Downloaded 10 times




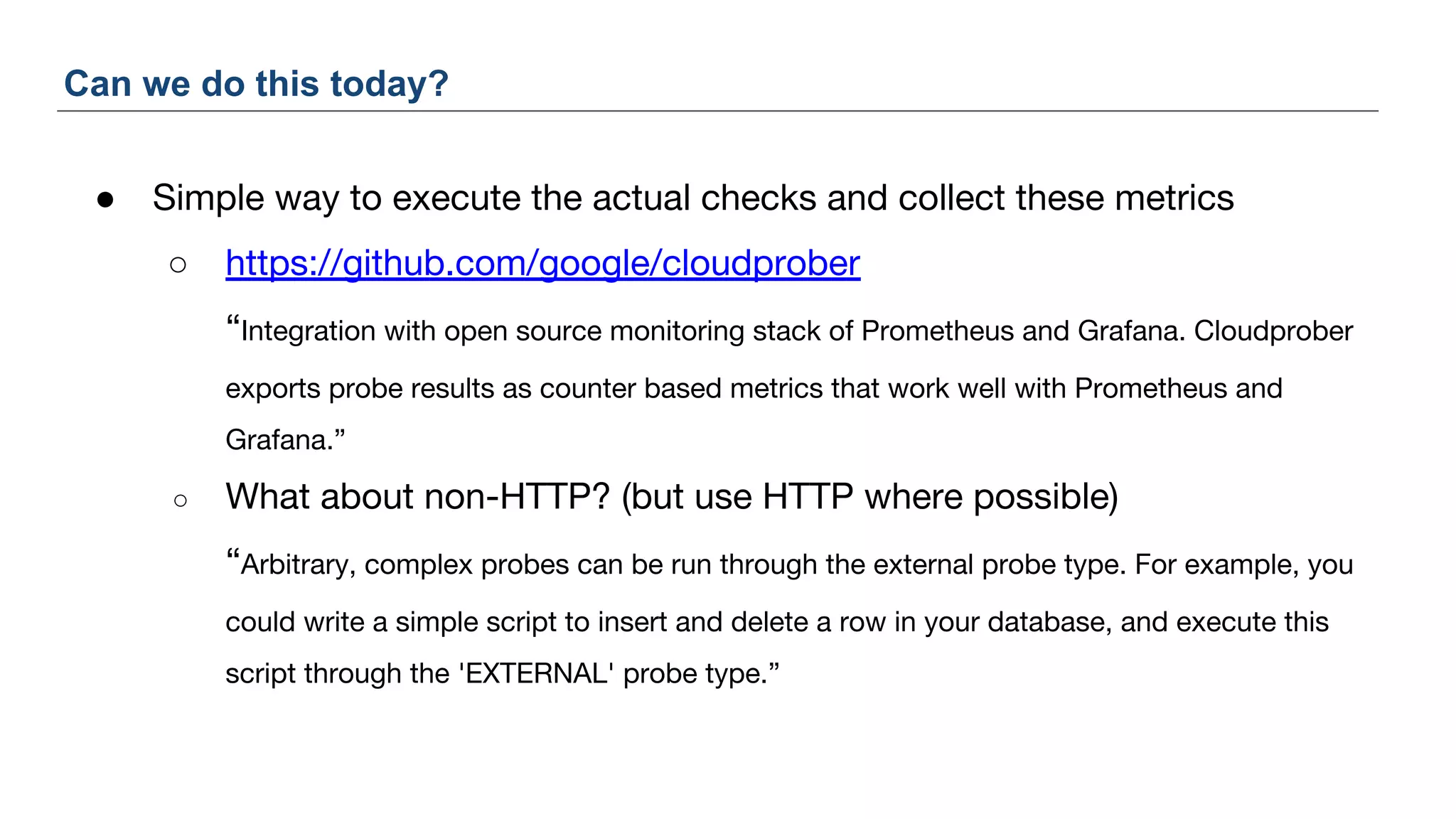
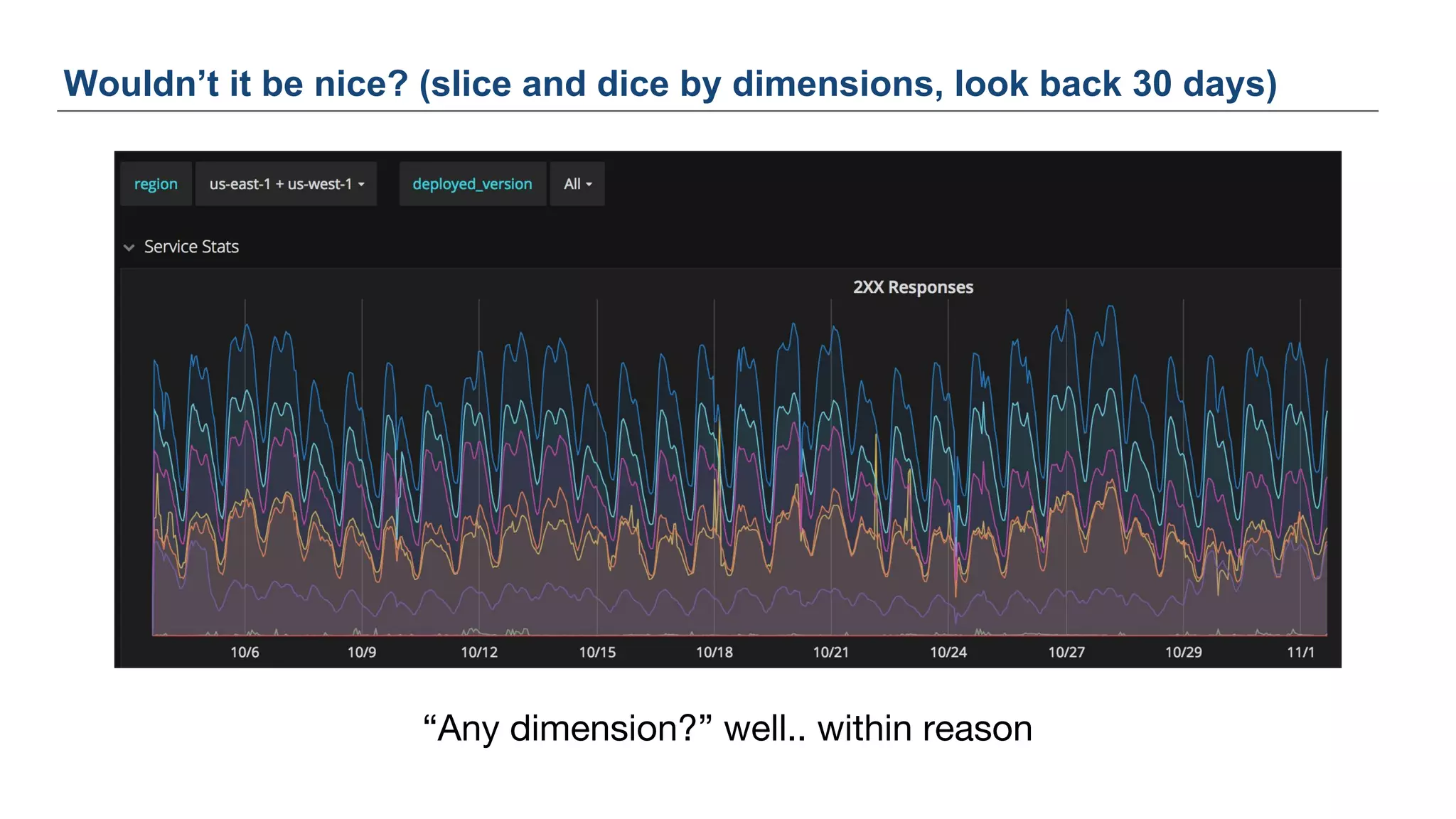

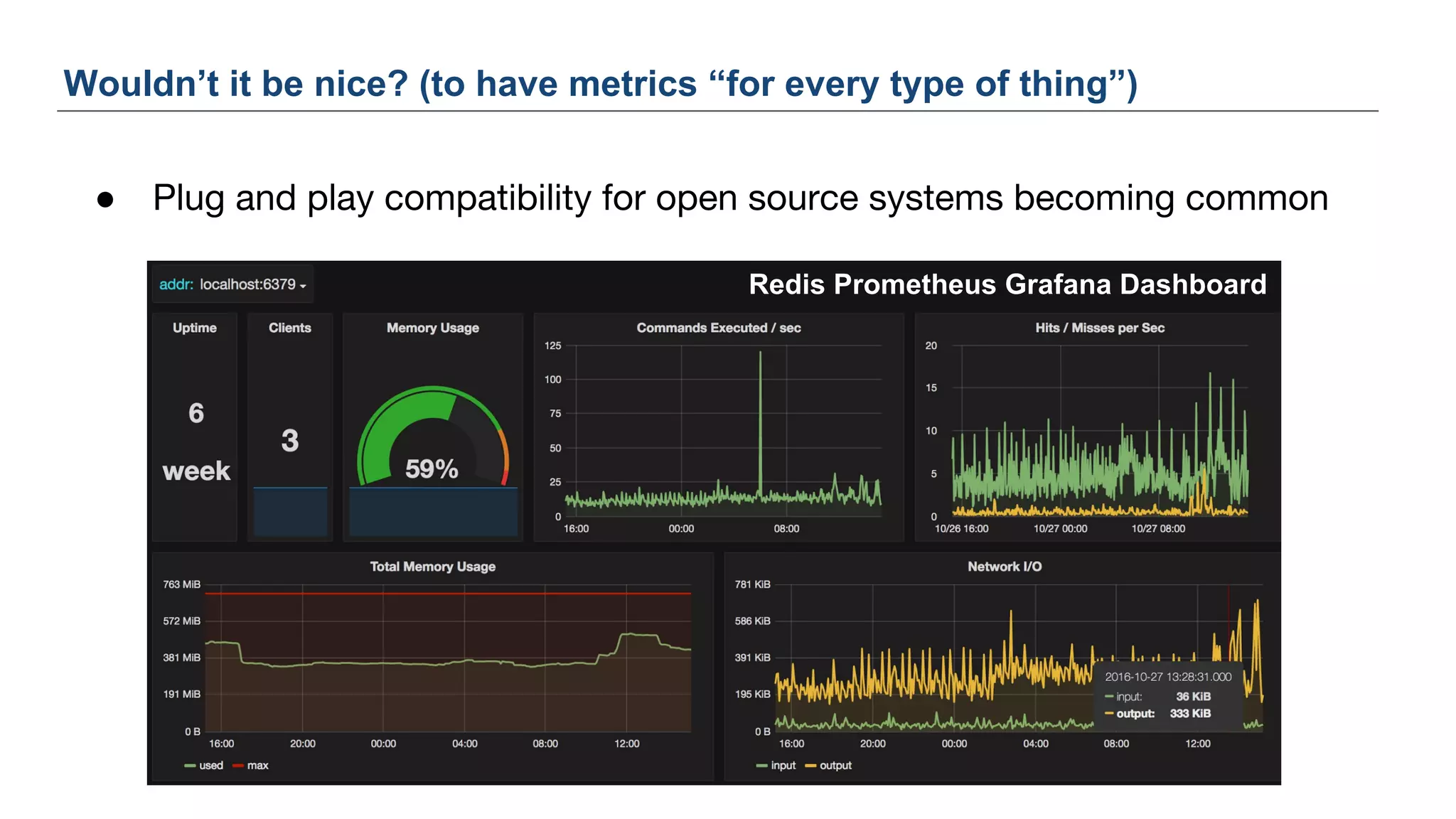

