The document discusses Grafana Labs' migration from using Cluster Autoscaler to Karpenter for autoscaling their EKS clusters. Some key points:
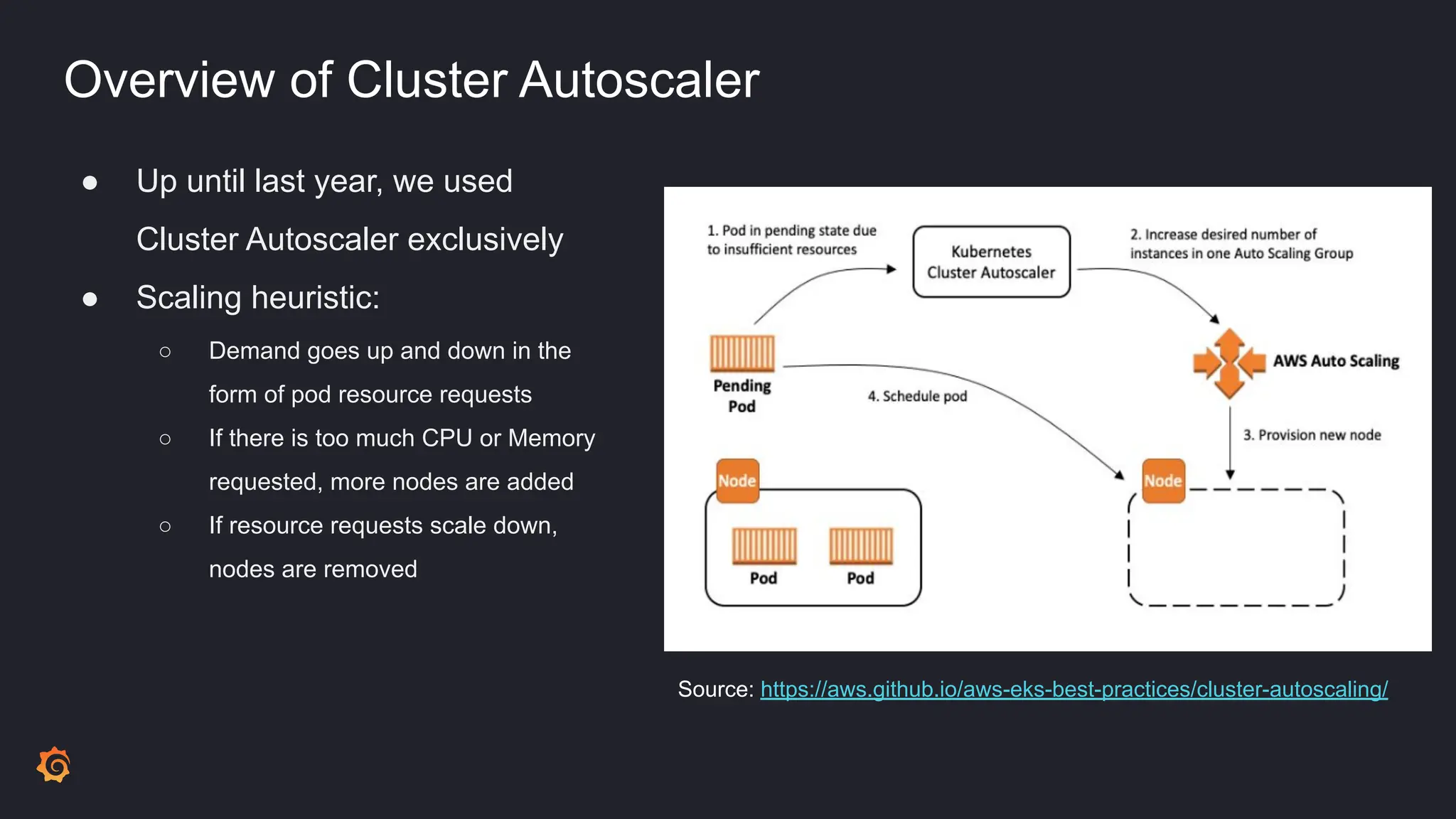
