Downloaded 13 times






![Architecture
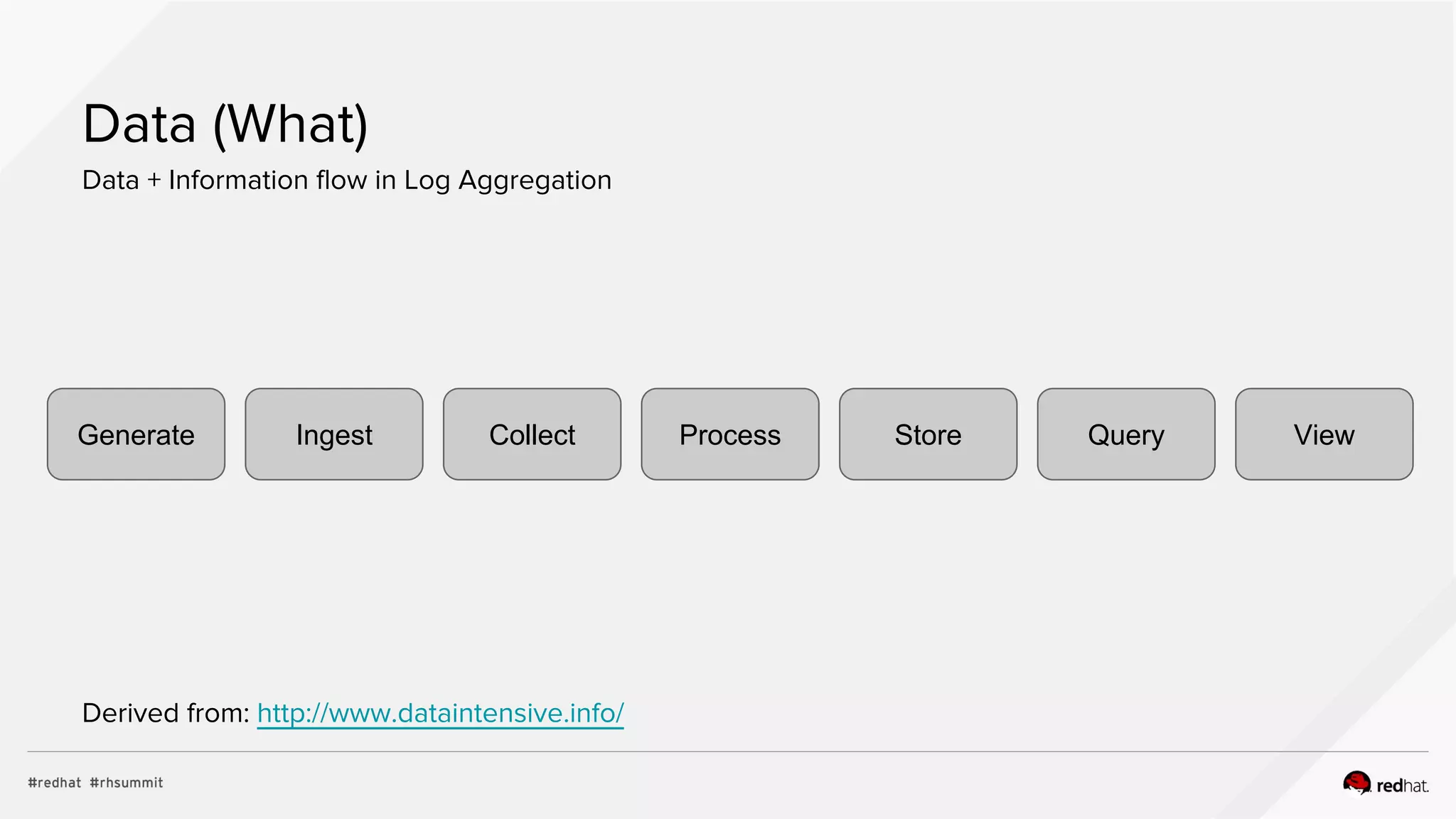
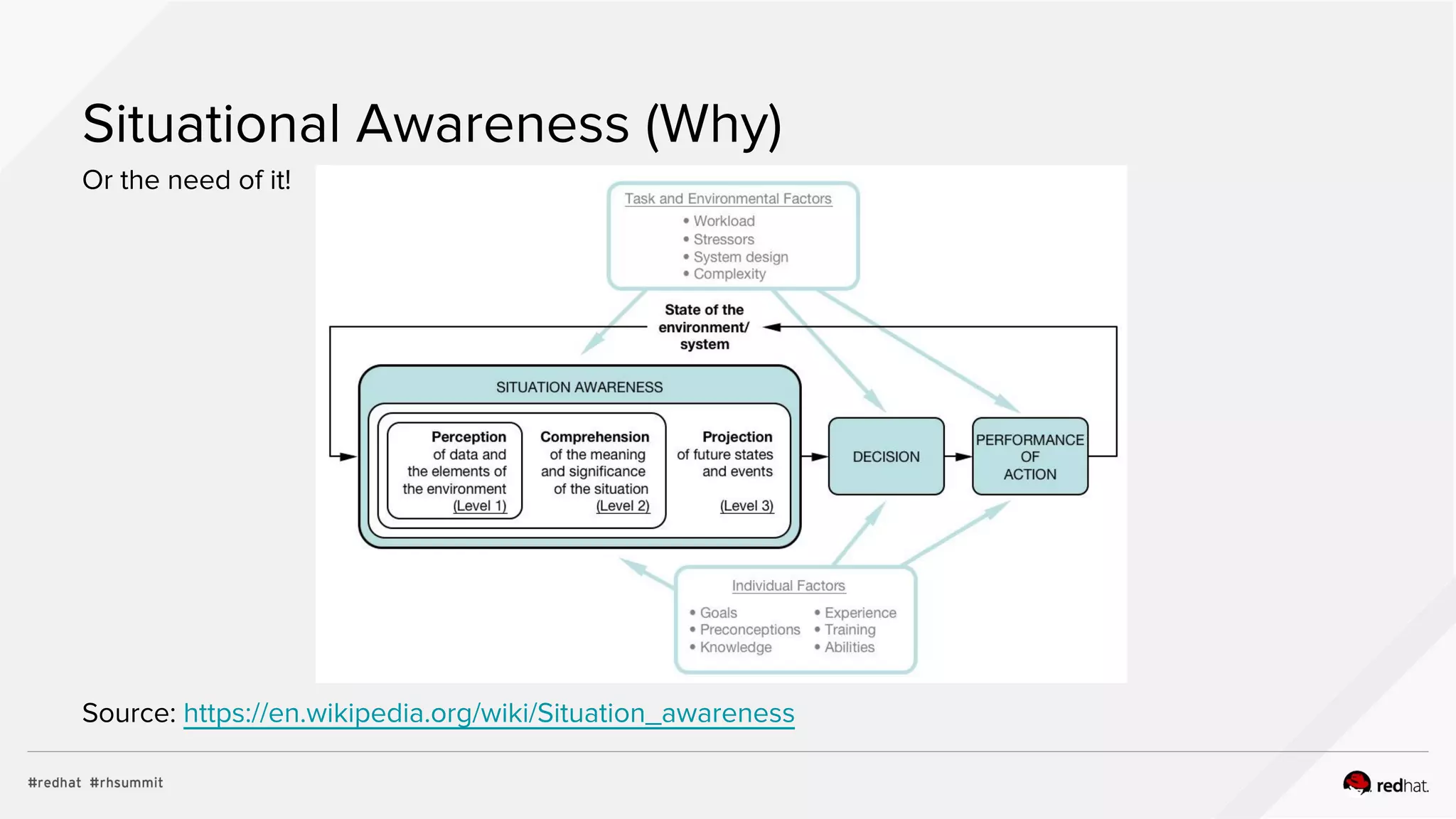
Proposed General Architecture
Real Time
Analytics
and
Response
Host
Bus
N N N
Archive
Data
Store
General
Visualization
M
C
M
C
Storage
Legend
M
C
N
Message
Client
Normalizer
C
C
C Collector
Slide Credit: Tushar Katarki [@tkatarki]](https://image.slidesharecdn.com/rhsummit2017-lt107508-bettermanagingyourredhatfootprintwithlogaggregation6-170508151347/75/Red-Hat-Summit-2017-LT107508-Better-Managing-your-Red-Hat-footprint-with-log-aggregation-12-2048.jpg)
![Implementation
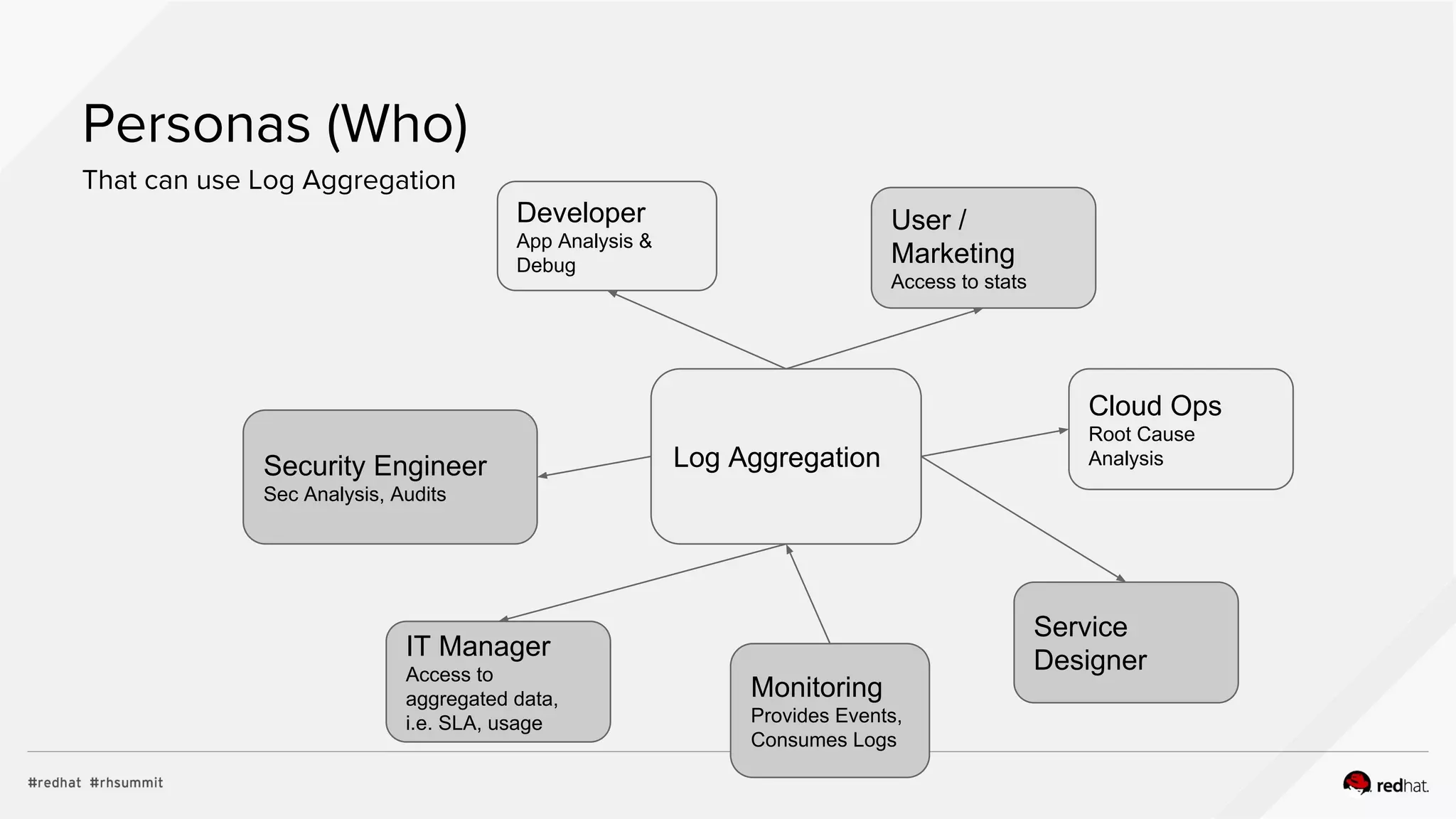
Introduction to EFK
KibanaElasticSearchLog Source Fluentd
User Interface for:
● Search
● Graph
● Dashboard
Index and store
data and metadata
