Download to read offline









![The petitioner contends that the regulatory
takings claim should not have been decided by
the jury and that the Court of Appeals adopted an
erroneous standard for regulatory takings liability.
526 U.S. 687 (1999)
sterm(decided,C,[_,_])
...
AND
sterm(adopted,J,[_,_])
...
[modal(should),negative,perfect,passive]](https://image.slidesharecdn.com/slides-160726144507/85/Slides-ltdca-9-320.jpg)

![Semantics of 'WDT' and 'WHNP': W^nterm(which,W,[])
Semanticsof 'IN': Obj^Subj^P^pterm(in,P,[Subj,Obj])
Unify: Obj = nterm(which,W,[])
Term = pterm(in,P,[Subj,Obj])
Semanticsof 'WHPP':
W^Subj^P^pterm(in,P,[Subj,nterm(which,W,[])])](https://image.slidesharecdn.com/slides-160726144507/85/Slides-ltdca-11-320.jpg)
![Semantics of 'S': E^sterm(claims,E,[_,_])
Unify: Term = pterm(in,P,[E,nterm(which,W,[])])
Tense = [present]
Semanticsof 'SBAR':
W^(E^(P^pterm(in,P,[E,nterm(which,W,[])]) &
sterm(claims,E,[_,_]))/[present])](https://image.slidesharecdn.com/slides-160726144507/85/Slides-ltdca-12-320.jpg)





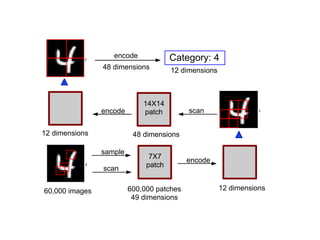

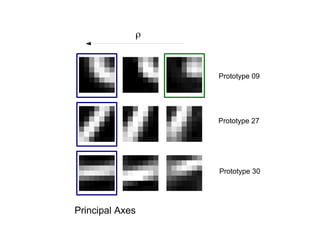
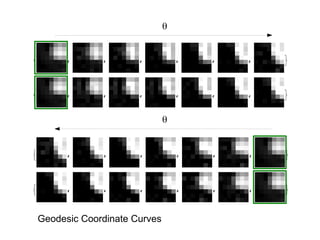






The document proposes a research strategy to produce computational summaries of legal cases at scale through semi-supervised learning of legal semantics. It summarizes three of the author's past papers on representing legal semantics and outlines a two-step approach: 1) Using natural language processing to automatically generate semantic interpretations of legal texts, and 2) Generalizing patterns of information extraction through unsupervised learning of semantics from a large corpus of cases. The current proposal is to initialize the model with word embeddings from legal texts and learn higher-level concepts by applying a theory of representation based on prototypes and manifolds.


































