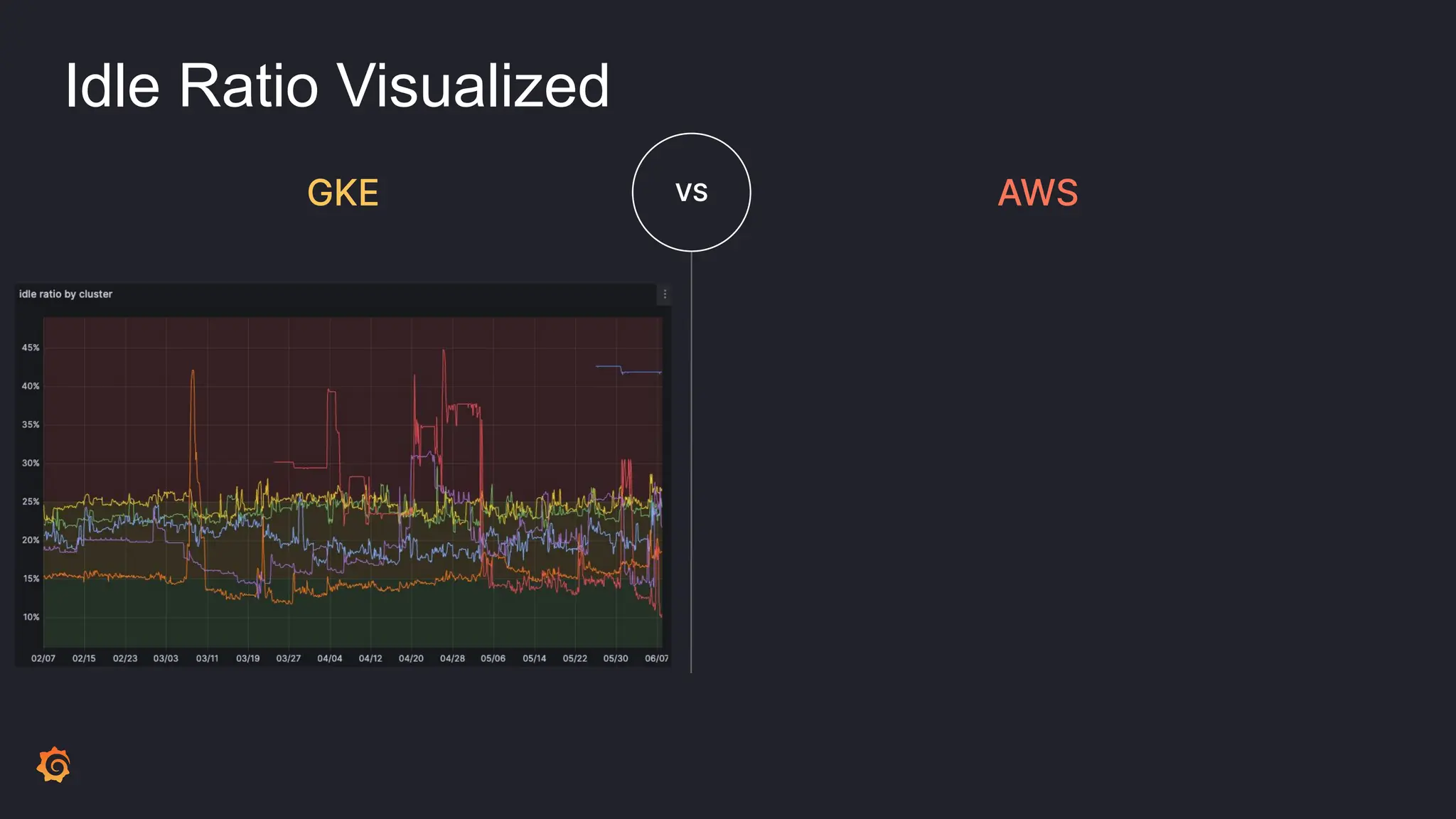
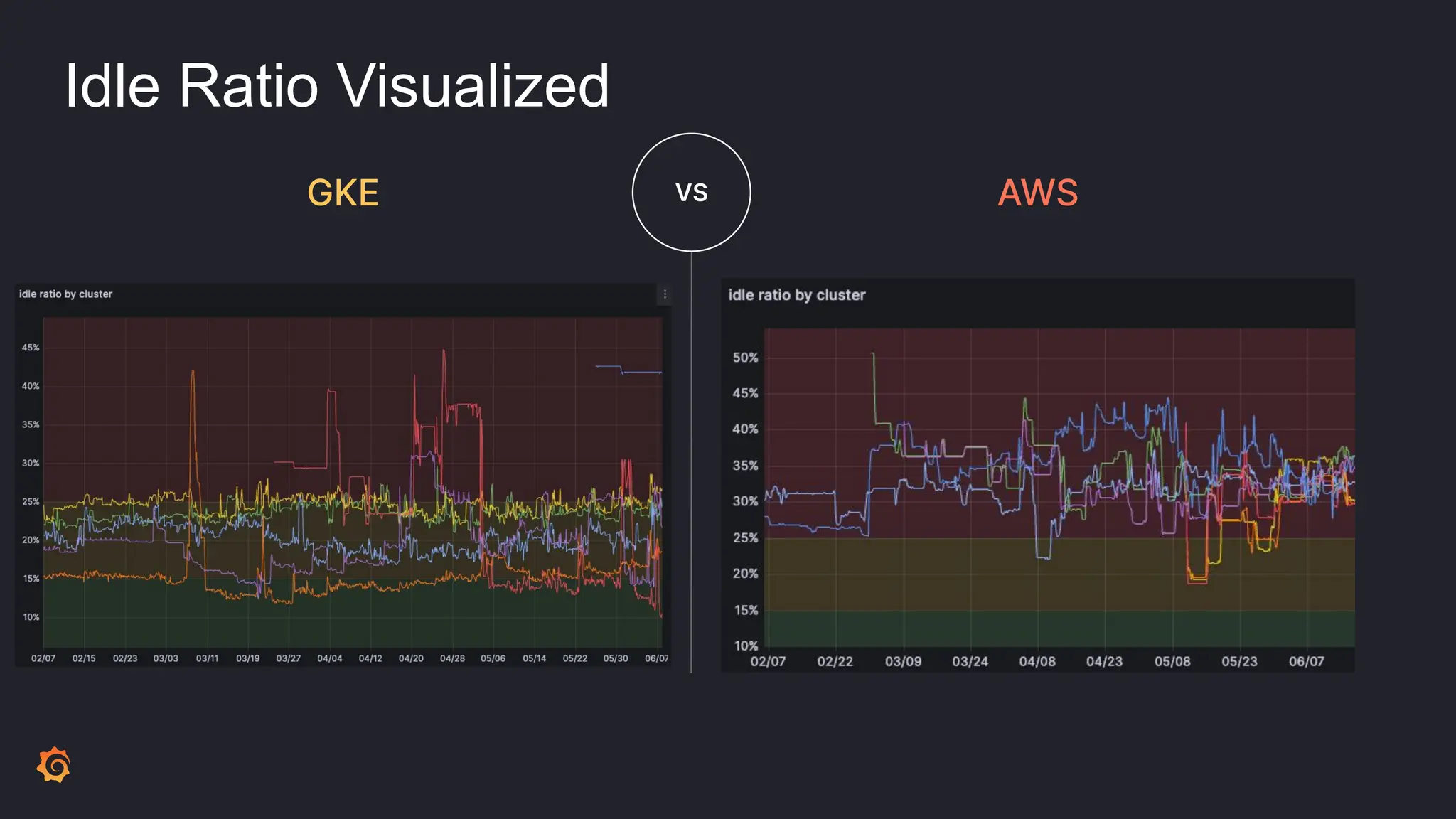
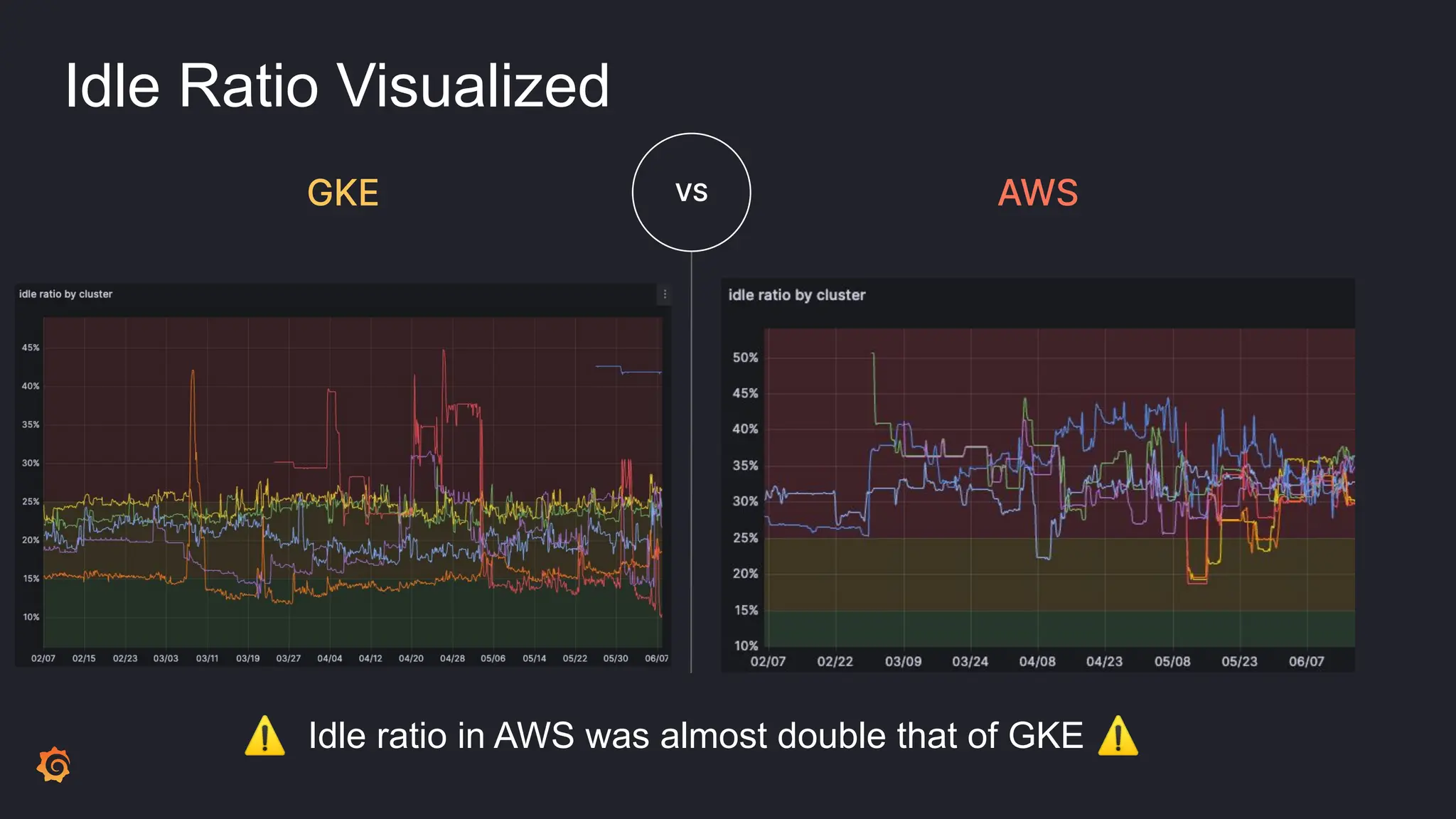
