Download to read offline





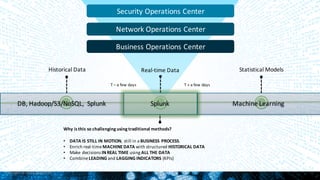


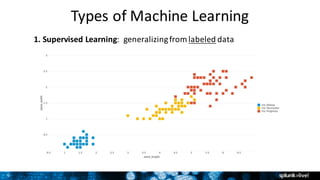

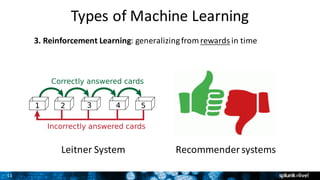






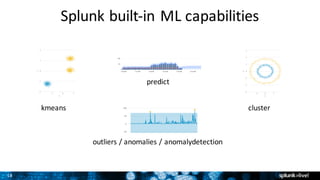







![27
3. Fit, Apply & Validate Models
• ML SPL – New grammar for doing ML in Splunk
• fit – fit models based on training data
– [training data] | fit LinearRegression costly_KPI
from feature1 feature2 feature3 into my_model
• apply – apply models on testing and production data
– [testing/production data] | apply my_model
• Validate Your Model (The Hard Part)
– Why hard? Because statistics is hard! Also: model error ≠ real world risk.
– Analyze residuals, mean-square error, goodness of fit, cross-validate, etc.
– Take Splunk’s Analytics & Data Science Education course](https://image.slidesharecdn.com/splunkliveperthmachinelearning-160804040822/85/SplunkLive-Perth-Machine-Learning-Analytics-27-320.jpg)









This document presents an overview of machine learning (ML) by Splunk, highlighting its importance for real-time data analysis and predictive maintenance across various operations, including IT, security, and business analytics. It explores different types of ML, relevant use cases, and the workflow for building and validating ML models, emphasizing the necessity of continuous refinement. Additionally, it outlines Splunk's built-in ML capabilities, available toolkits, and practical examples for implementation.





































































































