Download to read offline



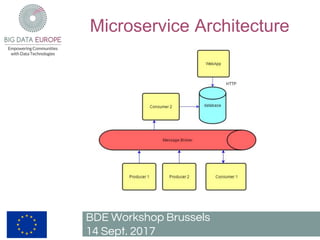

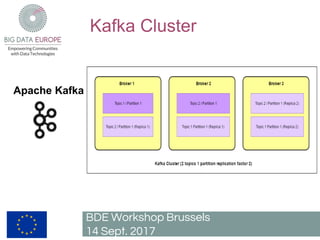

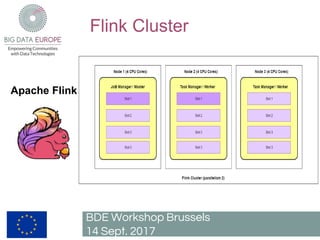

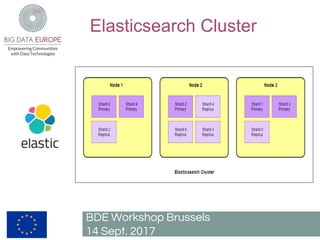
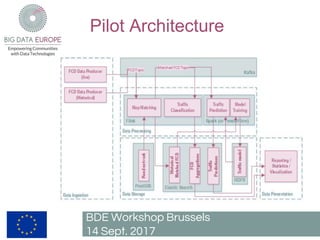
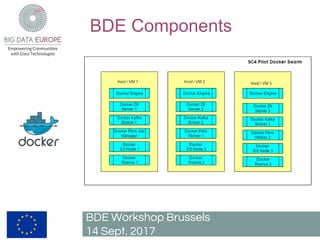
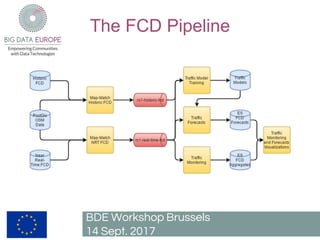


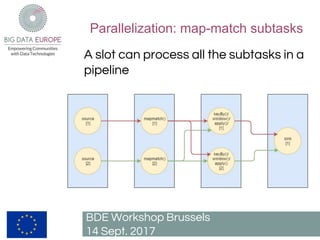









The document describes a pilot project to build a scalable and fault-tolerant platform to process unlimited data sets using open source frameworks. It will use Apache Kafka as a messaging system, Apache Flink for stream and batch processing, PostgreSQL with PostGIS for road network storage and Elasticsearch for result storage. The platform will include a Docker swarm cluster to ingest and map-match real-time floating car data and classify roads by traffic level. It will also develop a short-term traffic forecasting algorithm using a feedforward neural network. The SANSA stack will enable additional use cases by linking semantic technologies and linked data.






















![Michael Hall [InfluxData] | InfluxDB Community Update | InfluxDays EMEA 2021](https://cdn.slidesharecdn.com/ss_thumbnails/michaelhallslides1-210517164021-thumbnail.jpg?width=640&height=640&fit=bounds)


![Andy Charlton [InfluxData] | Managing Your Dashboards, Tasks and Alerts Made ...](https://cdn.slidesharecdn.com/ss_thumbnails/andycharltonslides-210507162942-thumbnail.jpg?width=640&height=640&fit=bounds)





























































