Downloaded 13 times



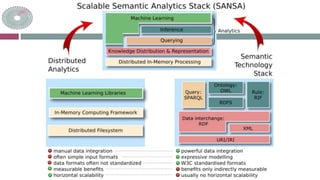







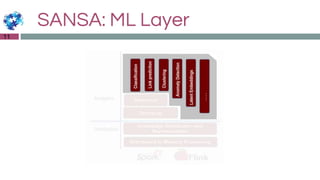




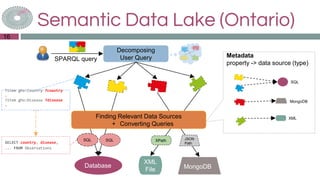
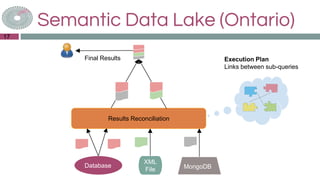






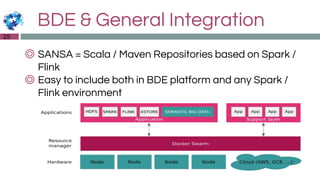

The document discusses the Sansa framework designed for distributed RDF dataset processing, highlighting its libraries for reading, querying, inference, and machine learning. It details the structure of the Sansa stack, which aims to provide scalable and fault-tolerant solutions for querying and analyzing semantic data while allowing integration with existing big data ecosystems like Spark and Flink. Additionally, it introduces the concept of a semantic data lake, which adds a semantic layer on top of various data formats to enable unified querying through SPARQL.























































































