Download as PDF, PPTX













![Step 1: Preprocessing of Data
1. Replace each appearance of a
product/company/author by generalized
[product], [company], [author], etc.
2. Remove all HTML tags and special symbols
from review text.](https://image.slidesharecdn.com/cs626-sarcasmandthwarting-nov13-131115101715-phpapp02/75/Sarcasm-Thwarting-in-Sentiment-Analysis-IIT-Bombay-15-2048.jpg)
![Step 2: Creating Feature Vectors
Pattern Based Features:
1. Classify words into High Frequency Words (HFWs) and
Content Words (CWs)
All [product], [company] tags and punctuation marks are
HFWs.
2. A pattern is a sequence of HFWs with slots for CWs.
Example: “Garmin does not care about product quality or
customer support” has patterns “[company] does not CW
about CW CW” or “about CW CW or CW CW”, etc.](https://image.slidesharecdn.com/cs626-sarcasmandthwarting-nov13-131115101715-phpapp02/75/Sarcasm-Thwarting-in-Sentiment-Analysis-IIT-Bombay-16-2048.jpg)

![Punctuation Based Features
●
●
●
●
●
Sentence length in words
Number of “!” characters
Number of “?” characters
Number of quotes
Number of capitalized/all capital words
Features are normalized to be in [0-1] by dividing them by
maximal observed value](https://image.slidesharecdn.com/cs626-sarcasmandthwarting-nov13-131115101715-phpapp02/75/Sarcasm-Thwarting-in-Sentiment-Analysis-IIT-Bombay-18-2048.jpg)



