Download as PDF, PPTX


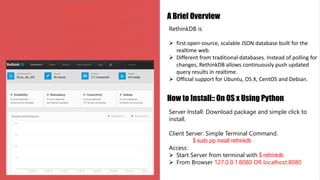
![Data manipulation
Database Creation
From GUI.
Or
From Python Shell: r.db_create(“library”).run()
Table Creation
From GUI.
Or
From Python Shell: r.db(“library”).table_create(“Book”).run()
Insert Data :: From Python Shell
Book.insert({ "BookID":"123", "Author": "Date",
"Title":"Introduction to DBS"}, { "BookID": "234",
"Author":"Jones", "Title": "Algorithms"}, { "BookID": "345",
"Author": "Kings", "Title": "Operating Systems"}).run()
Delete Data:: From Python Shell
r.table(“Book”).filter(r.row[“Author”] ==
“Kings”).delete().run()](https://image.slidesharecdn.com/rethinkdbzicoabhidey-150708084215-lva1-app6891/85/Rethinkdb-3-320.jpg)
![Programmatic access
officially support for client drivers javascript, ruby and
python. You can run queries from the command shell.
Query a
print r.table('Book').pluck('Title').run()
Query b
print r.table('Book').inner_join(r.table('BookLending'), lambda
x ,y: x["BookID"] == y["BookID"]).zip().run()
Query c
print r.table('Book').inner_join(r.table('BookLending'), lambda
x ,y: x["BookID"] ==
y["BookID"]).zip().filter(r.row["ReturnDate"] < '27-10-
2012').run()
Query d
print r.table('Book').inner_join(r.table('BookLending'), lambda
x ,y: x["BookID"] ==
y["BookID"]).zip().inner_join(r.table('Reader'), lambda x ,y:
x["ReaderID"] ==
y["ReaderID"]).zip().filter(r.row["Name"]=='Peter').run()](https://image.slidesharecdn.com/rethinkdbzicoabhidey-150708084215-lva1-app6891/85/Rethinkdb-4-320.jpg)

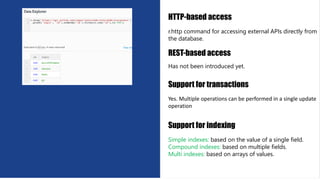
![Aggregation
Yes the system supports aggregation operations like
SUM, COUNT, MAX
Query e:: from Python Shell
print r.table('BookLending').inner_join(r.table('Reader'),
lambda x ,y: x["ReaderID"] ==
y["ReaderID"]).zip().filter(r.row["Name"] ==
'Laura').count().run()
Query e:: from Data Explorer
r.table('BookLending').innerJoin(r.table('Reader'),
function(marvelRow, dcRow) { return
marvelRow('ReaderID').eq(dcRow('ReaderID'))
}).zip().filter(r.row("Name").eq('Laura')).count()](https://image.slidesharecdn.com/rethinkdbzicoabhidey-150708084215-lva1-app6891/85/Rethinkdb-7-320.jpg)


RethinkDB is an open-source, scalable JSON database built for real-time applications that allows data to be continuously pushed to clients in real-time instead of polling for changes like traditional databases. It supports installation on Ubuntu, OS X, CentOS and Debian and programmatic access through JavaScript, Ruby, and Python drivers. Queries can be run from the command line or through RethinkDB's own declarative query language called Reql. RethinkDB also supports features like indexing, aggregation, transactions, and multi-master replication across multiple machines.

































































