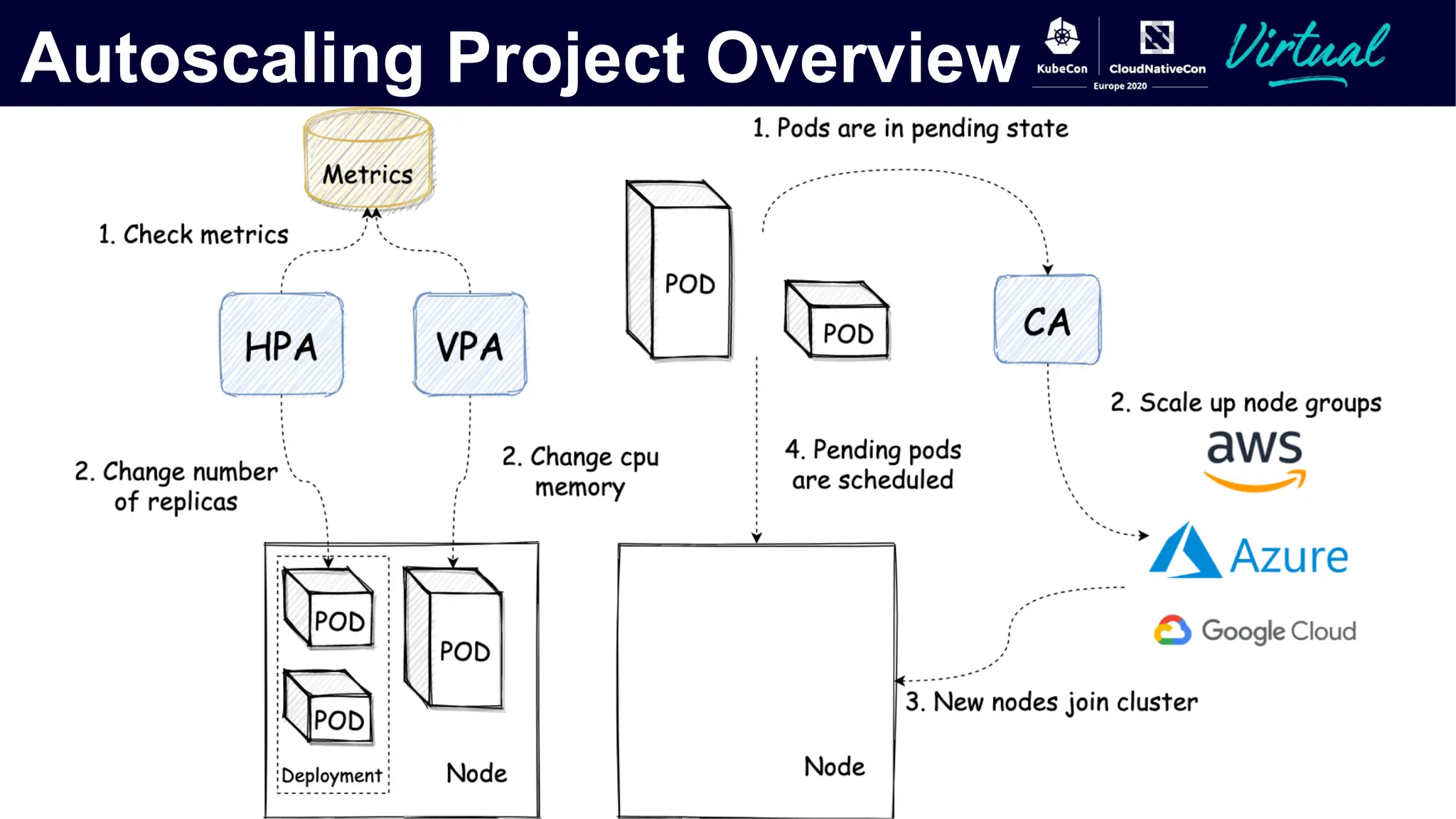
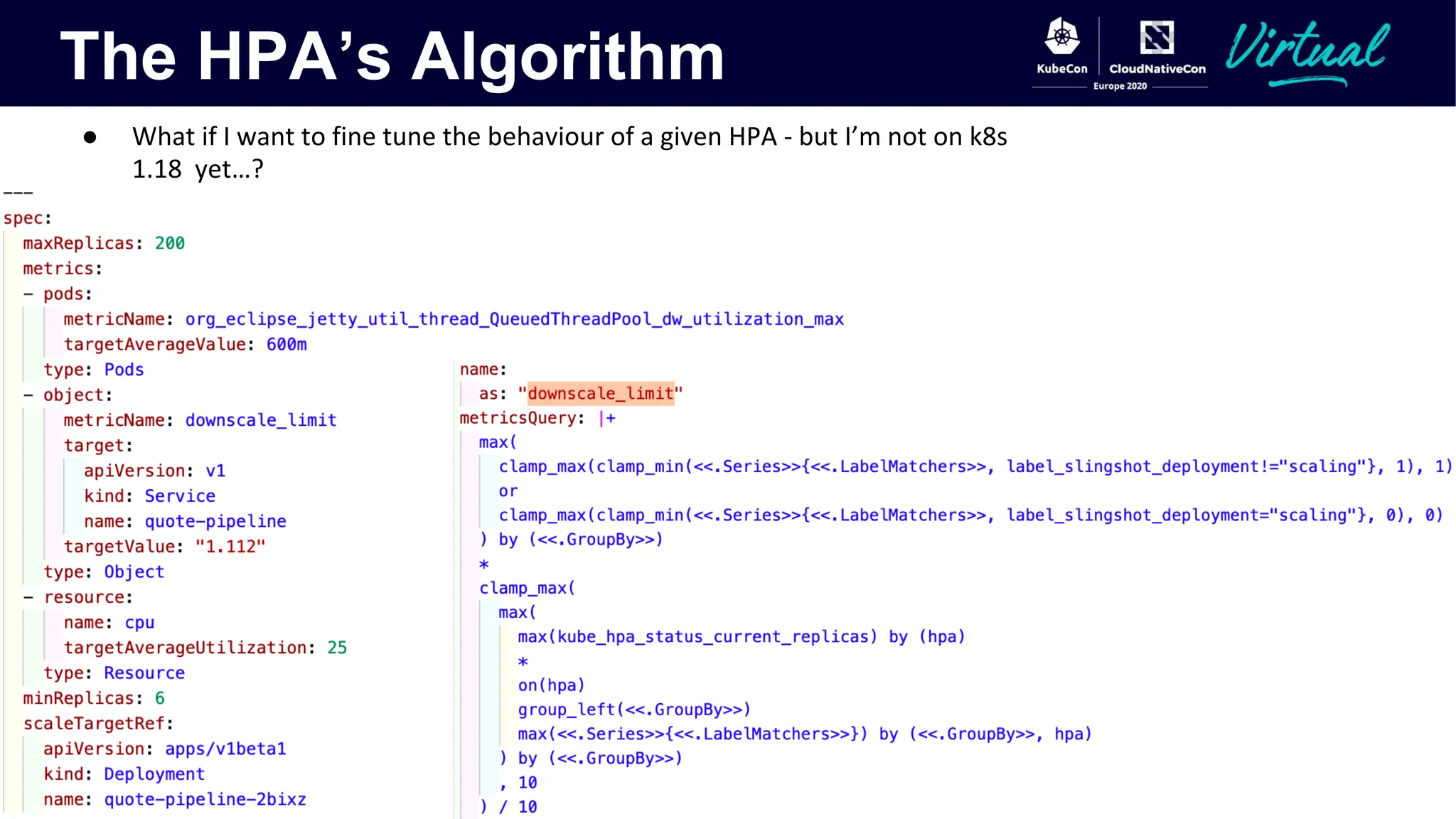
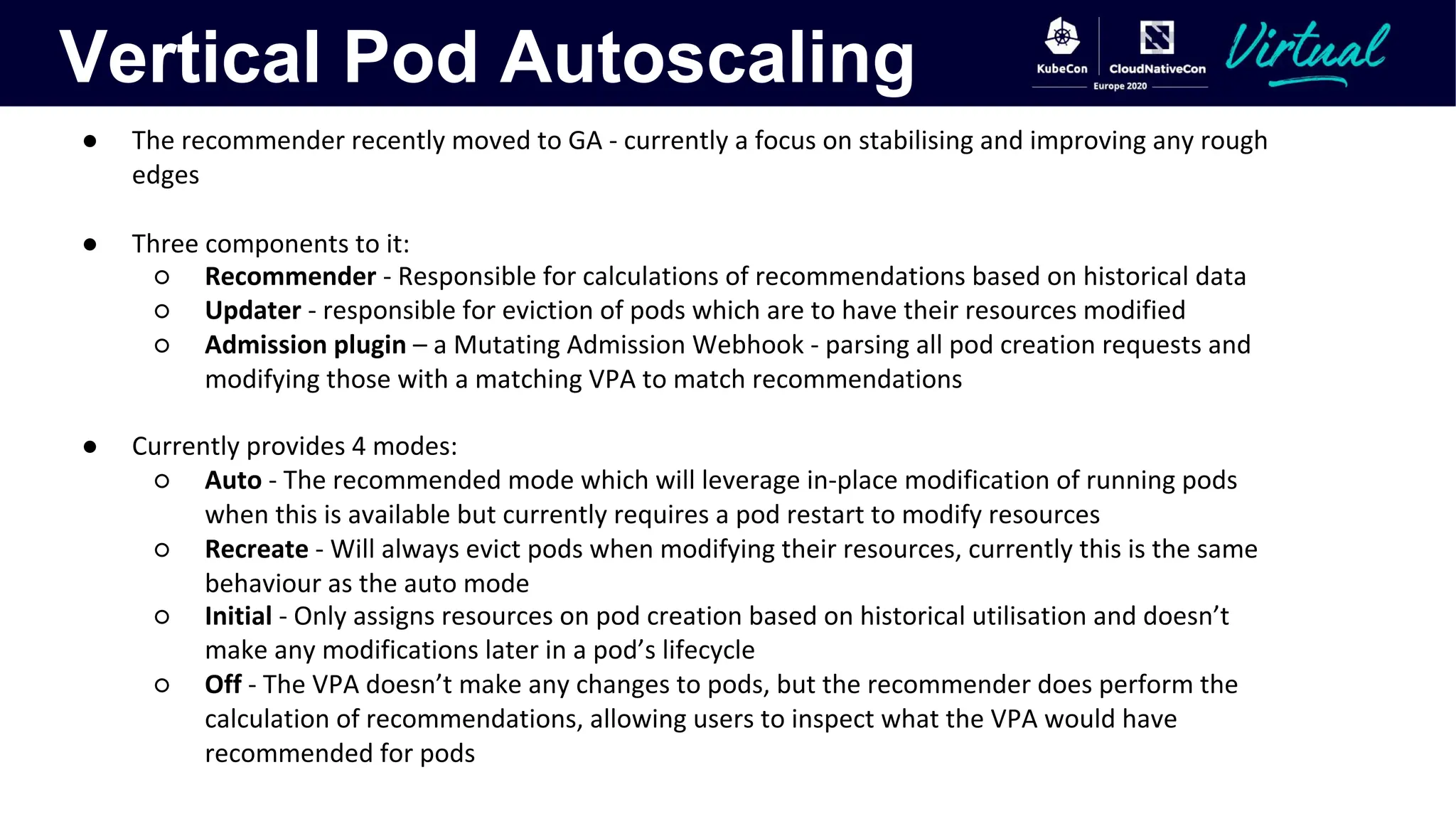
