Downloaded 67 times


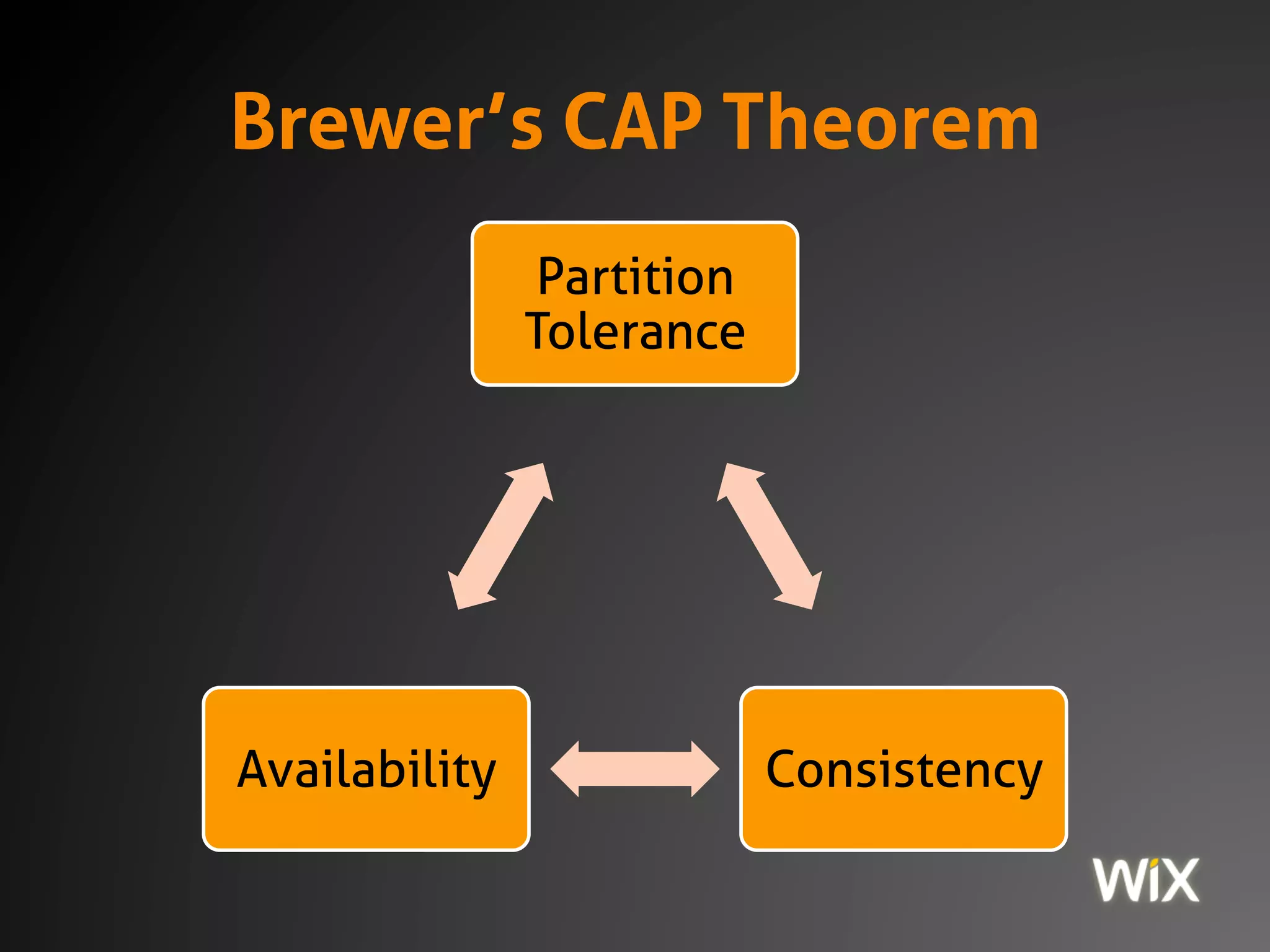
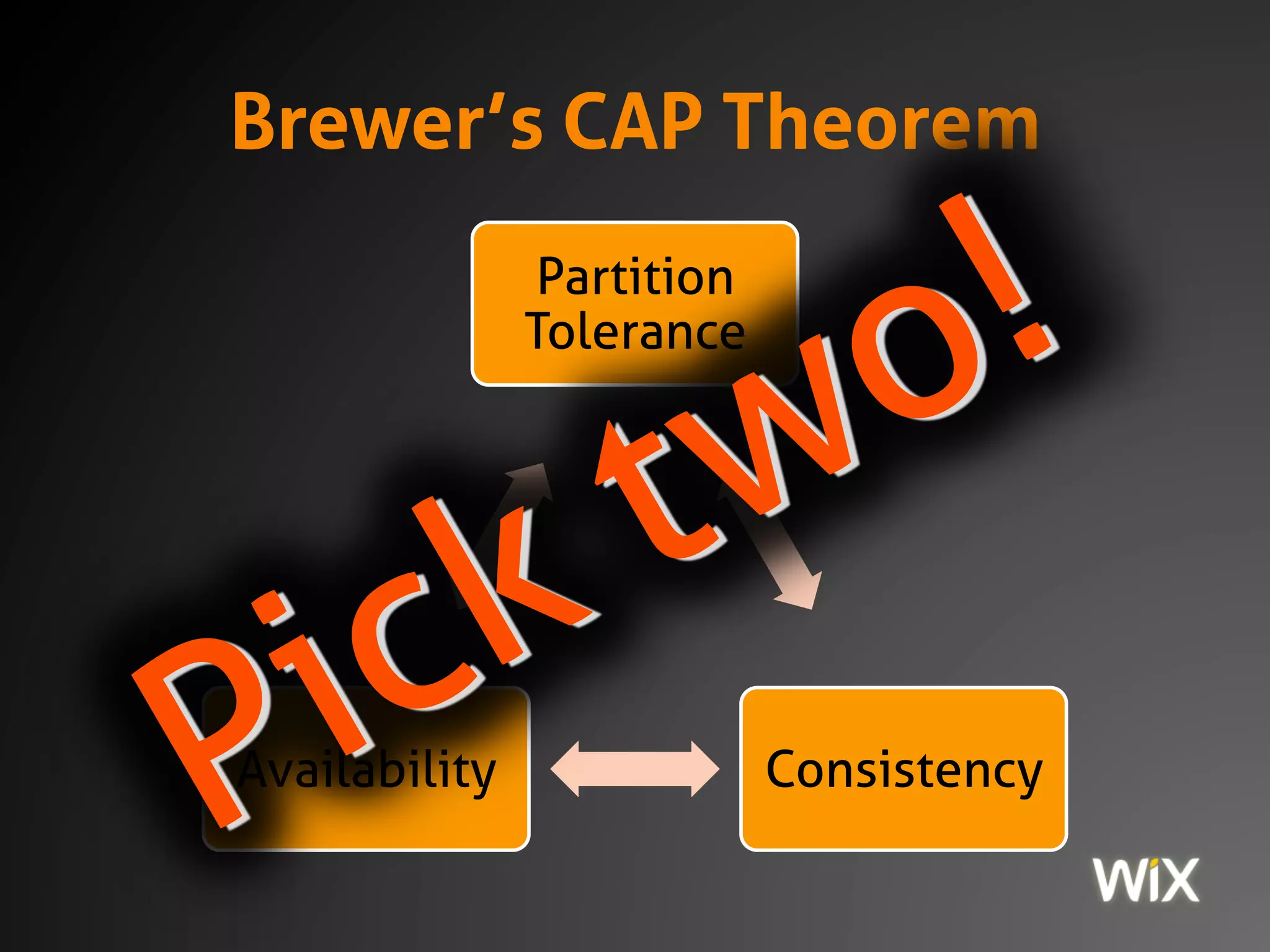














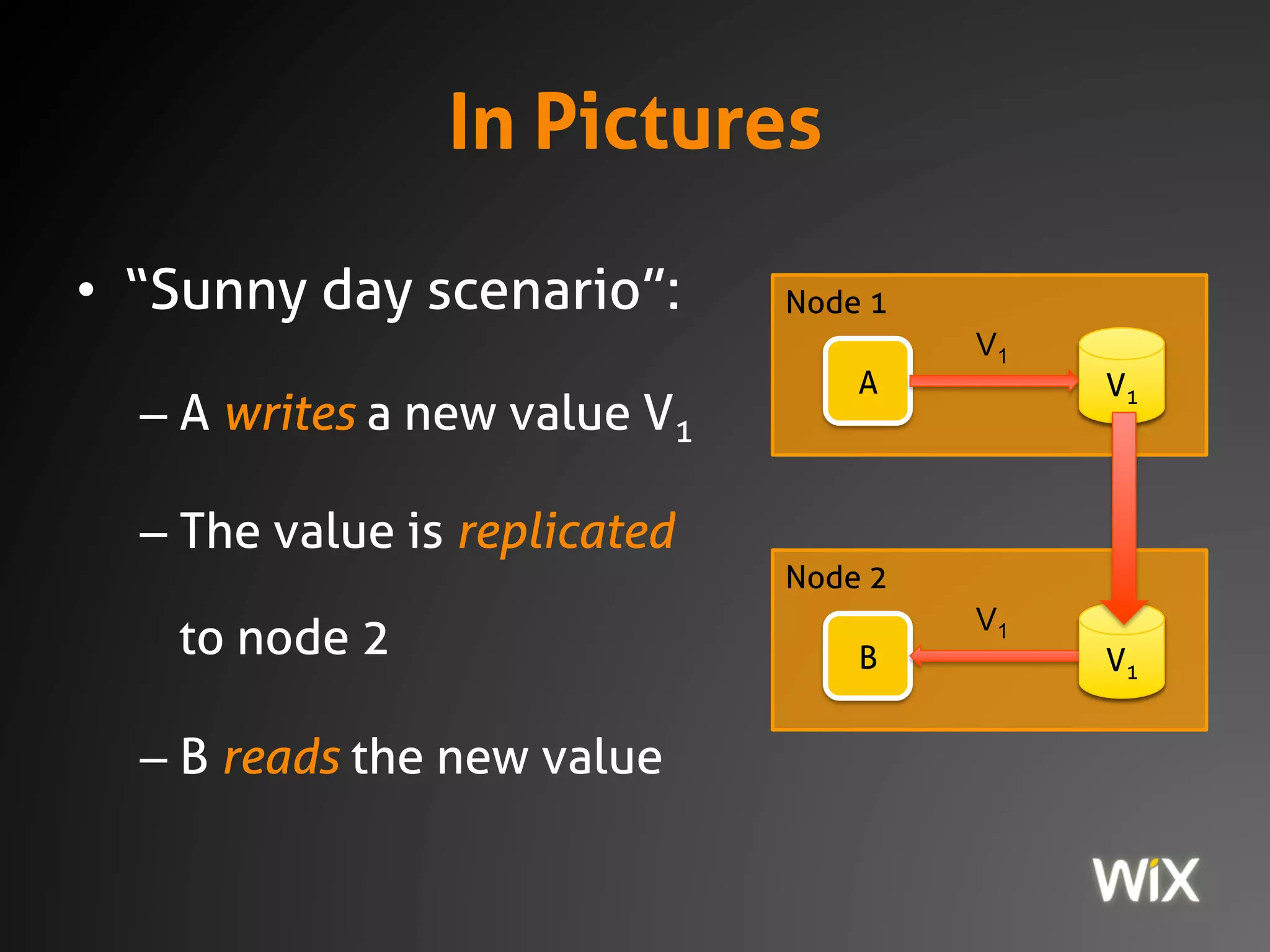
































The document discusses the CAP theorem, which states that in distributed systems one must choose between consistency, availability, and partition tolerance. It emphasizes that modern systems are always distributed and that managing this trade-off is critical for functionality, with practical examples illustrating the behavior of PostgreSQL and MongoDB under network partitions. The document also introduces strategies for ensuring data integrity and consistency in distributed systems, including the use of immutable data, idempotent operations, and eventual consistency mechanisms.
















![Grand Central Dispatch and multi-threading [iCONdev 2014]](https://cdn.slidesharecdn.com/ss_thumbnails/icondev-gcd-140326100357-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



































































