소개
NIO 기반 고성능네트워크 어플리케이션 프레임워크
오픈소스
Apache License Version 2.0
https://github.com/netty/netty
5.
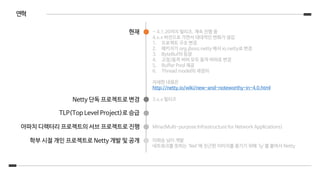
연혁
학부 시절 개인프로젝트로 Netty 개발 및 공개
아파치 디렉터리 프로젝트의 서브 프로젝트로 진행
TLP(Top Level Project)로 승급
Netty 단독 프로젝트로 변경
현재
이희승 님이 개발
네트워크를 뜻하는 ‘Net’에 친근한 이미지를 풍기기 위해 ‘ty’를 붙여서 Netty
Mina(Multi-purpose Infrastructure for Network Applications)
~ 4.1.20까지 릴리즈. 계속 진행 중
4.x.x 버전으로 가면서 대대적인 변화가 생김
1. 프로젝트 구조 변경
2. 패키지가 org.jboss.netty 에서 io.netty로 변경
3. ByteBuf의 등장
4. 고정/동적 버퍼 모두 동적 버퍼로 변경
5. Buffer Pool 제공
6. Thread model의 재정의
자세한 내용은
http://netty.io/wiki/new-and-noteworthy-in-4.0.html
3.x.x 릴리즈
우리는왜?
java.net.* 의 API를이용하여 Blocking 방식 또는 java.nio.*를 이용하여 Non-Blocking 방식으로 네트워킹 구현을
해도 전혀 문제가 없음
하지만 이 작업을 올바르고 안전하게(Multi Thread, 동기화 등 고려) 처리하기는 쉽지 않음
즉, Netty의 사용 이유도 다른 Framework 사용 이유와 크게 다르지 않음
‘생산성,개발편의,코드품질’
마찬가지로 Framework 학습 시간, 개발 자유도의 한계라는 단점도 존재
9.
Netty?
Netty is anasynchronous event-driven network application framework
for rapid development of maintainable high performance protocol servers & clients
“Netty는 비동기식 event-driven 네트워크 어플리케이션 프레임워크”
특징
다양한 전송 유형을위한 통합 API – Blocking & Non-blocking
Concern을 명확하게 분리 할 수 있는 유연하고 확장 가능한 이벤트 모델 기반
커스터마이징이 가능한 스레드 모델
진정한 connectionless datagram 소켓 지원
잘 정리된 Javadoc, 유저 가이드, 예제
추가적인 Dependency가 필요 없음
더 나은 처리량, 더 낮은 대기 시간
자원 소비량 감소
불필요한 메모리 복사의 최소화
SSL/TLS, StartTLS의 완벽한 지원
Design
디자인
Easeofuse
쉬운사용
Performance
성능
Security
보안
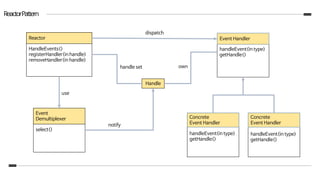
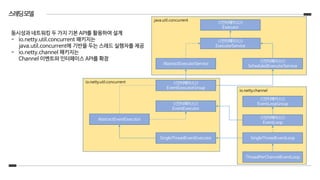
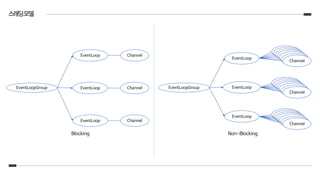
스레딩모델
동시성과 네트워킹 두가지 기본 API를 활용하여 설계
- io.netty.util.concurrent 패키지는
java.util.concurrent에 기반을 두는 스레드 실행자를 제공
- io.netty.channel 패키지는
Channel 이벤트와 인터페이스 API를 확장
<<인터페이스>>
Executor
<<인터페이스>>
ExecutorService
AbstractExecutorService
<<인터페이스>>
ScheduledExecutorService
<<인터페이스>>
EventExecutorGroup
<<인터페이스>>
EventExecutor
AbstractEventExecutor
SingleThreadEventExecutor SingleThreadEventLoop
ThreadPerChannelEventLoop
<<인터페이스>>
EventLoop
<<인터페이스>>
EventLoopGroup
java.util.concurrent
io.netty.util.concurrent
io.netty.channel
19.
