Download to read offline




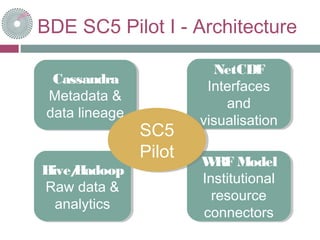






This document discusses using the BDE (Big Data Europe) platform to demonstrate downscaling of climatic and meteorological data, data ingestion and export, analytics capabilities, and data lineage tracking. The SC5 Pilot project ingests NetCDF files, performs WRF-based downscaling on institutional resources as requested, and maintains lineage records. Basic analytics like climate change indices are performed using Hive queries. Further development may investigate NetCDF transformations for WRF and test data lineage and downscaling customization. The BDE is expected to provide scalability, efficient resource use, and data reproducibility. Hands-on access to a Jupyter notebook is provided.










































































































