The document discusses serializing EMF models with Xtext. It covers:
- The new Xtext serializer is better than the old one in terms of errors, performance and deprecation.
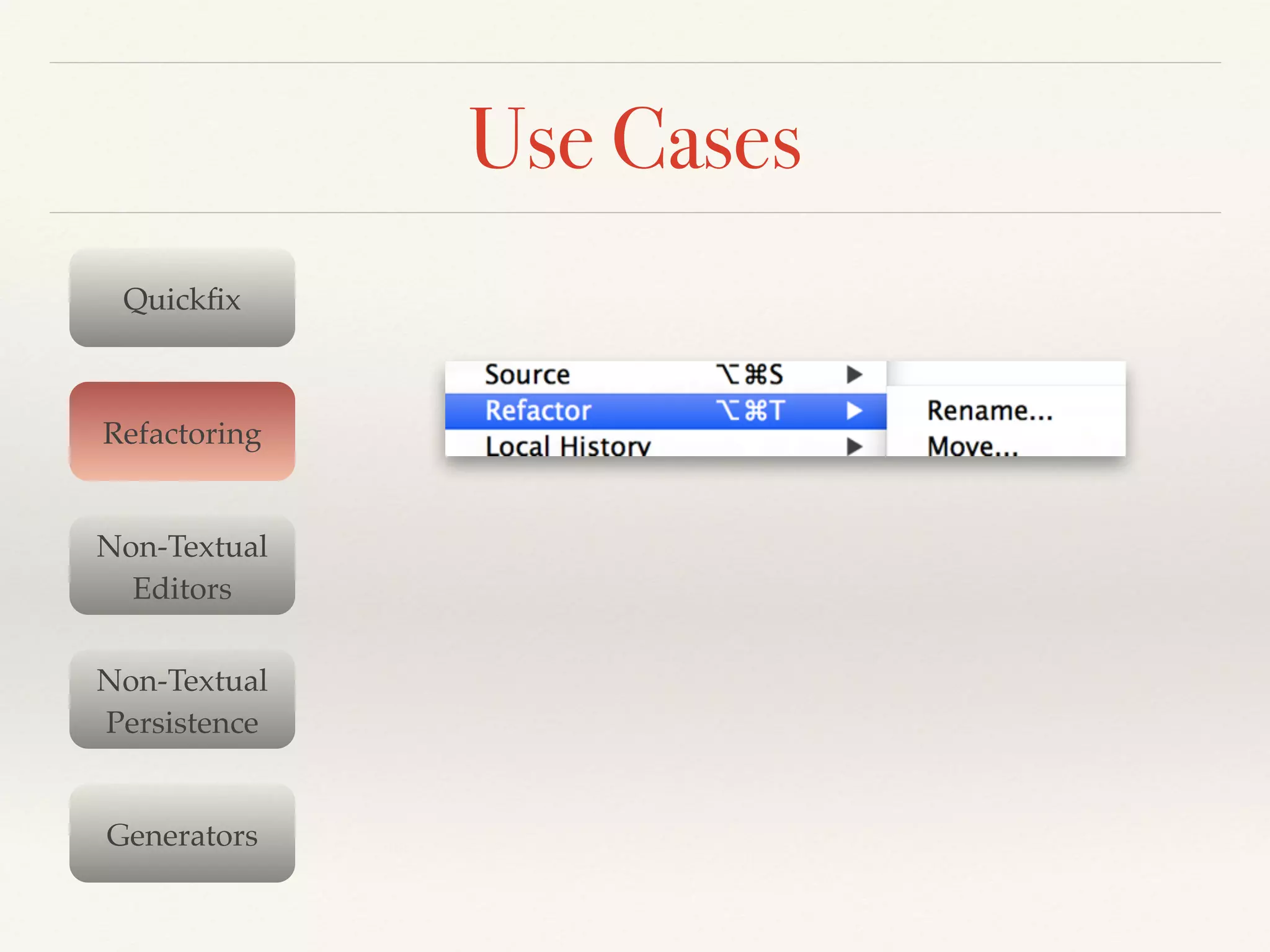
