Downloaded 33 times



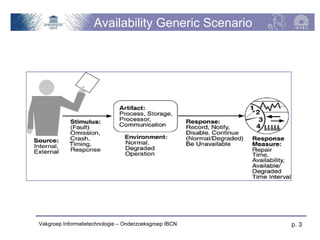




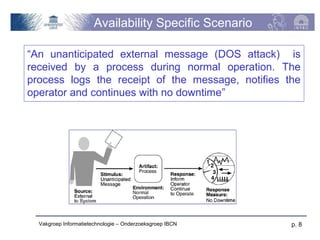

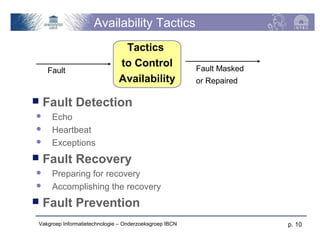





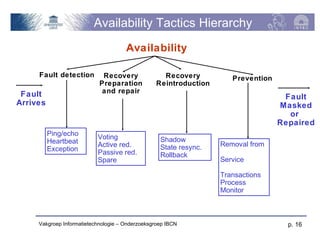

The document discusses software architecture quality attributes, specifically focusing on availability and its critical impact on system performance in light of faults and failures. It outlines generic and specific scenarios illustrating how systems should respond to and recover from failures, detailing various tactics for fault detection, recovery, and prevention. Key concepts include the differentiation of fault types, measures of availability, and the importance of system responses based on environmental conditions.












































































