순서
•조원별 업무분담
•일정 계획
-회의록
•문제 파악
-Linked List라는 자료구조를 활용하여
다항식 연산
•알고리즘 계획
•소스구현
•문제점 파악 / 해결법 토의
•최종소스
•시간 복잡도/공간 복잡도
3.
1) 조원별 업무분담
이름 역할
장동규 조장, 보고서 작성, 자료 조사
정예린 코딩, 자료 조사
정민정 알고리즘, 자료조사
서영진 보고서 작성, 자료 조사
2)일정계획
날짜 계획
링크드 리스트, 다항식 연산에 대해 조사
04.12~04.17
해오기, 보고서 작성
링크드 리스트 소스 구현하는 알고리즘, 이
04.17~04.19 것을 어떻게 다항식 연산에 활용할 것인지
생각 해오기, 보고서 작성
04.19~04.24 알고리즘을 소스로 구현, 최종 보고서 작성
4.
3)문제파악
링크드 리스트(Linked List)
배열구조의 단점을 보안한 자료구조이다. 배열은 인덱스를 이용하여 해당 주소에 바로 접
근할 수 있는 장점이 있지만, 단점으로는 삽입, 삭제 연산이 복잡하다. 그리고 배열은 선언
시 크기를 미리 정해줘야 하기 때문에 배열 공간 100개를 선언해 놓고 10개만 쓰는 경우
(메모리 낭비), 200개가 필요한 경우(공간 부족) 라면 배열 선언 부분을 다시 수정해줘야 하
는 불편함이 있다.
이러한 단점을 보안해 필요할 때 마다 공간을 할당하고 또 그것들을 연결하여 마치 배열처
럼 사용하는 기법이 바로 링크드 리스트이다.
링크드 리스트의 장점으로는 프로그래머가 미리 공간을 할당할 필요 없이 필요할때마다 공
간을 할당 받을 수 있도록 설계가 가능하다. 그러기 때문에 필요한 변수의 크기를 모를 경
우에는 배열보다 효율적이다. 하지만 링크드 리스트에도 단점은 있다. 다음 노드의 주소를
가리키기 위해 4byte(32비트 운영체제 기준)의 공간이 낭비된다. 또, 인덱스로 해당 주소에
접근하는 것이 아닌 노드의 첫 번째를 가리키는 Head라는 포인터 변수를 통해서 순차적으
로 접근하는 단점으로 인해 검색속도가 느리다는 단점이있다.
(3번지 주소까지 가기 위해서는 1, 2번 주소지를 거쳐야 갈 수 있다.)
5.
다음은 링크드 리스트를구현한 소스이다.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct tagNode{
char Name[20];
struct tagNode* NextNode;
}NODE;
구조체로 이루어져 있는 링크드 리스트. Name은 데이터를 담을 변수로 데이터가 들어가
며, tagNode*는 다음 노드의 주소를 가리킬 포인터 변수이다.
NODE* CreateNode(char name[])
{
NODE* NewNode = (NODE*)malloc(sizeof(NODE));
strcpy(NewNode -> Name, name);
NewNode -> NextNode = NULL;
return NewNode;
}
NODE를 생성하는 함수이다. 인자로는 해당 노드에 들어갈 값을 저장하기 위한 값을 받고
있다. NewNode라는 포인터를 생성후 그 해당하는 주소에 malloc함수로 공간을 동적할당하
고 있다.
void ConnectNode(NODE** Head, NODE* Node)
{
if(NULL == (*Head))
6.
{
*Head = Node;
}
else
{ NODE* Current = *Head;
while(Current -> nextNode != NULL)
{
Current = Current -> NextNode;
}
Current -> NextNode = Node;
}
}
인자로는 첫 노드를 가리키는 Head의 주소값과 연결한 노드를 인자로 받는다. 여기서 헤
드가 가리키는 노드가 없는(NULL)새로운 노드라면, main에 선언한 Head값 자체를 바꾸기
위해 포인터 Head의 주소값을 가져오기 때문에 결과적으론 이중 포인터를 사용해야 한다.