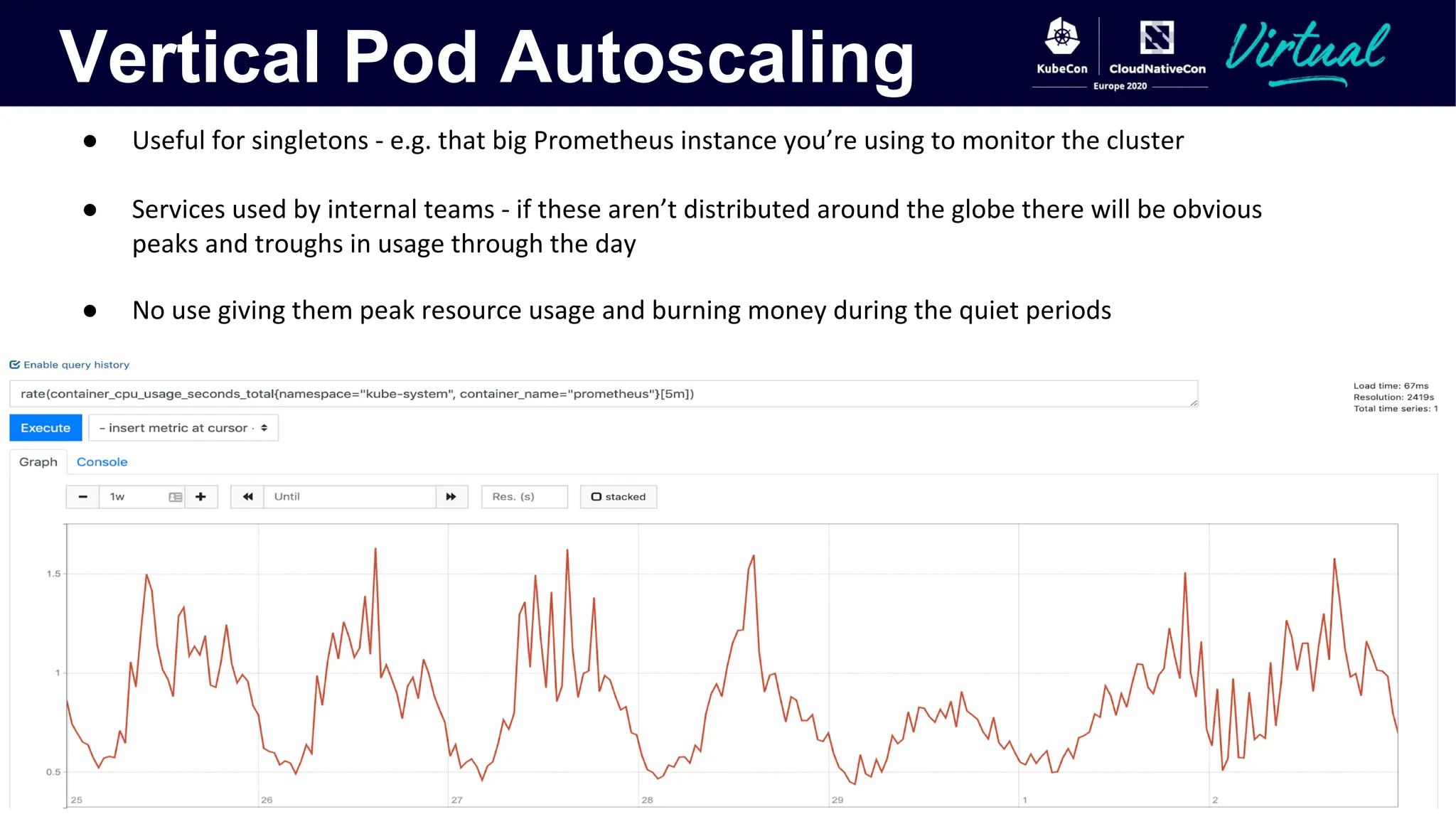
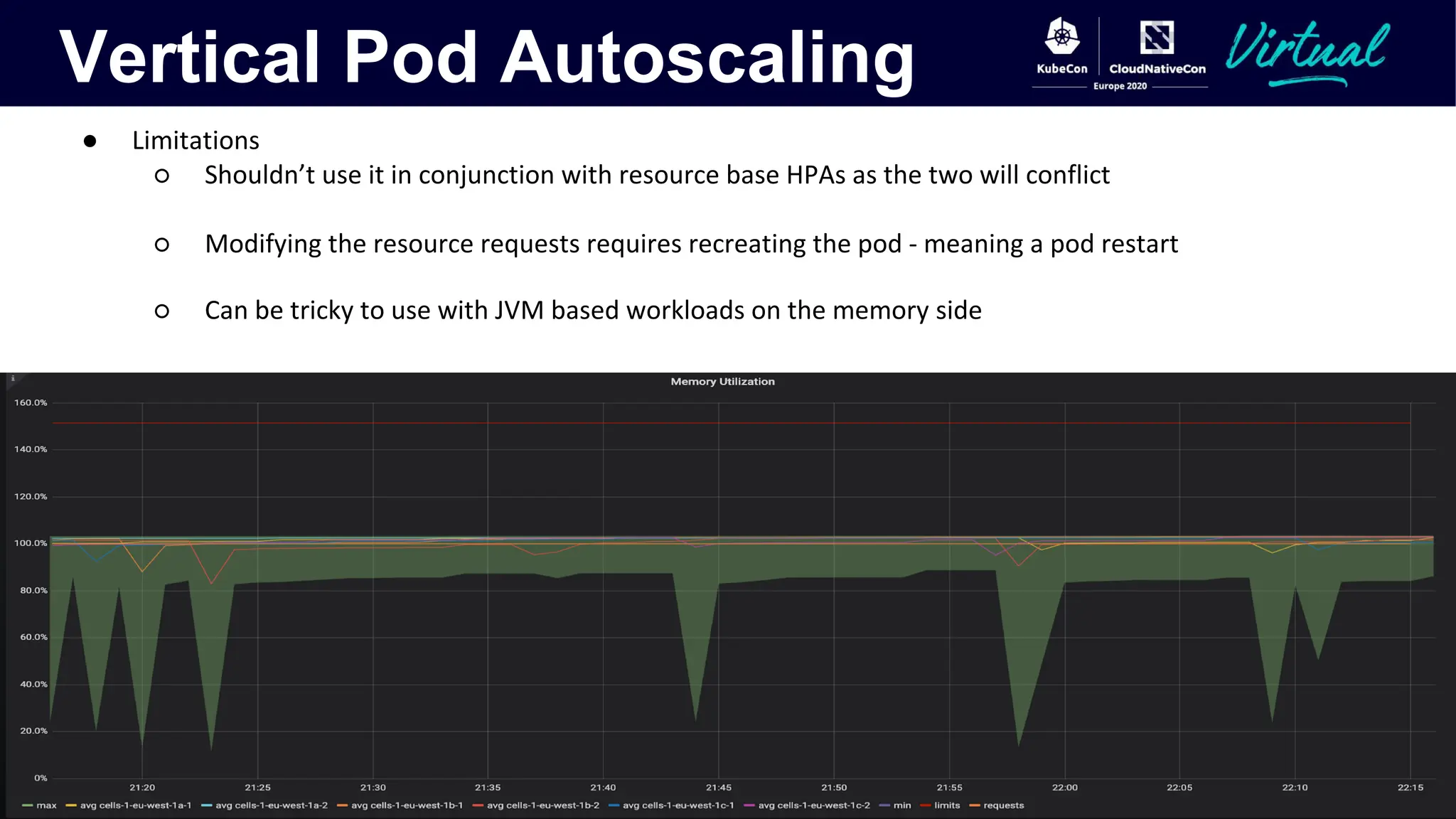