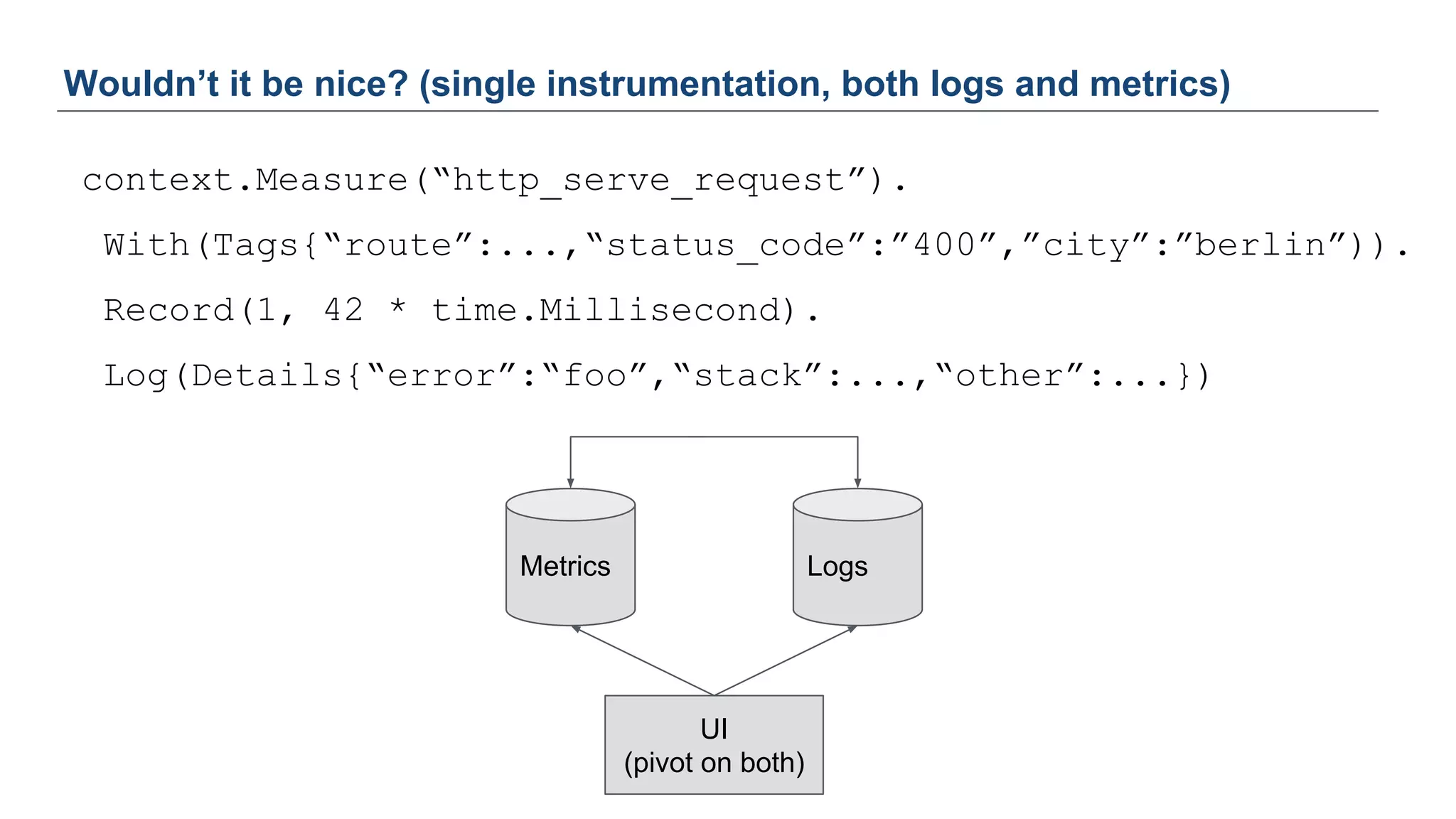
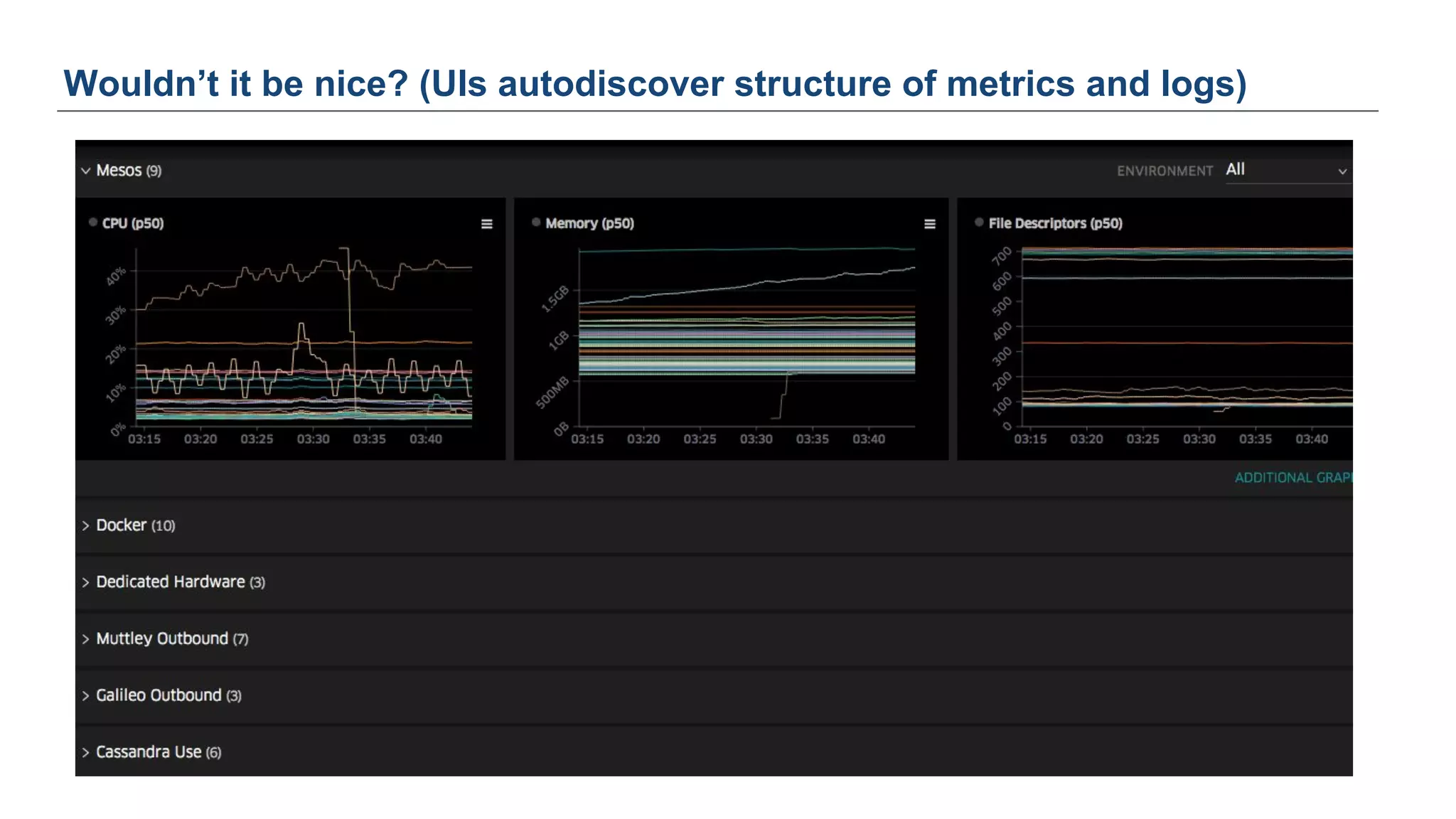












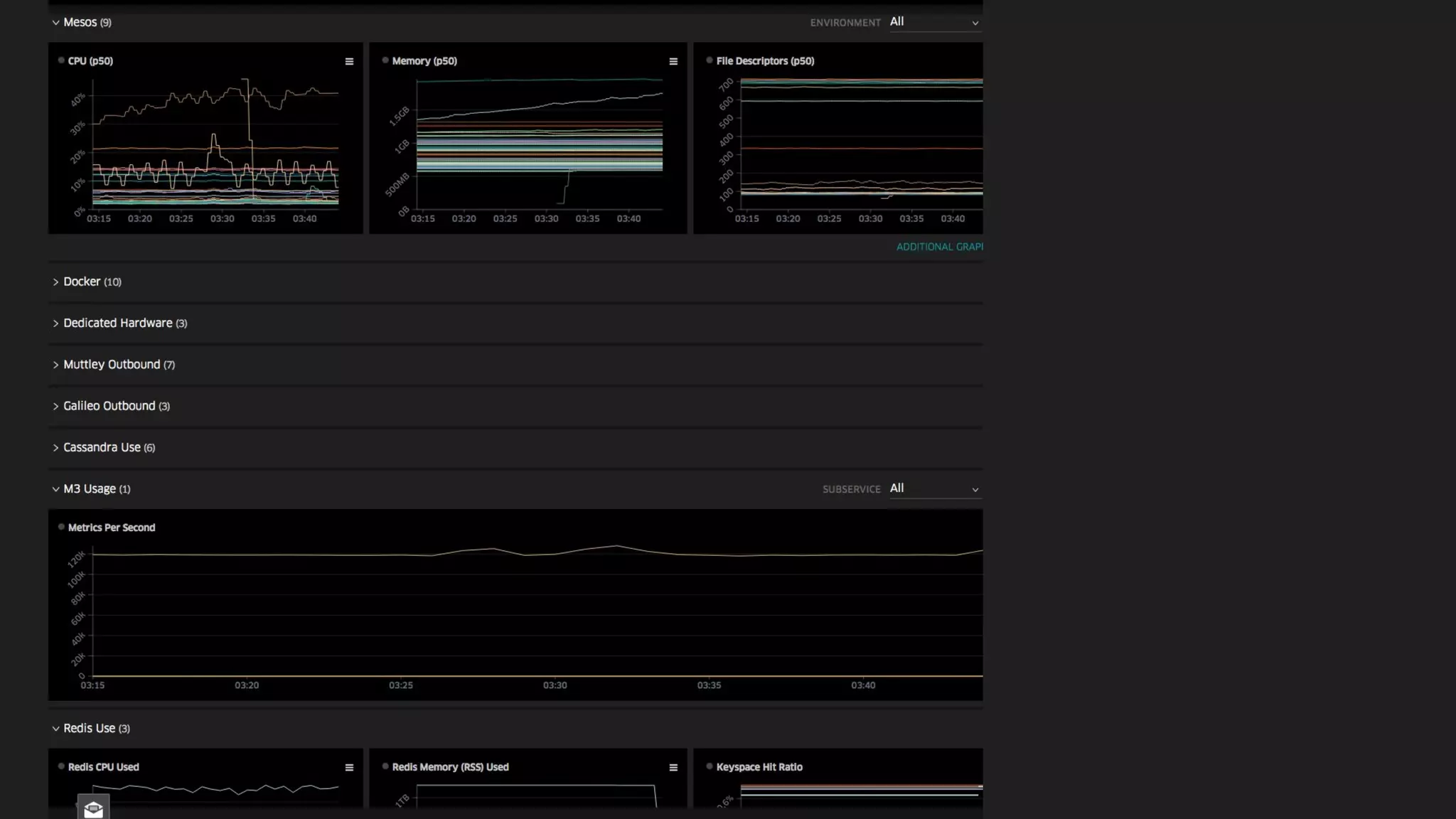
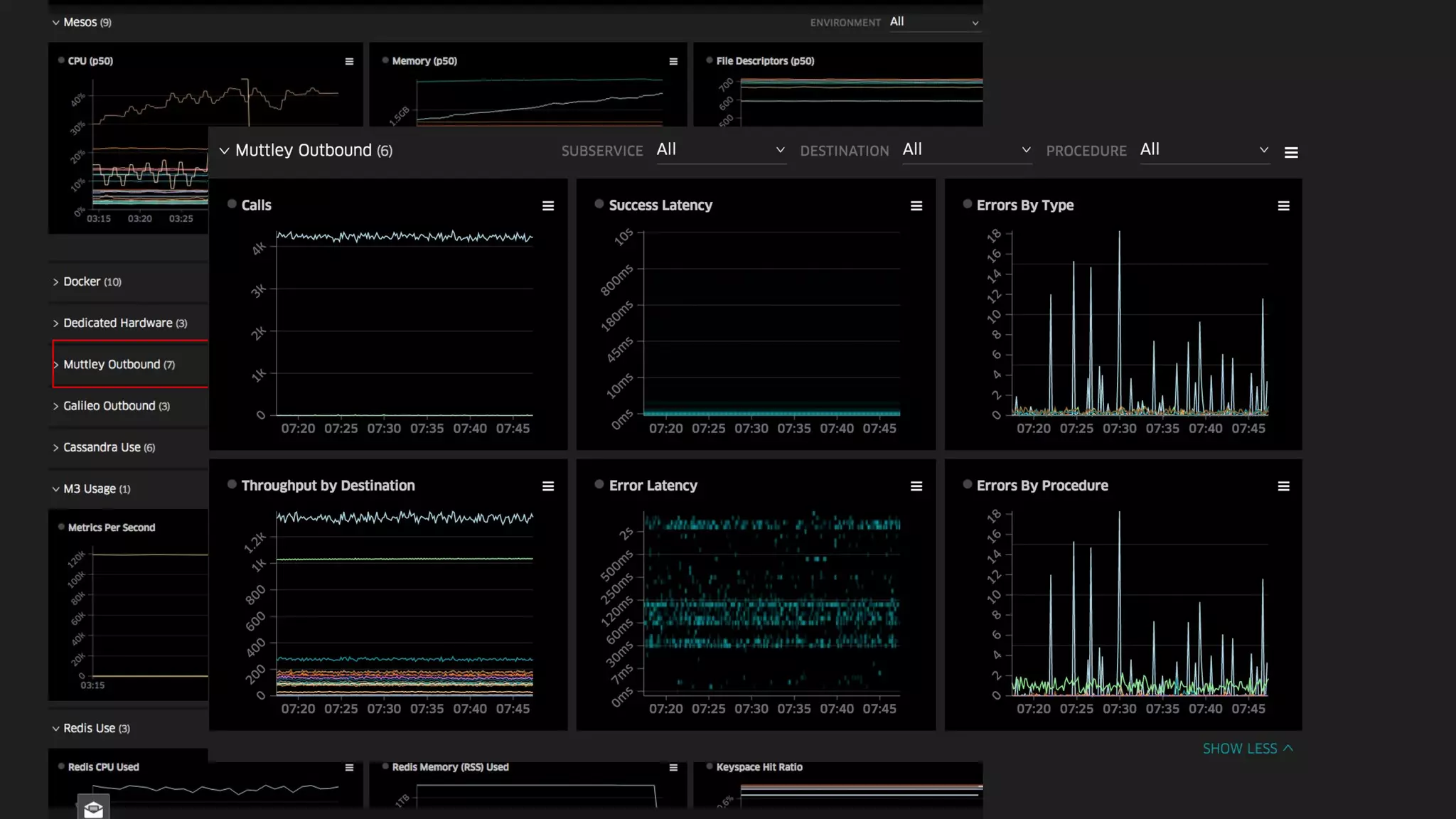