노드의 맨 마지막에 삽입할 경우의 수는 두 가지가 있다.
1. Head가 NULL일 경우(텅 빈 노드)
2. Head가 NULL이 아닐 경우(하나 이상의 연결된 노드)
1번의 경우는 Head의 다음 노드에 새 노드의 주소값을 넣으면 되지만, 2번의 경우엔 끝
노드를 찾아서(NULL이 있는곳) 연결 해 줘야 한다. NODE* Current;를 선언하는 이유는
Head의 값을 바꾸지 않고 연결된 다른 노드에 접근하기 위해서 사용한다.
void PrintNode(NODE* Head, int index)
{
NODE* Current = Head;
7.
while(Current != NULL&& 0 < index)
{
index--;
Current = Current -> NextNode;
}
printf(“%sn”, Current -> Name);
}
노드의 값을 출력하는 함수이다. 인자로는 Head와 몇 번째 노드를 출력할건지 정하는 변
수이다. while의 경우 Current != NULL은 NULL일 경우엔 노드의 끝이므로 이 이상 접근을
하지않기 위해 쓴다.
int GetCountNode(NODE * Head)
{
NODE* Current = Head;
int count = 0;
while(Current != NULL)
{
count++;
Current = Current -> NextNode;
}
return count;
}
PrintNode로 전체 출력을 하기를 원할 경우 노드의 개수를 알아내는데 사용되는 함수이다.
void InsertNode(NODE** Head, NODE* ConnectNode, int index)
{
if(0 == index)
8.
{
ConnectNode -> NextNode = (*Head);
*Head = ConnectNode;
}
else
{
NODE* Current = *Head;
while(0 < (--index))
{
Current = Current -> NextNode;
}
ConnectNode -> NextNode = Current -> NextNode;
Current -> NextNode = ConnectNode;
}
}
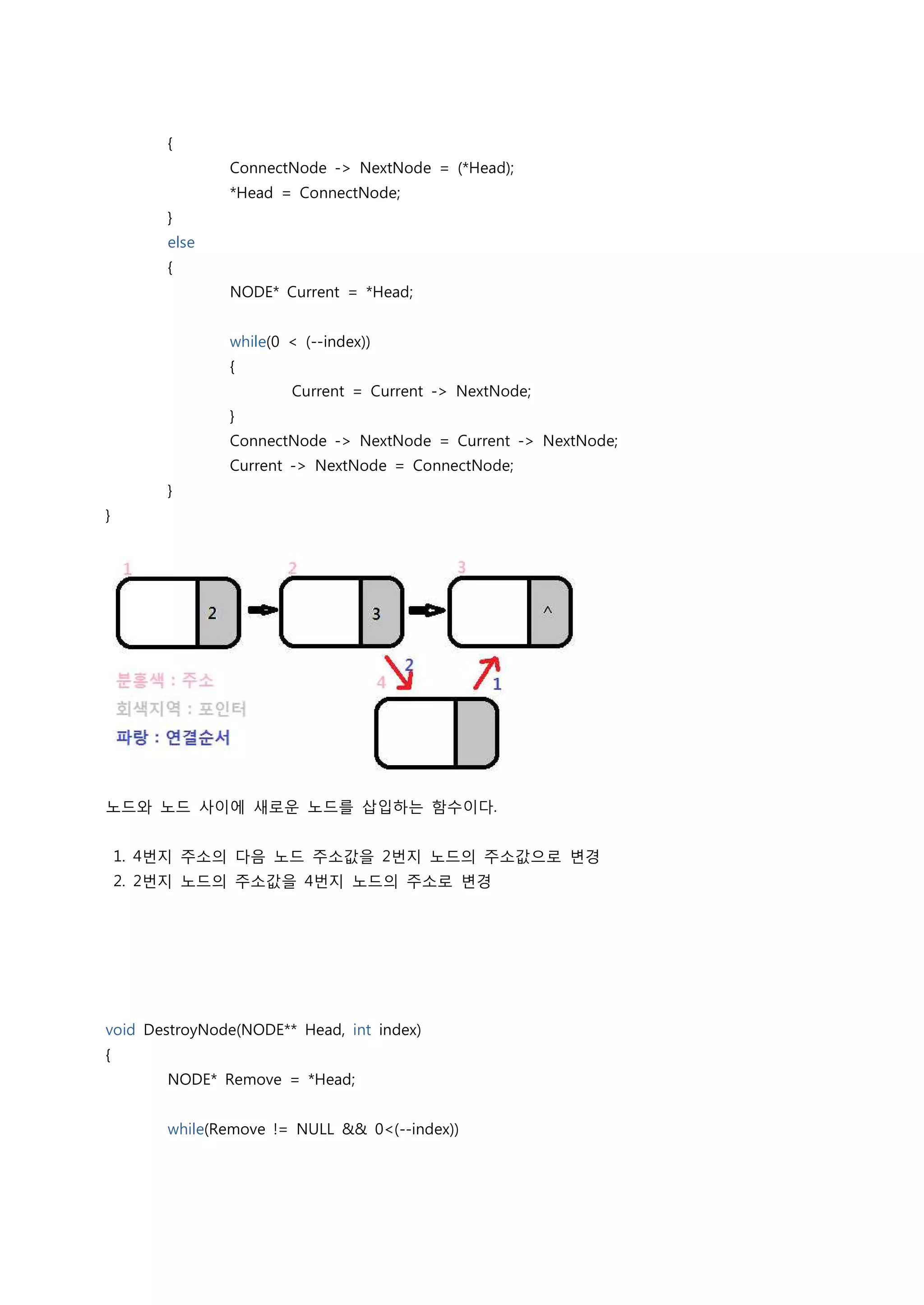
노드와 노드 사이에 새로운 노드를 삽입하는 함수이다.