making search
fast and reliable
● Parsing
● Filtering
● Enriching
● Deleting
● Output
Buffering
● TCP/UDP
● HTTP
● File: Text
● Stdout: CSV,
JSON,
MessagePack
● syslog/journal
Slide Credit: Tushar Katarki [@tkatarki]](https://image.slidesharecdn.com/rhsummit2017-lt107508-bettermanagingyourredhatfootprintwithlogaggregation6-170508151347/75/Red-Hat-Summit-2017-LT107508-Better-Managing-your-Red-Hat-footprint-with-log-aggregation-13-2048.jpg)
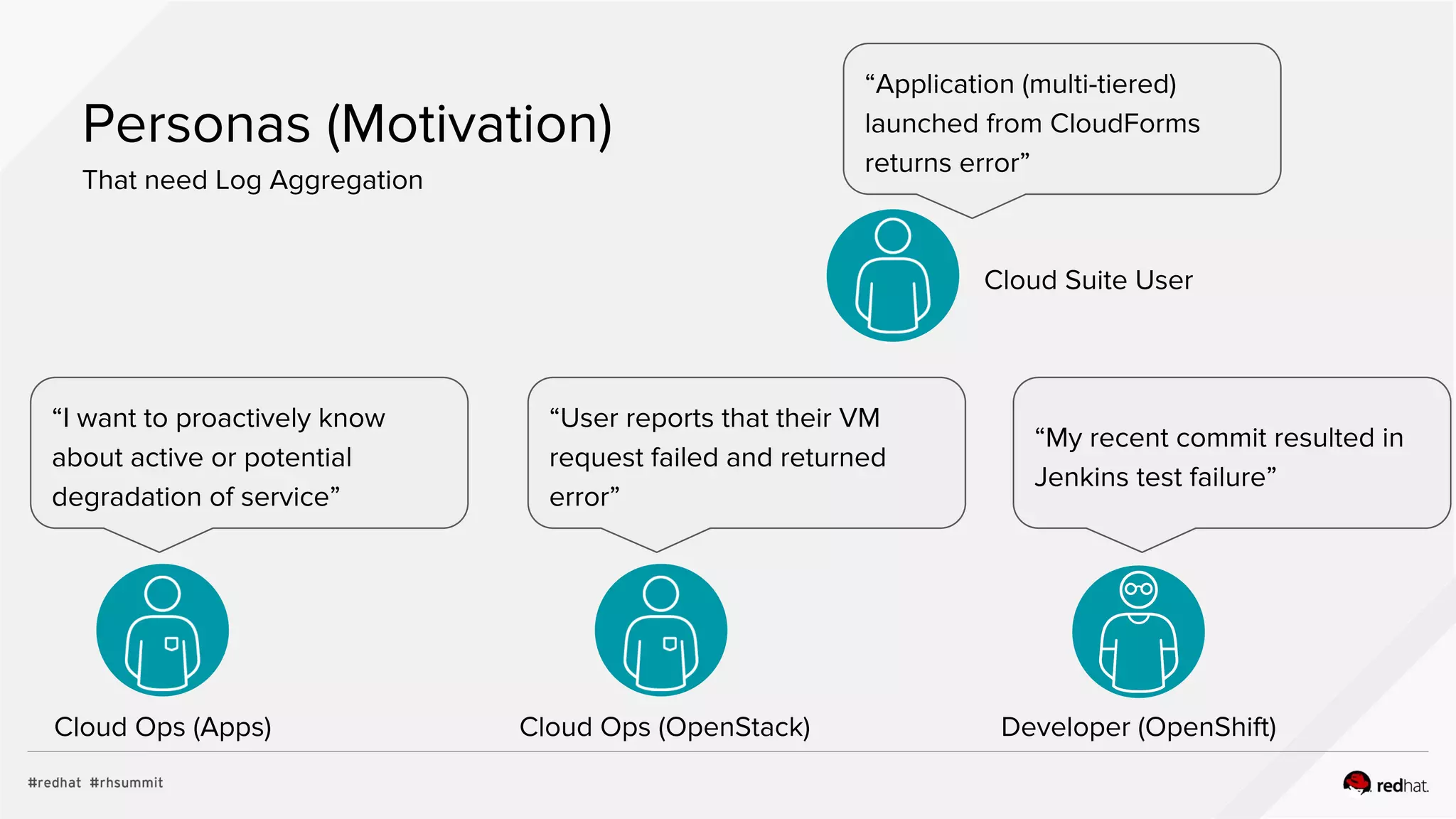
![Current Status
Being delivered and supported
OpenShift Container
Platform 3.5
● Full EFK stack provided
as containers
OpenStack Platform 10
● Fluentd as log collector
Red Hat Virtualization
● Coming Soon!
Log files
Journal Fluentd
Kuberentes
Services
Syslog
Master Nodes
Elastic
search
Kibana
...
