ランク行列分析に基づく音源分離とその発展
by
Kitamura Laboratory
PPTX
半教師あり非負値行列因子分解における音源分離性能向上のための効果的な基底学習法
by
Daichi Kitamura
独立深層学習行列分析に基づく多チャネル音源分離(Multichannel audio source separation based on indepen...
by
Daichi Kitamura
独立性に基づくブラインド音源分離の発展と独立低ランク行列分析 History of independence-based blind source sep...
by
Daichi Kitamura
ICASSP 2019での音響信号処理分野の世界動向
by
Yuma Koizumi
音源分離における音響モデリング(Acoustic modeling in audio source separation)
by
Daichi Kitamura
調波打撃音モデルに基づく線形多チャネルブラインド音源分離
by
Kitamura Laboratory
音源分離 ~DNN音源分離の基礎から最新技術まで~ Tokyo bishbash #3
by
Naoya Takahashi
独立低ランク行列分析に基づく音源分離とその発展
by
Kitamura Laboratory
半教師あり非負値行列因子分解における音源分離性能向上のための効果的な基底学習法
by
Daichi Kitamura
What's hot
PDF
Kameoka2017 ieice03
by
kame_hirokazu
PDF
異常音検知に対する深層学習適用事例
by
NU_I_TODALAB
PDF
環境音の特徴を活用した音響イベント検出・シーン分類
by
Keisuke Imoto
PPTX
音響メディア信号処理における独立成分分析の発展と応用, History of independent component analysis for sou...
by
Daichi Kitamura
PPTX
独立低ランク行列分析に基づくブラインド音源分離(Blind source separation based on independent low-rank...
by
Daichi Kitamura
PPTX
非負値行列因子分解に基づくブラインド及び教師あり音楽音源分離の効果的最適化法
by
Daichi Kitamura
PDF
音情報処理における特徴表現
by
NU_I_TODALAB
PDF
深層学習と音響信号処理
by
Yuma Koizumi
PDF
WaveNetが音声合成研究に与える影響
by
NU_I_TODALAB
PDF
深層学習を利用した音声強調
by
Yuma Koizumi
PPTX
非負値行列分解の確率的生成モデルと 多チャネル音源分離への応用 (Generative model in nonnegative matrix facto...
by
Daichi Kitamura
PPTX
スペクトログラム無矛盾性に基づく独立低ランク行列分析
by
Kitamura Laboratory
PPTX
音楽信号処理における基本周波数推定を応用した心拍信号解析
by
Kitamura Laboratory
PDF
Attentionの基礎からTransformerの入門まで
by
AGIRobots
PDF
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
by
Deep Learning JP
PDF
信号の独立性に基づく多チャンネル音源分離
by
NU_I_TODALAB
PDF
時系列問題に対するCNNの有用性検証
by
Masaharu Kinoshita
PDF
音楽を見る:情報可視化技術の音楽情報処理への適用
by
Takayuki Itoh
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
統計的手法に基づく異常音検知の理論と応用
by
Yuma Koizumi
Kameoka2017 ieice03
by
kame_hirokazu
異常音検知に対する深層学習適用事例
by
NU_I_TODALAB
環境音の特徴を活用した音響イベント検出・シーン分類
by
Keisuke Imoto
音響メディア信号処理における独立成分分析の発展と応用, History of independent component analysis for sou...
by
Daichi Kitamura
独立低ランク行列分析に基づくブラインド音源分離(Blind source separation based on independent low-rank...
by
Daichi Kitamura
非負値行列因子分解に基づくブラインド及び教師あり音楽音源分離の効果的最適化法
by
Daichi Kitamura
音情報処理における特徴表現
by
NU_I_TODALAB
深層学習と音響信号処理
by
Yuma Koizumi
WaveNetが音声合成研究に与える影響
by
NU_I_TODALAB
深層学習を利用した音声強調
by
Yuma Koizumi
非負値行列分解の確率的生成モデルと 多チャネル音源分離への応用 (Generative model in nonnegative matrix facto...
by
Daichi Kitamura
スペクトログラム無矛盾性に基づく独立低ランク行列分析
by
Kitamura Laboratory
音楽信号処理における基本周波数推定を応用した心拍信号解析
by
Kitamura Laboratory
Attentionの基礎からTransformerの入門まで
by
AGIRobots
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
by
Deep Learning JP
信号の独立性に基づく多チャンネル音源分離
by
NU_I_TODALAB
時系列問題に対するCNNの有用性検証
by
Masaharu Kinoshita
音楽を見る:情報可視化技術の音楽情報処理への適用
by
Takayuki Itoh
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
統計的手法に基づく異常音検知の理論と応用
by
Yuma Koizumi
Similar to 調波打撃音分離の時間周波数マスクを用いた線形ブラインド音源分離
PPTX
時間微分スペクトログラムに基づくブラインド音源分離
by
Kitamura Laboratory
PDF
Asj2017 3invited
by
SaruwatariLabUTokyo
PPTX
独立低ランク行列分析に基づく音源分離とその発展(Audio source separation based on independent low-rank...
