Downloaded 18 times












![Saving To Cassandra
val variants: RDD[VariantContext] = sc.adamVCFLoad(args(0))
variants.flatMap(getVariant)
.saveToCassandra("adam", "variants", AllColumns)](https://image.slidesharecdn.com/sparkcassandra-141210200741-conversion-gate01/85/Spark-Cassandra-13-320.jpg)
, 1L))
.reduceByKey(_ + _)
.map(r => (r._2, r._1))
.sortByKey(ascending = false)
rdd.collect()
.foreach(bc => println("%40st%d".format(bc._2, bc._1)))](https://image.slidesharecdn.com/sparkcassandra-141210200741-conversion-gate01/85/Spark-Cassandra-14-320.jpg)


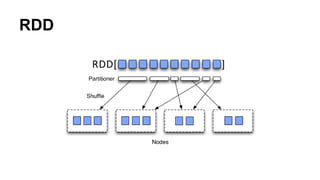
This document discusses using Spark with Cassandra. It provides an overview of Spark and its Resilient Distributed Dataset (RDD) framework. It describes using the spark-cassandra-connector to expose Cassandra tables as RDDs to read from and write to Cassandra from Spark. It also gives an example of using Spark and Cassandra for bioinformatics by integrating with the ADAM genomics project.



































