스레딩모델
1. EventLoopGroup에 다중EventLoop 또는 단일 EventLoop 할당이 가능
2. EventLoop의 이벤트/작업 처리 순서는 FIFO 방식
3. Runnable 또는 Callable을 EventLoop로 즉시 또는 예약 실행 가능(implements ScheduledExecutorService)
4. EventLoop는 변경되지 않는 Thread 하나로 동작
5. 모든 입출력 작업과 이벤트는 EventLoop에 할당된 Thread에 의해 처리 됨
4 + 5 )
EventLoop는 변경되지 않는 Thread 하나로 동작하는데 모든 입출력 작업과 이벤트는 EventLoop에 할당된 Thread에 의해 처리
따라서 인바운드(입력)와 아웃바인드(출력) 시에 Thread간 추가적인 컨텍스트 전환이 필요가 없으며
이벤트를 처리하는 ChannelHandler간의 동기화가 필요 없음
(단, 여러 동시채널에서 ChannelHandler가 공유될 수 있는 경우는 제외 @Sharable)
20.
스레딩모델
일반 상황처럼 ScheduledExecutorService구현은 풀 관리 작업의 일부로 스레드가 추가로 생성되는 등의 한계점을 가지고 있으며,
이 때문에 많은 작업을 예약할 경우 병목 현상이 발생할 수 있다.
이런 경우엔 Channel의 EventLoop를 이용하는 것이 성능상의 이익을 볼 수 있음
EventLoop가 ScheduledExecutorService를 implements 하기 때문에 JDK 구현의 모든 메서드를 제공
주기적이거나주기적이지않은작업(ex,HeartBeat)은어떻게하는것이좋을까?
21.
스레딩모델
EventLoop는 현재 실행중인 Thread를 확인하는 절차를 거침
즉, Thread가 현재 Channel과 해당 EventLoop에 할당된 것인지 확인
호출 Thread가 EventLoop에 속하는 경우 해당 코드 블록이 실행
그렇지 않다면 작업을 예약하고 내부 Queue에 넣음
단, 수행 시간이 오래 걸리는 작업은 실행 Queue에 넣지 않아야 함
- EventLoop에 할당 된 Thread는 하나이기 때문에 수행 되는 동안 Blocking이 걸림
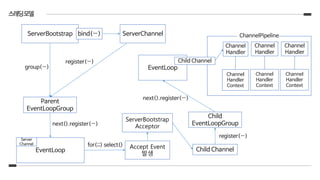
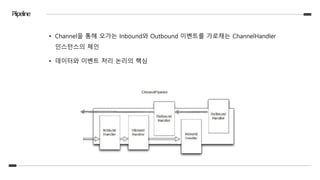
- 해당 문제를 해결하기 위해 ChannelPipeline의 add*(EventExecutorGroup group, …) 사용
왜 성능상의 이점이 있을까? - EventLoop의 Thread 관리 때문
22.
스레딩모델
write() 작업은 ChannelFuture를리턴하며 비동기로 진행이 됨
실질적인 write()는 void형이며 각각의 Channel내에 정의되어있는
unsafe(unsafe는 netty내 실제 전송을 구현하기 위해서 사용)를 사용
unsafe 내에서 java.nio.channels.SocketChannel의 write(...)를
사용하여 비동기로 동작하게 됨
* SocketChannel의 실제 구현체는
sun.nio.ch.SocketChannelImpl인데 해당 부분의 내부 구현은
native라서 어떤 방식으로 non-blocking을 구현했는지 파악이 어려움
파라미터로 짐작해보면 FileDescriptor를 가지고 처리를 하는 것 같음
잠깐!!!! write() 작업은 어떻게 진행이 될까?