by
Daichi Kitamura
PPTX
ILRMA 20170227 danwakai
by
SaruwatariLabUTokyo
PPTX
深層パーミュテーション解決法の基礎的検討
by
Kitamura Laboratory
PPTX
非負値行列因子分解を用いた被り音の抑圧
by
Kitamura Laboratory
PDF
近接分離最適化によるブラインド⾳源分離(Blind source separation via proximal splitting algorithm)
by
Daichi Kitamura
PDF
Kameoka2016 miru08
by
kame_hirokazu
PPTX
深層学習に基づく周波数帯域補間手法による音源分離処理の高速化
by
Kitamura Laboratory
PPTX
周波数双方向再帰に基づく深層パーミュテーション解決法
by
Kitamura Laboratory
PPTX
Study on optimal divergence for superresolution-based supervised nonnegative ...
by
Daichi Kitamura
PPTX
統計的独立性と低ランク行列分解理論に基づく ブラインド音源分離 –独立低ランク行列分析– Blind source separation based on...
by
Daichi Kitamura
PPTX
独立深層学習行列分析に基づく多チャネル音源分離の実験的評価(Experimental evaluation of multichannel audio s...
by
Daichi Kitamura
PPTX
深層学習に基づく間引きインジケータ付き周波数帯域補間手法による音源分離処理の高速化
by
Kitamura Laboratory
PPTX
Music signal separation using supervised nonnegative matrix factorization wit...
by
Daichi Kitamura
PDF
招待講演(鶴岡)
by
nozomuhamada
PPTX
ランク1空間近似を用いたBSSにおける音源及び空間モデルの考察 Study on Source and Spatial Models for BSS wi...
by
Daichi Kitamura
PDF
直交化及び距離最大化則条件を用いた教師あり非負値行列因子分解による音楽信号分離
by
奈良先端大 情報科学研究科
時間微分スペクトログラムに基づくブラインド音源分離
by
Kitamura Laboratory
Asj2017 3invited
by
SaruwatariLabUTokyo
独立低ランク行列分析に基づく音源分離とその発展(Audio source separation based on independent low-rank...
by
Daichi Kitamura
ILRMA 20170227 danwakai
by
SaruwatariLabUTokyo
深層パーミュテーション解決法の基礎的検討
by
Kitamura Laboratory
非負値行列因子分解を用いた被り音の抑圧
by
Kitamura Laboratory
近接分離最適化によるブラインド⾳源分離(Blind source separation via proximal splitting algorithm)
by
Daichi Kitamura
Kameoka2016 miru08
by
kame_hirokazu
深層学習に基づく周波数帯域補間手法による音源分離処理の高速化
by
Kitamura Laboratory
周波数双方向再帰に基づく深層パーミュテーション解決法
by
Kitamura Laboratory
Study on optimal divergence for superresolution-based supervised nonnegative ...
by
Daichi Kitamura
統計的独立性と低ランク行列分解理論に基づく ブラインド音源分離 –独立低ランク行列分析– Blind source separation based on...
by
Daichi Kitamura
独立深層学習行列分析に基づく多チャネル音源分離の実験的評価(Experimental evaluation of multichannel audio s...
by
Daichi Kitamura
深層学習に基づく間引きインジケータ付き周波数帯域補間手法による音源分離処理の高速化
by
Kitamura Laboratory
Music signal separation using supervised nonnegative matrix factorization wit...
by
Daichi Kitamura
招待講演(鶴岡)
by
nozomuhamada
ランク1空間近似を用いたBSSにおける音源及び空間モデルの考察 Study on Source and Spatial Models for BSS wi...
by
Daichi Kitamura
直交化及び距離最大化則条件を用いた教師あり非負値行列因子分解による音楽信号分離
by
奈良先端大 情報科学研究科
More from Kitamura Laboratory
PPTX
付け爪センサによる生体信号を用いた深層学習に基づく心拍推定
by
Kitamura Laboratory
PPTX
STEM教育を目的とした動画像処理による二重振り子の軌跡推定
by
Kitamura Laboratory
PPTX
ギタータブ譜からのギターリフ抽出アルゴリズム
by
Kitamura Laboratory
PPTX
Amplitude spectrogram prediction from mel-frequency cepstrum coefficients and...
by
Kitamura Laboratory
PPTX
Heart rate estimation of car driver using radar sensors and blind source sepa...
by
Kitamura Laboratory
PPTX
DNN-based frequency-domain permutation solver for multichannel audio source s...
by
Kitamura Laboratory
PDF
双方向LSTMによるラウドネス及びMFCCからの振幅スペクトログラム予測と評価
by
Kitamura Laboratory
PPTX
深層ニューラルネットワークに基づくパーミュテーション解決法の基礎的検討
by
Kitamura Laboratory
PPTX
多重解像度時間周波数表現に基づく独立低ランク行列分析,
by
Kitamura Laboratory
PPTX
深層学習に基づく音響特徴量からの振幅スペクトログラム予測
by
Kitamura Laboratory
PPTX
コサイン類似度罰則条件付き非負値行列因子分解に基づく音楽音源分離
by
Kitamura Laboratory
PPTX
Linear multichannel blind source separation based on time-frequency mask obta...
by
Kitamura Laboratory
PPTX
Prior distribution design for music bleeding-sound reduction based on nonnega...
