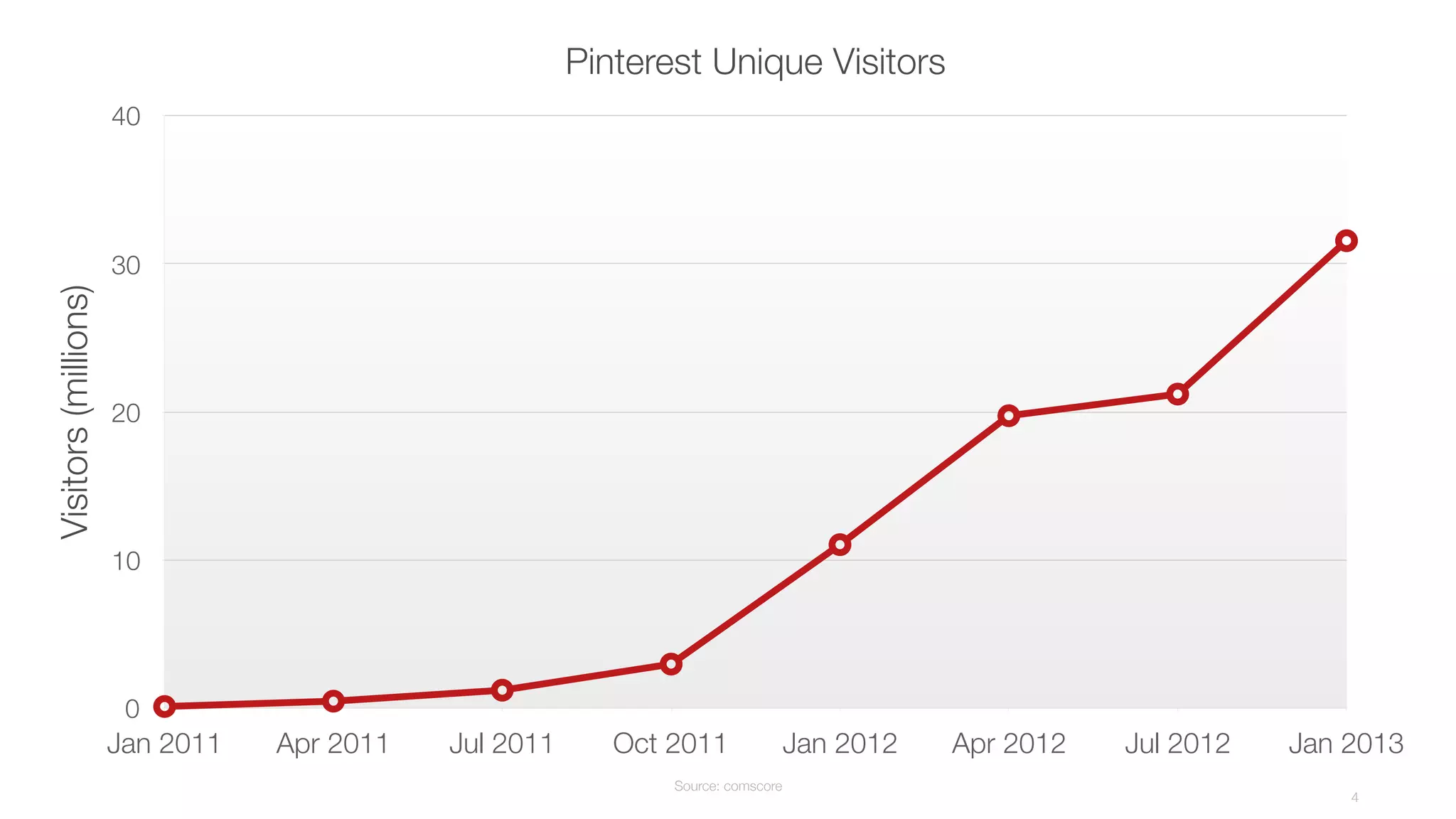
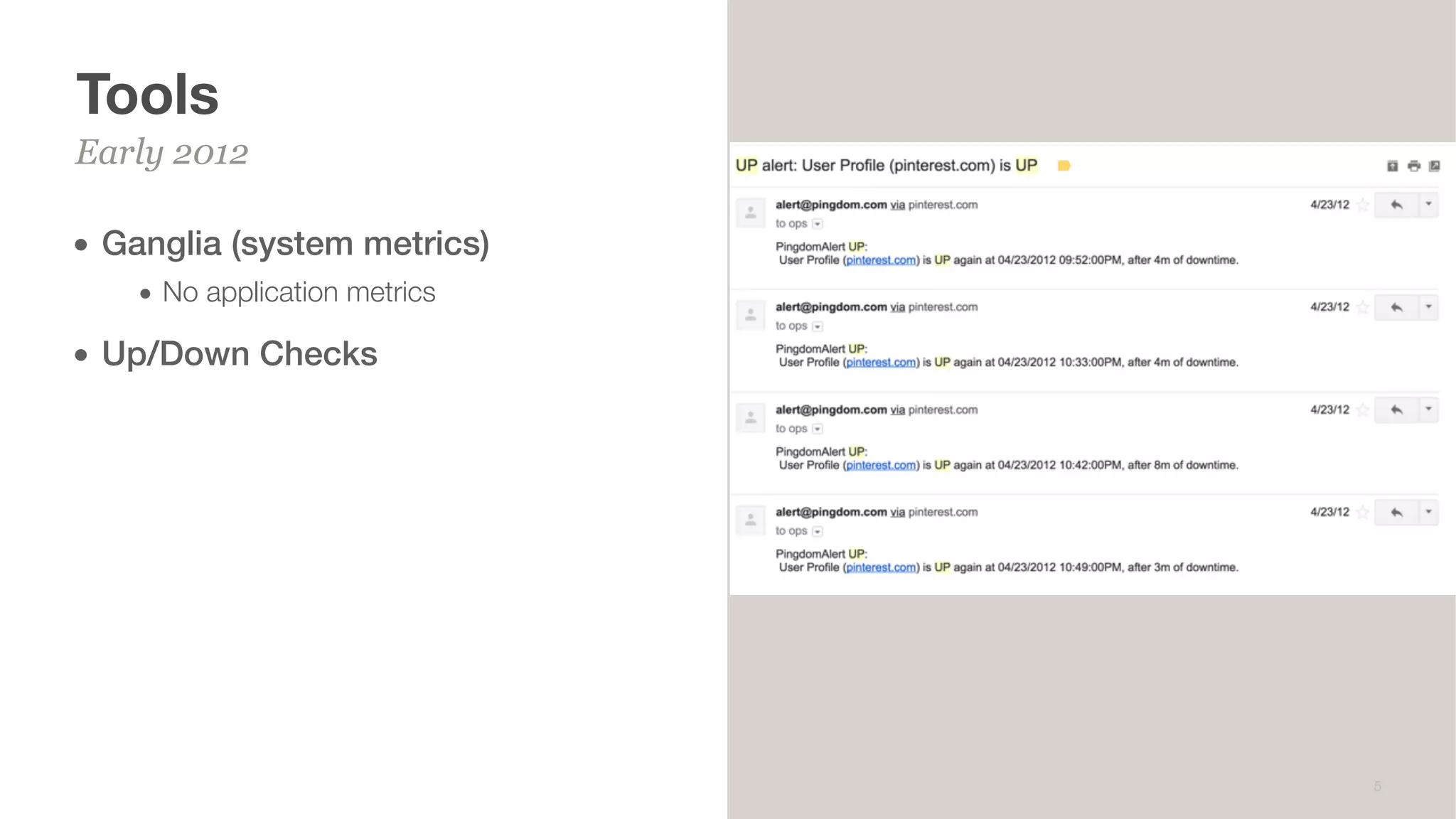
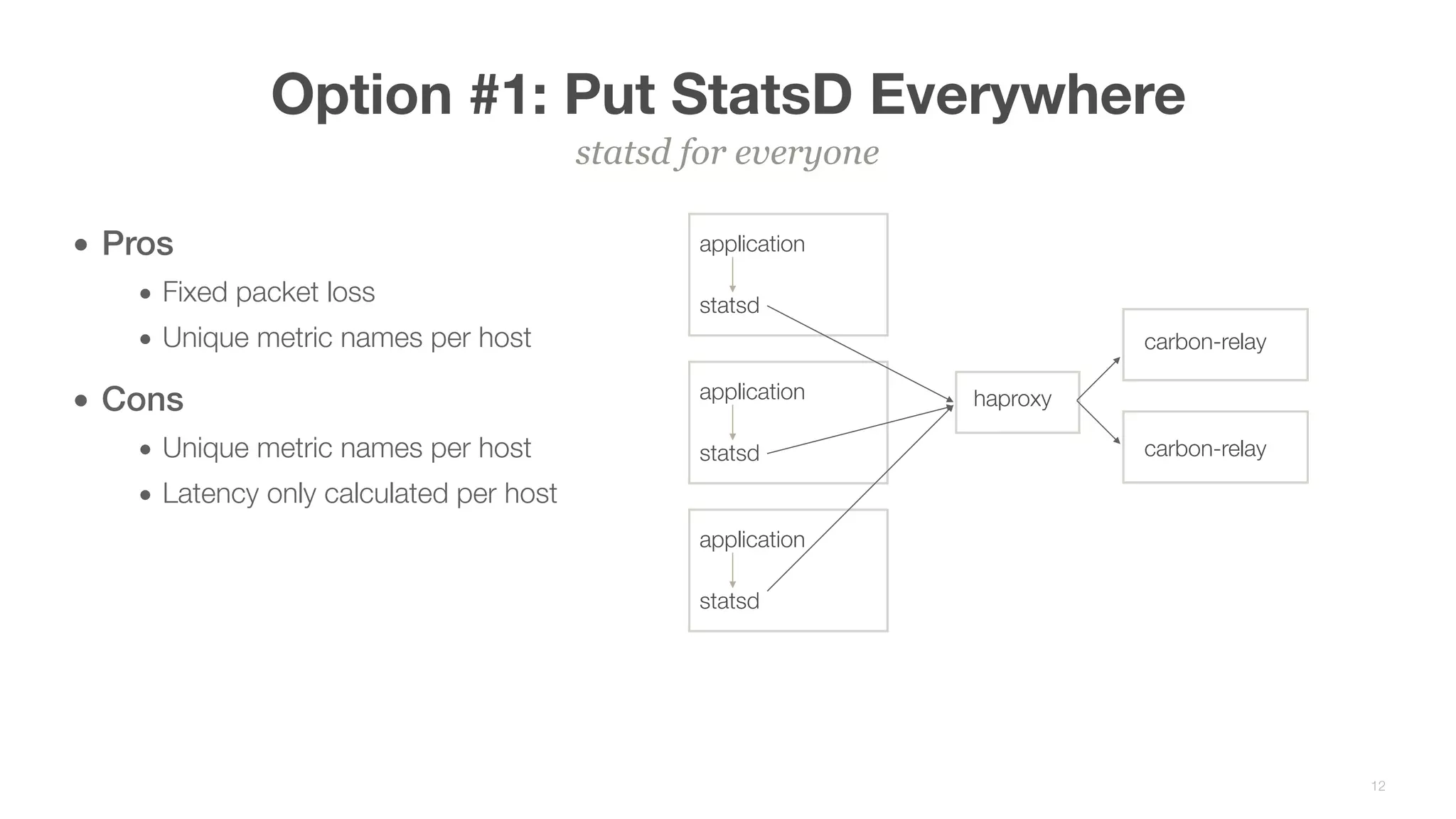
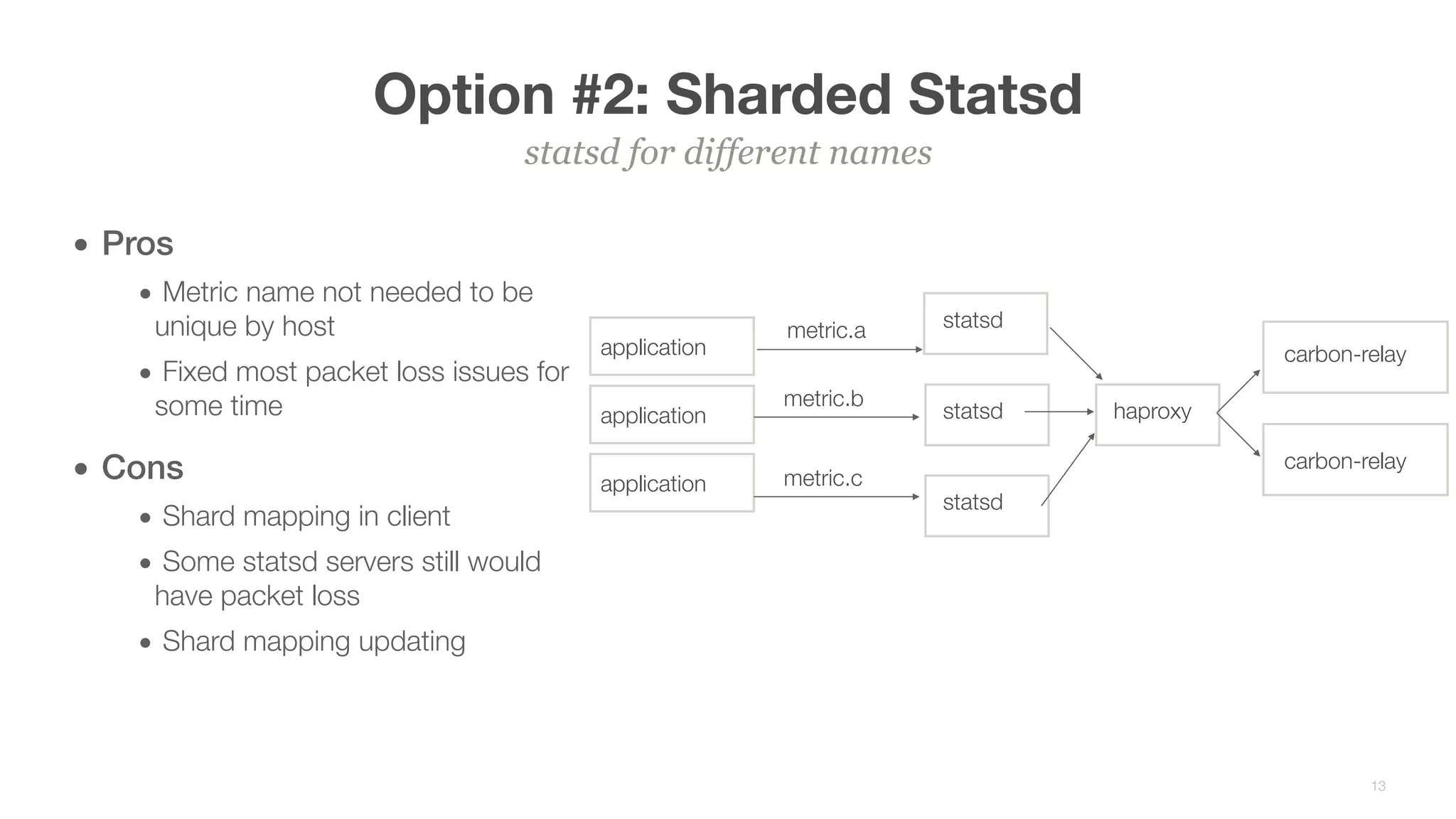