스레딩모델
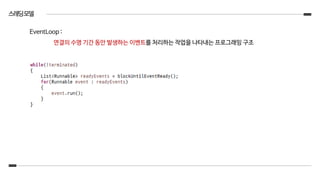
각각의 EventLoop는 taskQueue와scheduledTaskQueue를 가짐
addTask()는 taskQueue에 작업을 넣는 행위이고
scheduledTaskQueue().add()는 scheduledTaskQueue에 작업을 넣는 행위
EventLoop에서는 오른쪽 코드처럼 select()를 진행 후에 taskQueue에 있는 모든 작업들을 수행
그 과정에서 scheduledTaskQueue에 있는 작업 중에 처리 순서가 된 작업은 taskQueue에 offer()하여 자연스럽
게 처리가 되도록 진행
따라서 앞의 예제에서 현재 Thread가 EventLoop의 thread라면 바로 해당 EventLoop의
scheduledTaskQueue에 작업을 넣고
EventLoop의 Thread가 아니라면 scheduledTaskQueue에 넣는 행위 자체를 taskQueue에 넣고 EventLoop
가 자기자신의 scheduledTaskQueue에 넣을 수 있도록 함
예시 시나리오)
1. Channel에는 id 1번 Thread를 가지는 EventLoop를 할당
2. id 2번 Thread에서 ch.eventLoop().schedule(..)을 호출
3. schedule()에서는 현재 Thread와 EventLoop의 Thread를 비교(id 1 != id 2)
4. Thread가 다르기 때문에 EventLoop의 taskQueue에 scheduledTaskQueue에 add하는 행위를 넣음
5. EventLoop가 select()를 끝내며 자신의 taskQueue에 들어있던 scheduledTaskQueue에 add하는 행위를
수행
6. 현재 Thread와 EventLoop의 Thread가 같기 때문에(id 1 == id 1) 정상적으로 수행
앞슬라이드예제소스의이해를도울EventLoop의Task처리구조
EventLoop 내에서 select() 수행 부분
25.
스레딩모델
- 하나의 EventLoopGroup은하나 이상의 EventLoop를 포함
- EventLoopGroup은 Channel에 EventLoop를 할당
- 하나의 EventLoop는 수명주기 동안 하나의 Thread로 바인딩
- 하나의 Channel은 수명주기 동안 하나의 EventLoop에 등록
- 하나의 EventLoop를 하나 이상의 Channel로 할당 가능
- EventLoop가 생성 및 할당 되는 방법은 전송의 구현에 따라 다름(Blocking 또는 Non-Blocking)
Channel,Thread,EventLoop,EventLoopGroup간의관계
Bootstrap
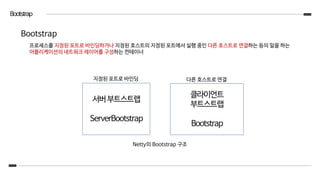
Bootstrap
프로세스를 지정된 포트로바인딩하거나 지정된 호스트의 지정된 포트에서 실행 중인 다른 호스트로 연결하는 등의 일을 하는
어플리케이션의 네트워크 레이어를 구성하는 컨테이너
서버부트스트랩
ServerBootstrap
지정된 포트로 바인딩
클라이언트
부트스트랩
Bootstrap
다른 호스트로 연결
Netty의 Bootstrap 구조
28.
Bootstrap
Bootstrap ServerBootstrap
네트워크 기능원격 호스트와 포트로 연결 로컬 포트로 바인딩
필요한 EventLoopGroup의 수 1 2
Bootstrap 비교
Bootstrap에는 EventLoopGroup이 하나만 필요하지만 ServerBootstrap에는 2개(동일한 인스턴스 가능)가 필요
Why?
29.