by
Kitamura Laboratory
PPTX
Blind audio source separation based on time-frequency structure models
by
Kitamura Laboratory
PPTX
独立成分分析に基づく信号源分離精度の予測
by
Kitamura Laboratory
PDF
独立低ランク行列分析を用いたインタラクティブ音源分離システム
by
Kitamura Laboratory
PPTX
局所時間周波数構造に基づく深層パーミュテーション解決法の実験的評価
by
Kitamura Laboratory
PPTX
基底共有型非負値行列因子分解に基づく楽器音の共通・固有成分の分析と音色変換への応用
by
Kitamura Laboratory
PPTX
コサイン類似度罰則条件付き半教師あり非負値行列因子分解と音源分離への応用
by
Kitamura Laboratory
PDF
ユーザーからの補助情報を用いるインタラクティブ音源分離システムの開発
by
Kitamura Laboratory
付け爪センサによる生体信号を用いた深層学習に基づく心拍推定
by
Kitamura Laboratory
STEM教育を目的とした動画像処理による二重振り子の軌跡推定
by
Kitamura Laboratory
ギタータブ譜からのギターリフ抽出アルゴリズム
by
Kitamura Laboratory
Amplitude spectrogram prediction from mel-frequency cepstrum coefficients and...
by
Kitamura Laboratory
Heart rate estimation of car driver using radar sensors and blind source sepa...
by
Kitamura Laboratory
DNN-based frequency-domain permutation solver for multichannel audio source s...
by
Kitamura Laboratory
双方向LSTMによるラウドネス及びMFCCからの振幅スペクトログラム予測と評価
by
Kitamura Laboratory
深層ニューラルネットワークに基づくパーミュテーション解決法の基礎的検討
by
Kitamura Laboratory
多重解像度時間周波数表現に基づく独立低ランク行列分析,
by
Kitamura Laboratory
深層学習に基づく音響特徴量からの振幅スペクトログラム予測
by
Kitamura Laboratory
コサイン類似度罰則条件付き非負値行列因子分解に基づく音楽音源分離
by
Kitamura Laboratory
Linear multichannel blind source separation based on time-frequency mask obta...
by
Kitamura Laboratory
Prior distribution design for music bleeding-sound reduction based on nonnega...
by
Kitamura Laboratory
Blind audio source separation based on time-frequency structure models
by
Kitamura Laboratory
独立成分分析に基づく信号源分離精度の予測
by
Kitamura Laboratory
独立低ランク行列分析を用いたインタラクティブ音源分離システム
by
Kitamura Laboratory
局所時間周波数構造に基づく深層パーミュテーション解決法の実験的評価
by
Kitamura Laboratory
基底共有型非負値行列因子分解に基づく楽器音の共通・固有成分の分析と音色変換への応用
by
Kitamura Laboratory
コサイン類似度罰則条件付き半教師あり非負値行列因子分解と音源分離への応用
by
Kitamura Laboratory
ユーザーからの補助情報を用いるインタラクティブ音源分離システムの開発
by
Kitamura Laboratory
調波打撃音分離の時間周波数マスクを用いた線形ブラインド音源分離
1.
調波打撃音分離の時間周波数マスクを用いた 線形ブラインド音源分離 Linear blind source
separation using time-frequency mask obtained by harmonic/percussive source separation 香川高等専門学校 電気情報工学科 北村研究室 5年 大藪 宗一郎 香川高専電気情報工学科 卒業研究発表会
2.
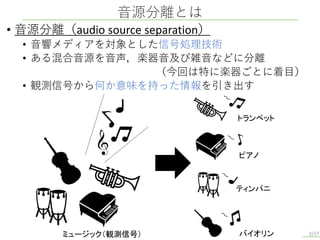
音源分離とは • 音源分離(audio source
separation) • 音響メディアを対象とした信号処理技術 • ある混合音源を音声,楽器音及び雑音などに分離 (今回は特に楽器ごとに着目) • 観測信号から何か意味を持った情報を引き出す トランペット バイオリン ピアノ ティンパニ ミュージック(観測信号) 2/17
3.
低音質 高音質 • ブラインド音源分離 (blind
source separation: BSS) 混合系 が未知の条件で分離系 を推定 • 多チャネルBSS • 観測信号が複数(マイクが複数) • 空間に対する情報が十分存在するため音質が良い • 単一チャネルBSS • 対象の観測信号が単一(マイクが単一) • 空間に対する情報がないため音質が悪い ブラインド音源分離 3/17 BSS 混合系 分離系 Ex. 独立ベクトル分析 (IVA) [T. Kim et al, 2007] 独立低ランク行列分析 (ILRMA) [D. Kitamura et al., 2018] 時間周波数マスクに基づくBSS (TFMBSS) [K. Yatabe and D. Kitamura, 2019] Ex. 調波打撃音分離 (HPSS) [N. Ono et al., 2008]
4.