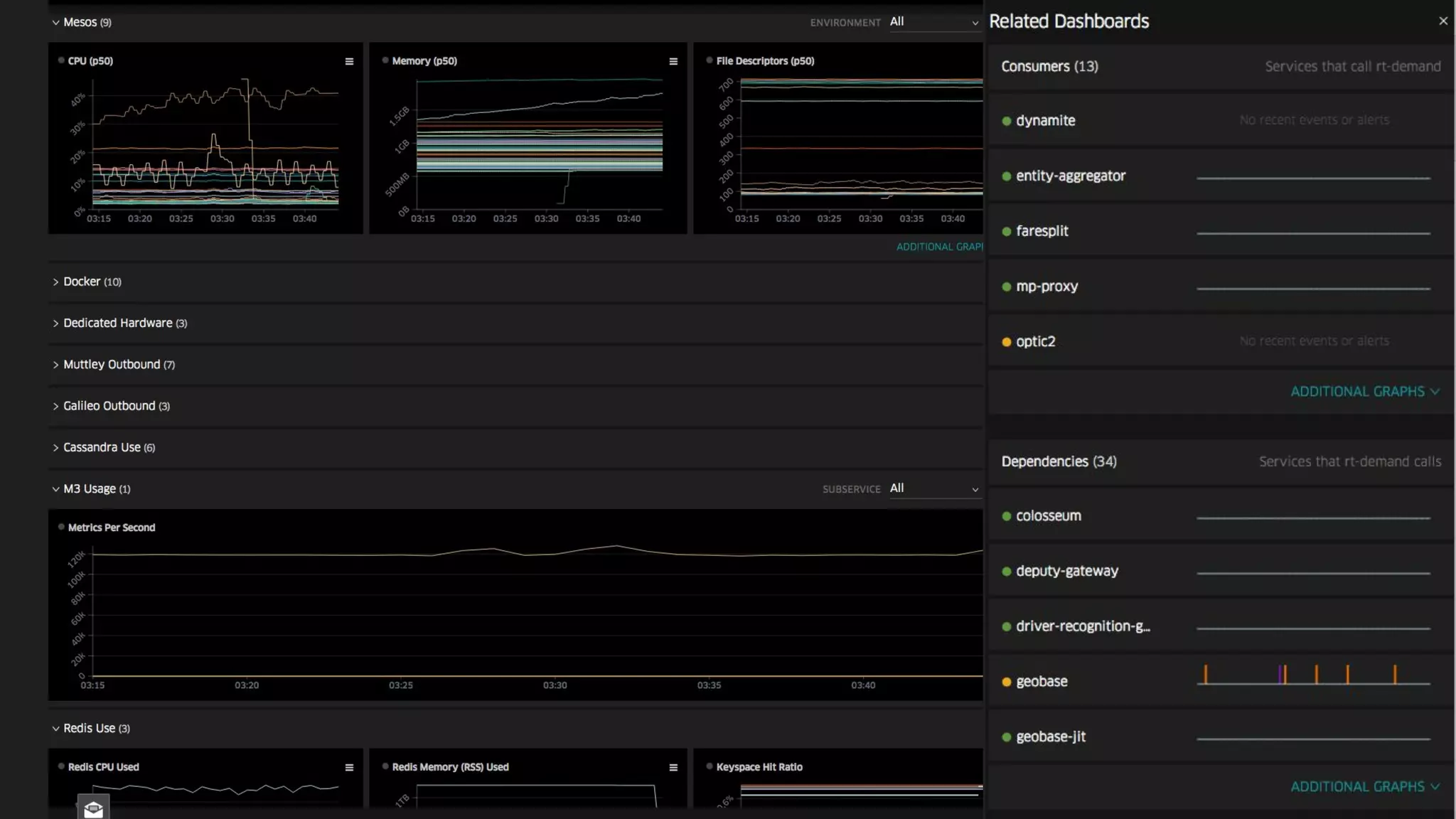

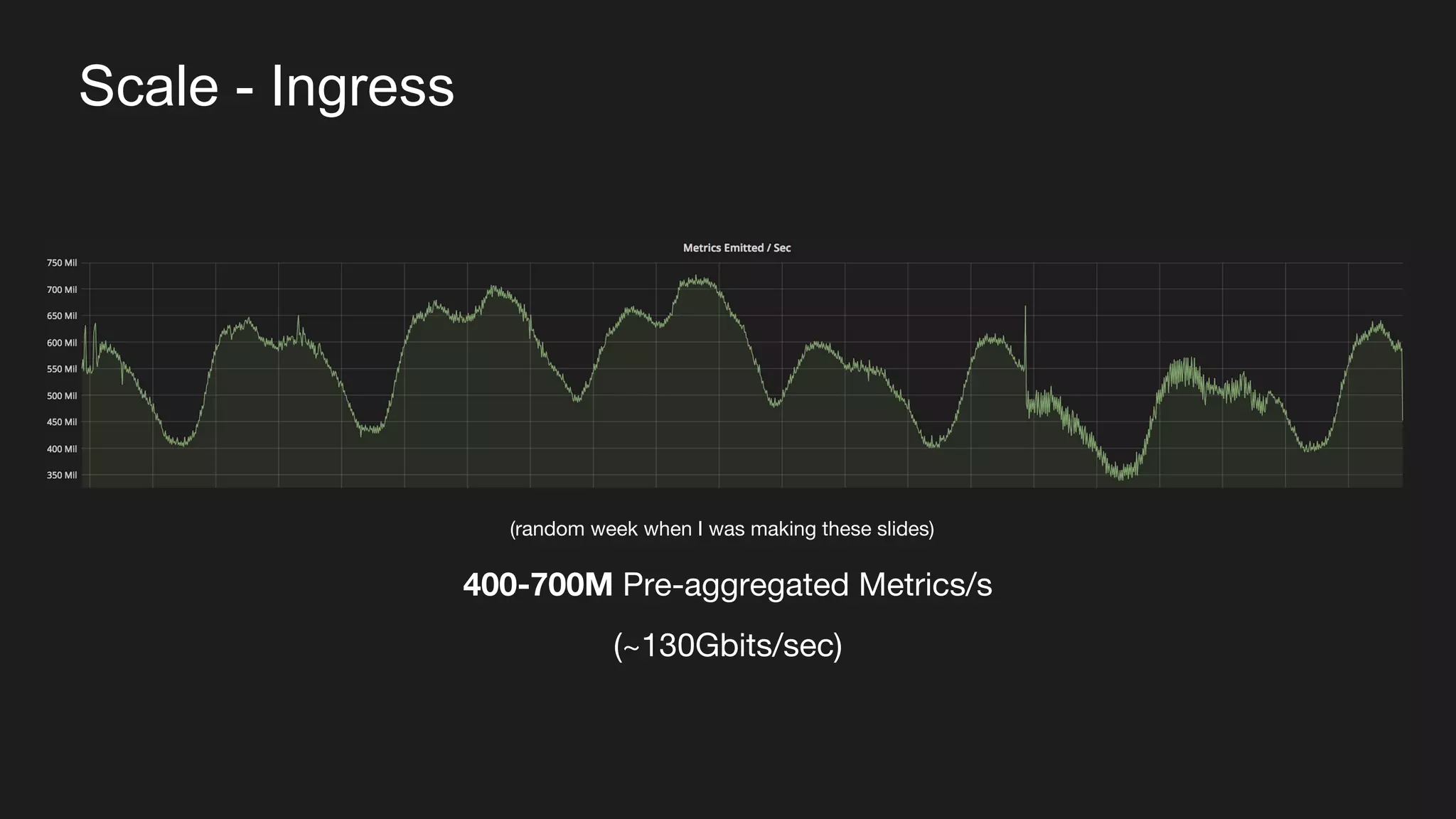
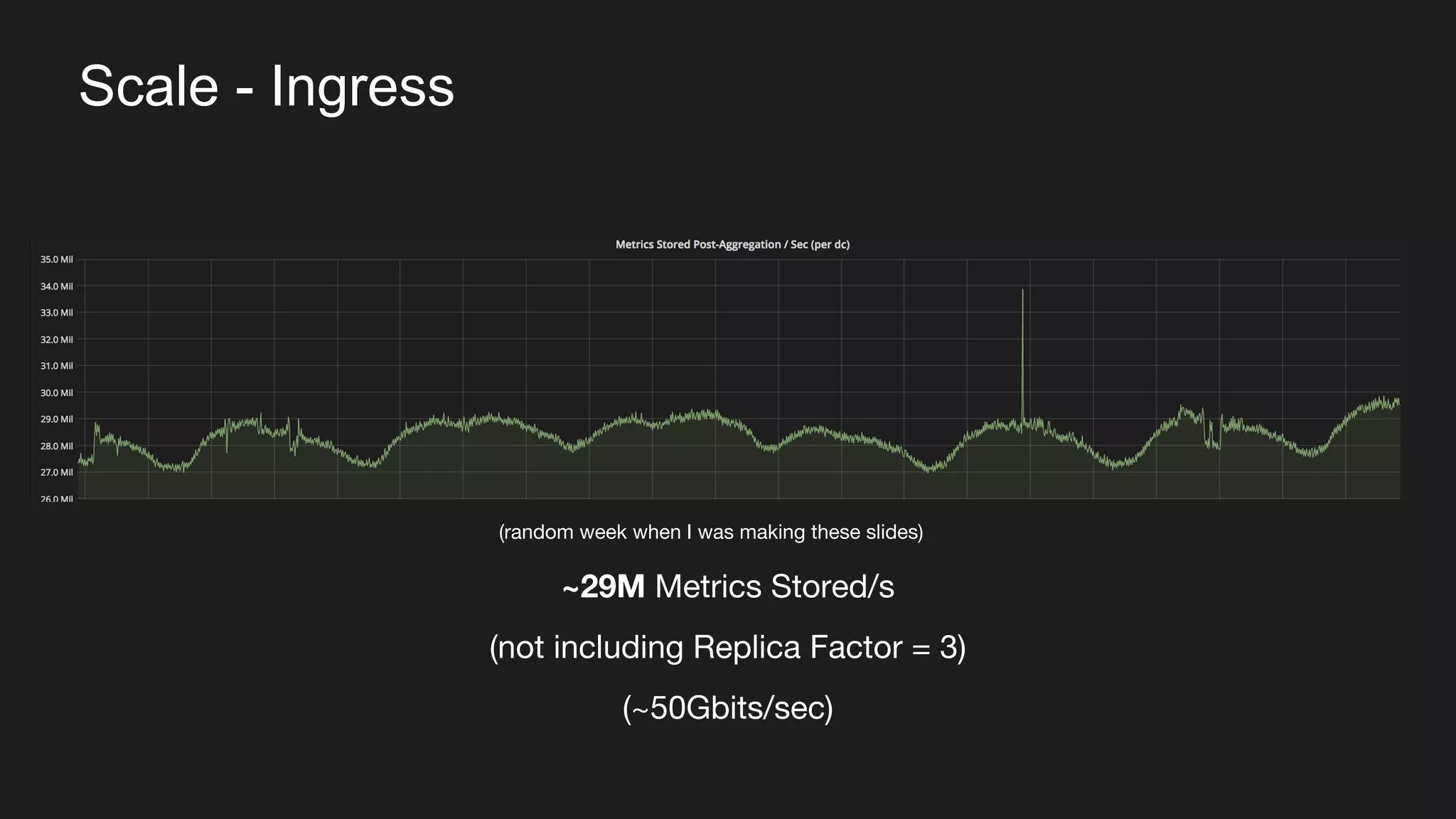
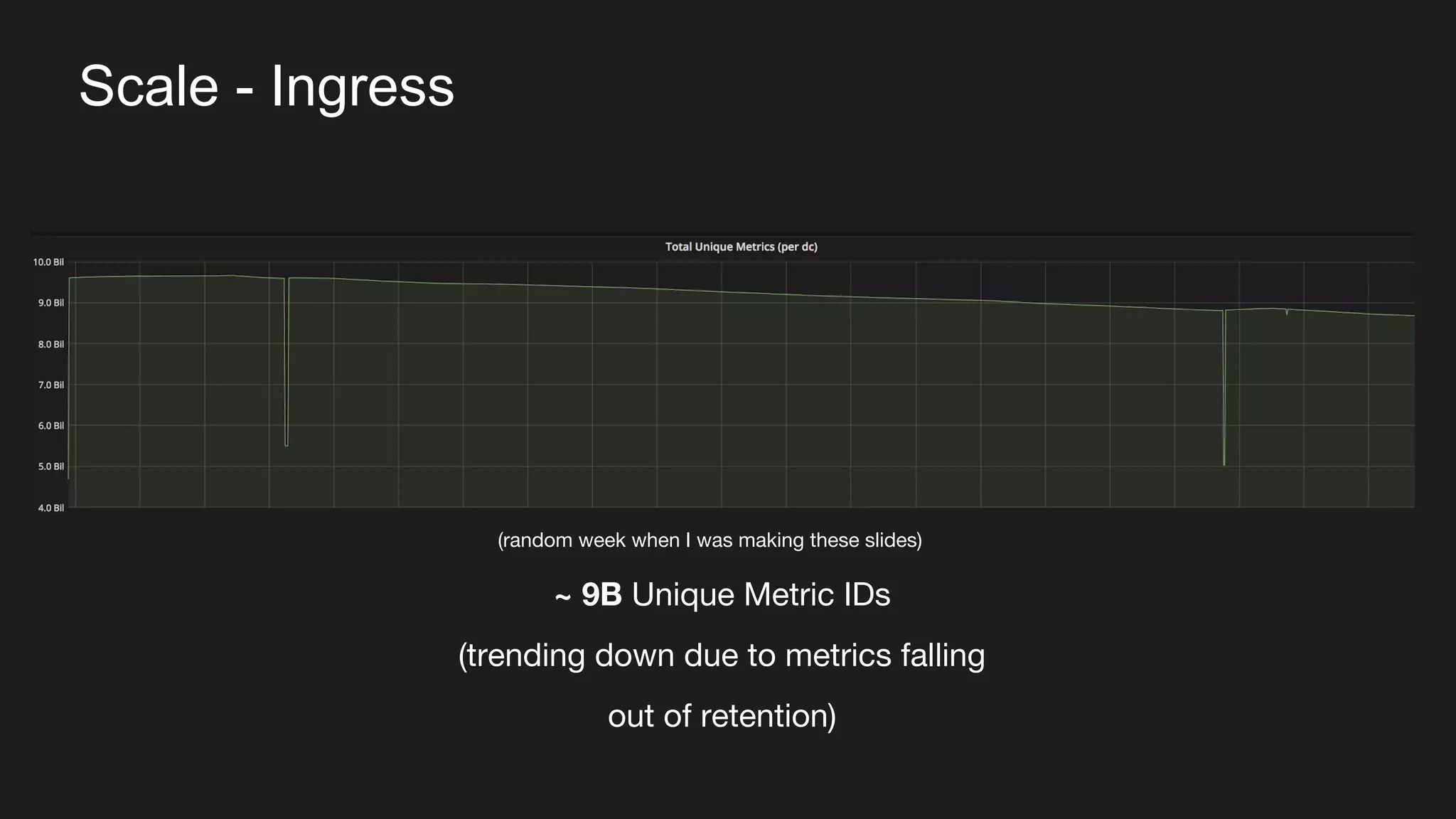