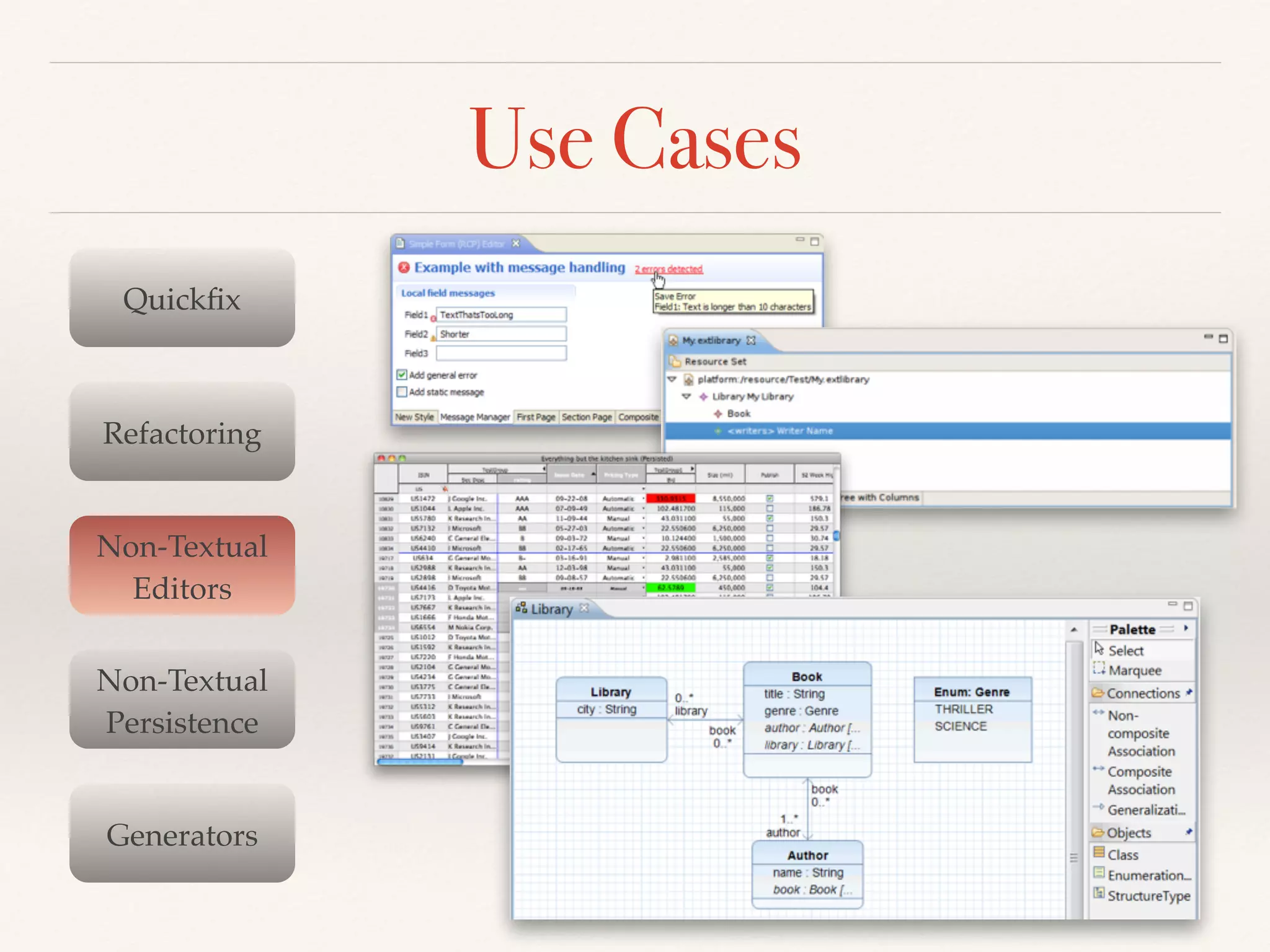
- Serialization is used for quickfixes, refactoring, persistence, generators and more. It guarantees syntactical correctness and handles comments/whitespace.