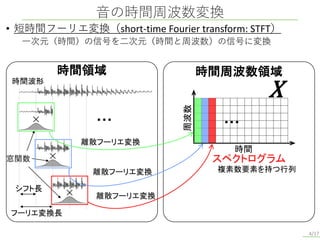
音の時間周波数変換 4/17 時間領域 窓関数 フーリエ変換長 シフト長 時間周波数領域 時間波形 … 離散フーリエ変換 離散フーリエ変換 離散フーリエ変換 スペクトログラム 複素数要素を持つ行列 周波数 時間 … X • 短時間フーリエ変換(short-time Fourier
transform: STFT) 一次元(時間)の信号を二次元(時間と周波数)の信号に変換
5.
• 音源モデルとは • 混合前の各音源の時間周波数構造 •
独立ベクトル分析 (IVA) • 同じ音源の周波数成分は 同じ時間に生起することを仮定 • 独立低ランク行列分析 (ILRMA) • 低ランク時間周波数構造を仮定 (同じスペクトルの繰り返しが多い) • 調波打撃音分離 (HPSS) • 時間方向に連続な音源 と周波数方向に連続な音源を仮定 • 様々な音源モデルに対応可能なフレームワーク • 時間周波数マスクに基づくBSS (TFMBSS) [K. Yatabe and D. Kitamura, 2019] • 時間周波数マスクで表現される音源モデルを仮定 多チャネルBSSにおける音源モデル 5/17 周波数 時間 周波数 時間 周波数 時間
6.
時間周波数マスクの生成 6/17 • 時間周波数マスクの推定問題 単一チャネル観測信号に対する音源分離 非目的音源を時間周波数領域でマスキングする非線形処理 時間周波数マスク(binary or
soft)の推定 時間 [s] 周波数 [Hz] 赤、青の音源から成る混合信号から 赤の音源のみを取り出したい…. 赤の音源の部分を”1” それ以外を”0” とするようなマスクを掛け合わせる
7.
• 調波打撃音分離 (HPSS)
[N. Ono et al., 2008] スペクトログラムの周波数,時間方向の滑らかさに着目して分離する手法 • HPSSはモノラルの音源分離手法 • HPSSの分離モデルに沿って強力に分離 • 分離のみは強力だが歪みが大きくとても非線形 モノラル音源分離の従来法 7/17 調波音信号 混合信号 調波楽器 打楽器 調波成分 打撃成分 時間 周波数 打撃音信号
8.
• 時間周波数マスクに基づくBSS (TFMBSS)
[K. Yatabe and D. Kitamura, 2019] • 音源モデルは時間周波数マスクで表現が可能 • この時間周波数マスクをplug-and-playで活用 • TFMBSSのモノラルBSSへの適用 • モノラルのHPSSからマスクを作成しTFMBSSに導入 • これを反復的に更新 • HPSSによる調波打撃音分離+TFMBSSの線形な分離 TFMBSSの概要 8/17 Mask 線形な分離信号 TFMBSS IVA ILRMA FDICA HPSS Mask 非線形な分離信号 線形な分離信号 TFMBSS Iteration
9.
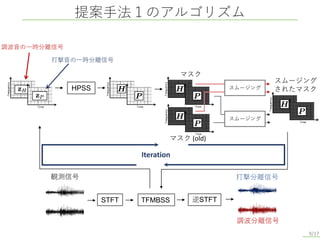
提案手法1のアルゴリズム 9/17 調波分離信号 打撃分離信号 逆STFT STFT TFMBSS 観測信号 HPSS スムージング されたマスク スムージング マスク スムージング Iteration 調波音の一時分離信号 打撃音の一時分離信号 マスク (old)
10.
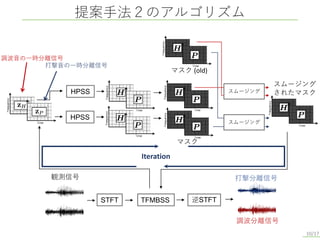
提案手法2のアルゴリズム 10/17 HPSS 調波分離信号 打撃分離信号 逆STFT STFT TFMBSS 観測信号 スムージング されたマスク スムージング スムージング マスク (old) HPSS マスク Iteration 調波音の一時分離信号 打撃音の一時分離信号
11.
• TFMBSSの反復更新における不安定要素 • 時間周波数マスクが反復ごとに大きく変動 •
マスクの変動は安定した音源分離の阻害を招く • スムージング処理 • スムージングパラメータはスムージング度合いを決定 • この操作を毎反復時,マスク生成後に適用 • 適用後,現在のマスクに代入 • TFMBSSの最適化の安定を図る 時間周波数マスクのスムージング 11/17 現在のマスク 一反復前のマスク スムージングパラメータ 要素ごとの積
12.
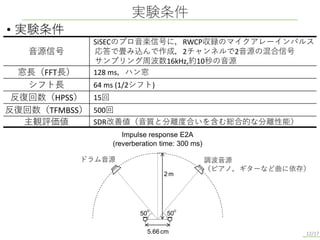
実験条件 12/17 • 実験条件 音源信号 SiSECのプロ音楽信号に,RWCP収録のマイクアレーインパルス 応答で畳み込んで作成,2チャンネルで2音源の混合信号 サンプリング周波数16kHz,約10秒の音源 窓長(FFT長) 128
ms,ハン窓 シフト長 64 ms (1/2シフト) 反復回数(HPSS) 15回 反復回数(TFMBSS) 500回 主観評価値 SDR改善値(音質と分離度合いを含む総合的な分離性能) 2 m 5.66cm 50 50 調波音源 (ピアノ,ギターなど曲に依存) Impulse response E2A (reverberation time: 300 ms) ドラム音源
13.