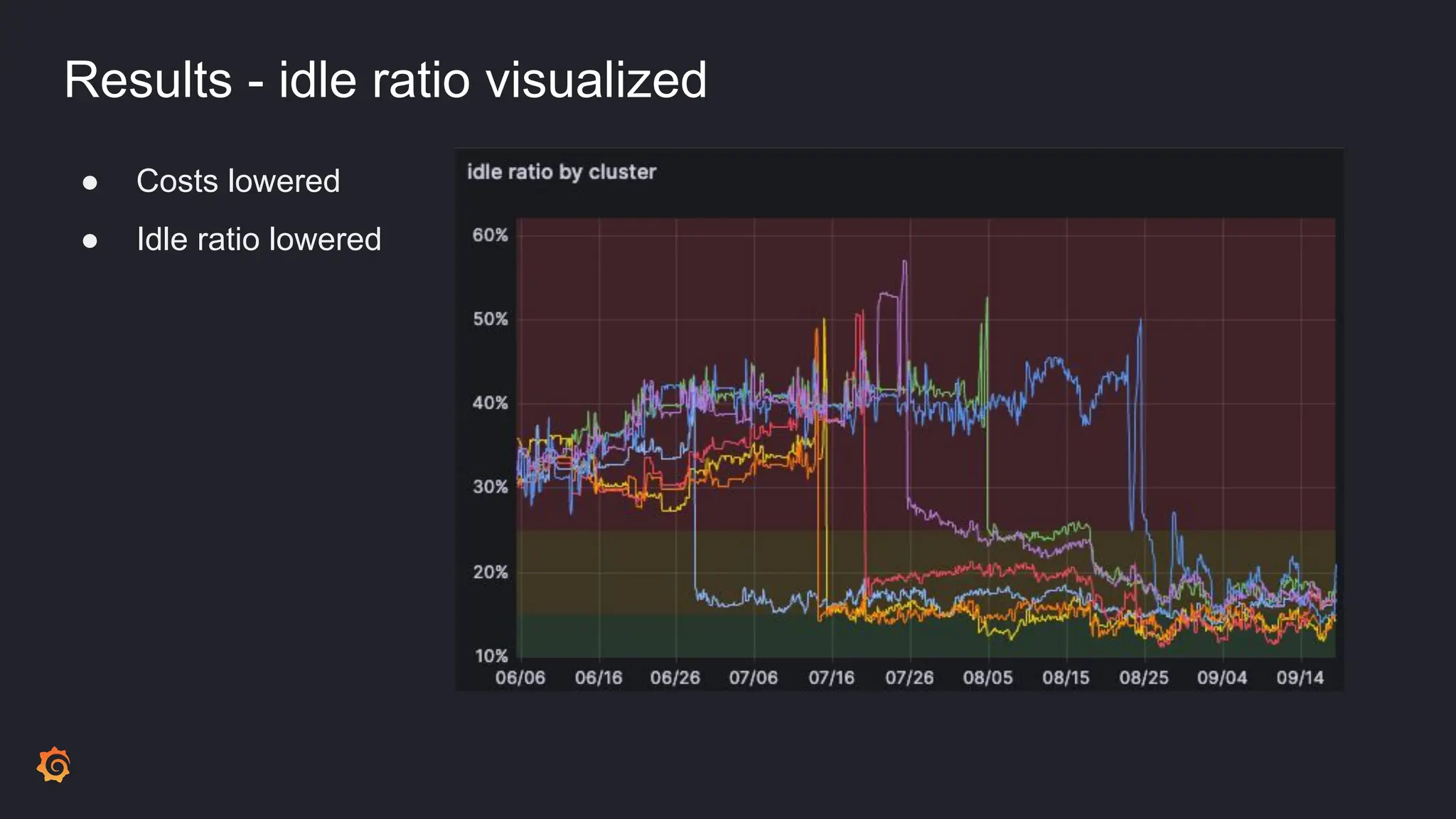
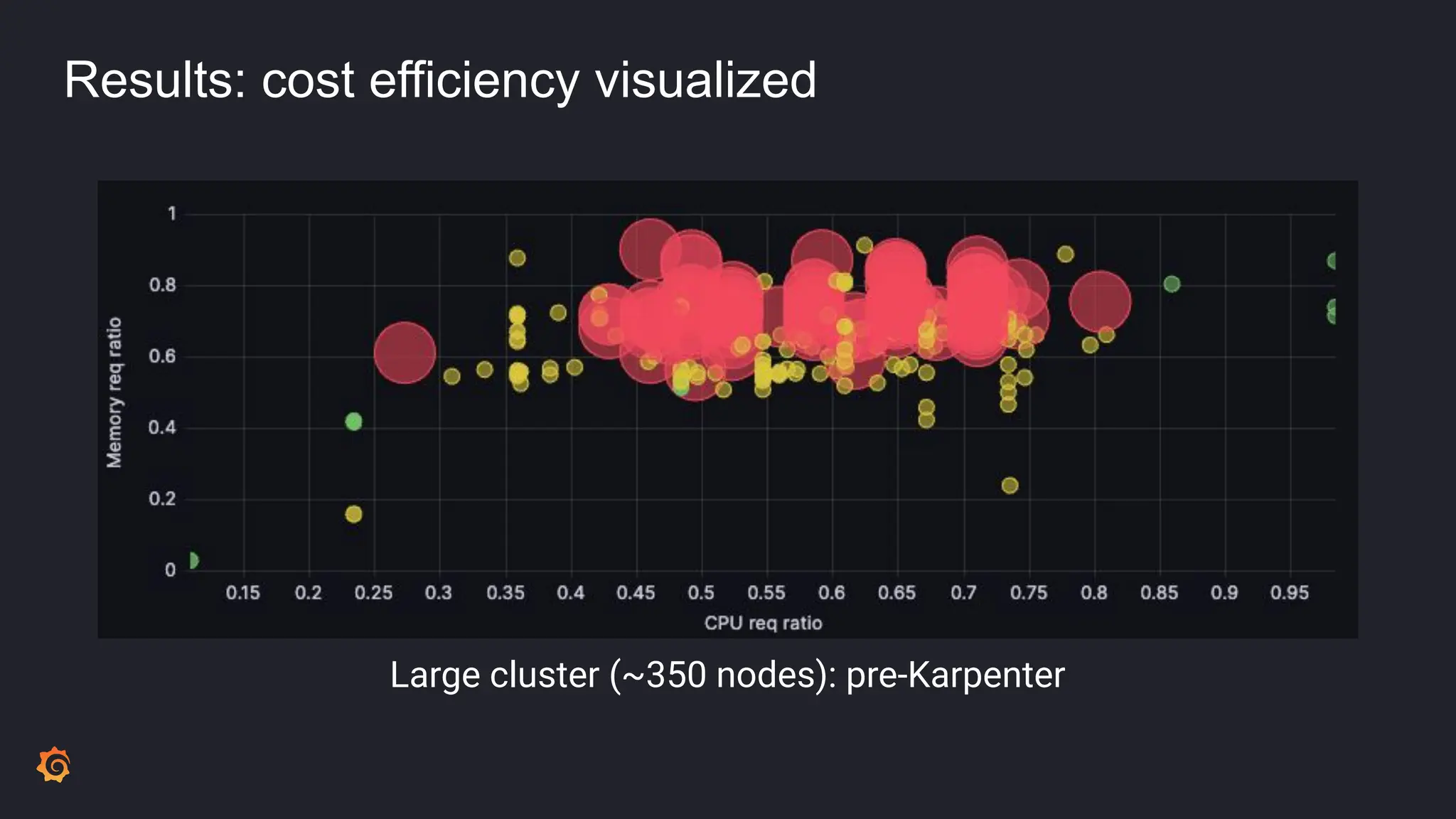
- Cluster Autoscaler was not optimizing resource utilization efficiently, leading to high idle ratios and wasted costs.