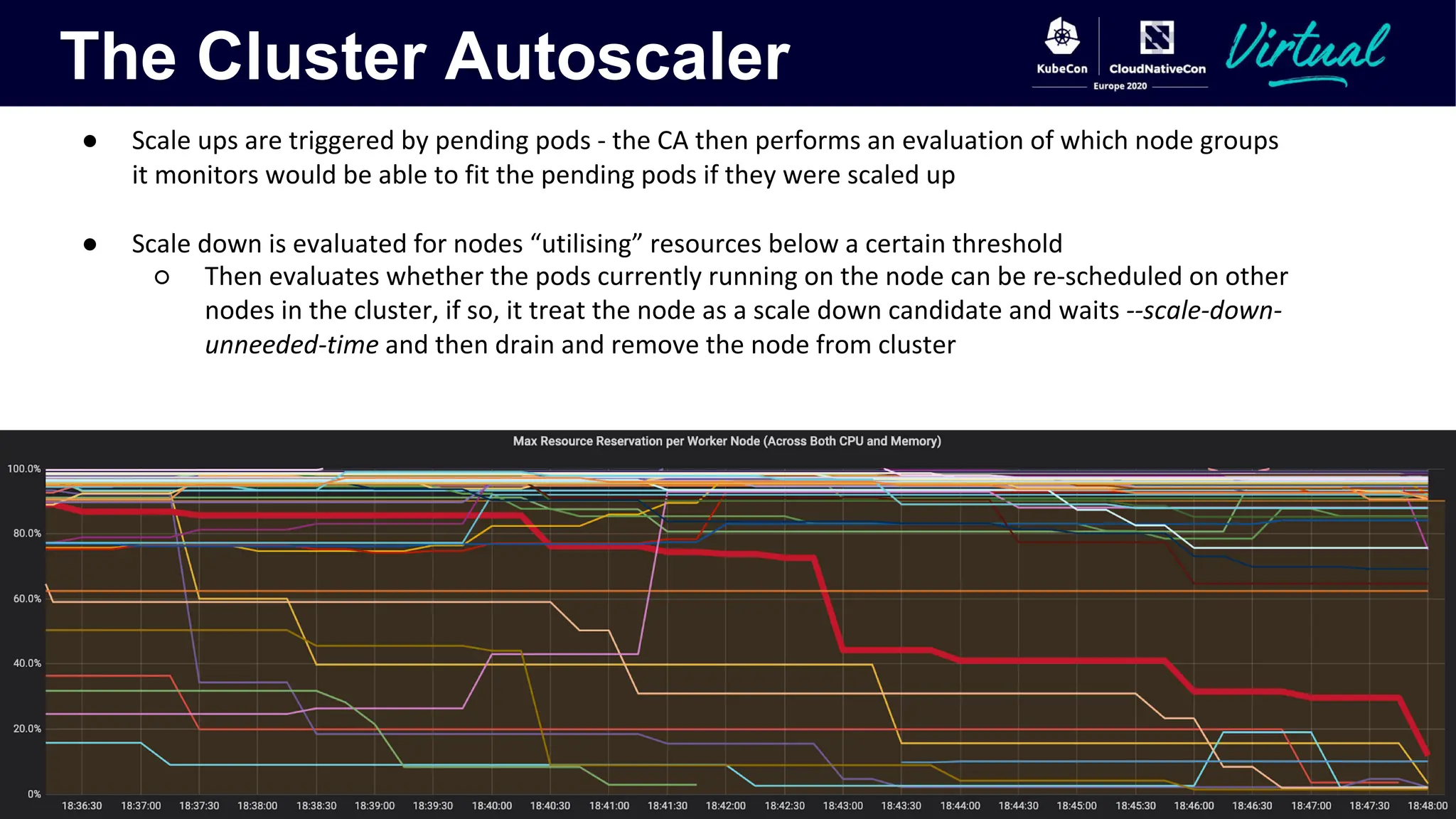
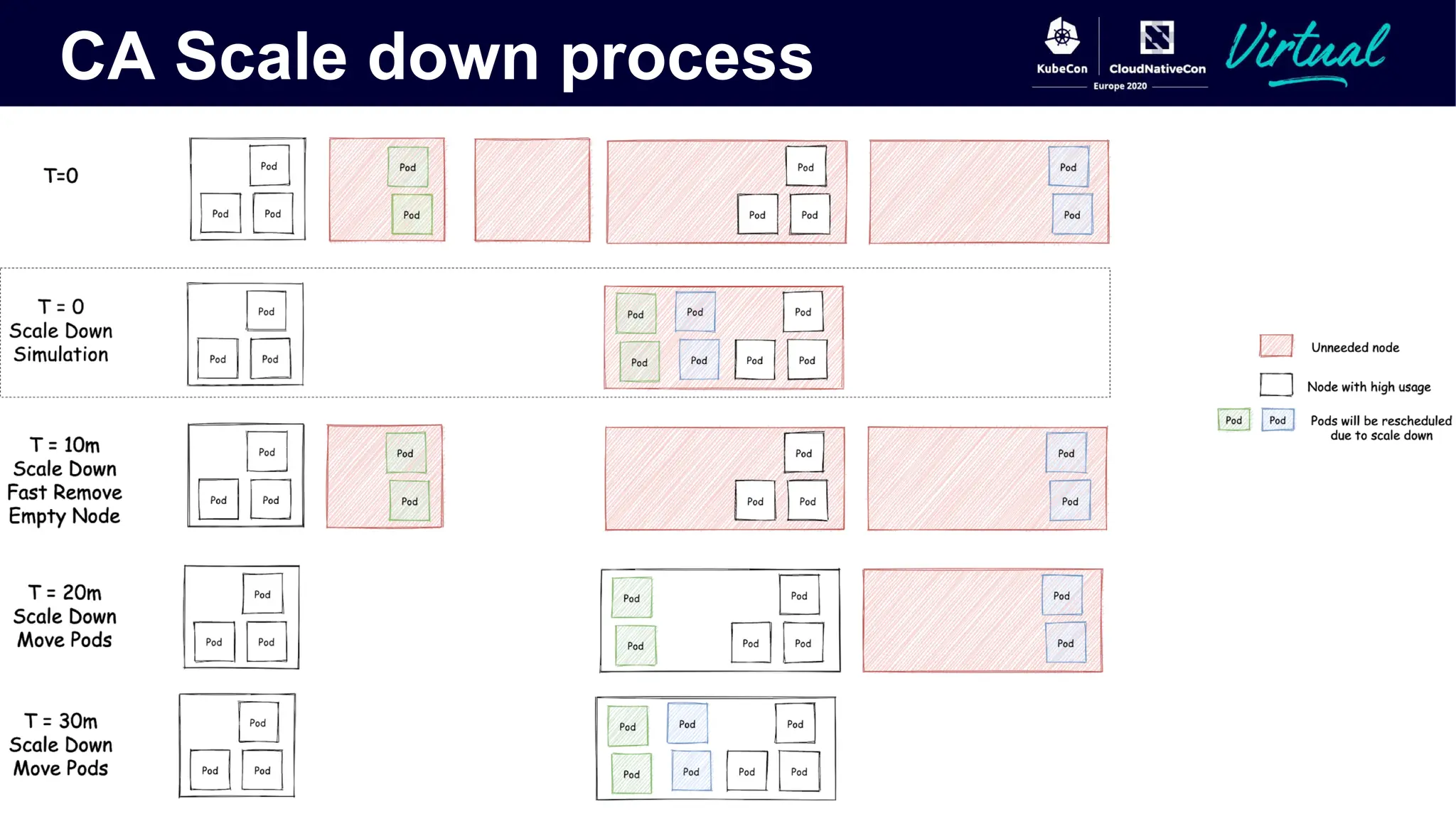
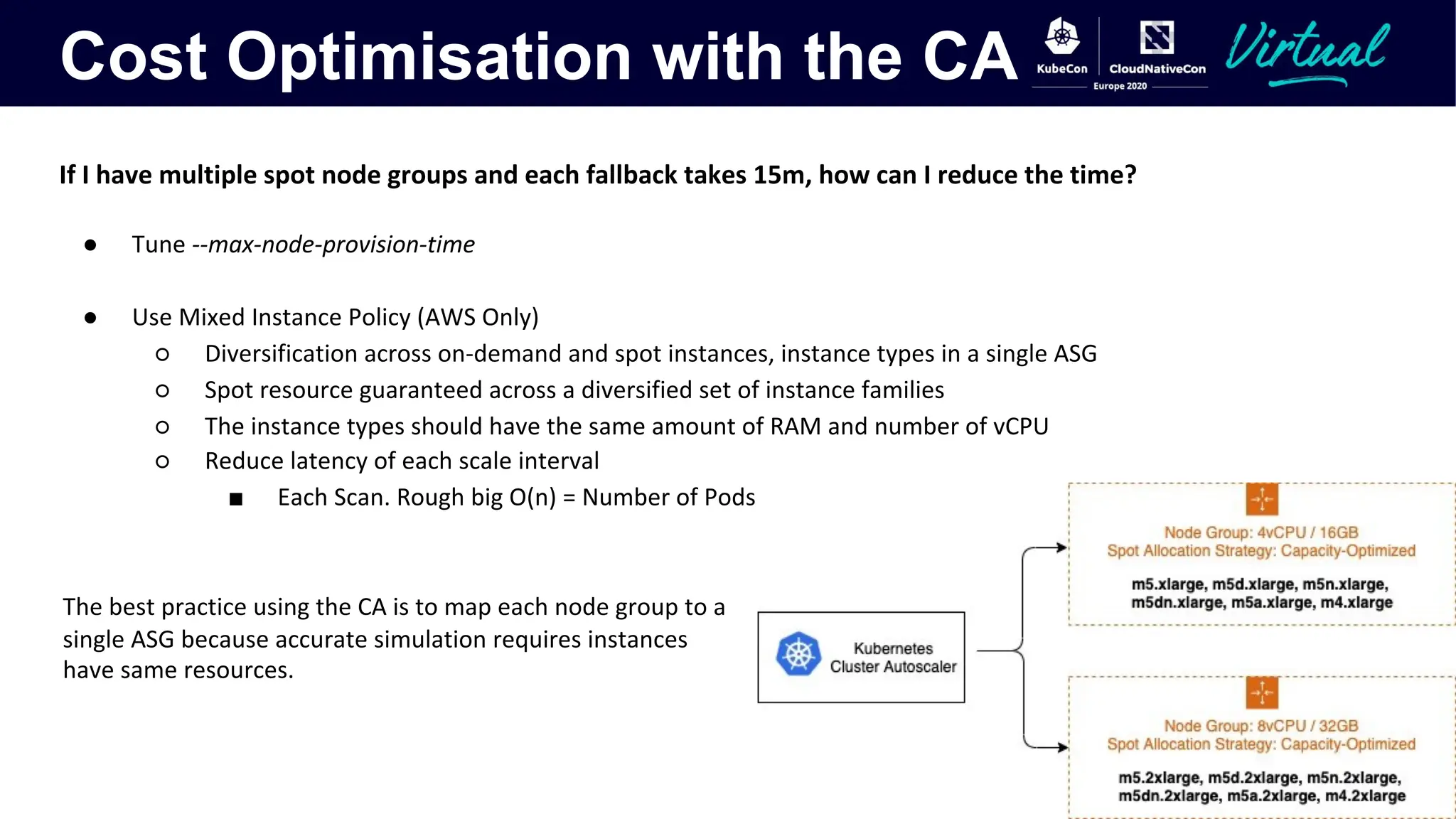
