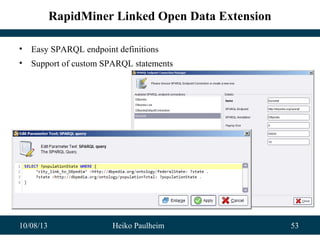
Download as ODP, PPTX














![10/08/13 Heiko Paulheim 21
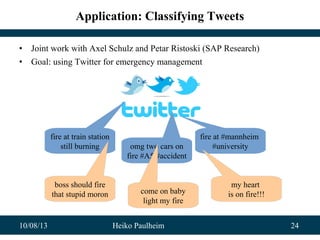
Application: Classifying Events from Wikipedia
• Possibly Learned Model:
– "Angela Merkel" → Politics
• How can we do better?
• Background knowledge from Linked Open Data
– 2011, March 15 - German chancellor Angela Merkel [class: Politician] shuts
down the seven oldest German nuclear power plants.
– 2012, May 13, Elections in North Rhine-Westphalia – Hannelore Kraft [class:
Politician] is elected to continue as Minister-President, heading an SPD-
Green coalition.
• Model learned in that case:
– "[class: Politician]" → Politics](https://image.slidesharecdn.com/dmold-2013-131008082726-phpapp01/85/Exploiting-Linked-Open-Data-as-Background-Knowledge-in-Data-Mining-21-320.jpg)
![10/08/13 Heiko Paulheim 22
Application: Classifying Events from Wikipedia
• Model learned in that case:
– "[class: Politician]" → Politics
• Much more general
– Can also classify events with politicians
not contained in the training set
• Less training examples required
– A few events with politicians, athletes, singers, ... are enough](https://image.slidesharecdn.com/dmold-2013-131008082726-phpapp01/85/Exploiting-Linked-Open-Data-as-Background-Knowledge-in-Data-Mining-22-320.jpg)
![10/08/13 Heiko Paulheim 23
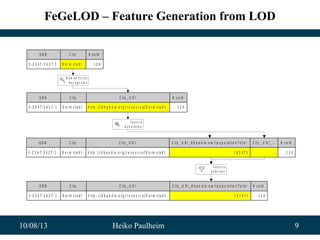
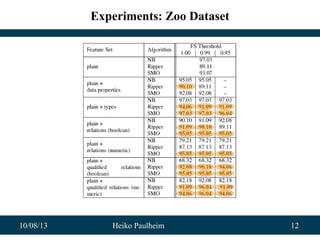
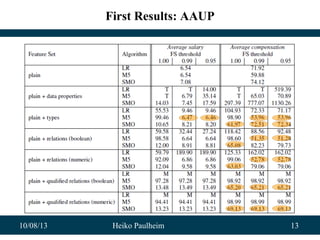
Application: Classifying Events from Wikipedia
• Experiments on Wikipedia data
– >10 categories
– 1,000 labeled examples as training set
– Classification accuracy: 80%
• Plus:
– We have trained a language-independent model!
• often, models are like "elect*" → Politics
– 22. Mai 2012: Peter Altmaier [class: Politician] wird als Nachfolger von
Norbert Röttgen [class: Politician] zum Bundesumweltminister ernannt.
– 6 januari 2012: Jonas Sjöstedt [class: Politician] väljs till ny partiledare för
Vänsterpartiet efter Lars Ohly [class: Politician].](https://image.slidesharecdn.com/dmold-2013-131008082726-phpapp01/85/Exploiting-Linked-Open-Data-as-Background-Knowledge-in-Data-Mining-23-320.jpg)





























![10/08/13 Heiko Paulheim 60
Challenges and Future Work
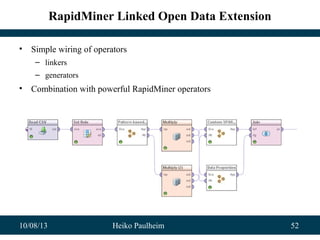
• Automatically exploit data sources with non-simple structures
EU18931 a Funding .
EU18931 has-grant-value [
has-amount 1300000 .
has-unit-of-measure EUR .
]
• Support geo/temporal features
– e.g., Data Cubes
– e.g., Linked Geo Data
• Construct complex features (in a scalable way!)
– e.g., cinemas per inhabitant
real example from
CORDIS dataset](https://image.slidesharecdn.com/dmold-2013-131008082726-phpapp01/85/Exploiting-Linked-Open-Data-as-Background-Knowledge-in-Data-Mining-60-320.jpg)




The document summarizes an approach to exploiting linked open data as background knowledge in data mining tasks. It describes using LOD to generate additional features for machine learning algorithms from entity names in datasets. Experiments show this approach can improve results for classification tasks. Applications discussed include classifying events from Wikipedia and tweets by leveraging background knowledge from DBpedia to prevent overfitting. The document also proposes using LOD to help explain statistics by enriching datasets and analyzing correlations.























































































