Download to read offline




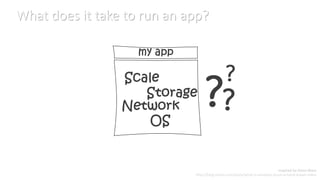
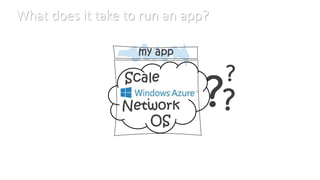
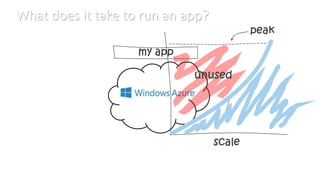
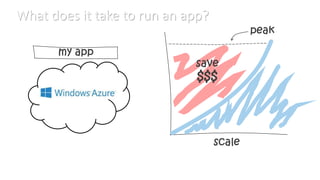





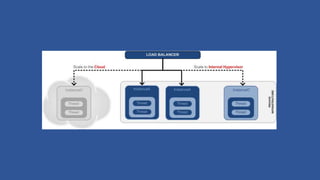


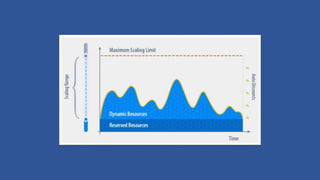


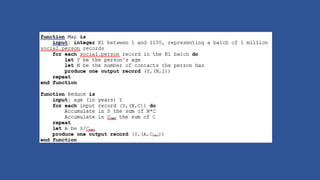

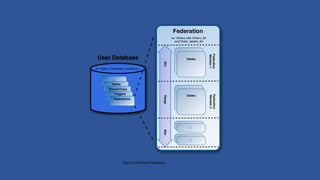

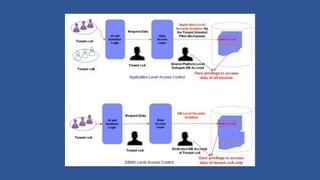






This document discusses various considerations for cloud computing applications including scalability, the cloud environment, cloud native applications, common cloud patterns, and challenges. Specifically, it covers: - Achieving horizontal and vertical scalability by adding/increasing compute and storage resources - How the cloud enables on-demand resources and pay-per-use models - Designing applications to leverage cloud services and scale horizontally across nodes - Common patterns for queue-based workflows, auto-scaling, data partitioning, and handling failures - Challenges of network latency, node failures, and eventual consistency in distributed systems























































