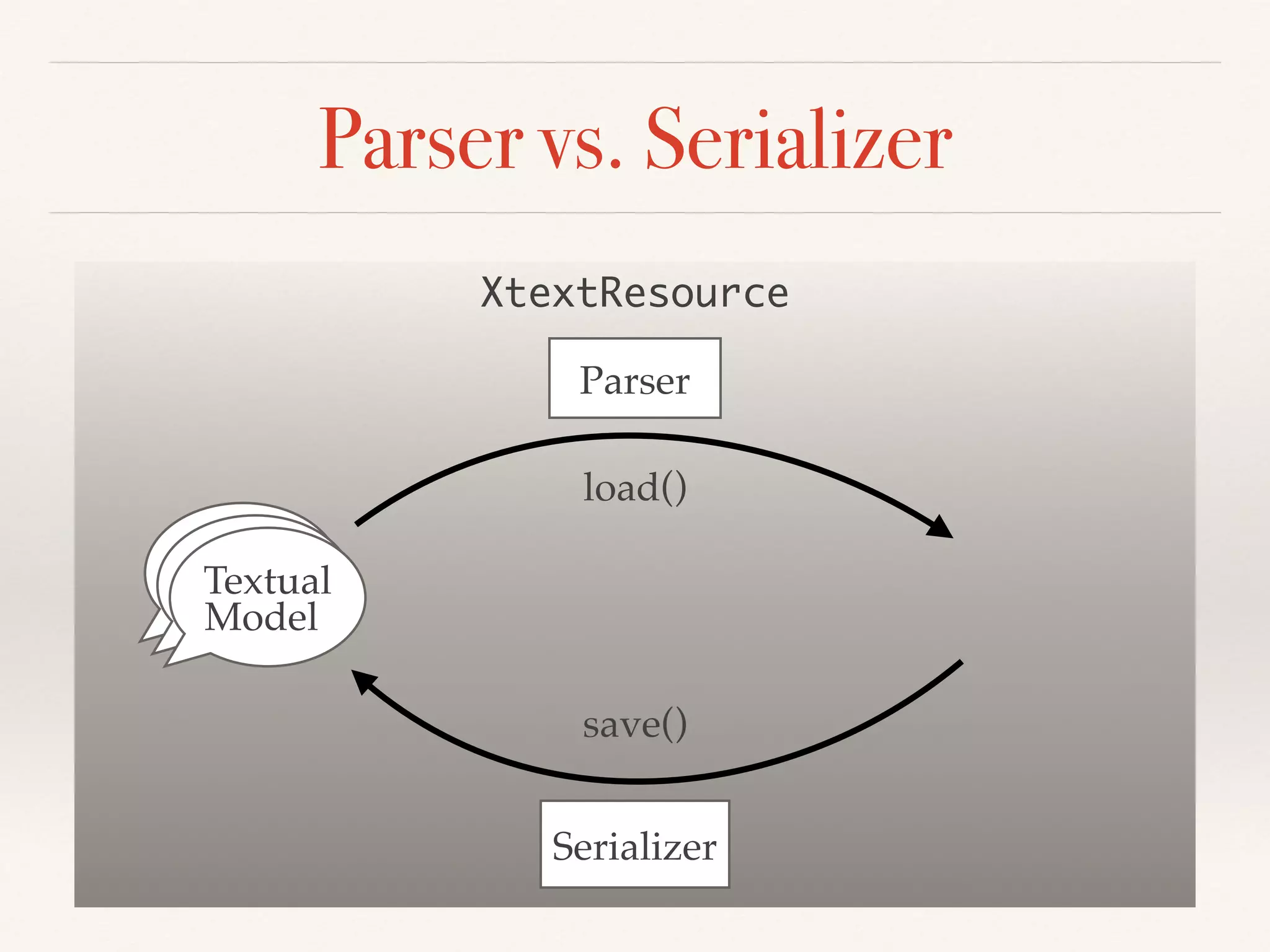
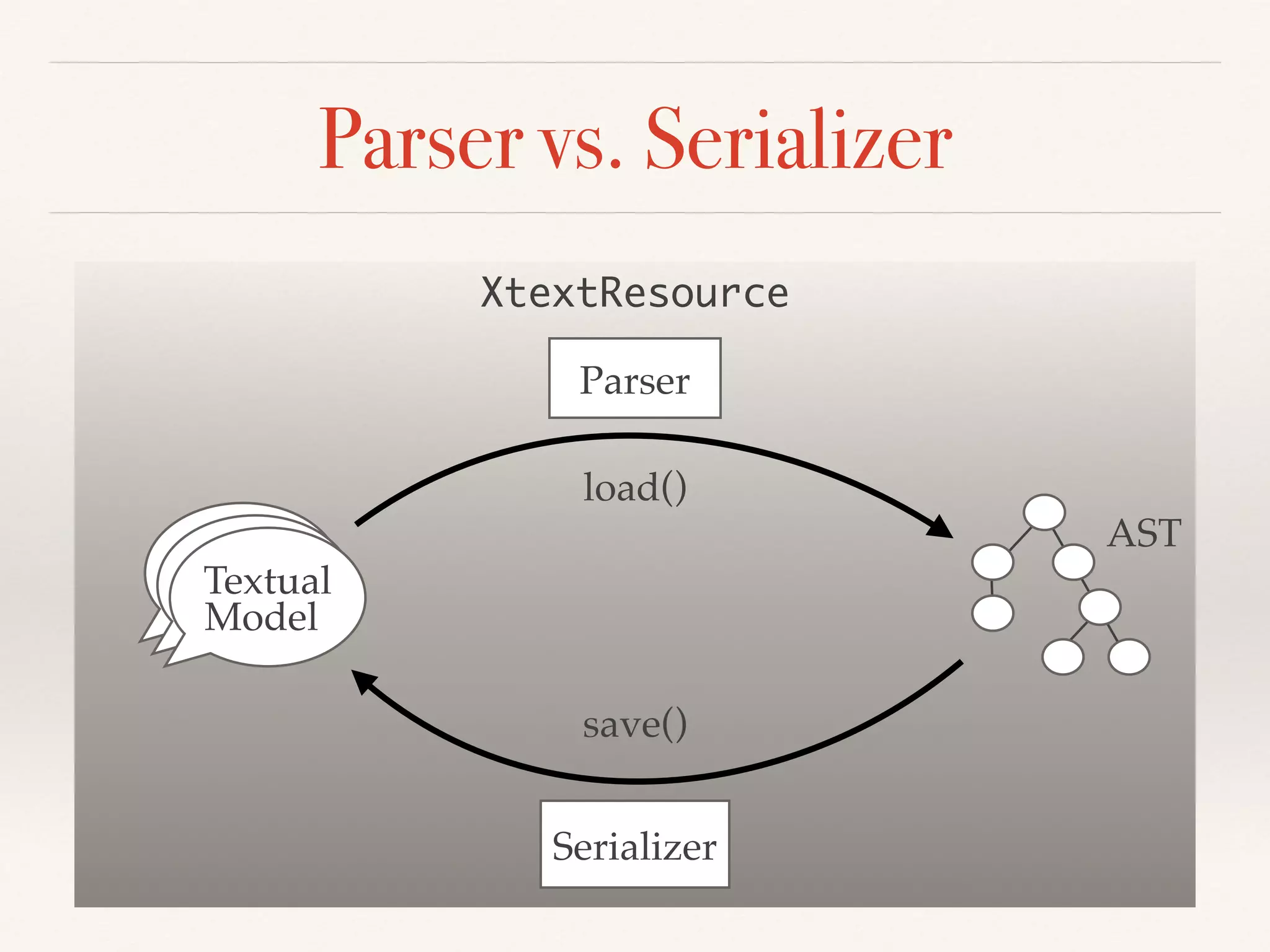
