Download as PDF, PPTX







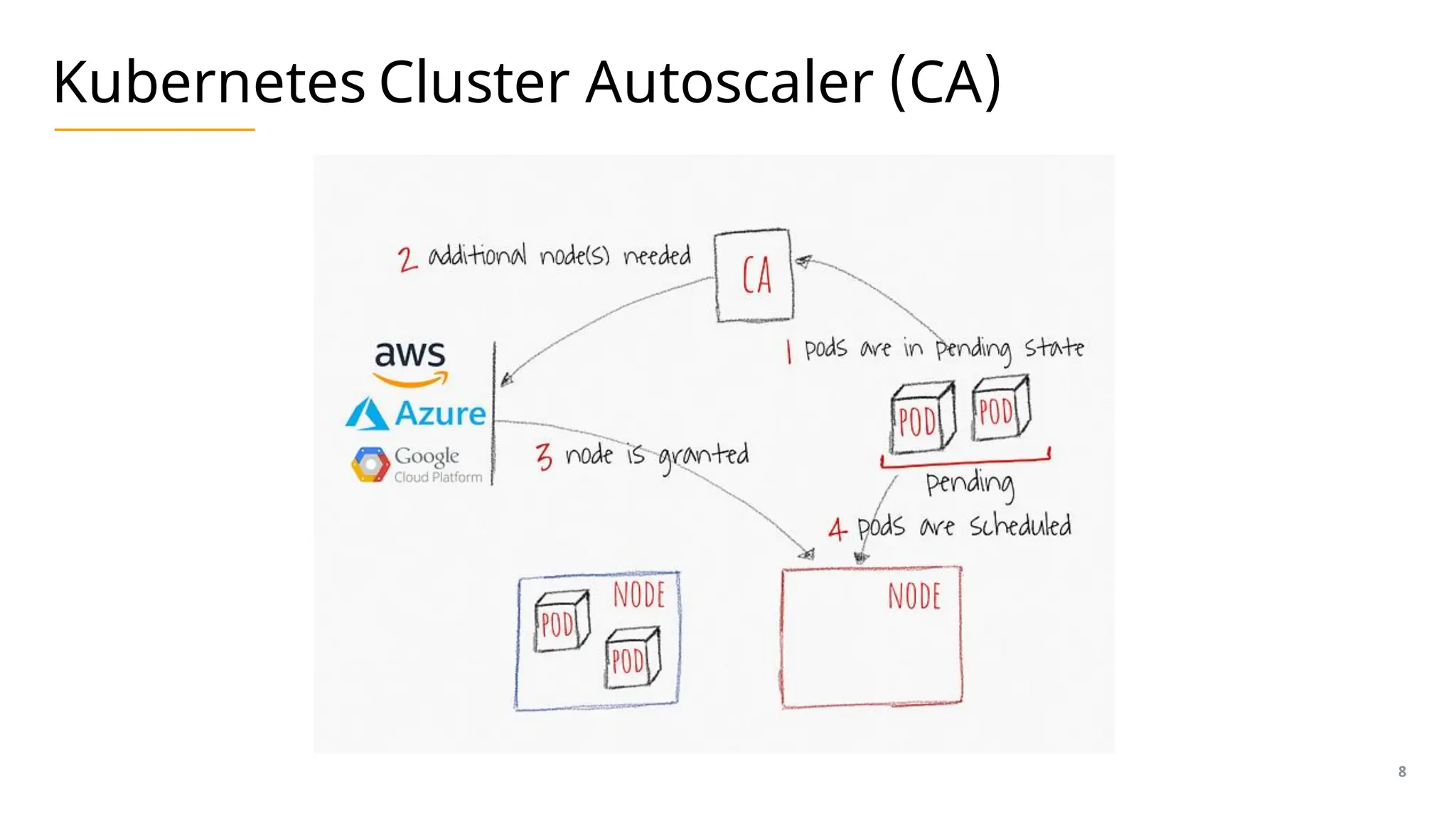


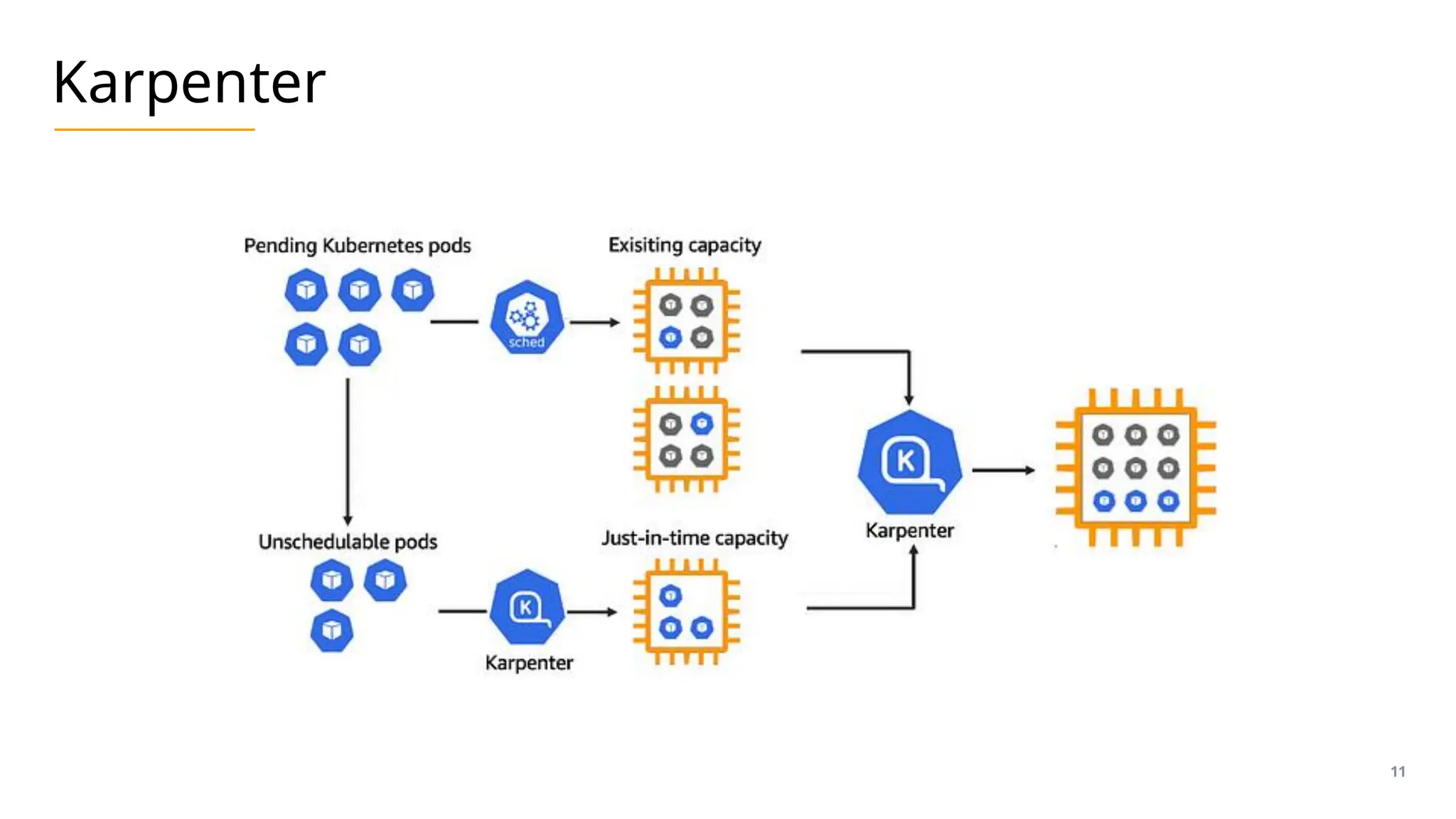








The document presents an overview of scaling AKS (Azure Kubernetes Service) nodes, focusing on Kubernetes scheduling and cluster autoscaling strategies, including traditional autoscalers and Karpenter. It highlights the key functionalities of the Kubernetes scheduler, cluster autoscaler, and Karpenter, emphasizing their roles in managing resources dynamically and efficiently in cloud-native environments. Additionally, it discusses the capabilities of Karpenter on Azure, its alpha status, and limitations while summarizing the advantages of using these tools for varying workload types.
































































