Downloaded 42 times


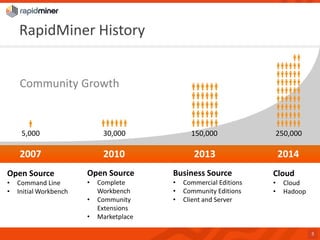

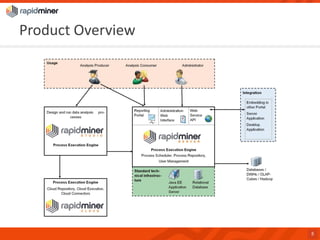

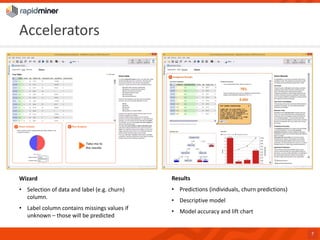
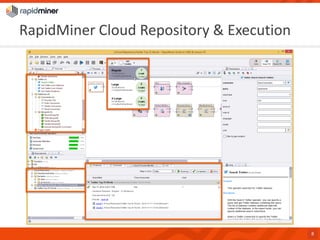
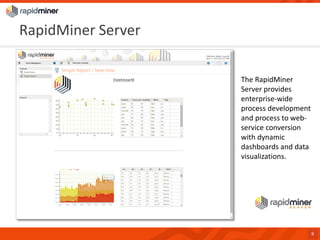
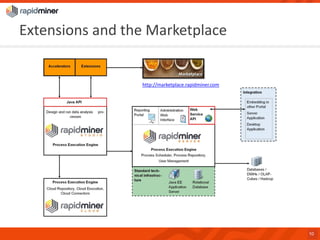




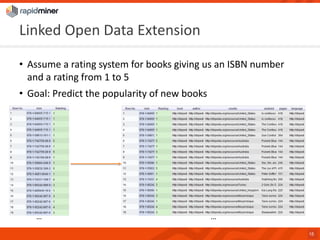
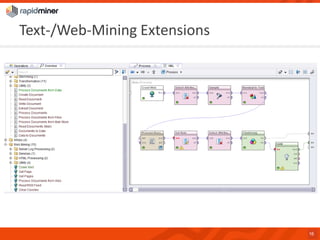
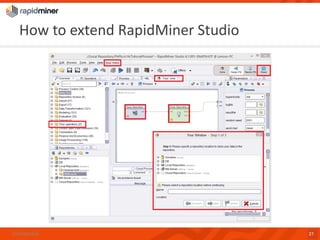

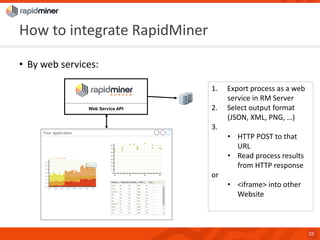



RapidMiner provides a platform for data mining and predictive analytics with over 1500 operators and a marketplace for developers to create extensions. The software integrates seamlessly with various data sources and has seen significant community growth, boasting over 250,000 users and 600 customers globally. Key features include a user-friendly design environment for rapid data process development and the ability to deploy processes to a server or cloud.















































