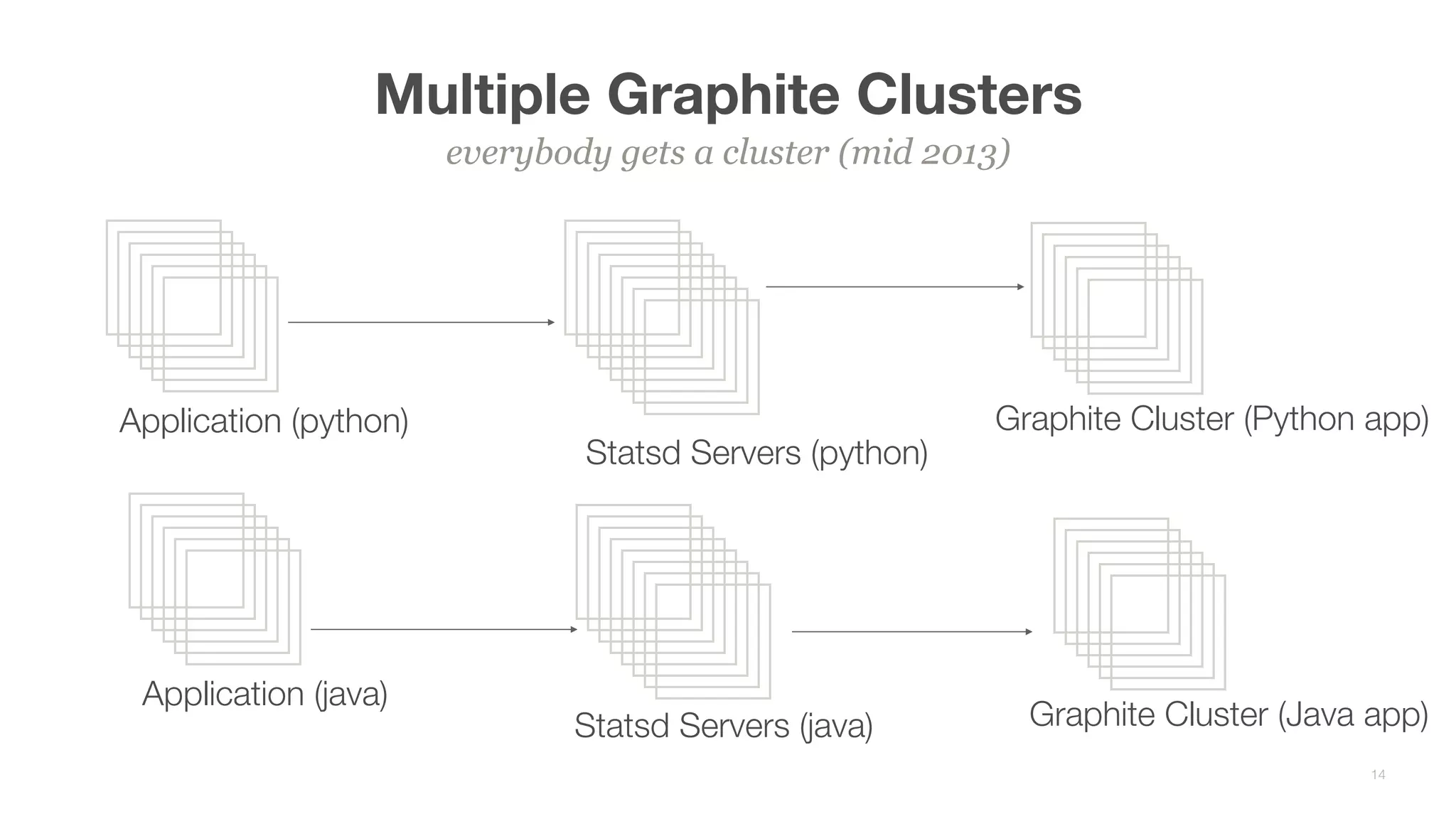
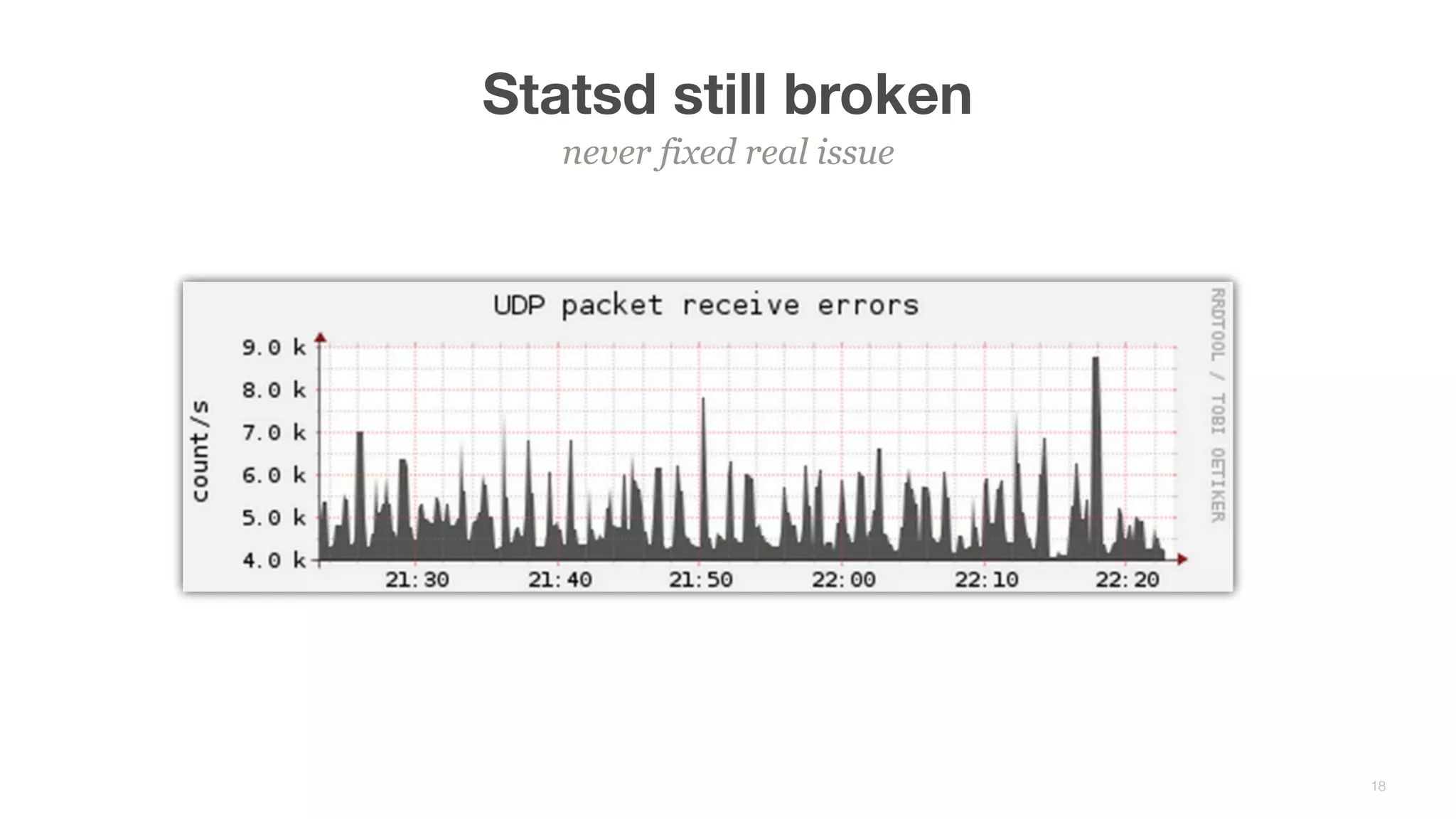
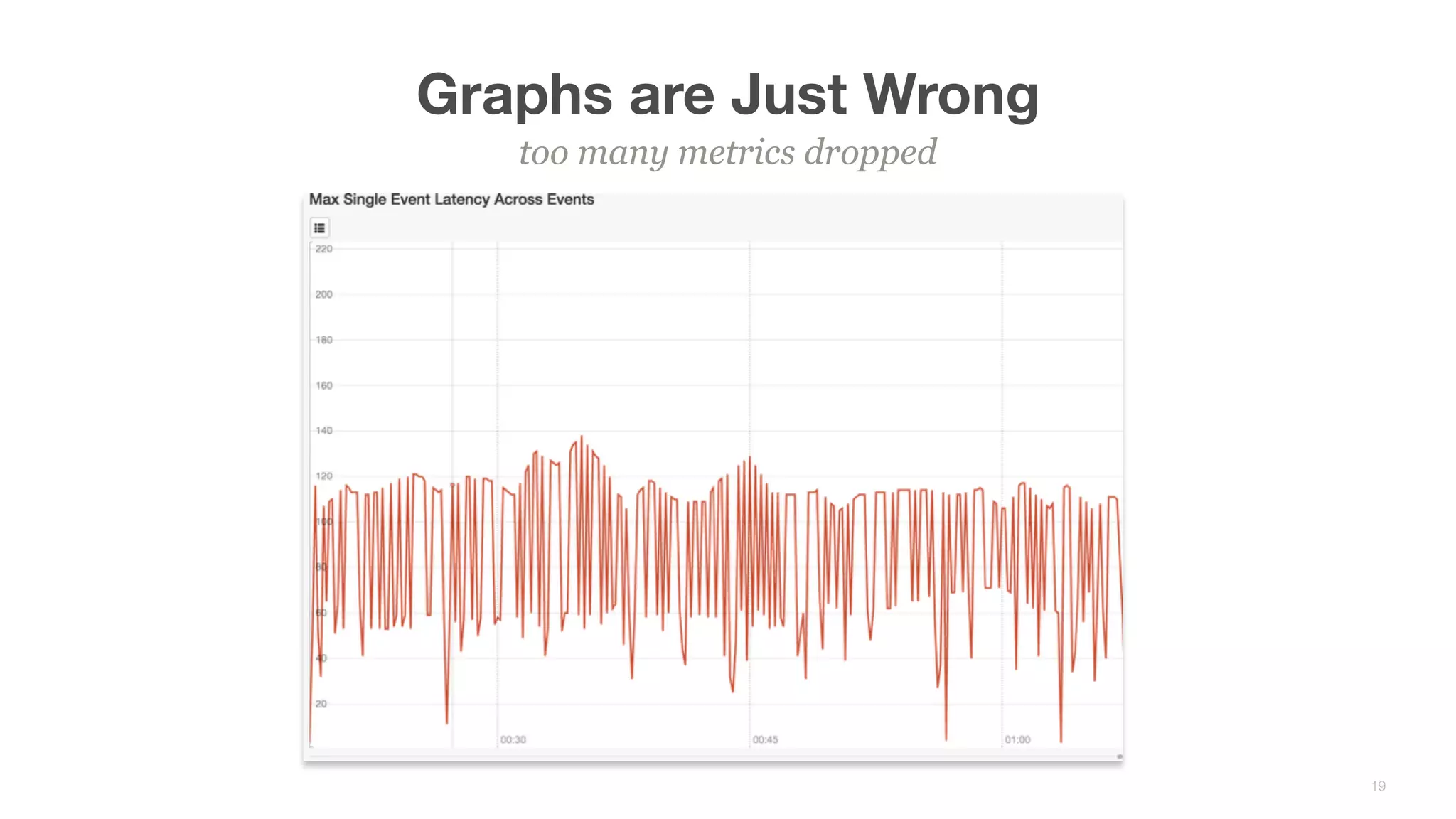