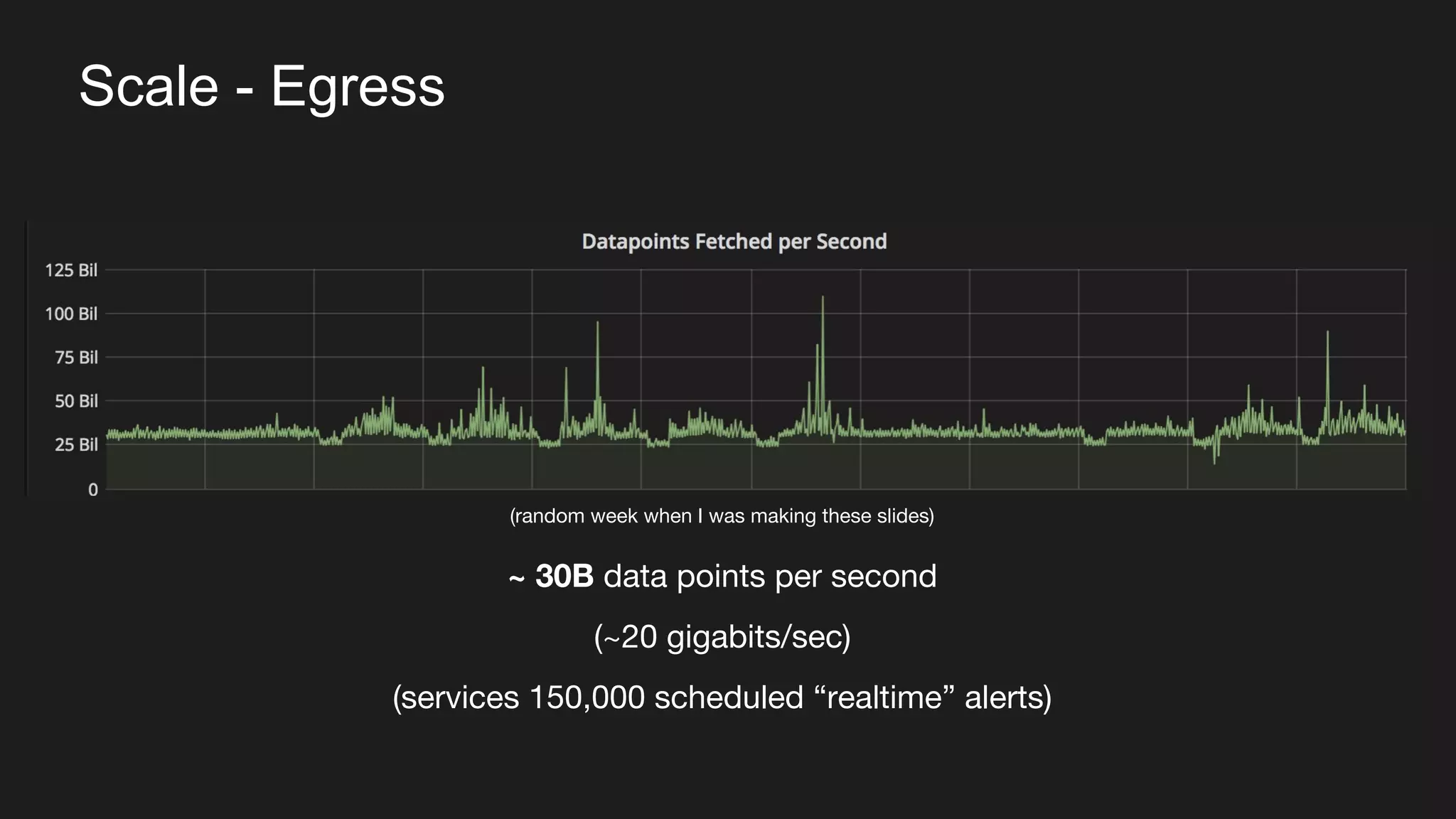




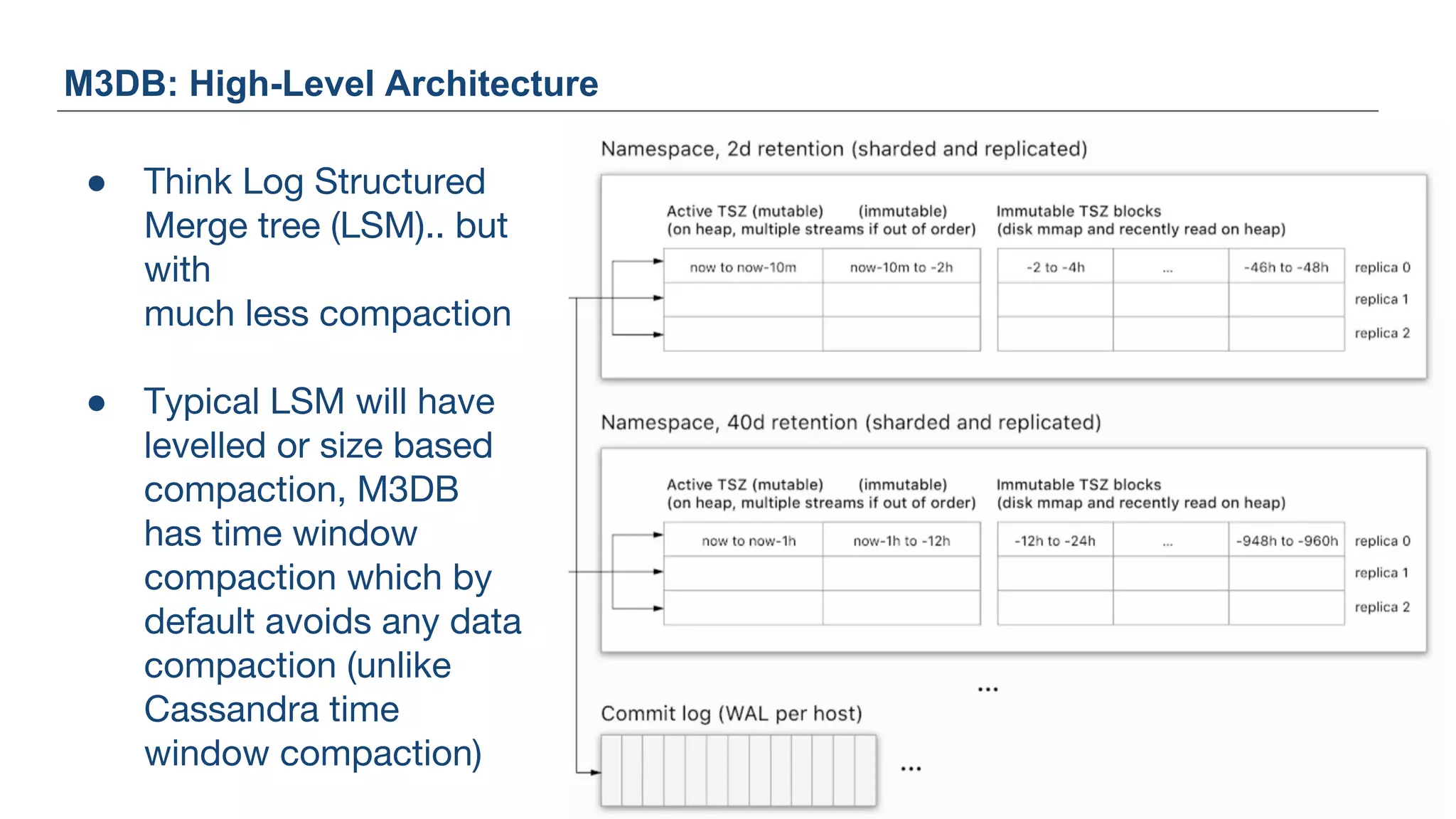



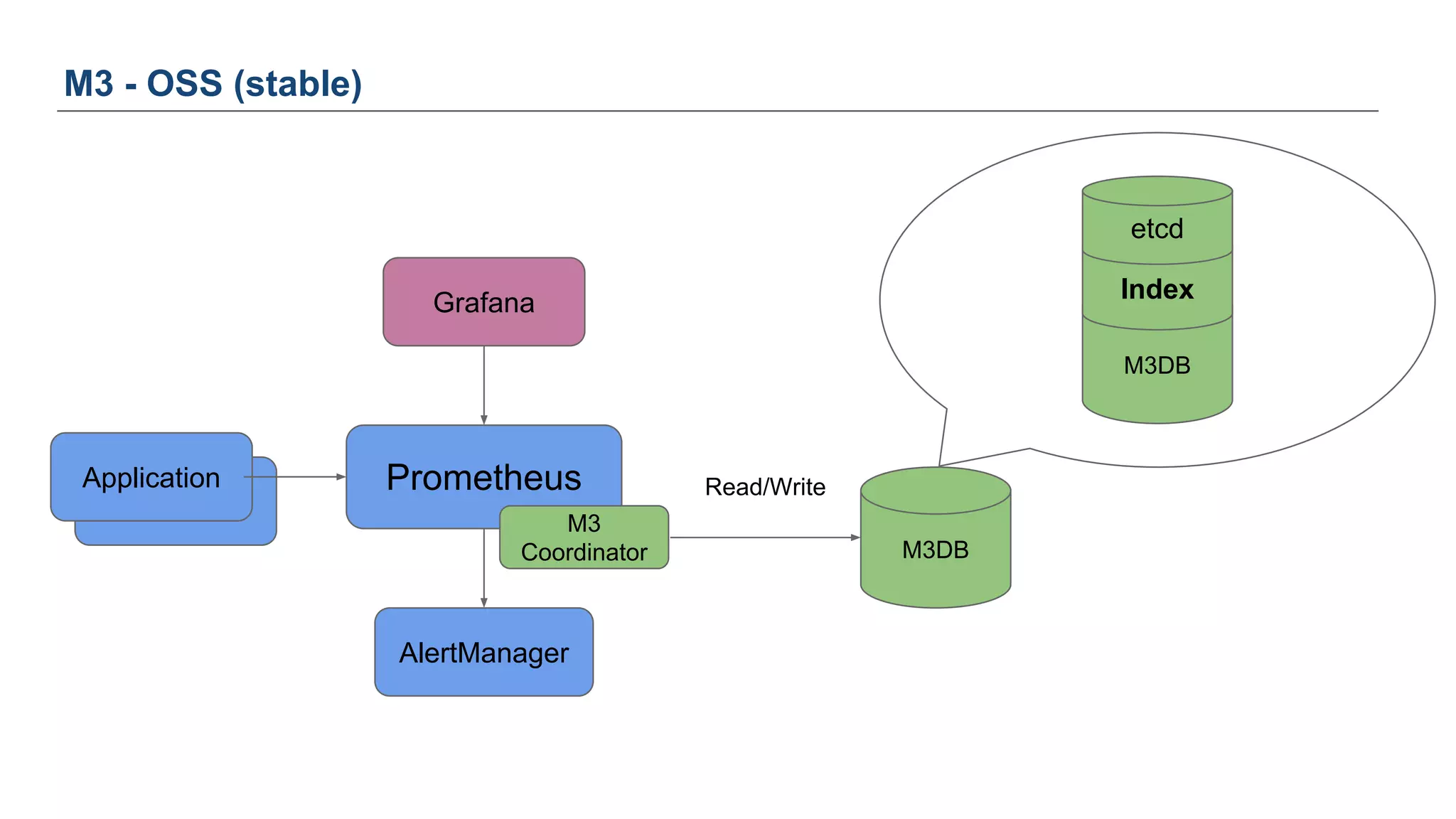
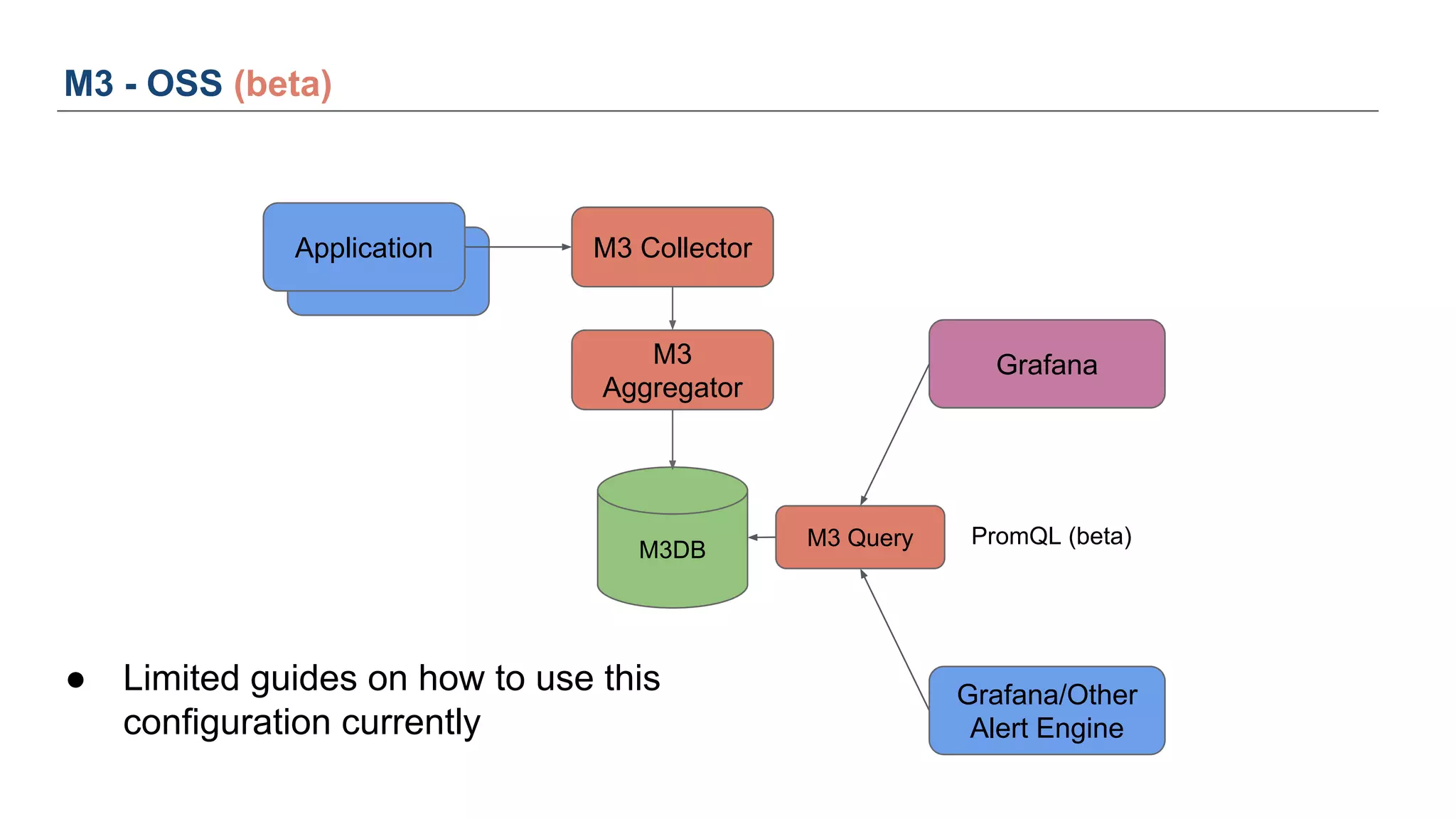
