Download as PDF, PPTX


![CNN Architecture
margin (*)
(1_overall)
keypoint heatmap
(category 2~8)
box size (*)
local offset
EfficientNet
(ImageNet pretrained)
BiFPN
image
[b, 3, h, w]
[b, 4]
[b, 2, h/4, w/4]
[b, 2, h/4, w/4]
[b, 7, h/4, w/4]
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks https://arxiv.org/abs/1905.11946
EfficientDet: Scalable and Efficient Object Detection https://arxiv.org/abs/1911.09070
Objects as Points https://arxiv.org/abs/1904.07850
(*) normalized by
input image width
category mask
[b, 7, 1, 1]
×
CenterNet
Margin Regression
古典籍:
[1, 1, 1, 1, 0, 0, 0]
明治期以降刊行:
[0, 0, 1, 1, 1, 1, 1]](https://image.slidesharecdn.com/ndl-1st-200308022827/85/SIGNATE-1st-place-solution-3-320.jpg)
![Training Parameters
• 5-Fold CV
• Batch Size: 6 (2 GPU, GTX1080ti x 2)
• Epochs: 104
• Optimizer: RAdam, LR=1.2e-3 (x0.1 at epoch=[64, 96])
• Data Augmentation:
• Random Crop & Scale
• Gray Scale / Thresholding (cv2.adaptiveThreshold)
• Random Rotate (±0.2degree)
• Cutout (side edge)
• Loss Function:
• keypoint heatmap: Focal Loss (weight=1.0)
• box size: L1 Loss (weight=5.0)
• local offset : L1 Loss (weight=0.2)
• margin : L1 Loss (weight=12.5)
On the Variance of the Adaptive Learning Rate and Beyond https://arxiv.org/abs/1908.03265](https://image.slidesharecdn.com/ndl-1st-200308022827/85/SIGNATE-1st-place-solution-4-320.jpg)
![Score History
public private
single model (Φ=4), 5-Fold CV,
NMS ensemble
0.79143 0.82140
single model (Φ=4), 5-Fold CV, TTA (3 scale),
NMS ensemble
0.80315 0.82782
3 model (Φ=[0, 2, 4]), 5-Fold CV, TTA (3 scale),
NMS ensemble
0.80468 0.82961
3 model (Φ=[0, 2, 4]), 5-Fold CV, TTA (3 scale),
WBF ensemble
0.82226 0.84791
5 model (Φ=[0, 1, 2, 3, 4]), 5-Fold CV, TTA (3 scale),
WBF ensemble
0.82340 0.84978](https://image.slidesharecdn.com/ndl-1st-200308022827/85/SIGNATE-1st-place-solution-6-320.jpg)

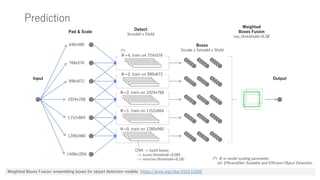
This document summarizes the 1st place solution for detecting objects in images of classical and modern Japanese books for the National Diet Library of Japan. The solution uses an EfficientDet model with BiFPN and CenterNet to detect 7 categories of objects. It is trained on over 2000 images using focal loss, L1 loss, and data augmentation. Multiple models at different scales are ensemble using weighted boxes fusion to achieve mean IoU scores of 0.82340 for public and 0.84978 for private leaderboards.


![[DL輪読会]SlowFast Networks for Video Recognition](https://cdn.slidesharecdn.com/ss_thumbnails/20191206slowfastnetworkkuboshizuma-191206010601-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]医用画像解析におけるセグメンテーション](https://cdn.slidesharecdn.com/ss_thumbnails/20190301fujino4-190322072121-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[NS][Lab_Seminar_241118]Relation Matters: Foreground-aware Graph-based Relati...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar241118fgrr-241118111529-1ff1aba4-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Mikhail Rozhkov - AI Product Canvas: From Business Goals to T...](https://cdn.slidesharecdn.com/ss_thumbnails/d53doddtpgfqivmzqel6-mikhail-rozhkov-ai-product-canvas-v1-260121115910-9dd517a7-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DSC Europe 25] Egor Krasheninnikov - The Control Stack: Building Guardrails ...](https://cdn.slidesharecdn.com/ss_thumbnails/3lzcz7hxqmo51mtalv4u-the-control-stack-260119101520-ea90841a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tamas Srancsik - How To Teach Your AI Football? An Argument f...](https://cdn.slidesharecdn.com/ss_thumbnails/bcjh1m9xtbosv20ucftb-tamas-srancsik-how-to-teach-your-ai-football-260121115910-08b53e9e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Srdj Stanisic - Local and Private AI in UX.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vwmetykqmztgmokmmkfa-3-srdjan-stanisic-local-and-small-ai-in-ux-260120105855-55a31869-thumbnail.jpg?width=640&height=640&fit=bounds)