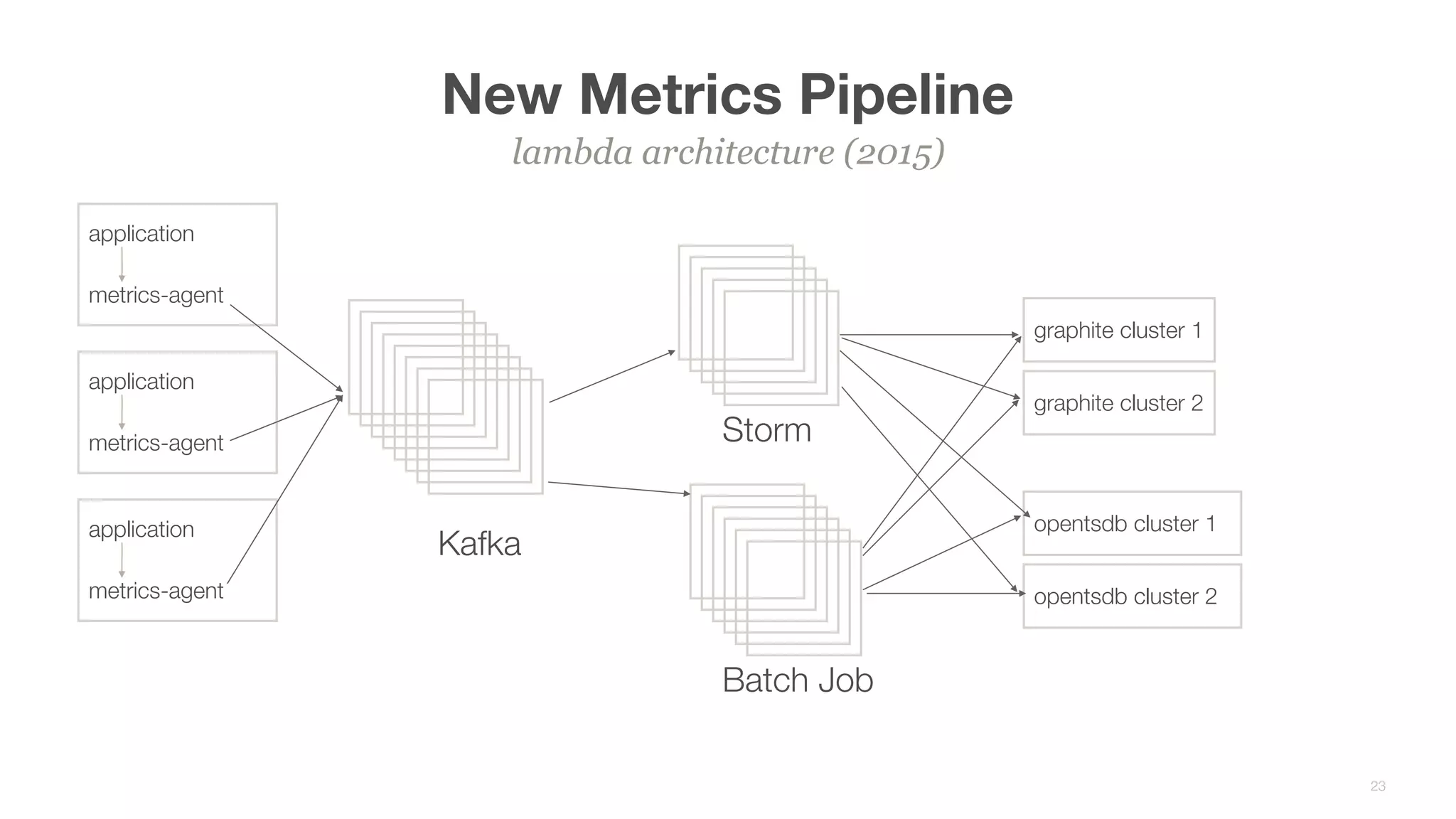
This document summarizes Brian Overstreet's talk on scaling Pinterest's monitoring system over time as the company and traffic grew. It describes how Pinterest started with just Ganglia for system metrics and no application metrics. They introduced Graphite but faced challenges with packet loss and metrics being dropped. They then introduced OpenTSDB which users were happier with due to its querying speed. Pinterest developed an agent-based pipeline using Kafka and Storm to address packet loss issues and allow over 1.5 million points per second to be ingested by OpenTSDB. Key lessons included the need to educate users, control incoming metrics, and ensure the monitoring system scales with engineers rather than just site users.





















































































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