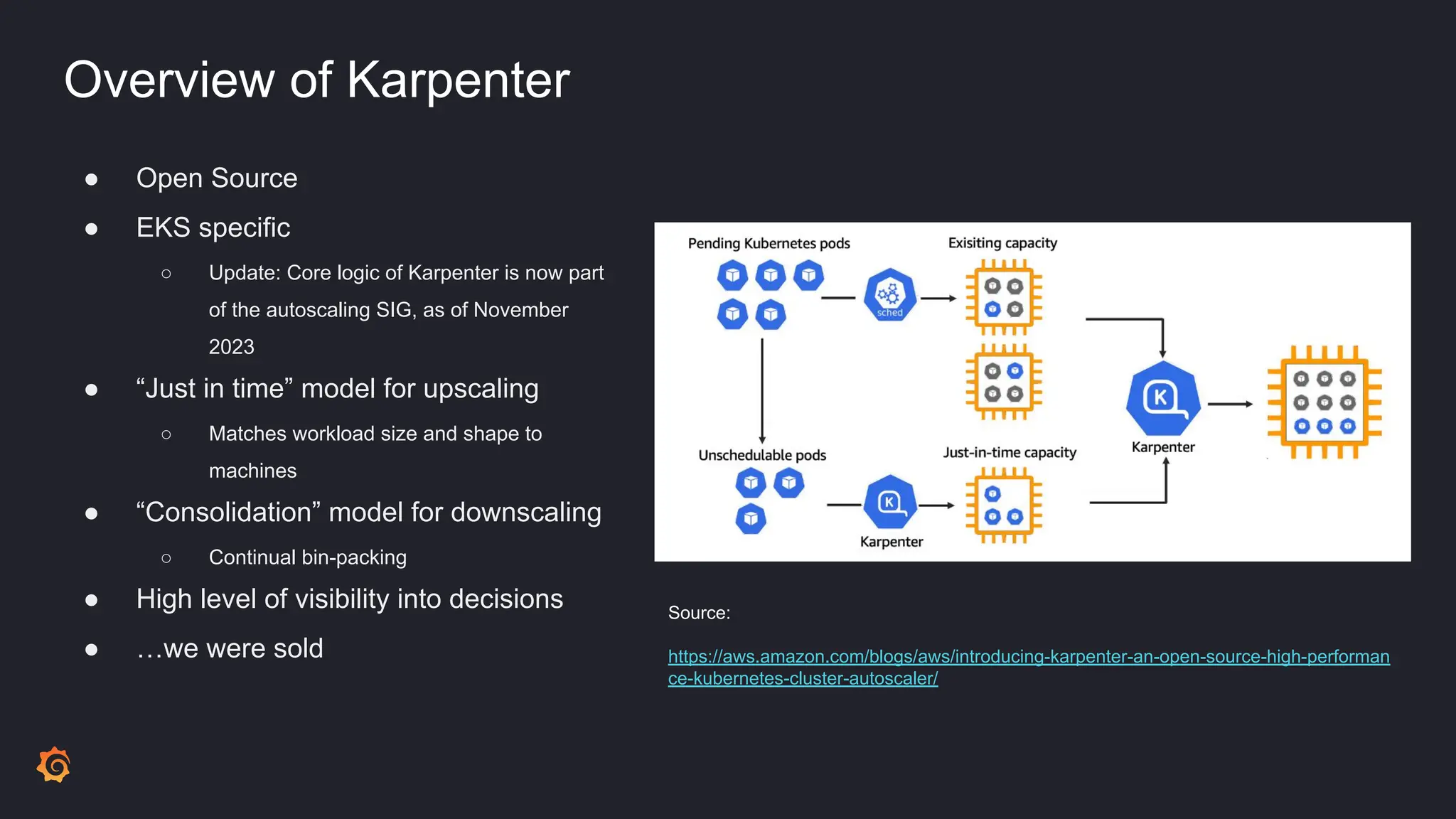
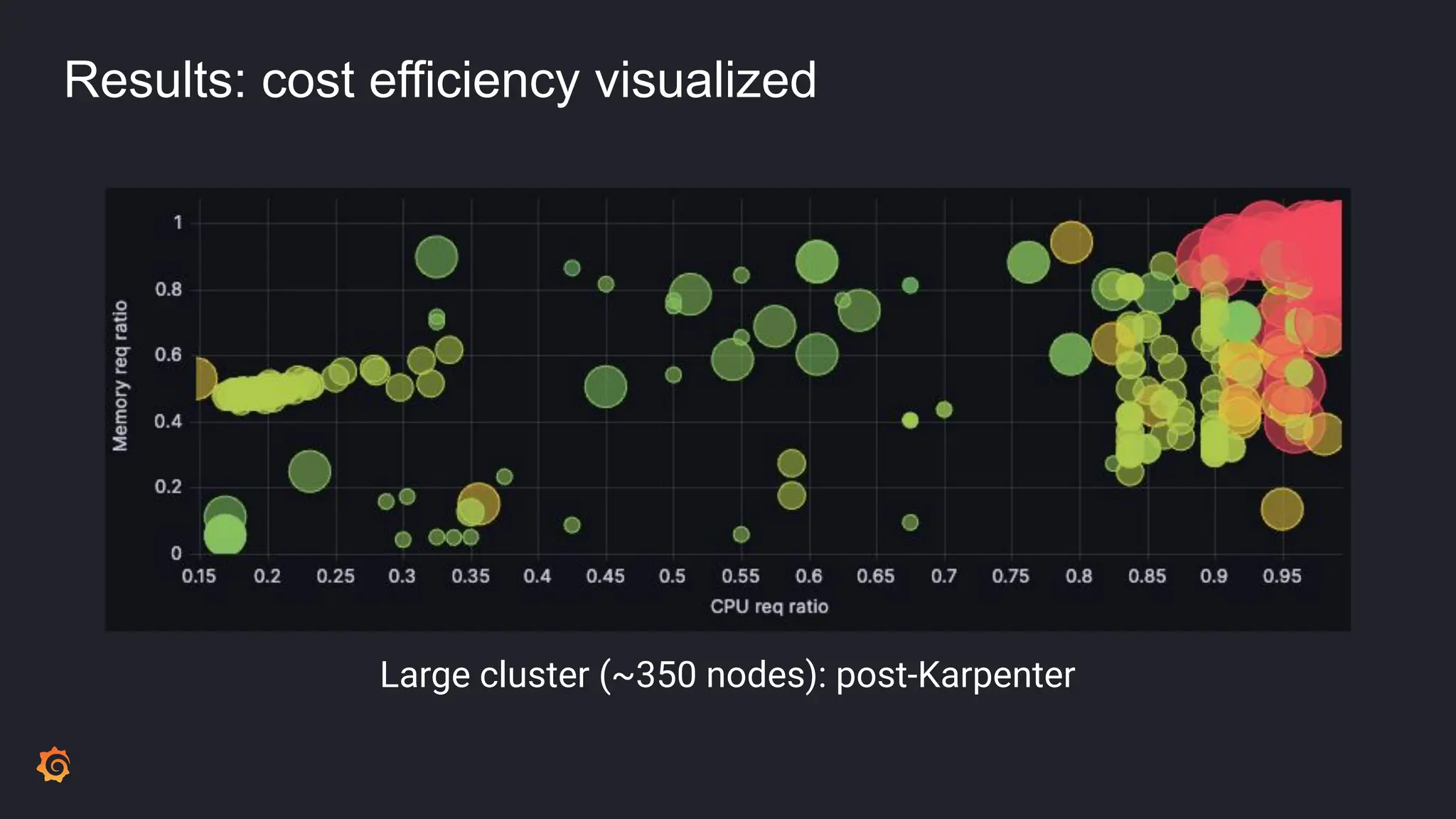
- Karpenter was identified as a potential replacement due to its "just in time" and "consolidation" scaling models for better bin packing of workloads.