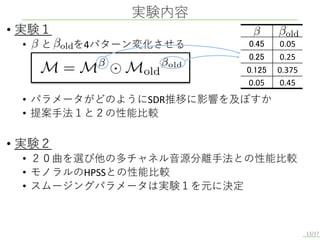
• 実験1 • と
を4パターン変化させる • パラメータがどのようにSDR推移に影響を及ぼすか • 提案手法1と2の性能比較 • 実験2 • 20曲を選び他の多チャネル音源分離手法との性能比較 • モノラルのHPSSとの性能比較 • スムージングパラメータは実験1を元に決定 実験内容 13/17 0.45 0.05 0.25 0.25 0.125 0.375 0.05 0.45
14.
-3 -1 1 3 5 7 9 11 0 100 200
300 400 SDR improvement [dB] Number of iterations in BSS [times] β = 0.45/βold = 0.05 β = 0.25/βold = 0.25 β = 0.125/βold = 0.375 β = 0.05/βold = 0.45 実験1における実験結果(手法1) 14/17 • パラメータ調整による提案手法1の反復毎のSDR改善量 変化小 変化大
15.
-4 -2 0 2 4 6 8 10 12 14 0 100 200
300 400 SDR improvement [dB] Number of iterations in BSS [times] β = 0.45/βold = 0.05 β = 0.25/βold = 0.25 β = 0.125/βold = 0.375 β = 0.05/βold = 0.45 実験1における実験結果(手法2) 15/17 • パラメータ調整による提案手法2の反復毎のSDR改善量 変化小 変化大
16.
• 全20曲におけるSDR改善量の平均値 • 結果 •
2種類の提案手法共に従来のHPSSより性能が向上 • 平均的に提案手法1より提案手法2方が性能が良い • 提案手法2では実験データ20曲において最も性能が良い 実験2における実験結果 16/17 Method Average SDR [dB] HPSS 4.68 IVA 7.09 ILRMA 8.56 HPSS + TFMBSS(提案手法1) 7.44 HPSS + TFMBSS(提案手法2) 11.00
17.
• 本研究の背景 • 音源モデル比較の必要性 •
従来は多チャネルBSSにTFMBSSを適用 • 本研究における新規性 • 従来のモノラル音源分離手法を多チャネル化 TFMBSS + HPSS HPSSの調波打撃音分離を活かしながら線形分離 マスクを反復更新 • マスクのスムージングによる最適化の安定 • 実験結果 • スムージングによるSDR改善量の推移の安定を確認 • 2種類の提案手法共に従来のHPSSより性能が向上 • 研究業績 まとめ 17/17 大藪宗一郎, 北村大地, 矢田部浩平, "調波打撃音分離の時間周波数マスクを用いた線形ブラインド音源分離, "日本音響学会 2020年春季研究発表会講演論文集", 3-1-16, pp. ???–???, 埼玉, 2020年3月(査読無).
Editor's Notes
#2
このタイトルで発表させていただきます. 北村研究室 大藪宗一郎です.よろしくお願いします.
#3
今日,音声をインプットとしたような機器の普及などに伴い音源分離技術のニーズは高まっています. 音源分離とは,音響メディアを対象とした信号処理技術であり,混合音源を音声,楽器音及び雑音などに分離する技術です. 次に,音源分離の中でも研究が盛んであるブラインド音源分離について解説します.
#4
ブラインド音源分離とはマイクや音源の位置などの事前情報が未知という状態から分離系Wを推定するという音源分離手法です. 特に,BSSの中でも観測信号が複数である場合を多チャネルBSS,単一である場合を単一チャネルBSSと言います. 多チャネルBSSにはIVA,ILRMA,TFMBSSなどが挙げられます. 単一チャネルBSSにはHPSSなどが挙げられます. 多チャネルでは分離フィルタの推定において十分に情報が存在するため,高音質であるのに対し,単一チャネルでは情報が少ないため低音質です.
#5
そして,音源分離という信号処理分野においての一般的な変換について解説します. 観測した時間信号から任意のフーリエ変換長分,離散フーリエ変換し一本のベクトルを生成します.(クリック)そしてもう一本(クリック)もう一本(クリック)というように 時間軸上に並べることで複素数要素を持った時間周波数表現であるスペクトログラムが生成されます.音源分離においては,このスペクトログラムを信号処理の対象とするのが一般的です.
#6
今日に至るまで様々な音源モデルに基づくBSSが提案されてきました. 音源モデルというのは混合前の音源の時間周波数構造に関する仮定です. 例えばILRMAであれば,低ランク時間周波数構造を仮定 というように各手法それぞれに仮定する音源モデルが存在します. 将来的な,より良い音源モデルの探求において,音源モデルの比較はとても重要であるといえます. このことから,様々な音源モデルを統一的に扱えるフレームワークとして 時間周波数マスクで表現される音源モデルを仮定した,時間周波数マスクに基づくBSS TFMBSSが提案されています.
