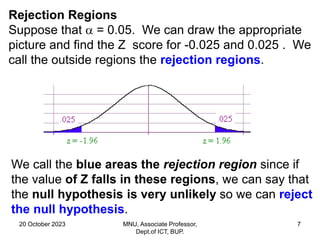
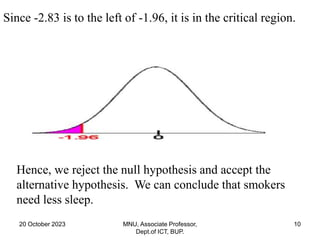
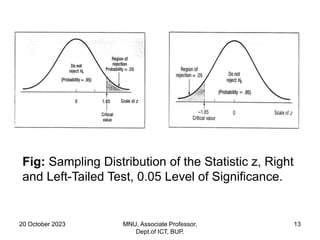
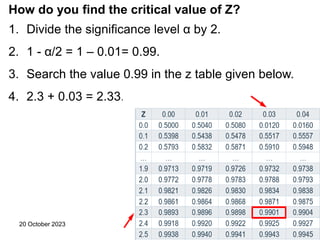
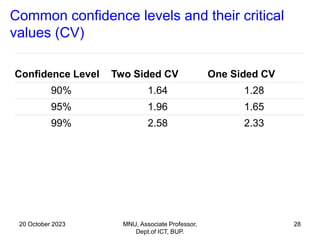
This document contains a presentation on hypothesis testing given by Dr. Mohammed Nasir Uddin. The presentation covers topics such as the definition of a hypothesis, null and alternative hypotheses, one-tailed and two-tailed tests, types of errors in hypothesis testing, p-values, and the steps to conduct hypothesis testing. Examples are provided to illustrate key concepts like computing rejection regions, concluding whether to reject or fail to reject the null hypothesis based on test statistics, and testing hypotheses about population means.