1. 4번지 주소의 다음 노드 주소값을 2번지 노드의 주소값으로 변경
2. 2번지 노드의 주소값을 4번지 노드의 주소로 변경
void DestroyNode(NODE** Head, int index)
{
NODE* Remove = *Head;
while(Remove != NULL && 0<(--index))
9.
{
Remove = Remove -> NextNode;
}
if(*Head == Remove)
{
*Head = Remove -> NextNode;
}
else
{
NODE* Current = *Head;
while(Current != NULL && Current -> NextNode != Remove)
{
Current = Current -> NextNode;
}
if(Current != NULL)
{
Current -> NextNode = Remove -> NextNode;
}
}
free(Remove);
}
삭제 연산은 삽입 연산보다 훨씬 간단하다. 삭제할 노드의 앞노드(1번노드)의 다음 주소를
삭제할 노드의 다음 주소를 가리키도록만 하면 된다.
프로그래머가 할당하는 공간은 프로그래머가 해제해 줘야한다. 그러기 위해서 사용하는 함
수 free가 있다. 인자는 해제할 메모리의 주소값만 넘기면 되기 때문에 삭제할 노드의 주소
를 보내주면 된다.
구조체
다른 종류의 데이터를 하나로 묶어서 사용하는 데이터 결합법을 말한다.
각기 다른 형이나 다른 의미의 값을 가지고 있는 배열들을 한 번에 나타낼 수 있도록 구현
한 자료구 조형이다.
10.
struct 구조체 이름
{
자료형 자료이름;
자료형 자료이름;
}
과 같이 정의 할 수 있으며, 정의를 할 때에는 다음의 조건이 따른다.
①구조체 정의에서 바로 초기화 할 수 없다.
②구조체 선언은 문자에 해당되기 때문에 끝마친 후 ;을 붙여 주어야 한다.
구조체를 통해서 여러개의 테이타 값을 묶을 수 있게 하여 연결리스트를 구현 할 수 있도록
한다.
4)알고리즘 계획
① 다항식의 표현
DATA LINK
1) 각 노드의 구조체 배열에서 DATA를 저장하는 배열과 다른 노드를 가리킬 수 있는 LINK
가 존재한다. 이 때 DATA는 처리하는 값을 저장하는 배열이고, LINK는 다음 노드를 가리키
는 포인터의 역할을 한다.
