Downloaded 14 times






![Feature–oriented domain analysis [Kang 1990]
• Feature models = a
lightweight method for
defining a space of options
• De facto standard for
modeling variability
8
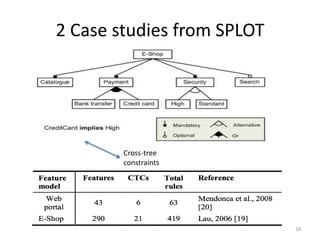
Cross-Tree Constraints
Cross-Tree Constraints](https://image.slidesharecdn.com/sayyadslidesicse13v2-130525131101-phpapp02/85/On-the-Value-of-User-Preferences-in-Search-Based-Software-Engineering-8-320.jpg)

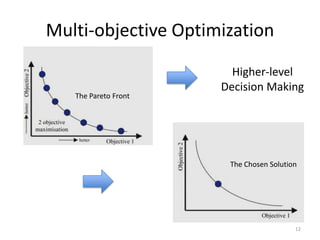
![Survival of the fittest
(according to NSGA-II [Deb et al. 2002])
13
Boolean dominance (x Dominates y, or does not):
- In no objective is x worse than y
- In at least one objective, x is better than y Crowd
pruning](https://image.slidesharecdn.com/sayyadslidesicse13v2-130525131101-phpapp02/85/On-the-Value-of-User-Preferences-in-Search-Based-Software-Engineering-13-320.jpg)
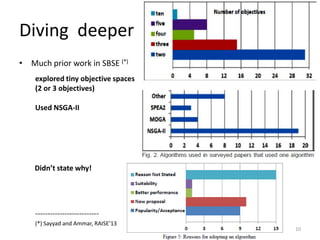
![Tinkering with small stuff…
ssNSGA-II: steady state [Durillo ‘09+
14
Other Algorithms: Ranking criteria:
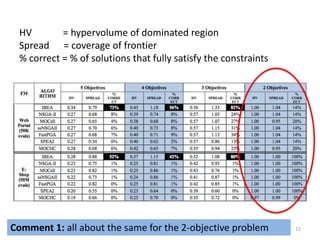
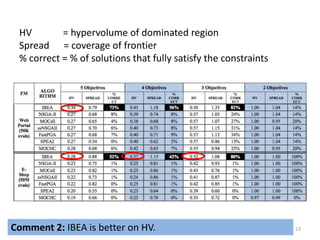
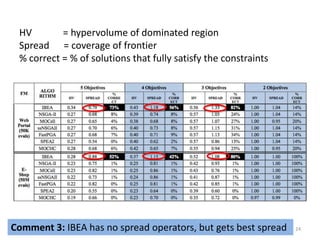
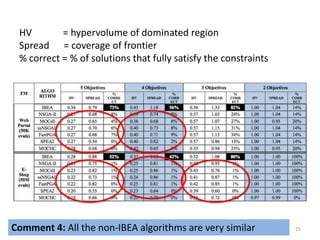
NSGA-II
SPEA2 *Zitzler ‘01+ More focus on diversity, with a
new diversity measure.
FastPGA [Eskandari ‘07+
Borrowed criteria from
NSGA-II, and diversity
measure from SPEA2
MOCell (Cellular GA) [Nebro ‘09] NSGA-II
NSGA-IIMOCHC (re-designed selection, crossover,
and mutation) [Nebro ‘07+
Boolean Dominance
Boolean Dominance
Boolean Dominance
Boolean Dominance
Boolean Dominance](https://image.slidesharecdn.com/sayyadslidesicse13v2-130525131101-phpapp02/85/On-the-Value-of-User-Preferences-in-Search-Based-Software-Engineering-14-320.jpg)




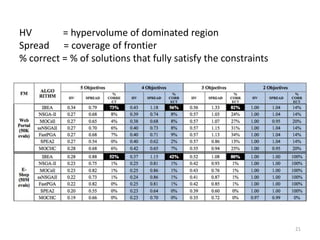
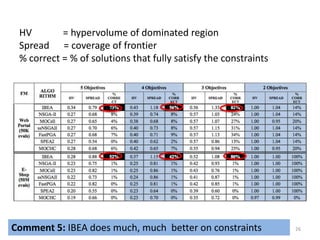
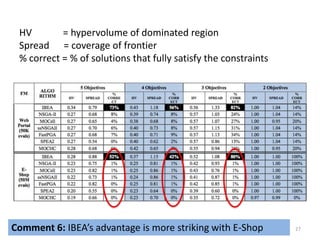




The document discusses the importance of user preferences in search-based software engineering (SBSE), focusing on evolutionary algorithms and their ability to optimize software product lines. It highlights the transition from product-based software to app-based solutions, emphasizing the need for rapid reconfiguration to meet diverse user needs. The study also presents empirical results suggesting that the indicator-based evolutionary algorithm (IBEA) outperforms traditional methods like NSGA-II and SPEA2 in handling multi-objective optimization and user preferences.



































































