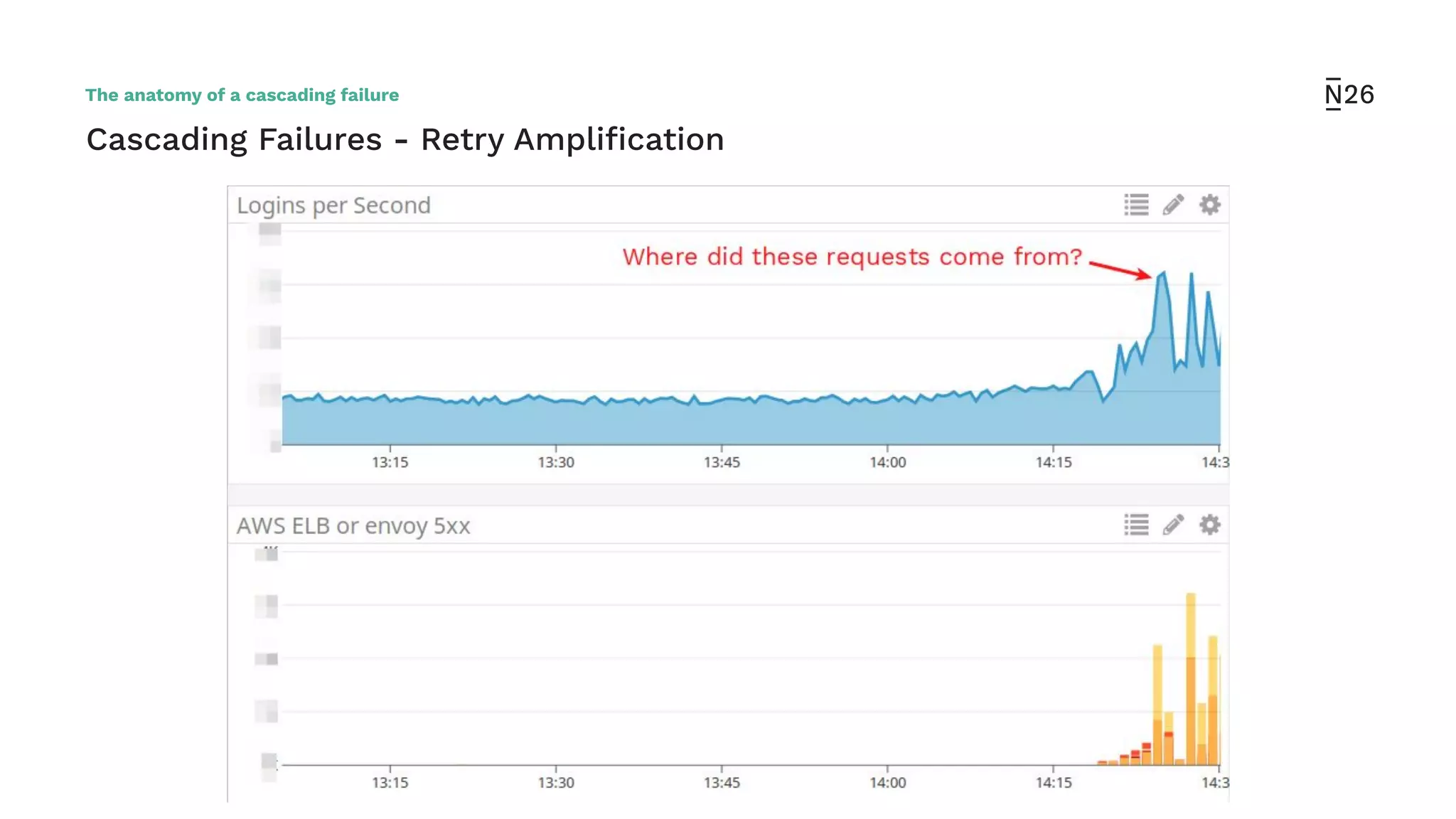