#7
ここで,時間周波数マスクについても解説させていただきます. 時間周波数マスクの生成は,単一チャネル観測信号に対する音源分離です. 図のように赤青の混合信号から赤の音源のみを取り出したい時,赤の音源の部分を1,それ以外を0というようなマスクを作成します.(クリック) これを要素ごとに適用することで赤の音源のみを取り出すと言う処理です. しかしながら,時間周波数マスキングは非線形処理であるため,局所的な誤差の発生により分離音源に人工歪みが発生するため音質は高いとは言えません.
#8
次にモノラルの音源分離手法の一例として,HPSSを解説をさせていただきます. このスペクトログラム上で縦線が打撃成分(クリック),横線が調波成分であり(クリック), これらを検出するために,打撃成分であれば周波数方向の,調波成分であれば時間方向の滑らかさを見て調波音信号,打撃音信号に分離する手法です. HPSSは分離モデルに沿って強力に分離しますがモノラルBSSということもあってとても非線形で音質が悪いです.
#9
次に,TFMBSSについて解説します. TFMBBSは時間周波数マスクで表現された音源モデルが存在すればplug-and-playで活用が可能なフレームワークです. 今日に至るまで多チャネルBSSにTFMBSSを適用してきたという背景があり,本研究では,新たにモノラルBSSへTFMBSSを適用することを提案します. これより線形な分離とHPSSによる長波打撃音分離の両立を実現することを目的としています. 次にHPSSとTFMBSSを用いた2種類のアルゴリズムを提案し,ブロック図で解説します.
#10
一つ目はHPSSの動作を忠実に踏襲したアルゴリズムです. まず観測信号を(クリック)STFTして,(クリック)その後TFMBSSに取り込まれます. (クリック)その後調波成分に対する中間変数zH,打撃成分に対するzPを隔てて,(クリック)HPSSに取り込まれ(クリック)調波成分と打撃成分に分離されます. (クリック)そこからマスクを生成し,(クリック)2反復目以降では過去のマスクとスムージングを施し,(クリック)新しくマスクを得ます.スムージング操作については後述します. (クリック)これをTFMBSSに返すという動作を任意の反復回数繰り返した後,(クリック)逆STFTで時間信号に変換し(クリック)線形な打撃成分,調波成分の音源得ます.
#11
二つ目はHPSSをフィルタと捉えた排他的アルゴリズムになっています. (クリック)まず提案手法1と同様の動作でzH,zPを隔てて,(クリック)2つの別のHPSSに取り込まれ(クリック)調波成分と打撃成分に分離されます. (クリック)そこからマスクを二組生成し,(クリック)このうちzHに対応したHPSSから生成されたマスクではPのマスクを破棄,もう片方のマスクでは逆にHのマスクを破棄します. この操作によって,zHに対応したHPSSから生成されたマスクからは調波成分ではないものが除去され,もう一方では,打撃成分でないものが除去されます. (クリック)そして同様に過去のマスクとスムージングを施し,(クリック)新しくマスクを得ます.(クリック)そして同じように分離音源を得ます.
#12
前述のブロック図にて登場したスムージングについて解説します. TFMBSSは反復的に最適化を行いますが,一反復ごとにマスクを更新する際,マスクが大きく変動すると安定した音源分離がされない場合があります. この問題に対してマスクのスムージングを行うことで解決できるのでは?と考えました. スムージング処理はこの式で行われます.βとβoldはマスクのスムージング度合いを決定するもので,このパラメータをもとに反復毎にスムージングを行いTFMBSSの最適化の安定を図ります. 次に,本研究の有用性を示すために行った二つの実験の結果を示します.
#13
まず実験条件として,実験対象は,下のような状況で録音された混合音源です. TFMBSSにおける反復回数は500回で,その一回の反復でHPSSが15回反復更新しています. 主観評価指標としてSDR改善量を用います.
#14
一つ目の実験では,マスクのスムージングの有用性を確認します. βとβoldを表のような4パターンで変化させ,このパラメータが反復毎のSDRの推移にどのような影響を与えるか,そして提案手法1と2の性能比較を行います. 二つ目の実験では,前述の音楽信号から20曲を選び従来の多チャネルBSS及び従来のモノラルHPSSと比較します. この時のβとβoldのパラメータ設定は実験1を基に決定します.
#15
実験1における提案手法1の反復毎のSDR改善量の推移を示しています.縦軸がSDR改善量で,横軸はBSSの反復回数を示しています. 灰色,藍色,赤色,黄色の順番で灰色線が最も反復間のマスクの変化が大きく黄色線が最もマスクの変化が小さいです. 灰色線,藍色線では反復間のマスクの変化が大きすぎて推移が安定していません.対して,黄色線では推移は安定しているが収束速度と収束点が劣っています. この4パターンでは,赤色線がトレードオフを考慮した最適パラメータといえます.
#16
次に,実験1における提案手法2の反復毎のSDR改善量の推移を示しています. パラメータに関する推移の変動は提案手法1と同様ですが, 全体的に安定性が低いです.しかし,最終的な収束スコアは高いと言えます.
