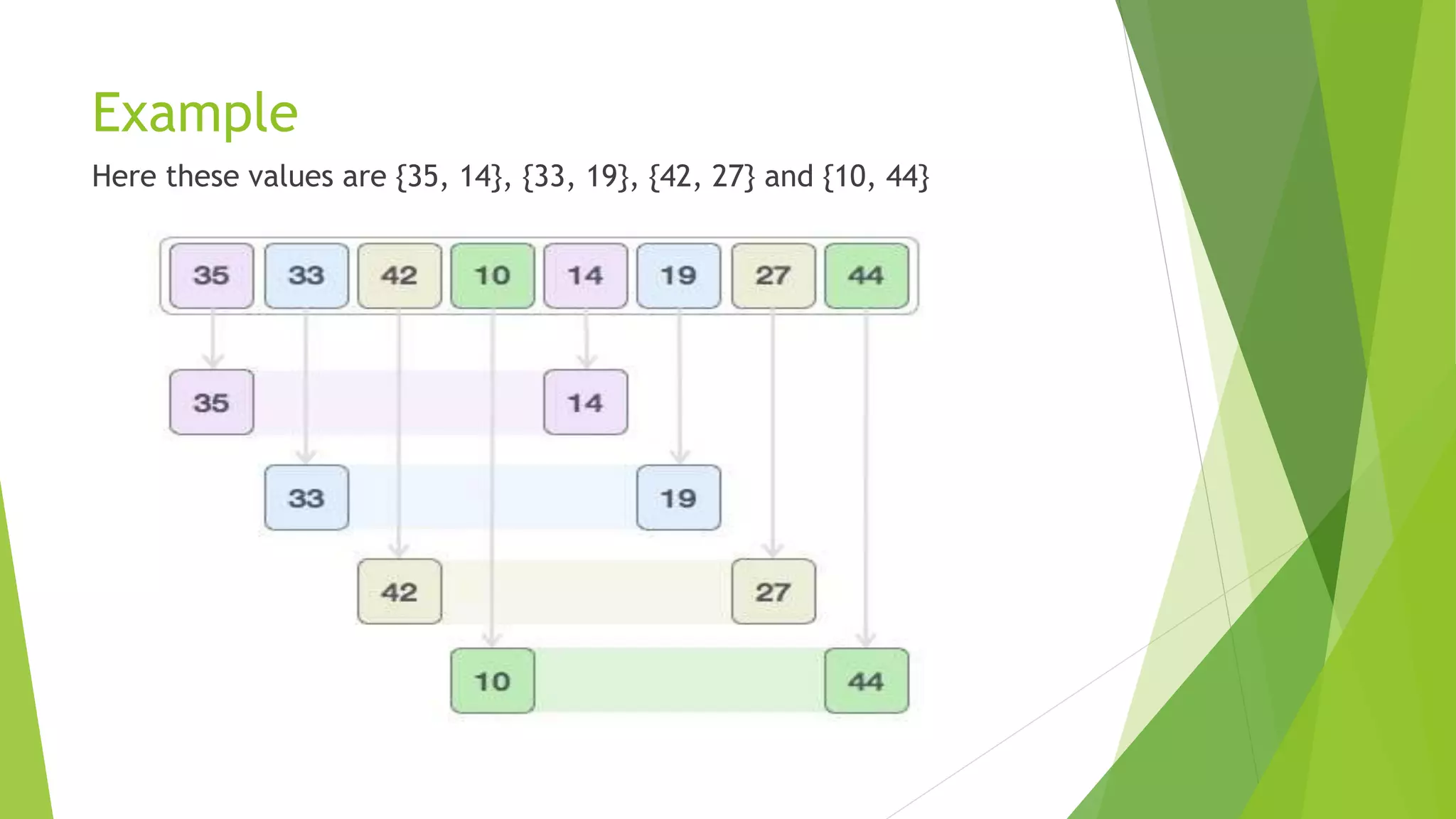
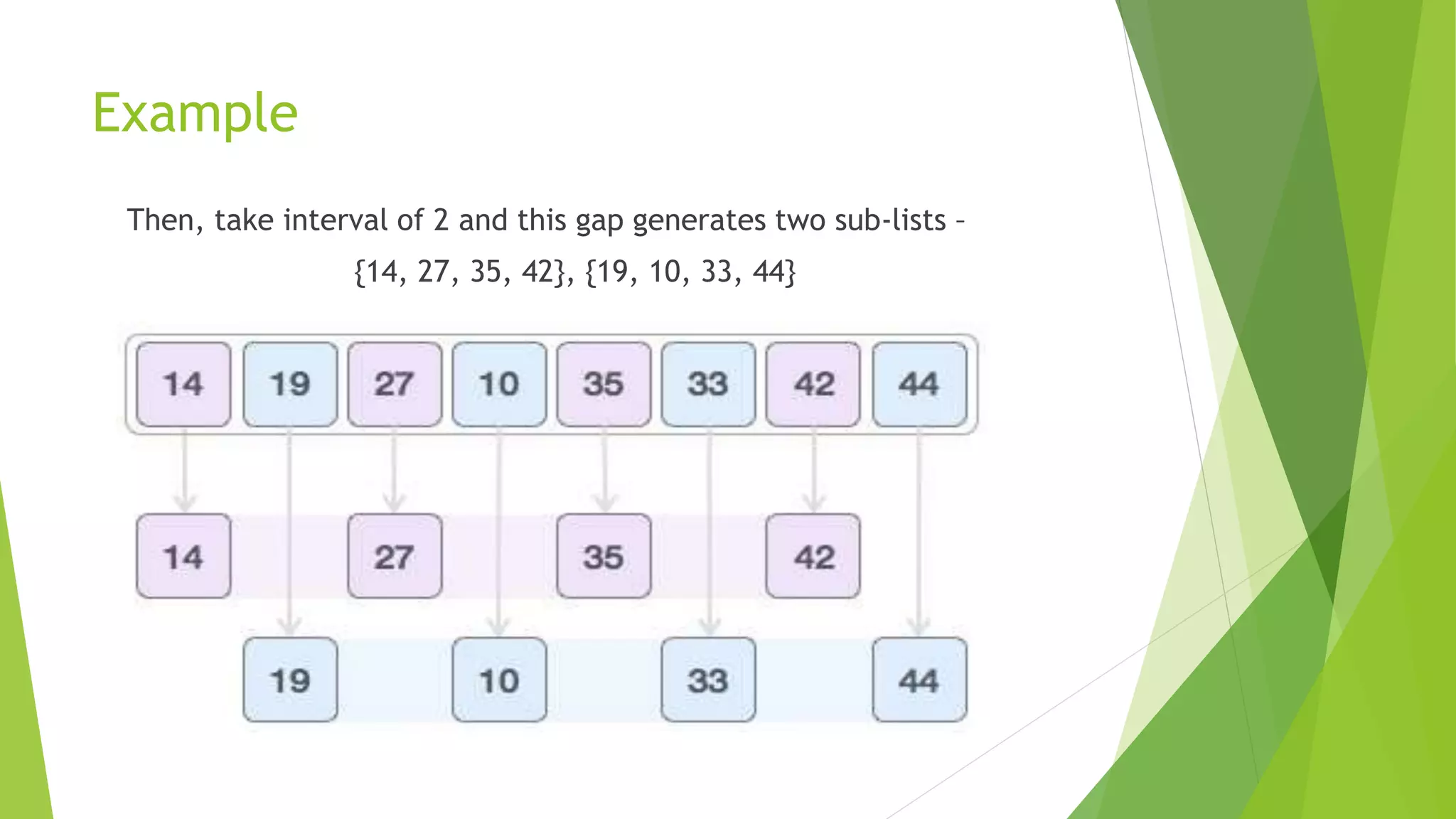
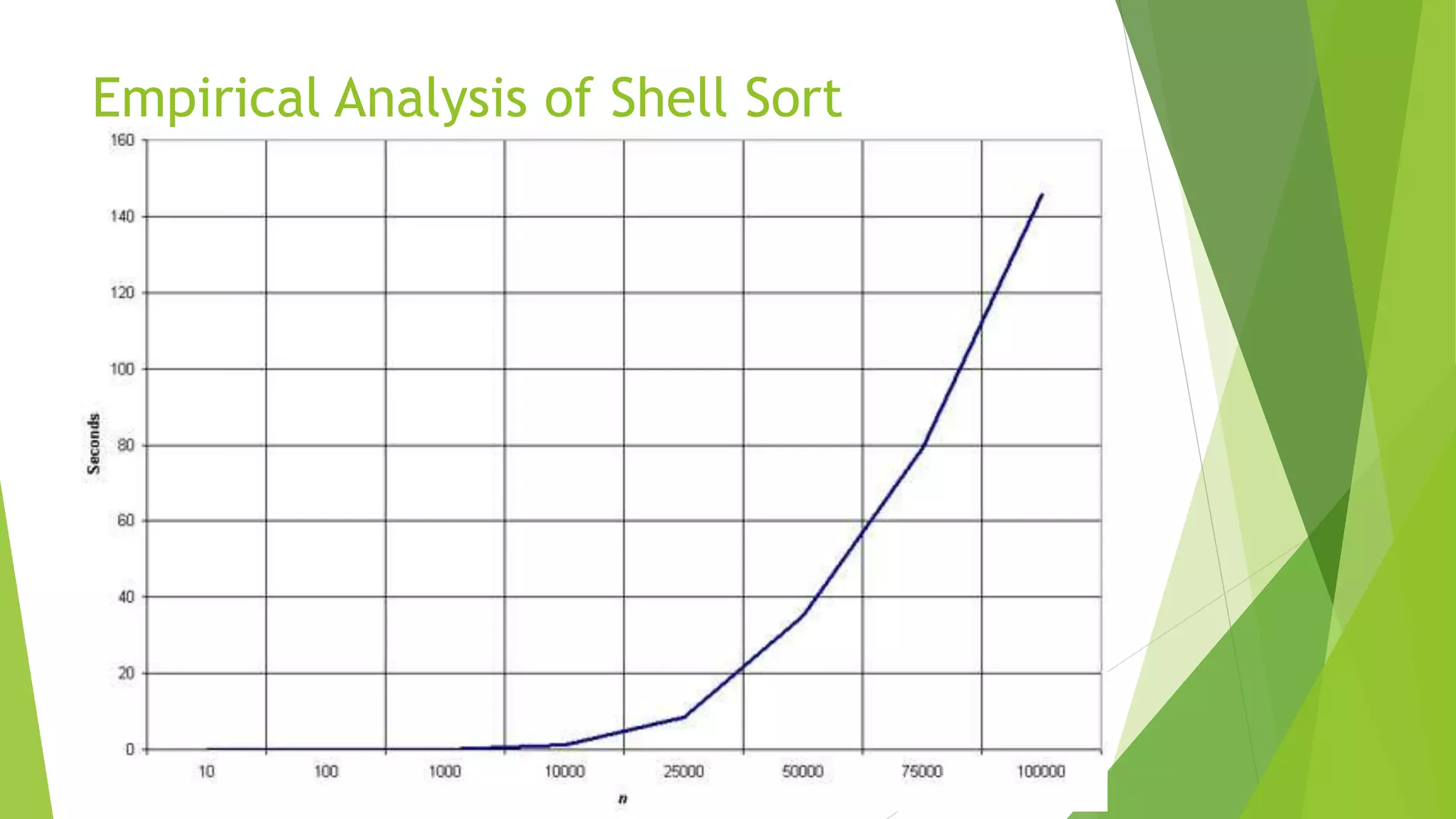
Shell sort, developed by Donald Shell in 1959, is a highly efficient sorting algorithm that minimizes the time complexity of sorting by comparing distant elements instead of adjacent ones. It operates using an increment sequence, allowing for multiple passes through a list and is generally faster than bubble and insertion sorts, though it is less efficient than merge, heap, and quick sorts. The algorithm’s performance depends on the choice of increment sequence, with its best case occurring when the array is already sorted.



















![Data Structures - Lecture 8 [Sorting Algorithms]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture-8sortingalgorithms-150205105023-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)












![Shell sort[1]](https://cdn.slidesharecdn.com/ss_thumbnails/shellsort1-131120033842-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)










![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
