Downloaded 43 times













![Geometric Moments
This feature use only one value for the feature vector,
however, the performance of current implementation
isn’t well scaled, [2] which means when the image
size become large, it takes very long time to
computer the feature vector. The pros of using this
feature combine with other features such co-
occurrence, which can provide a better result to user.](https://image.slidesharecdn.com/webcrawlerwithemailextractorandimageextractor-140531022930-phpapp02/85/Web-crawler-with-email-extractor-and-image-extractor-15-320.jpg)

![Color Moments
This feature has very reasonable size of feature
vector, and the computation isn’t expensive, [4]
Colour Moments are measures that can be
differentiate images based on their feature of colour,
however, the basic of colour moments lays in the
assumption that the distribution of colour in an
image can be interpreted as a probability
distribution. On pros of it is its skewness can be used
to measure of the degree of asymmetry in the
distribution.](https://image.slidesharecdn.com/webcrawlerwithemailextractorandimageextractor-140531022930-phpapp02/85/Web-crawler-with-email-extractor-and-image-extractor-17-320.jpg)













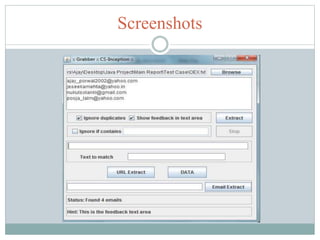
This document describes a web crawler, email extractor, and image extractor program created by Abhinav Gupta, Nitish Parikh, and Rishabh Singh. It discusses how each component works, including that a web crawler starts with seed URLs and recursively extracts links, an email extractor finds emails on websites through various methods, and an image extractor locates images in a database using features like color histograms. The document also provides screenshots and discusses limitations, findings, conclusions, and possibilities for future work.















