#17
20曲の最終的なSDR改善量の平均値の表を示します. 最終的な結果として,2種類の提案手法共に従来のHPSSより性能が向上したこと, 全体的に提案手法2のほうが提案手法1よりも性能が良く他の多チャネルBSSよりも性能が良いことが観測されました.
#18
最後に総括としまして, まず,音源分離技術のニーズの高まりに応えるためのより良い音源モデルの探求には, 音源モデルの比較が必要であり,そのためにTFMBSSが提案され,従来は多チャネルのBSSに適用してきたという背景があります. そして,本研究の新規性として, モノラルの音源分離手法にTFMBSSを適用することで多チャネル化すること 及び,スムージングによる最適化の安定を提案しました. 実験1ではスムージングによるSDRの推移の安定化を観測し,パラメータ設定においては収束速度・収束値と安定性のトレードオフを設定する必要があるという結果が得られました. 実験2ではTFMBSSのよる線形分離によって従来のHPSSと比較して提案手法のSDR値の明確な上昇を観測しました. これで発表を終わります.
#19
次に,実験2における代表3曲の最終的なSDR改善量を示しています.縦軸が曲番号で,横軸はSDR改善量になっています. 有彩色のものが提案手法で,無彩色ものが従来法です. Song no.2と14では,モノラルのHPSSの得手不得手に応じて提案手法のSDRが増幅されたような結果になっています. Song no.9では,提案手法1ではモノラルのHPSSの得手不得手に従っていますが,提案手法2ではモノラルのHPSSのSDR改善量が低くても高いスコアを出しています.
#20
次に,実験2における11曲目から20曲目のSDR改善量を示しています. (クリック)同じく青枠の結果ではモノラルのHPSSの得手不得手に応じています. (クリック)緑枠でも,同じく提案手法2のみモノラルのHPSSのSDR改善量が低くても高いスコアを出しています.(クリック)黄枠でも,同じくモノラルのHPSSのスコアに対して提案手法のスコアの伸びが良くないという結果でした.
#21
マイクの数による分類として主に3つに分けられます. マイク数が1つの場合をモノラル信号の音源分離, マイクが複数存在するが分離したい音源数よりマイクの数が少ない場合を劣決定条件の音源分離, マイクが複数で分離したい音源よりマイクの数が多い場合を優決定条件の音源分離と言います. マイク数が多いということは情報が多い,と言えるので分離音源は高音質でマイクの数が少なくなるほど低音質になります.HPSSはモノラル信号の音源分離にあたり,ILRMAやIVAは優決定条件の音源分離にあたります.
#22
ここで,改めて動機の提示をします. まず,HPSSは単チャネルBSSで音質が優れないという現状があります. これを解決するためモノラルのHPSSから生成した非線形な分離信号を基にマスクを作成しTFMBSSに取り込みます. これより線形な分離とHPSSによる長波打撃音分離の両立を実現することを目的としています. 本発表では,HPSSとTFMBSSを組み合わせた2つのアルゴリズムを解説します.
#23
本研究の俯瞰図です. 現在に至るまでILRMAなどの多チャネルBSSに対してTFMBSSを適応してきたという経緯があります. それを単チャネルBSSであるHPSSに適用することで(クリック)HPSSの分離特性を活かしつつ多チャネルの線形分離を実現したい.というのが本研究の目的です.
#24
次に,TFMBBSは時間周波数マスクで表現された音源モデルが存在すればplug-and-playで活用が可能なフレームワークです. 要するに時間周波数マスクがあればどんな音源モデルのBSSでも最適化を行うことが可能と言えます. その実態は近接作用素という,端的に言えば射影と最小化を同時に行うような関数を用いた最適化アルゴリズムであり, この最適化アルゴリズムの一部を時間周波数マスクキングで置き換えたものがTFMBSSです.
#26
提案手法に移る前に従来法の解説をさせていただきます. HPSSとはスペクトログラムの周波数,時間方向の滑らかさに着目して分離する手法で,この目的関数を最小化することで分離を行う最適化問題です. このスペクトログラム上で縦線が打撃成分(クリック),横線が調波成分であり(クリック), これらを検出するために打撃成分であれば周波数方向の,調波成分であれば時間方向の滑らかさを見て(クリック)ハーモニックマトリックスパーッカッシブマトリックスに分離します.
#27
提案手法に移る前に従来法の解説をさせていただきます. HPSSとはスペクトログラムの周波数,時間方向の滑らかさに着目して分離する手法で,この目的関数を最小化することで分離を行う最適化問題です. このスペクトログラム上で縦線が打撃成分(クリック),横線が調波成分であり(クリック), これらを検出するために打撃成分であれば周波数方向の,調波成分であれば時間方向の滑らかさを見て(クリック)ハーモニックマトリックスパーッカッシブマトリックスに分離します.