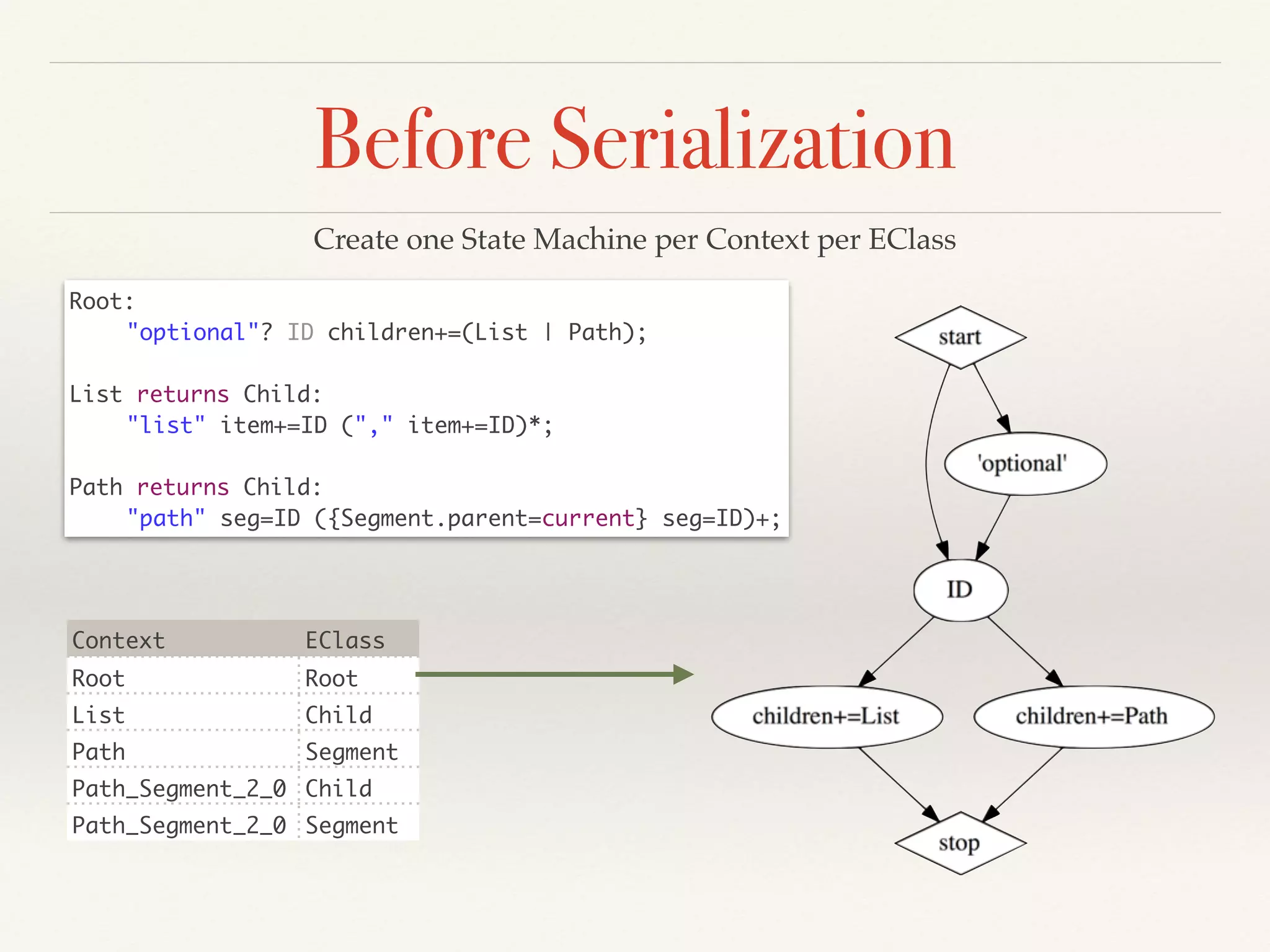
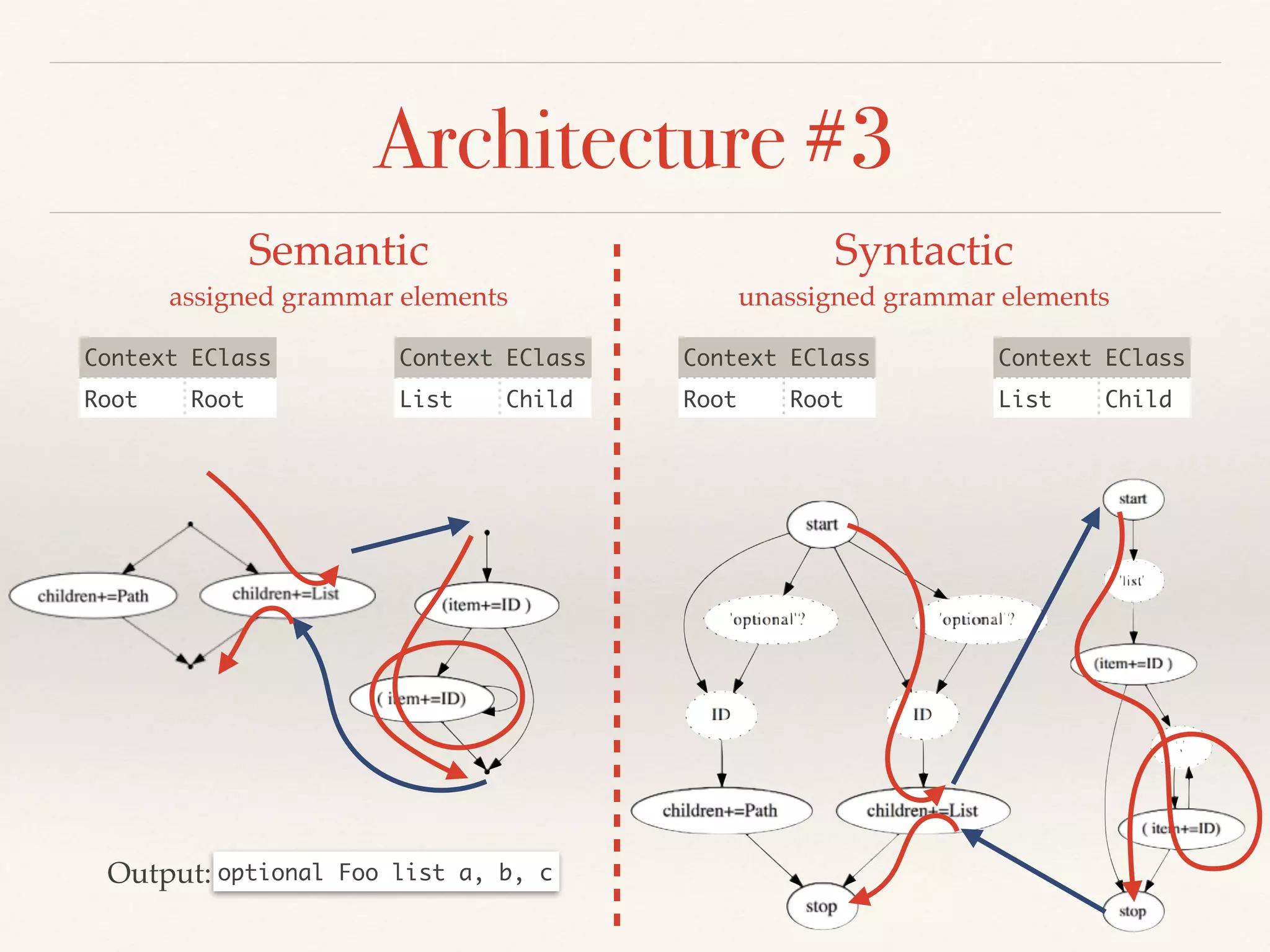
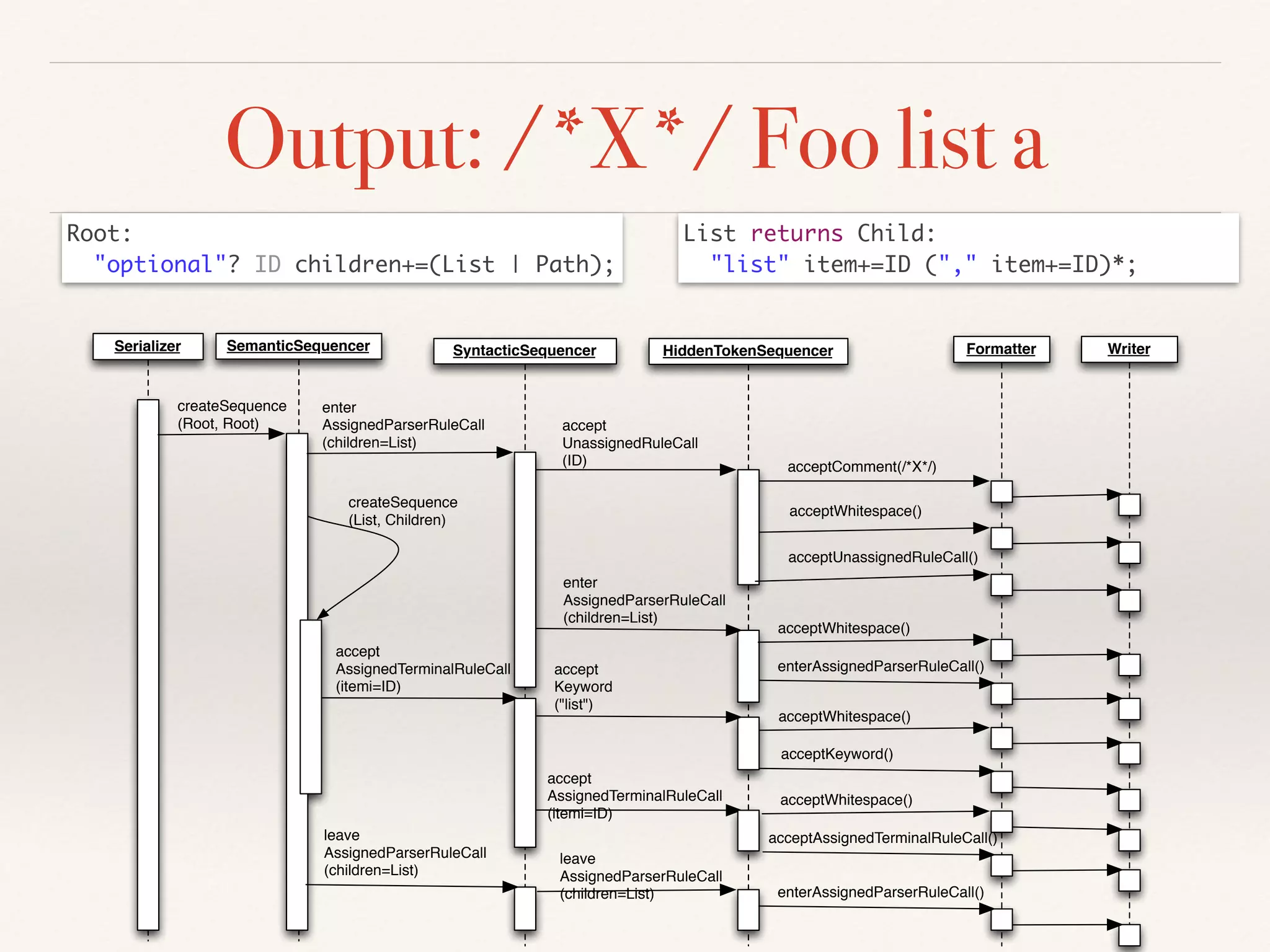
- The serializer must parse a serialized model back to the original, and serialize modifications with minimal textual diffs. Ambiguities can cause parsing/serialization mismatches.