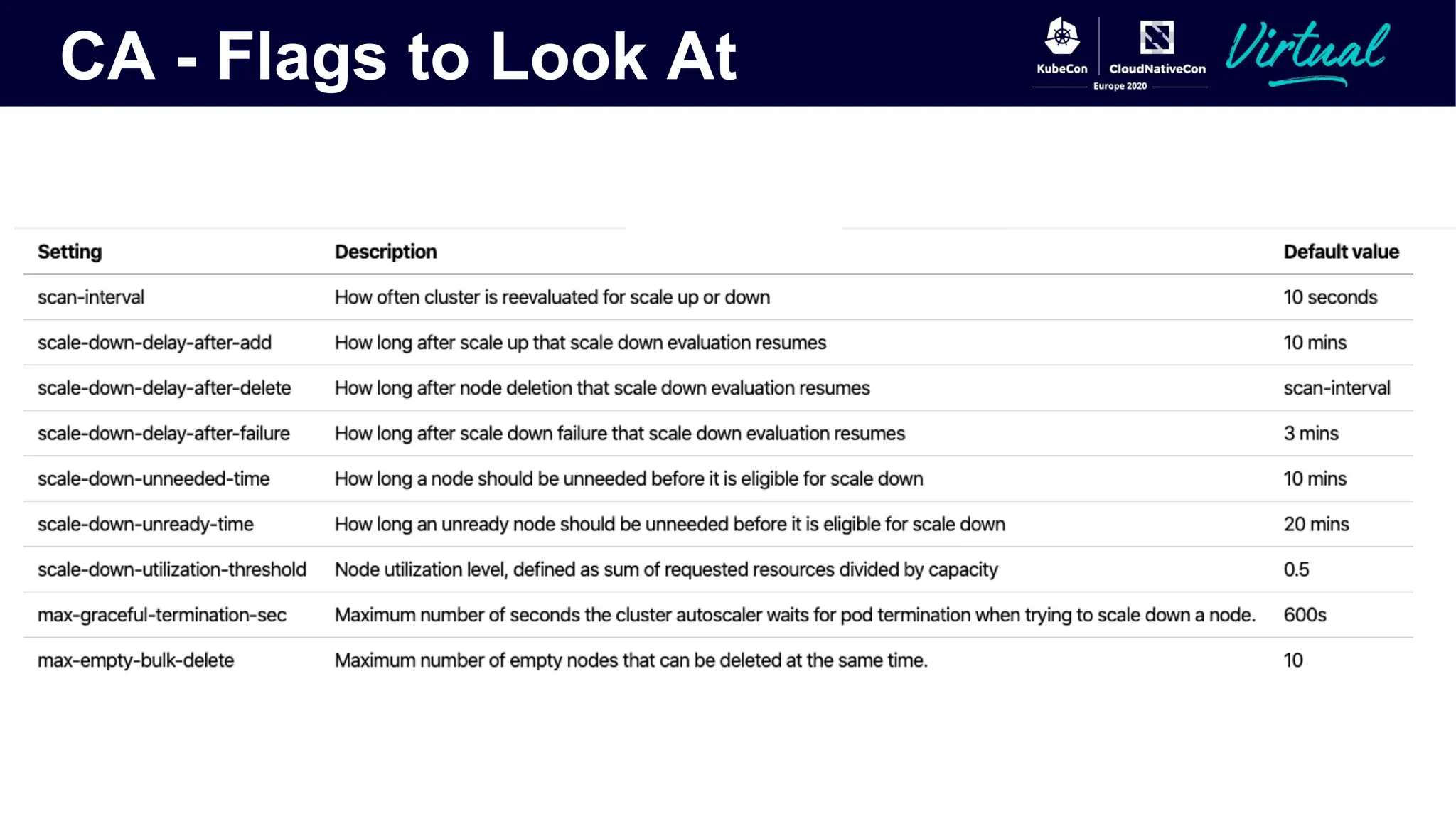
The document discusses Kubernetes autoscaling and cost optimization strategies, focusing on horizontal pod autoscaling (HPA), vertical pod autoscaling (VPA), and cluster autoscaling (CA). It highlights different metrics types for autoscaling, their implementations, and configurations, including the challenges and limitations associated with them. The document concludes that effective cost-saving requires understanding workloads, and emphasizes tuning HPA to realize substantial benefits.