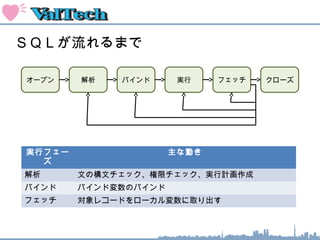
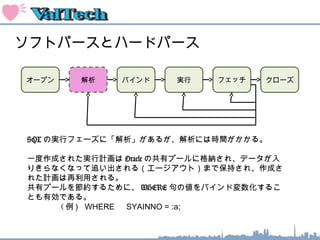
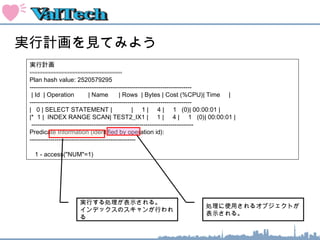
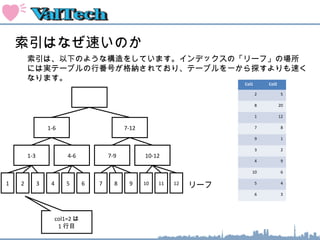
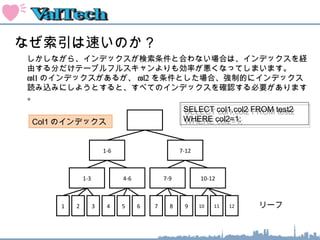
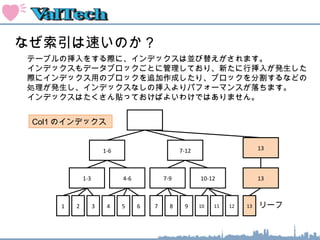
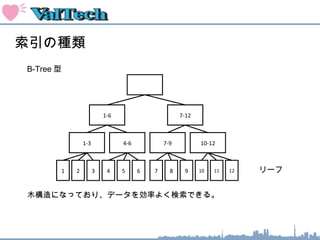
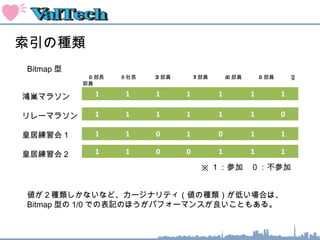
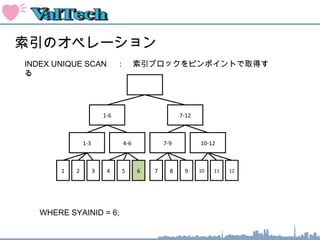
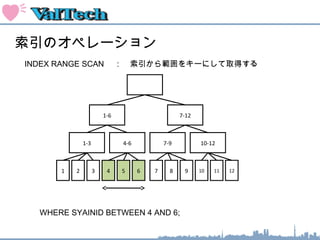
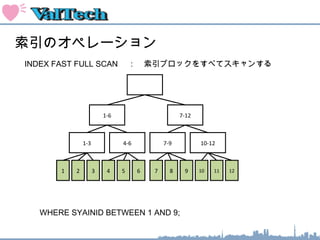
索引のオペレーション
1-6 7-12
1
INDEX FASTFULL SCAN : 索引ブロックをすべてスキャンする
1-3 4-6 7-9 10-12
2 3 4 5 6 7 8 9 10 11 12
WHERE SYAINID BETWEEN 1 AND 9;
18.
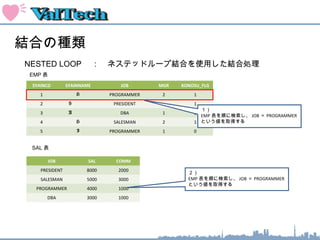
結合の種類
NESTED LOOP : ネステッドループ結合を使用した結合処理
SYAINCDSYAINNAME JOB MGR KONOSU_FLG
1 H PROGRAMMER 2 1
2 S PRESIDENT 1
3 A DBA 1 1
4 H SALESMAN 2 1
5 I PROGRAMMER 1 0
EMP 表
JOB SAL COMM
PRESIDENT 8000 2000
SALESMAN 5000 3000
PROGRAMMER 4000 1000
DBA 3000 1000
SAL 表
SELECT emp.syainname , sal.sal
FROM emp, sal
WHERE emp.job = sal.job;
SELECT emp.syainname , sal.sal
FROM emp, sal
WHERE emp.job = sal.job;
19.
結合の種類
NESTED LOOP : ネステッドループ結合を使用した結合処理
SYAINCDSYAINNAME JOB MGR KONOSU_FLG
1 H PROGRAMMER 2 1
2 S PRESIDENT 1
3 A DBA 1 1
4 H SALESMAN 2 1
5 I PROGRAMMER 1 0
EMP 表
JOB SAL COMM
PRESIDENT 8000 2000
SALESMAN 5000 3000
PROGRAMMER 4000 1000
DBA 3000 1000
SAL 表
1)
EMP 表を順に検索し、 JOB = PROGRAMMER
という値を取得する
2)
EMP 表を順に検索し、 JOB = PROGRAMMER
という値を取得する
20.
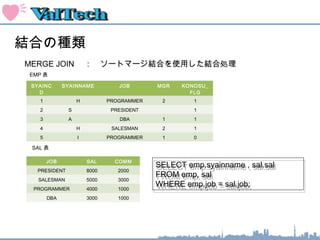
結合の種類
MERGE JOIN : ソートマージ結合を使用した結合処理
SYAINC
D
SYAINNAMEJOB MGR KONOSU_
FLG
1 H PROGRAMMER 2 1
2 S PRESIDENT 1
3 A DBA 1 1
4 H SALESMAN 2 1
5 I PROGRAMMER 1 0
EMP 表
JOB SAL COMM
PRESIDENT 8000 2000
SALESMAN 5000 3000
PROGRAMMER 4000 1000
DBA 3000 1000
SAL 表
SELECT emp.syainname , sal.sal
FROM emp, sal
WHERE emp.job = sal.job;
SELECT emp.syainname , sal.sal
FROM emp, sal
WHERE emp.job = sal.job;
21.