Application Nodes
Log files
Journal Fluentd
App inside
container
Syslog
Infra Nodes
Elastic
search
Kibana
host logs
App inside
container
Elastic
search
Curator
Multi-Tenant
Access
Diagram Credit: Tushar Katarki [@tkatarki]](https://image.slidesharecdn.com/rhsummit2017-lt107508-bettermanagingyourredhatfootprintwithlogaggregation6-170508151347/75/Red-Hat-Summit-2017-LT107508-Better-Managing-your-Red-Hat-footprint-with-log-aggregation-14-2048.jpg)

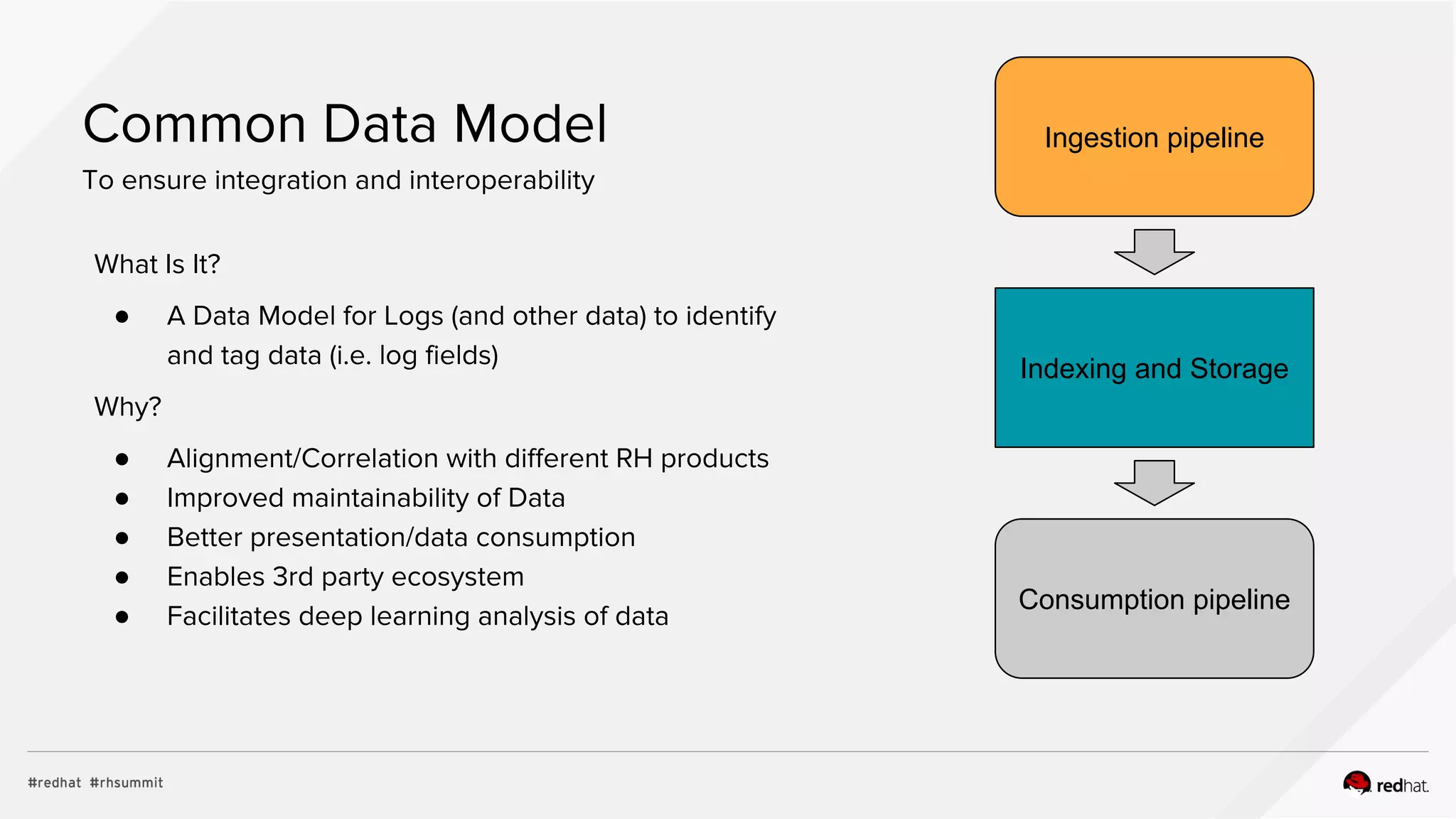
![Common Data Model
Example ...
Data extracted:
● Container name
● Pod name
● Namespace name
● Docker container ID
K8S data queried:
● Pod UID
● Pod labels
● Pod host
● Namespace UID.
All merged into output log in JSON Format
Images Credit: Anton Sherkhonov [@peatz]
CDM
A → 1
B → 2
C → 3](https://image.slidesharecdn.com/rhsummit2017-lt107508-bettermanagingyourredhatfootprintwithlogaggregation6-170508151347/75/Red-Hat-Summit-2017-LT107508-Better-Managing-your-Red-Hat-footprint-with-log-aggregation-17-2048.jpg)




The document discusses log aggregation strategies to efficiently manage Red Hat's cloud deployments, emphasizing the need for scalable solutions in multi-tenant environments. It outlines challenges faced in data processing and the proposed architecture using EFK (Elasticsearch, Fluentd, Kibana) for real-time analytics and monitoring. Additionally, it presents a common data model to enhance interoperability and data consumption across different Red Hat products.




























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)