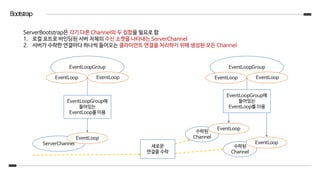
Bootstrap
ServerBootstrap은 각기 다른Channel의 두 집합을 필요로 함
1. 로컬 포트로 바인딩된 서버 자체의 수신 소켓을 나타내는 ServerChannel
2. 서버가 수락한 연결마다 하나씩 들어오는 클라이언트 연결을 처리하기 위해 생성된 모든 Channel
EventLoopGroup
EventLoop EventLoop
EventLoopGroup에
들어있는
EventLoop를 이용
ServerChannel
EventLoop
EventLoopGroup
EventLoop EventLoop
EventLoopGroup에
들어있는
EventLoop를 이용
수락된
Channel
EventLoop
새로운
연결을 수락
수락된
Channel
EventLoop
스레딩모델
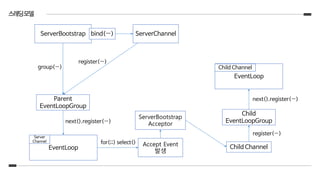
1. ServerBootstrap은 EventLoopGroup을2개 사용.(같은 인스턴스여도 상관 없음)
2. port를 bind할 때 ServerChannel이 생성
3. 해당 ServerChannel은 Parent EventLoopGroup에 register()되고 Parent EventLoopGroup은 해당 채널에 EventLoop
하나를 할당
4. ServerChannel을 register()하는 과정에서 EventHandler로 ServerBootstrapAcceptor를 등록
5. 채널에 할당 된 EventLoop는 ServerChannel에서의 Event를 지속적으로 select()
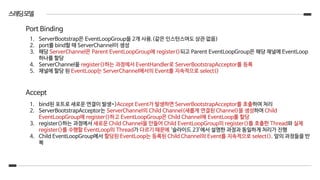
Port Binding
1. bind된 포트로 새로운 연결이 발생=>Accept Event가 발생하면 ServerBootstrapAcceptor를 호출하여 처리
2. ServerBootstrapAcceptor는 ServerChannel의 Child Channel(새롭게 연결된 Channel)을 생성하여 Child
EventLoopGroup에 register()하고 EventLoopGroup은 Child Channel에 EventLoop를 할당
3. register()하는 과정에서 새로운 Child Channel을 만들어 Child EventLoopGroup의 register()를 호출한 Thread와 실제
register()를 수행할 EventLoop의 Thread가 다르기 때문에 ‘슬라이드 23’에서 설명한 과정과 동일하게 처리가 진행
4. Child EventLoopGroup에서 할당된 EventLoop는 등록된 Child Channel의 Event를 지속적으로 select(). 앞의 과정들을 반
복
Accept
Future
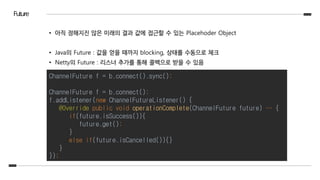
• 아직 정해지진않은 미래의 결과 값에 접근할 수 있는 Placehoder Object
• Java의 Future : 값을 얻을 때까지 blocking, 상태를 수동으로 체크
• Netty의 Future : 리스너 추가를 통해 콜백으로 받을 수 있음
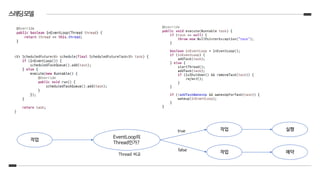
ChannelFuture f = b.connect().sync();
ChannelFuture f = b.connect();
f.addListener(new ChannelFutureListener() {
@Override public void operationComplete(ChannelFuture future) … {
if(future.isSuccess()){
future.get();
}
else if(future.isCancelled()){}
}
});
43.
Promise
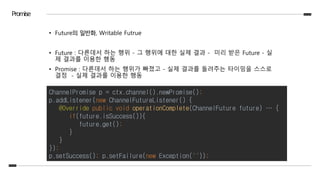
• Future의 일반화,Writable Futrue
• Future : 다른데서 하는 행위 - 그 행위에 대한 실제 결과 - 미리 받은 Future - 실
제 결과를 이용한 행동
• Promise : 다른데서 하는 행위가 빠졌고 - 실제 결과를 돌려주는 타이밍을 스스로
결정 - 실제 결과를 이용한 행동
ChannelPromise p = ctx.channel().newPromise();
p.addListener(new ChannelFutureListener() {
@Override public void operationComplete(ChannelFuture future) … {
if(future.isSuccess()){
future.get();
}
}
});
p.setSuccess(); p.setFailure(new Exception(""));
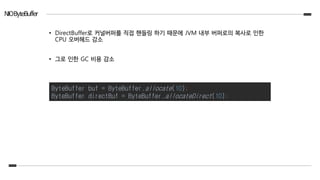
NIOByteBuffer
• DirectBuffer로 커널버퍼를직접 핸들링 하기 때문에 JVM 내부 버퍼로의 복사로 인한
CPU 오버헤드 감소
• 그로 인한 GC 비용 감소
ByteBuffer buf = ByteBuffer.allocate(10);
ByteBuffer directBuf = ByteBuffer.allocateDirect(10);
48.