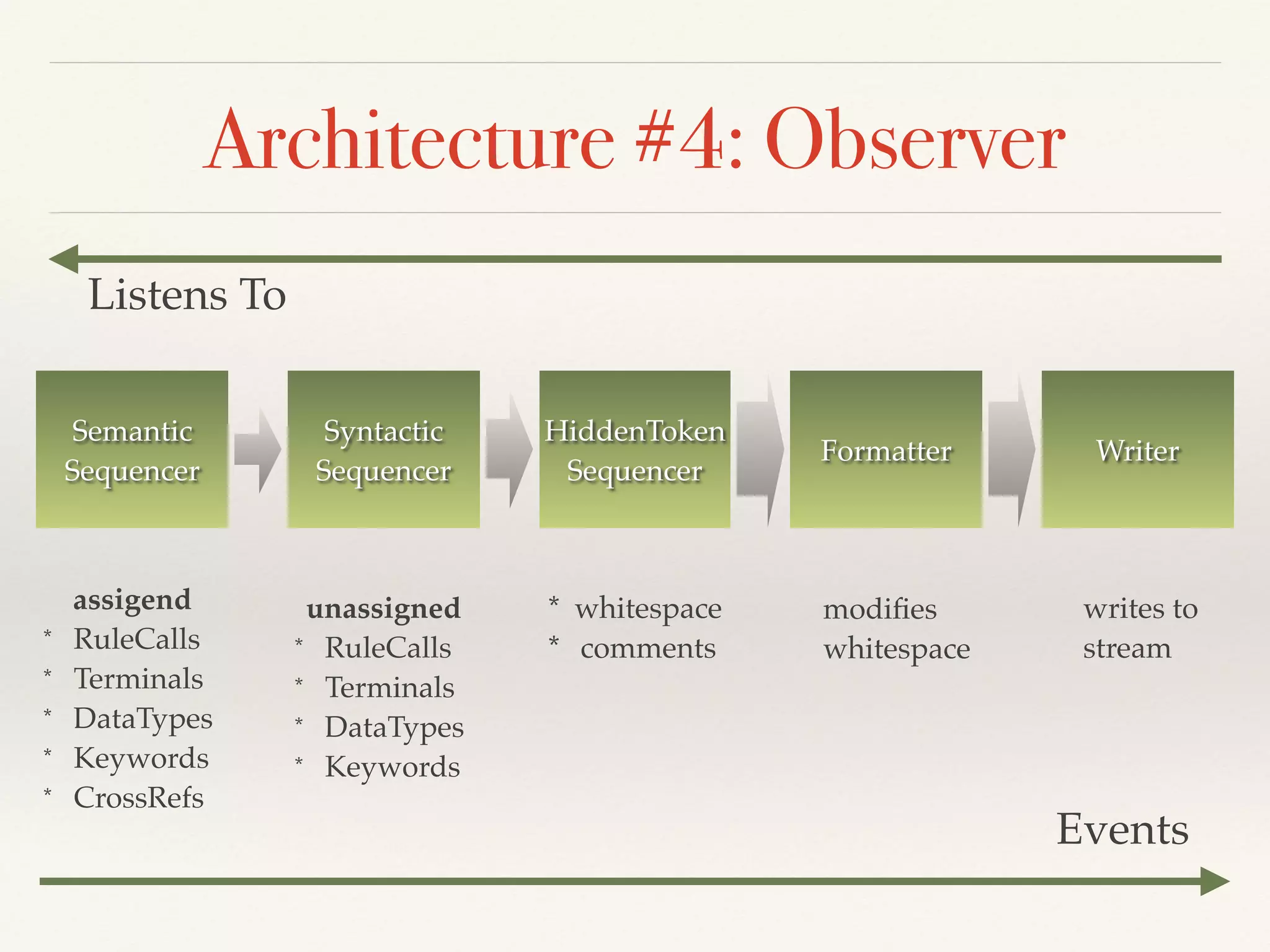
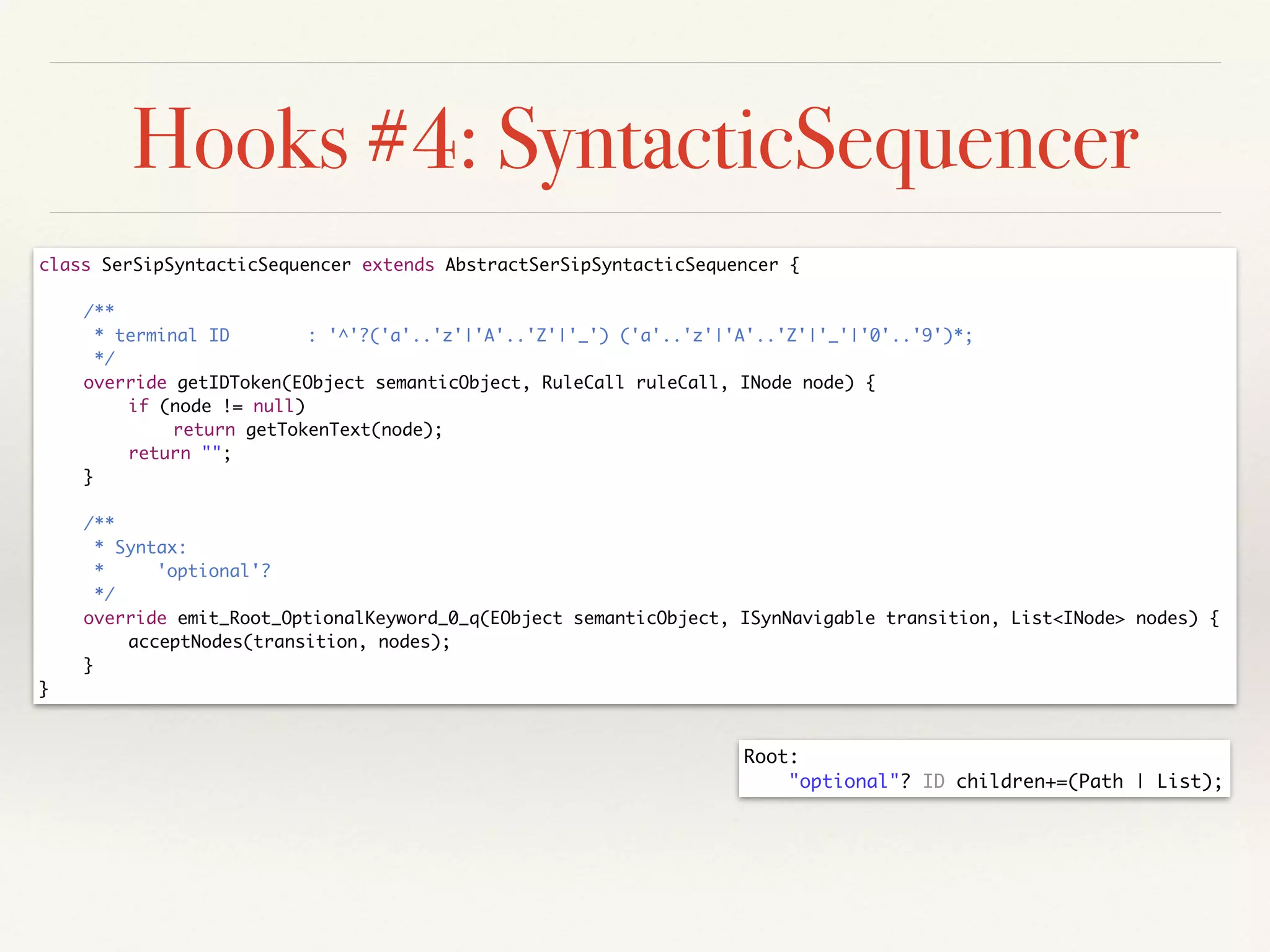
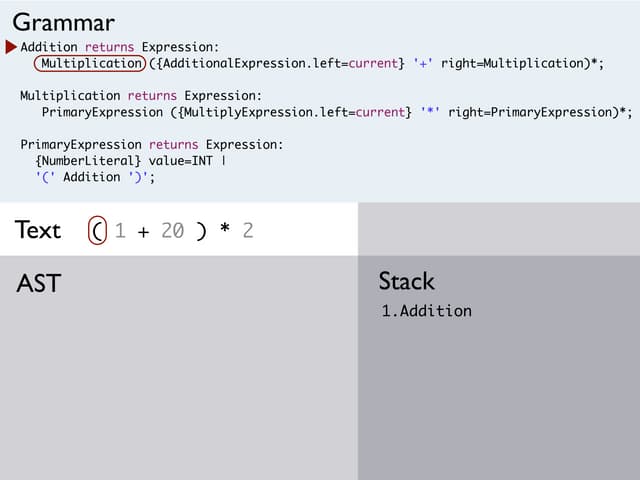
- The architecture uses state machines and observer pattern. Hooks allow customizing cross-references, keywords, values and more during serialization.