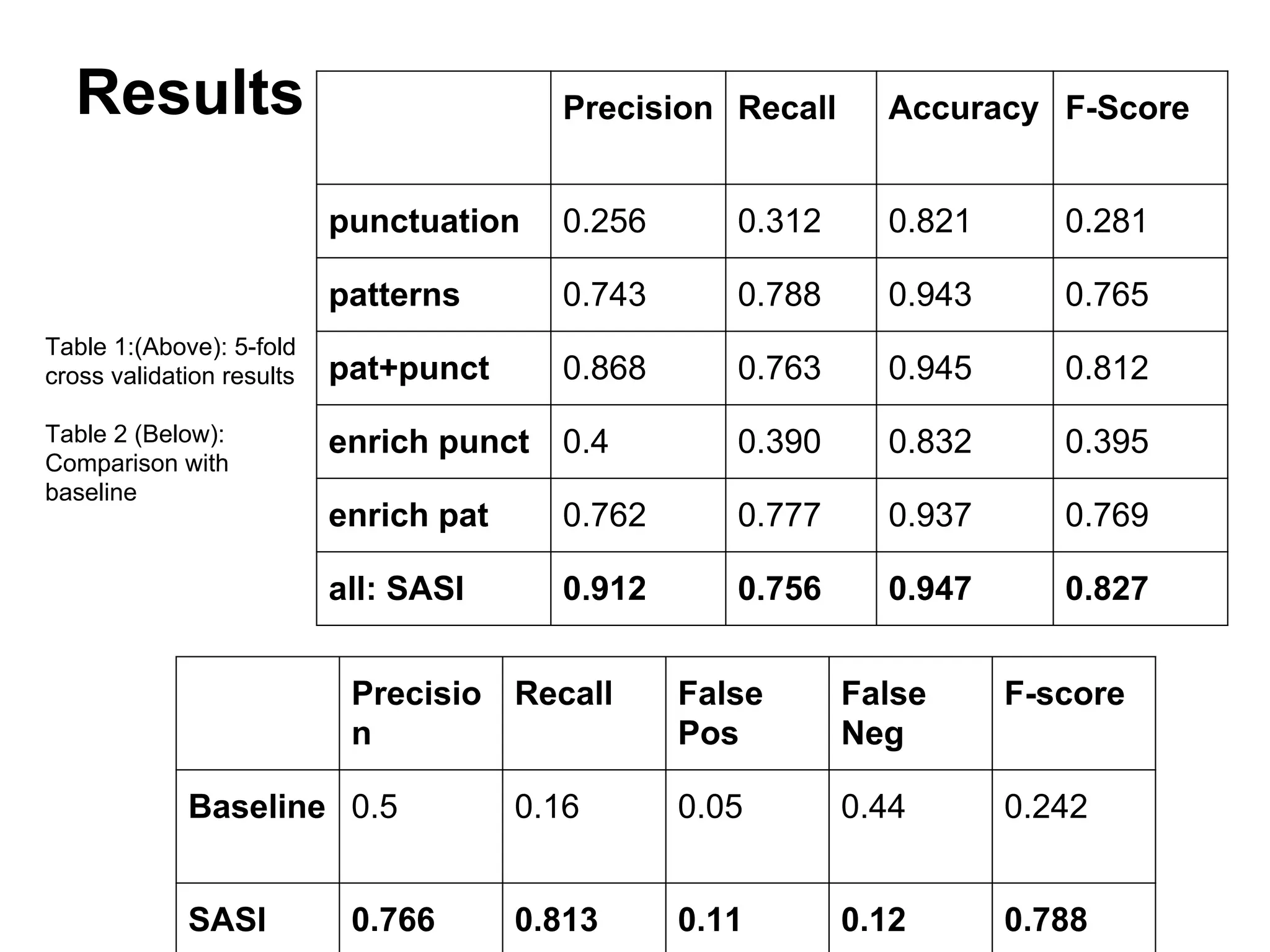




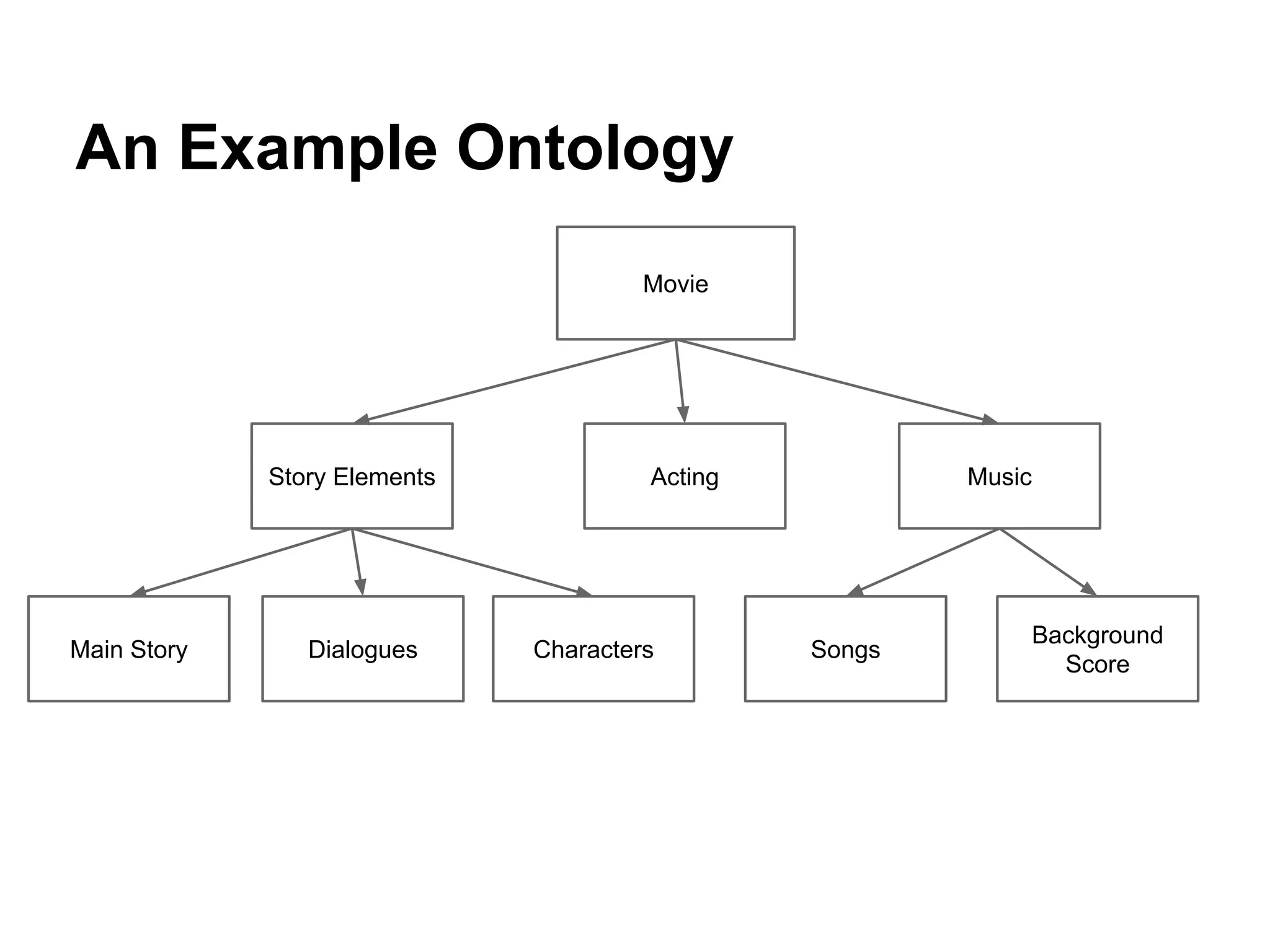


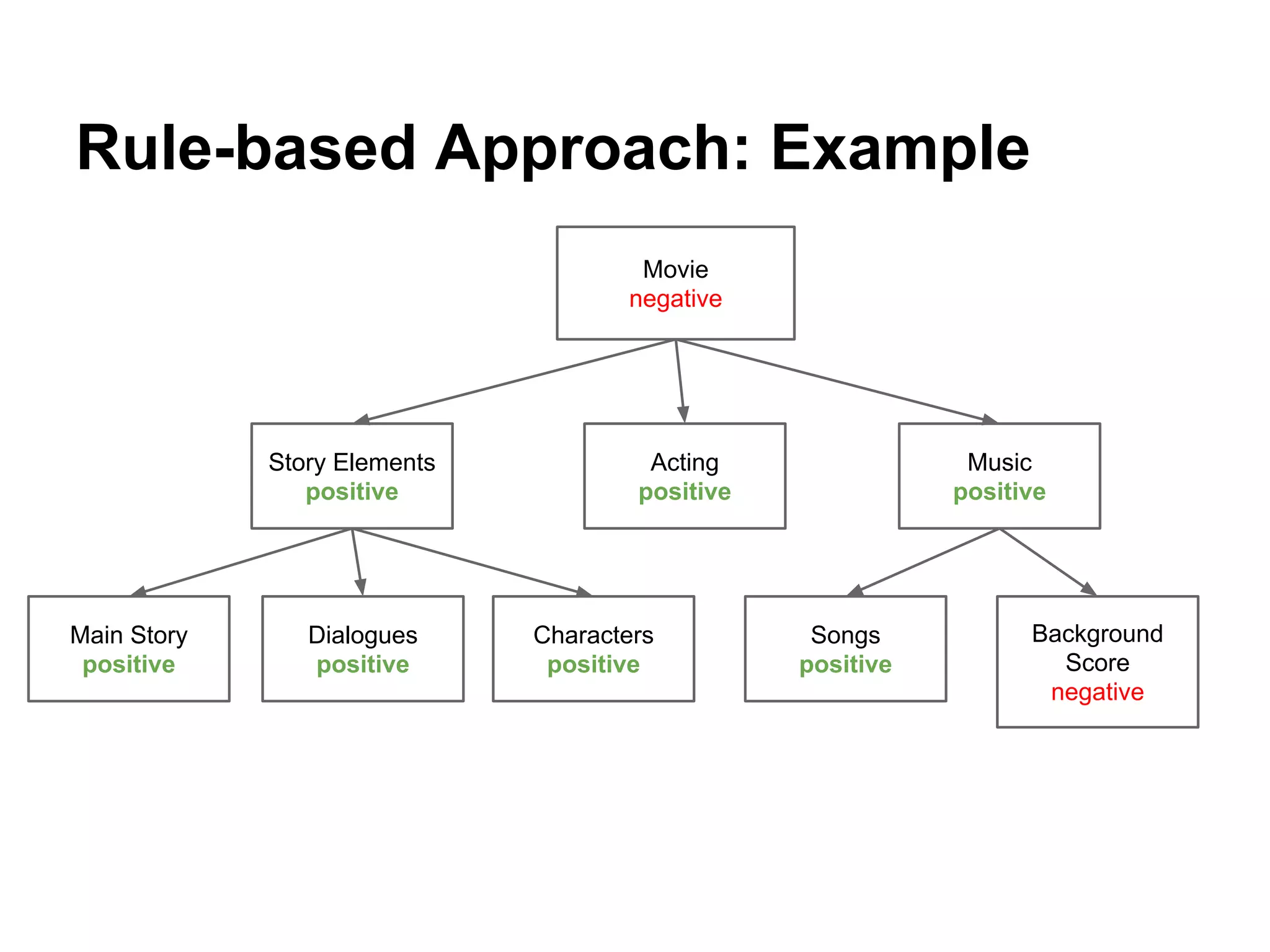




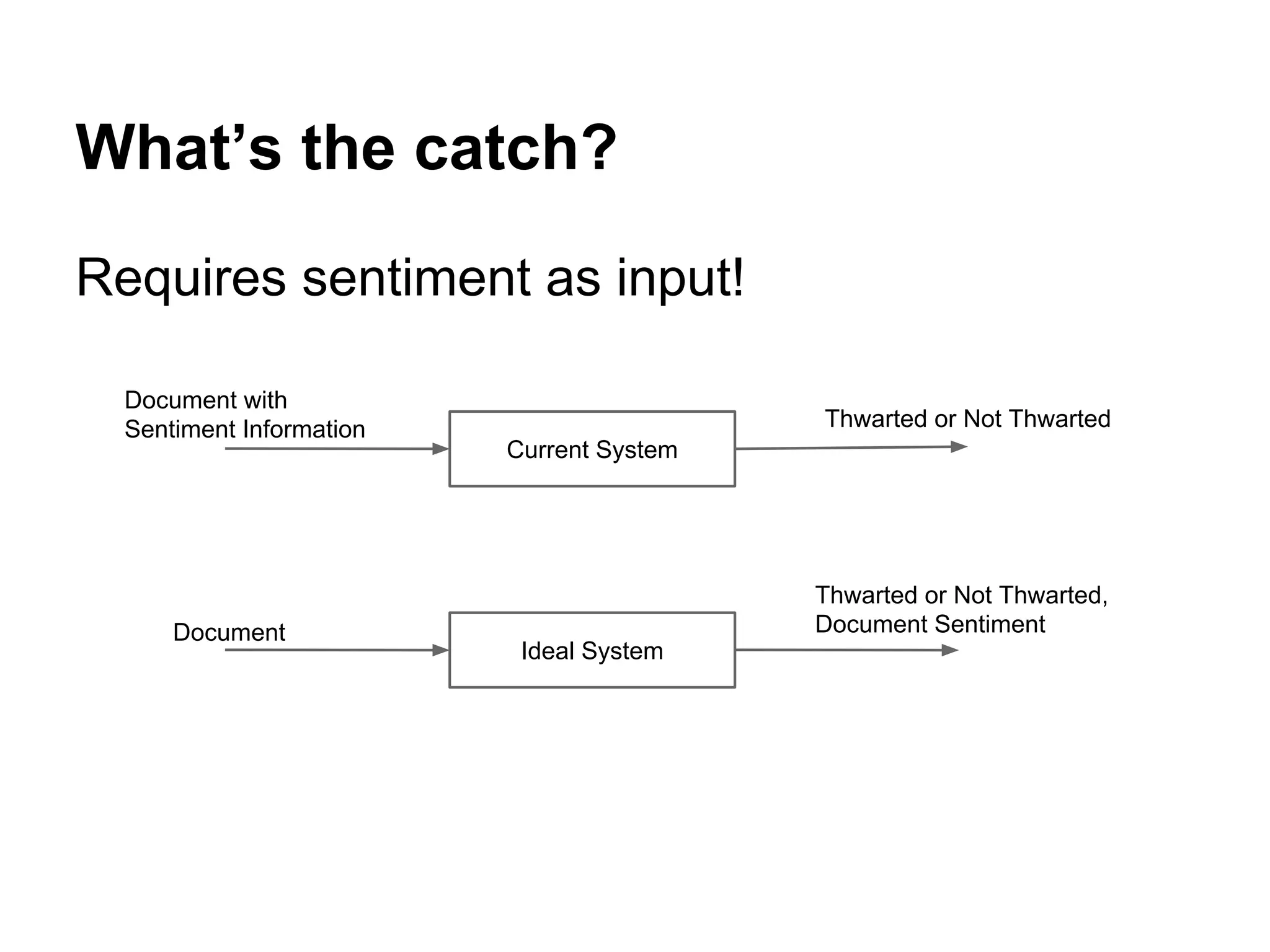




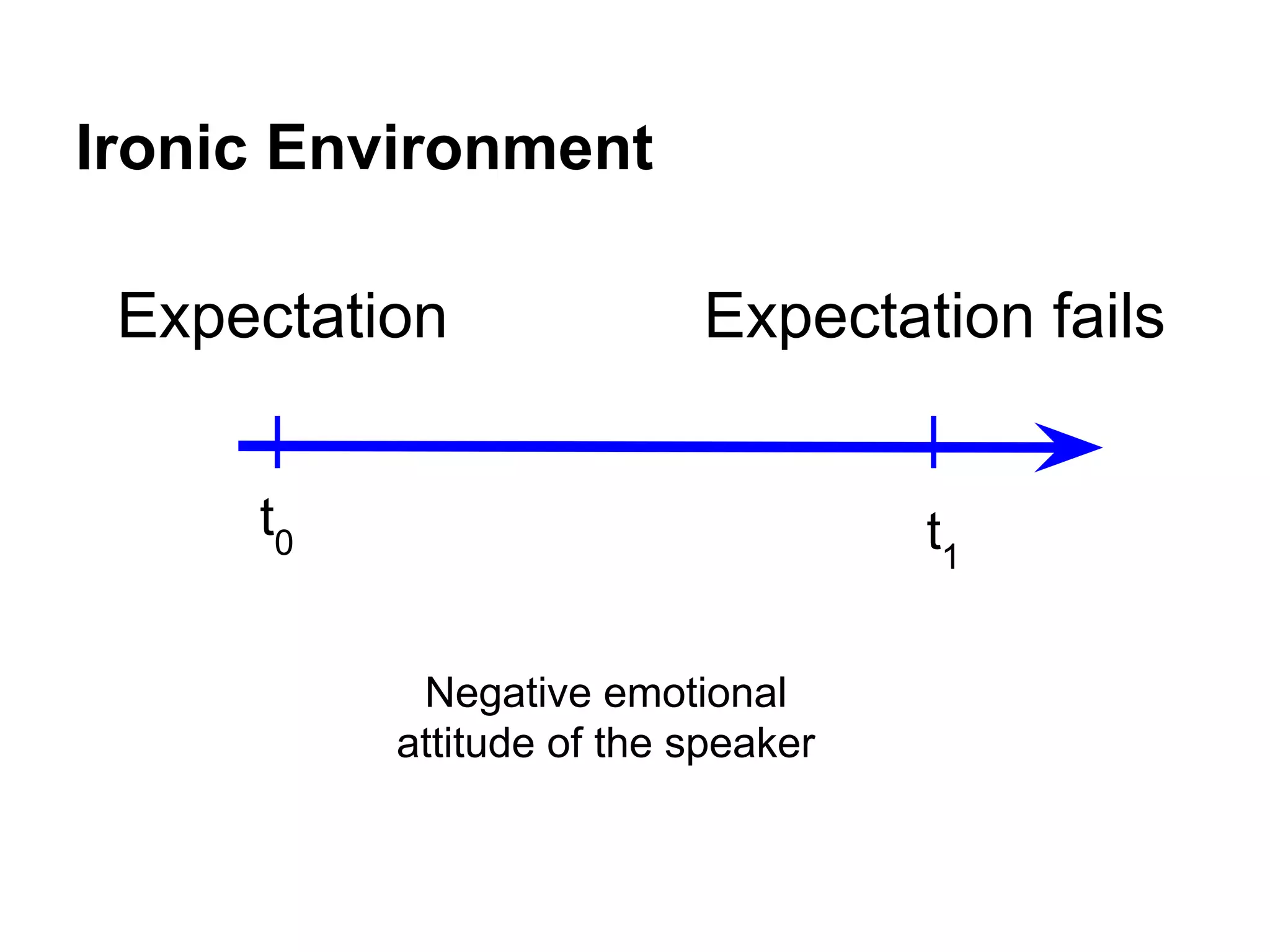
1) The document discusses various linguistic phenomena including irony, sarcasm, and thwarting. It presents algorithms for detecting sarcasm and thwarting in text. 2) For sarcasm detection, a semi-supervised algorithm uses pattern-based and punctuation-based features to classify sentences, achieving up to 81% accuracy. 3) Thwarting detection compares sentiment across levels of a domain ontology, using either rule-based or machine learning approaches, with the latter approach achieving up to 81% accuracy.















![NLP Asignment Final Presentation [IIT-Bombay]](https://cdn.slidesharecdn.com/ss_thumbnails/final-presentation-131213084802-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









![MTech Seminar Presentation [IIT-Bombay]](https://cdn.slidesharecdn.com/ss_thumbnails/seminar-presentation-final-140502111554-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)











































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