NettyByteBuf
• NIO ByteBuffer를개선
• 내장 복합 버퍼 형식을 통한 투명한 제로카피 달성
• 용량을 필요에 따라 확장가능
• 읽기와 쓰기에 고유 인덱스를 적용함
• ByteBuffer의 flip() 메소드 호출 없이도 Reader와 Writer 모드를 전환할 수 있음
• 메서드 체인이 지원됨
• 참조 카운팅이 지원됨
• 풀링 지원됨(PooledByteBufAllocator를 이용하면 성능개선 및 메모리 단편화 최소화,
jemalloc이라는 고효율 메모리할당 방식을 이용)
49.
복합버퍼
• ByteBuf를 필요에따라 추가삭제 할 수 있음
• 복사하지 않고 하나로 묶어줌
CompositeByteBuf messageBuf = Unpooled.compositeBuffer();
ByteBuf headerBuf = ctx.alloc().directBuffer();
ByteBuf bodyBuf = ctx.alloc().directBuffer();
messageBuf.addComponent(headerBuf);
messageBuf.addComponent(bodyBuf);
for(ByteBuf buf : messageBuf){
System.out.println(buf.toString());
}
50.
인덱스관리
읽을 수 있는바이트폐기 가능한 바이트 기록할 수 있는 바이트
0 readerIndex writerIndex capacity
• 읽기와 쓰기에 고유 인덱스를 적용함
• ByteBuffer의 flip() 메소드 호출 없이도 Reader와 Writer 모드를 전환할 수 있음
51.
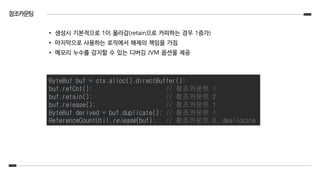
참조카운팅
• 생성시 기본적으로1이 올라감(retain으로 카피하는 경우 1증가)
• 마지막으로 사용하는 로직에서 해제의 책임을 가짐
• 메모리 누수를 감지할 수 있는 디버깅 JVM 옵션을 제공
ByteBuf buf = ctx.alloc().directBuffer();
buf.refCnt(); // 참조카운트 1
buf.retain(); // 참조카운트 2
buf.release(); // 참조카운트 1
ByteBuf derived = buf.duplicate(); // 참조카운트 1
ReferenceCountUtil.release(buf); // 참조카운트 0, deallocate





















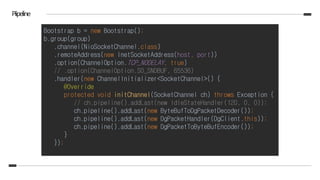
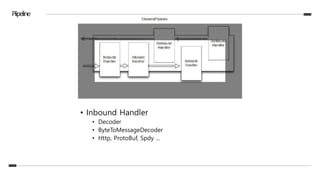
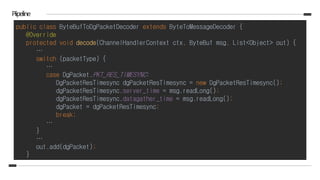
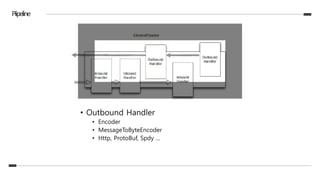
![Piipeline
public class DgPacketToByteBufEncoder extends MessageToByteEncoder<DgPacket>{
private final static Logger logger =
LoggerFactory.getLogger(DgPacketToByteBufEncoder.class);
@Override
protected void encode(ChannelHandlerContext ctx, DgPacket msg, ByteBuf out) throws
Exception {
msg.write(out);
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws
Exception {
logger.error("[MFJ-WSMJ-00080000] DataGather packing send error", cause);
}
}](https://image.slidesharecdn.com/netty180214-180404021904/85/Netty-41-320.jpg)





































![[E6]2012. netty internals](https://cdn.slidesharecdn.com/ss_thumbnails/e62012-nettyinternals-120919020847-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