Download

![低音質
高音質
• ブラインド音源分離 (blind source separation: BSS)
混合系 が未知の条件で分離系 を推定
• 多チャネルBSS
• 観測信号が複数(マイクが複数)
• 空間に対する情報が十分存在するため音質が良い
• 単一チャネルBSS
• 対象の観測信号が単一(マイクが単一)
• 空間に対する情報がないため音質が悪い
ブラインド音源分離
3/17
BSS
混合系 分離系
Ex. 独立ベクトル分析 (IVA) [T. Kim et al, 2007]
独立低ランク行列分析 (ILRMA) [D. Kitamura et al., 2018]
時間周波数マスクに基づくBSS (TFMBSS) [K. Yatabe and D. Kitamura, 2019]
Ex. 調波打撃音分離 (HPSS) [N. Ono et al., 2008]](https://image.slidesharecdn.com/20190305-210827053739/85/slide-3-320.jpg)
![• 音源モデルとは
• 混合前の各音源の時間周波数構造
• 独立ベクトル分析 (IVA)
• 同じ音源の周波数成分は
同じ時間に生起することを仮定
• 独立低ランク行列分析 (ILRMA)
• 低ランク時間周波数構造を仮定
(同じスペクトルの繰り返しが多い)
• 調波打撃音分離 (HPSS)
• 時間方向に連続な音源
と周波数方向に連続な音源を仮定
• 様々な音源モデルに対応可能なフレームワーク
• 時間周波数マスクに基づくBSS (TFMBSS) [K. Yatabe and D. Kitamura, 2019]
• 時間周波数マスクで表現される音源モデルを仮定
多チャネルBSSにおける音源モデル
5/17
周波数
時間
周波数
時間
周波数
時間](https://image.slidesharecdn.com/20190305-210827053739/85/slide-5-320.jpg)
![時間周波数マスクの生成
6/17
• 時間周波数マスクの推定問題
単一チャネル観測信号に対する音源分離
非目的音源を時間周波数領域でマスキングする非線形処理
時間周波数マスク(binary or soft)の推定
時間 [s]
周波数
[Hz]
赤、青の音源から成る混合信号から
赤の音源のみを取り出したい….
赤の音源の部分を”1”
それ以外を”0”
とするようなマスクを掛け合わせる](https://image.slidesharecdn.com/20190305-210827053739/85/slide-6-320.jpg)
![• 調波打撃音分離 (HPSS) [N. Ono et al., 2008]
スペクトログラムの周波数,時間方向の滑らかさに着目して分離する手法
• HPSSはモノラルの音源分離手法
• HPSSの分離モデルに沿って強力に分離
• 分離のみは強力だが歪みが大きくとても非線形
モノラル音源分離の従来法
7/17
調波音信号
混合信号
調波楽器
打楽器
調波成分
打撃成分
時間
周波数
打撃音信号](https://image.slidesharecdn.com/20190305-210827053739/85/slide-7-320.jpg)
![• 時間周波数マスクに基づくBSS (TFMBSS) [K. Yatabe and D. Kitamura, 2019]
• 音源モデルは時間周波数マスクで表現が可能
• この時間周波数マスクをplug-and-playで活用
• TFMBSSのモノラルBSSへの適用
• モノラルのHPSSからマスクを作成しTFMBSSに導入
• これを反復的に更新
• HPSSによる調波打撃音分離+TFMBSSの線形な分離
TFMBSSの概要
8/17
Mask
線形な分離信号
TFMBSS
IVA
ILRMA
FDICA
HPSS
Mask
非線形な分離信号 線形な分離信号
TFMBSS
Iteration](https://image.slidesharecdn.com/20190305-210827053739/85/slide-8-320.jpg)

![-3
-1
1
3
5
7
9
11
0 100 200 300 400
SDR
improvement
[dB]
Number of iterations in BSS [times]
β = 0.45/βold = 0.05
β = 0.25/βold = 0.25
β = 0.125/βold = 0.375
β = 0.05/βold = 0.45
実験1における実験結果(手法1)
14/17
• パラメータ調整による提案手法1の反復毎のSDR改善量
変化小
変化大](https://image.slidesharecdn.com/20190305-210827053739/85/slide-14-320.jpg)
![-4
-2
0
2
4
6
8
10
12
14
0 100 200 300 400
SDR
improvement
[dB]
Number of iterations in BSS [times]
β = 0.45/βold = 0.05
β = 0.25/βold = 0.25
β = 0.125/βold = 0.375
β = 0.05/βold = 0.45
実験1における実験結果(手法2)
15/17
• パラメータ調整による提案手法2の反復毎のSDR改善量
変化小
変化大](https://image.slidesharecdn.com/20190305-210827053739/85/slide-15-320.jpg)
![• 全20曲におけるSDR改善量の平均値
• 結果
• 2種類の提案手法共に従来のHPSSより性能が向上
• 平均的に提案手法1より提案手法2方が性能が良い
• 提案手法2では実験データ20曲において最も性能が良い
実験2における実験結果
16/17
Method Average SDR [dB]
HPSS 4.68
IVA 7.09
ILRMA 8.56
HPSS + TFMBSS(提案手法1) 7.44
HPSS + TFMBSS(提案手法2) 11.00](https://image.slidesharecdn.com/20190305-210827053739/85/slide-16-320.jpg)
























![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)










