다항식을 구현하기 위해서는,
2) 다항식의 각 항을 계수부분 지수부분으로 나누어 생각한다.
DATA의 배열도 계수와 지수를 저장할 수 있는 구조체를 선언한다.
계수부분 지수부분
11.
즉,
DATA- DATA-지
LINK
계수부분 수부분
과 같이 한 노드가 만들어지게 된다.
3) 이러한 노드를 다항식에서 항의 개수만큼 LINK를 이용해 다음 항을 가리키고 다음 항을
가리키는 식으로 한 개의 다항식에 대해 한 개의 연결리스트를 만들어준다.
② 다항식의 덧셈과 뺄셈
1) 연결리스트로 작성 된 다항식1과 다항식2에 대해서 지수부분이 같은 노드끼리 연산을 해
준 다.
2) 다항식 3을 연결리스트로 작성하게 되는데, 이 때 1과2로 연산된 값을 3에 저장한다.
3) 1과 2에 같은 지수부분이 없어서 연산되지 않은 나머지 항들은 그대로 복사되어서 3에
저 장된다.
4) 다항식의 연산을 마쳐서 3에 저장된 결과 값을 출력한다.
③ 다항식의 곱셈
1) 다항식 1의 노드와 다항식2의 노드의 계수부분은 곱셈연산을 하고 지수부분은 더하기 연
산 을 해준다.
2) 다항식1의 노드와 다항식2의 노드는 서로의 노드가 모두 순서쌍을 한 번 씩은 이루어야
된 다.
3) 순서쌍을 이루어서 연산 된 결과 값은 새로운 연결리스트 3에 저장된다.
4) 각 노드들을 모두 더할 수 있도록, 위에서 작성하였던 ADD연산을 한 번 더 해준다.
5) 정리 되어 3에 저장된 결과 값을 출력한다.
④ 다항식의 나눗셈
1) 나누는 다항식의 최고차항이 나눠지는 최고차항과 같아지게 할 수 있는 X가 계속해서 몫
이 될 수 있다.
2) 계수의 계산은,
p(x)의 계수 = s(x)계수*q(x) 계수, q(x)계수는 p/s과 같이 된다.
3) 계속 최고차항에 맞춰서 X가 곱해져서 나눠지는 다항식에 그 결과 값을 뺄셈을 하고 있
다.
이 때 곱해지는 차수가 0이거나 나머지가 0이면 스톱한다.
만약 뺄셈을 하다가 다항식이 남게 되면 그 남은 다항식은 나머지가 된다.




![다음은 링크드 리스트를 구현한 소스이다.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct tagNode{
char Name[20];
struct tagNode* NextNode;
}NODE;
구조체로 이루어져 있는 링크드 리스트. Name은 데이터를 담을 변수로 데이터가 들어가
며, tagNode*는 다음 노드의 주소를 가리킬 포인터 변수이다.
NODE* CreateNode(char name[])
{
NODE* NewNode = (NODE*)malloc(sizeof(NODE));
strcpy(NewNode -> Name, name);
NewNode -> NextNode = NULL;
return NewNode;
}
NODE를 생성하는 함수이다. 인자로는 해당 노드에 들어갈 값을 저장하기 위한 값을 받고
있다. NewNode라는 포인터를 생성후 그 해당하는 주소에 malloc함수로 공간을 동적할당하
고 있다.
void ConnectNode(NODE** Head, NODE* Node)
{
if(NULL == (*Head))](https://image.slidesharecdn.com/2012ds03-13407275188158-phpapp01-120626111922-phpapp01/75/2012-Ds-03-5-2048.jpg)

























![[Swift] Data Structure - Dequeue](https://cdn.slidesharecdn.com/ss_thumbnails/swiftdatastructure-dequeue-200527055025-thumbnail.jpg?width=640&height=640&fit=bounds)









