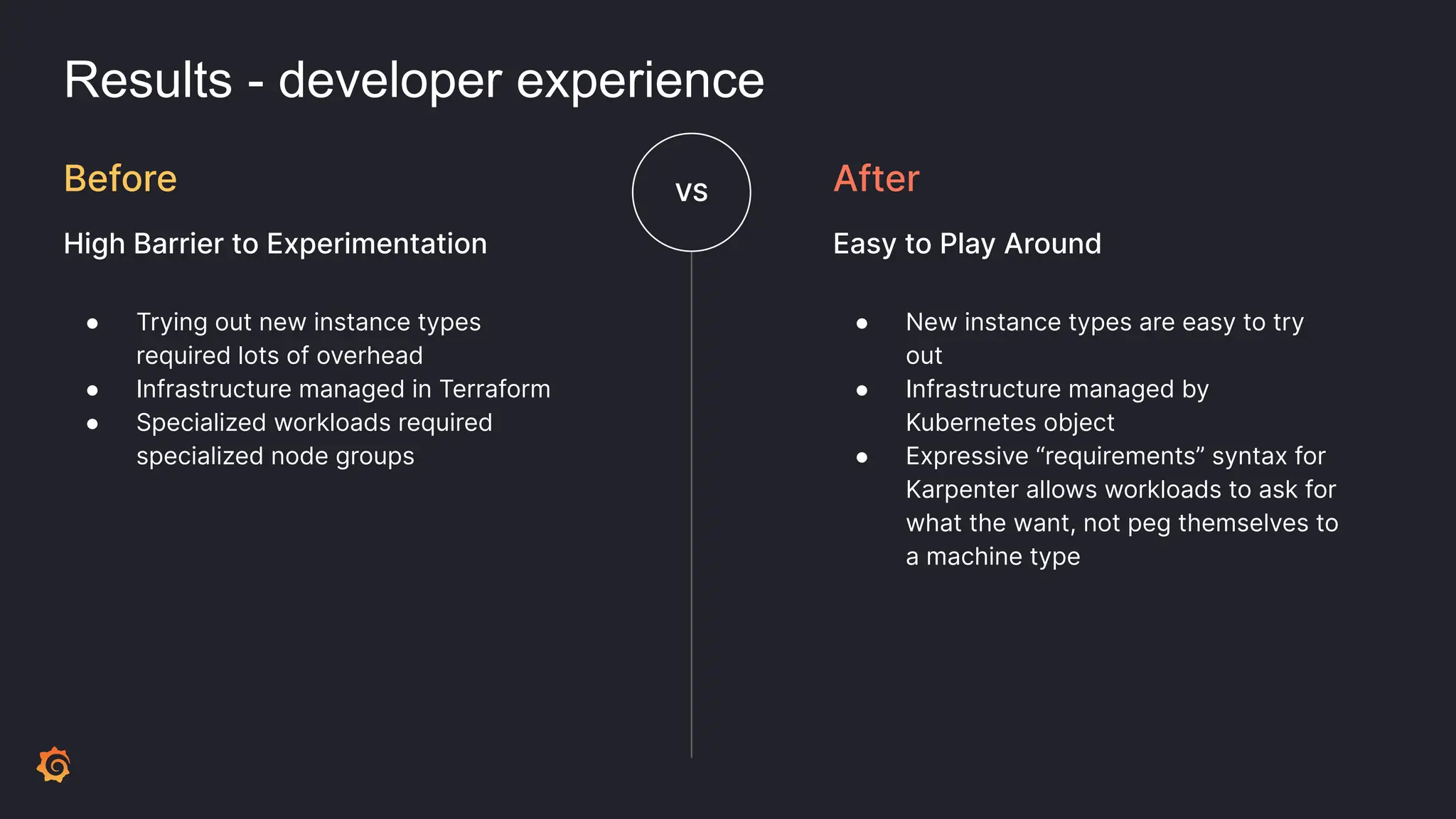
- The migration was planned and executed to minimize downtime, with resources defined as code and a careful ordering of steps like deploying Karpenter and draining old nodes.
- The results included significantly reduced costs and idle ratios through more effective resource distribution, as































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