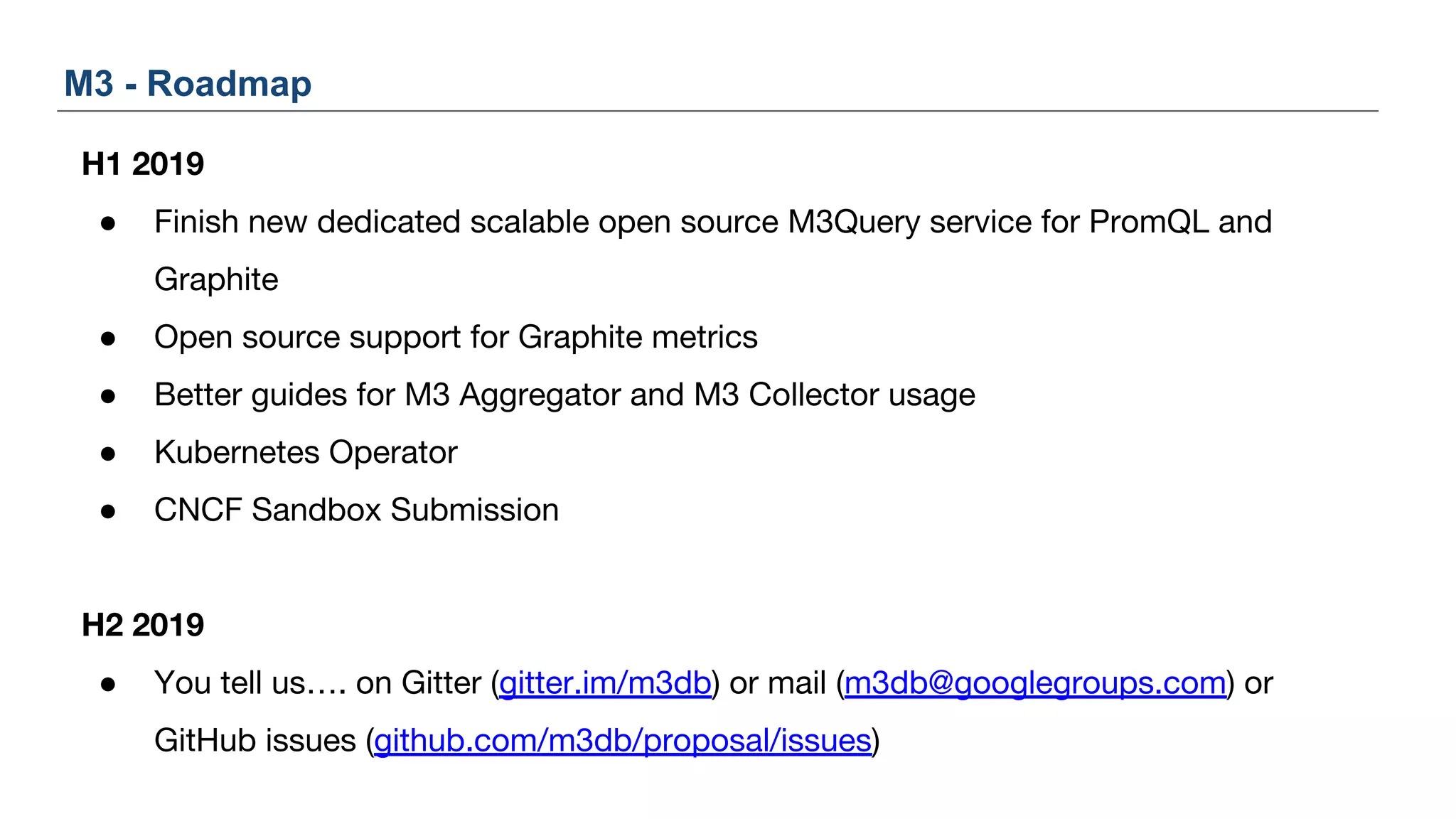
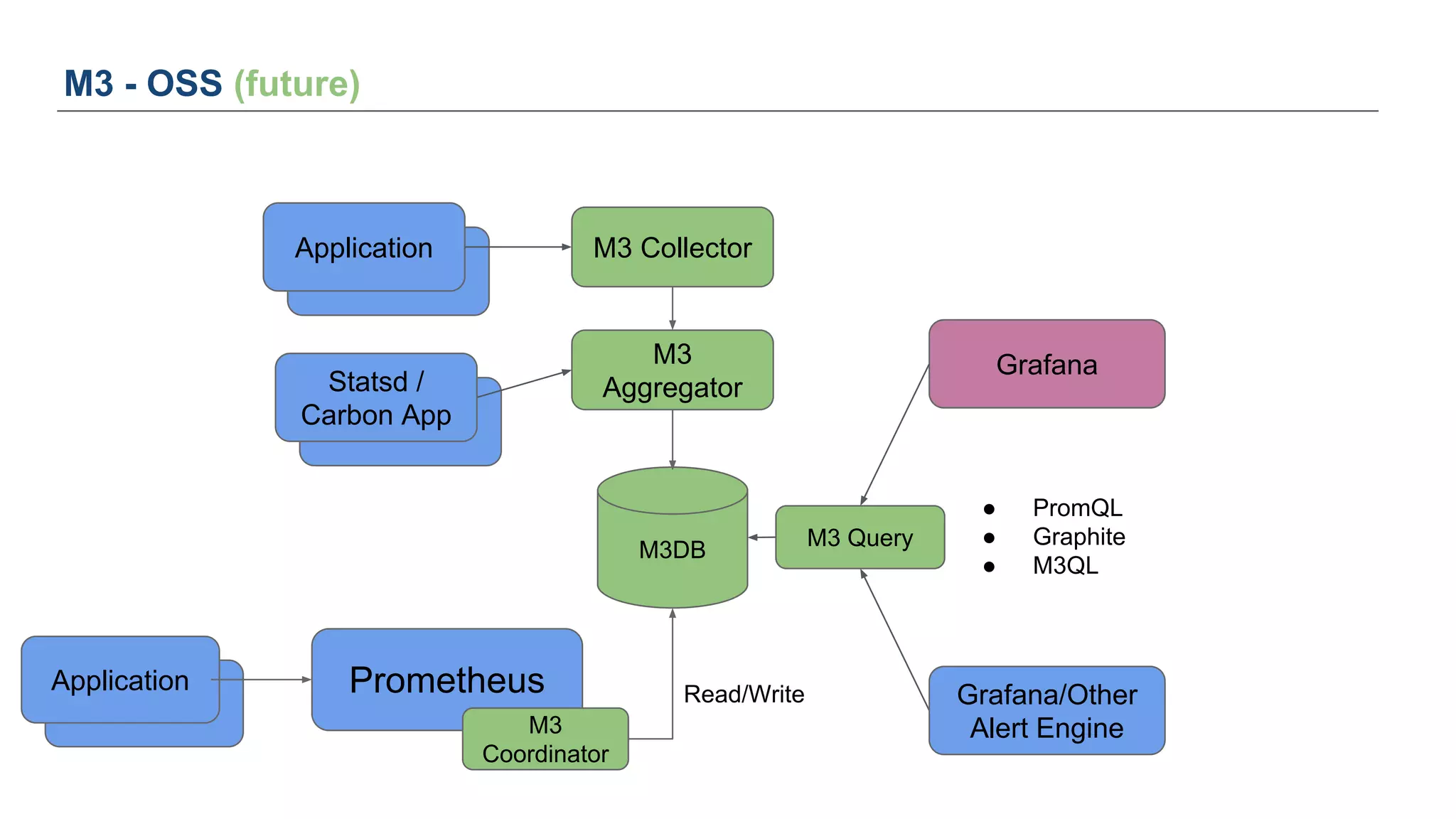



The document discusses Uber's M3 metrics platform and the evolution of observability in monitoring complex systems. It emphasizes the advantages of high-dimensionality metrics for better drill-down capabilities and efficient monitoring across multiple services, especially in a microservices architecture. The document also outlines M3's design principles and its improvements over previous systems, highlighting its scalability, cost-effectiveness, and optimizations for high read and write volumes.


























































