Download to read offline




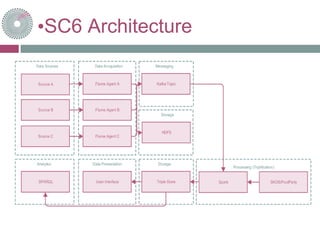




![•SC6 – Processing (I)
Apache Spark
Parallel computing
In SC6
Acts as a Kafka Consumer
Working on message pairs from Kafka
Filename (String)
File content (byte[])
Triplification via Parser for each datasource
SPI](https://image.slidesharecdn.com/sc6-170503145727/85/Societal-Challenge-6-Social-Sciences-Spending-Comparison-11-320.jpg)





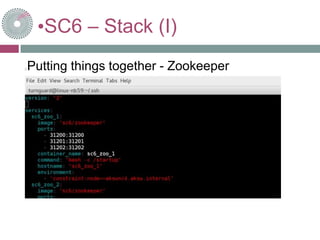







The document outlines a webinar on the BDE-platform release presented by Jürgen Jakobitsch, focusing on creating an online dashboard for economic data through various data acquisition, messaging, and processing techniques involving technologies like Apache Flume, Kafka, and Spark. It details the architecture and setup for handling large data sets, normalizing to RDF, and utilizing a Spark framework for processing and visualization. The session includes a Q&A segment for participants to engage and ask questions.























































