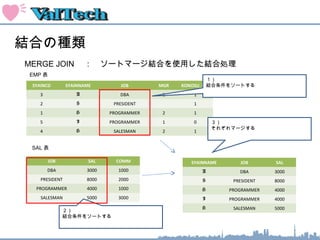
結合の種類
MERGE JOIN : ソートマージ結合を使用した結合処理
SYAINCDSYAINNAME JOB MGR KONOSU_FLG
3 A DBA 1 1
2 S PRESIDENT 1
1 H PROGRAMMER 2 1
5 I PROGRAMMER 1 0
4 H SALESMAN 2 1
EMP 表
JOB SAL COMM
DBA 3000 1000
PRESIDENT 8000 2000
PROGRAMMER 4000 1000
SALESMAN 5000 3000
SAL 表
1)
結合条件をソートする
2)
結合条件をソートする
SYAINNAME JOB SAL
A DBA 3000
S PRESIDENT 8000
H PROGRAMMER 4000
I PROGRAMMER 4000
H SALESMAN 5000
3)
それぞれマージする
22.
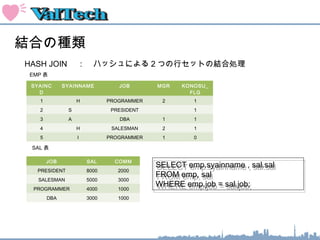
結合の種類
HASH JOIN : ハッシュによる2 つの行セットの結合処理
SYAINC
D
SYAINNAME JOB MGR KONOSU_
FLG
1 H PROGRAMMER 2 1
2 S PRESIDENT 1
3 A DBA 1 1
4 H SALESMAN 2 1
5 I PROGRAMMER 1 0
EMP 表
JOB SAL COMM
PRESIDENT 8000 2000
SALESMAN 5000 3000
PROGRAMMER 4000 1000
DBA 3000 1000
SAL 表
SELECT emp.syainname , sal.sal
FROM emp, sal
WHERE emp.job = sal.job;
SELECT emp.syainname , sal.sal
FROM emp, sal
WHERE emp.job = sal.job;
23.
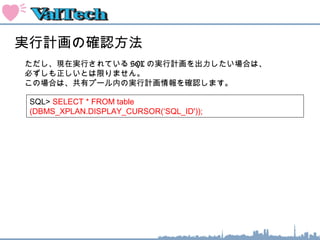
結合の種類
HASH JOIN : ハッシュによる2 つの行セットの結合処理
SYAINC
D
SYAINNAME JOB MGR KONOSU_
FLG
1 H PROGRAMMER 2 1
2 S PRESIDENT 1
3 A DBA 1 1
4 H SALESMAN 2 1
5 I PROGRAMMER 1 0
EMP 表
JOB SAL COMM
PRESIDENT 8000 2000
SALESMAN 5000 3000
PROGRAMMER 4000 1000
DBA 3000 1000
SAL 表
2 )
もう一つの表の結合条件式に
ハッシュ関数をかけて、
結合できるかをハッシュテーブルで確認
SYAINI
D
SAL
1 4000
2 8000
3 3000
4 5000
5 4000
HASH TABLE
1)
レコード数の少ない表の結合条件式を
ハッシュ関数にかけて、
メモリ上にハッシュテーブルを作成
ハッシュ関数
ハ
ッ
シ
ュ
関
数
24.
ヒント句
オペレーション( SQL を実行する際の処理方法)を固定させることが
できる。
Operationヒント句 使用例
TABLE ACCESS
FULL
FULL SELECT /*+ FULL(tab) */ * from
tab;
INDEX RANGE
SCAN
INDEX SELECT /*+ INDEX(tab idx) */ *
from tab;
INDEX UNIQUE
SCAN
INDEX FAST FULL
SCAN
NESTED LOOP USE_NL SELECT /*+ USE_NL(a b)*/ * from
a,b;
MERGE JOIN USE_MERG
E
SELECT /*+ USE_MERGE (a b)*/ *
from a,b;























![[Oracle DBA & Developer Day 2012] 高可用性システムに適した管理性と性能を向上させるASM と RMAN の魅力](https://cdn.slidesharecdn.com/ss_thumbnails/ma-4print20121205-200702094006-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Oracle DBA & Developer Day 2016] しばちょう先生の特別講義!!ストレージ管理のベストプラクティス ~ASMからExada...](https://cdn.slidesharecdn.com/ss_thumbnails/mktgdd2-3stragemanagementfordl2-200702092359-thumbnail.jpg?width=640&height=640&fit=bounds)














![おじさん二人が語る OOW デビューのススメ! Oracle OpenWorld 2016参加報告 [検閲版] 株式会社コーソル 杉本 篤信, 河野 敏彦](https://cdn.slidesharecdn.com/ss_thumbnails/20151117-jpoug-toshihiko-kouno-atsunobu-sugimoto-oow-161118160944-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db tech showcase Sapporo 2015] B15:ビッグデータ/クラウドにデータ連携自由自在 (オンプレミス ↔ クラウド ↔ クラ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtssapporo2015b15bigdatacloudinsighttechnology-150917050117-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[B31] LOGMinerってレプリケーションソフトで使われているけどどうなってる? by Toshiya Morita](https://cdn.slidesharecdn.com/ss_thumbnails/b31iti-140624235903-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





