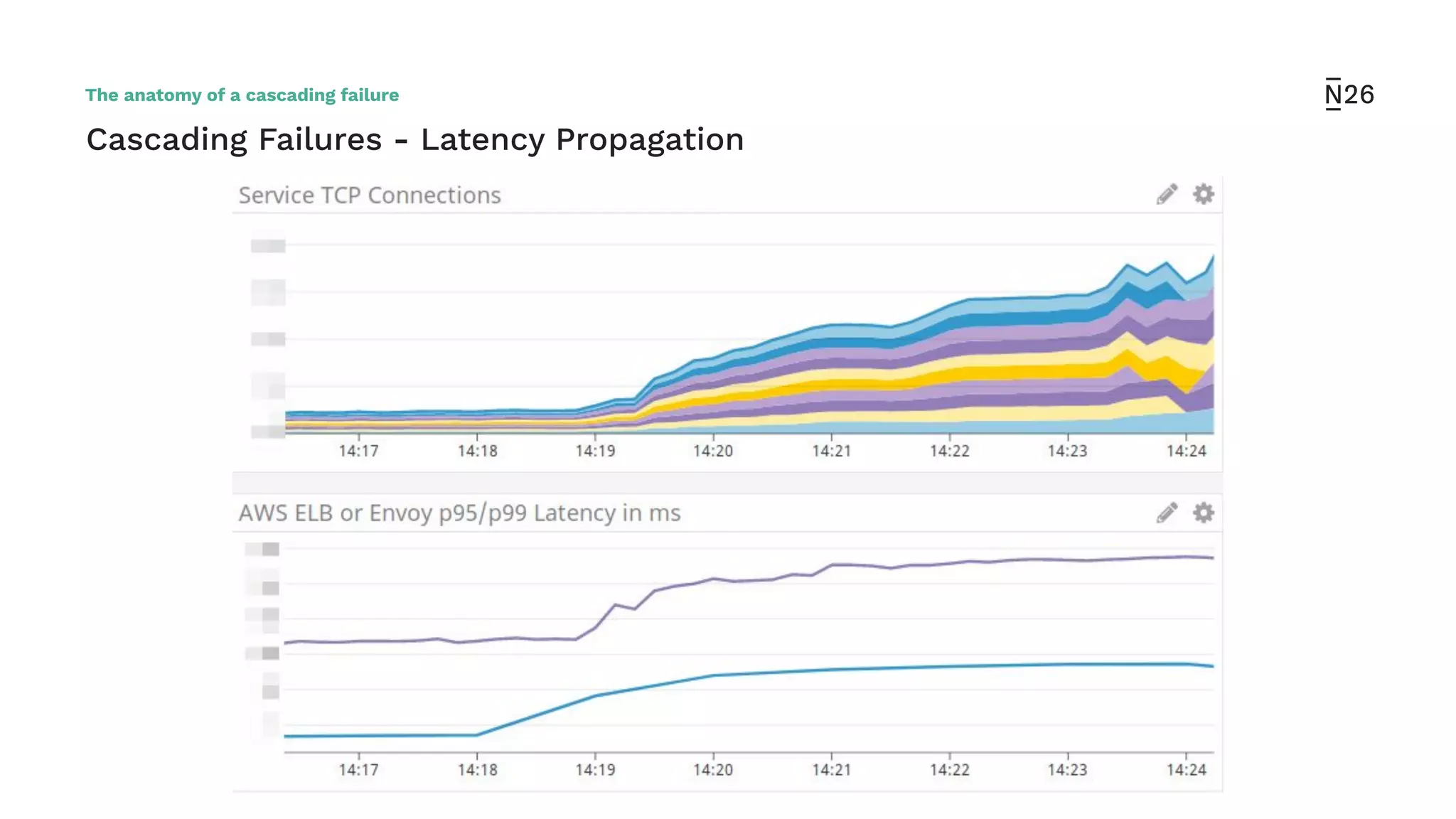
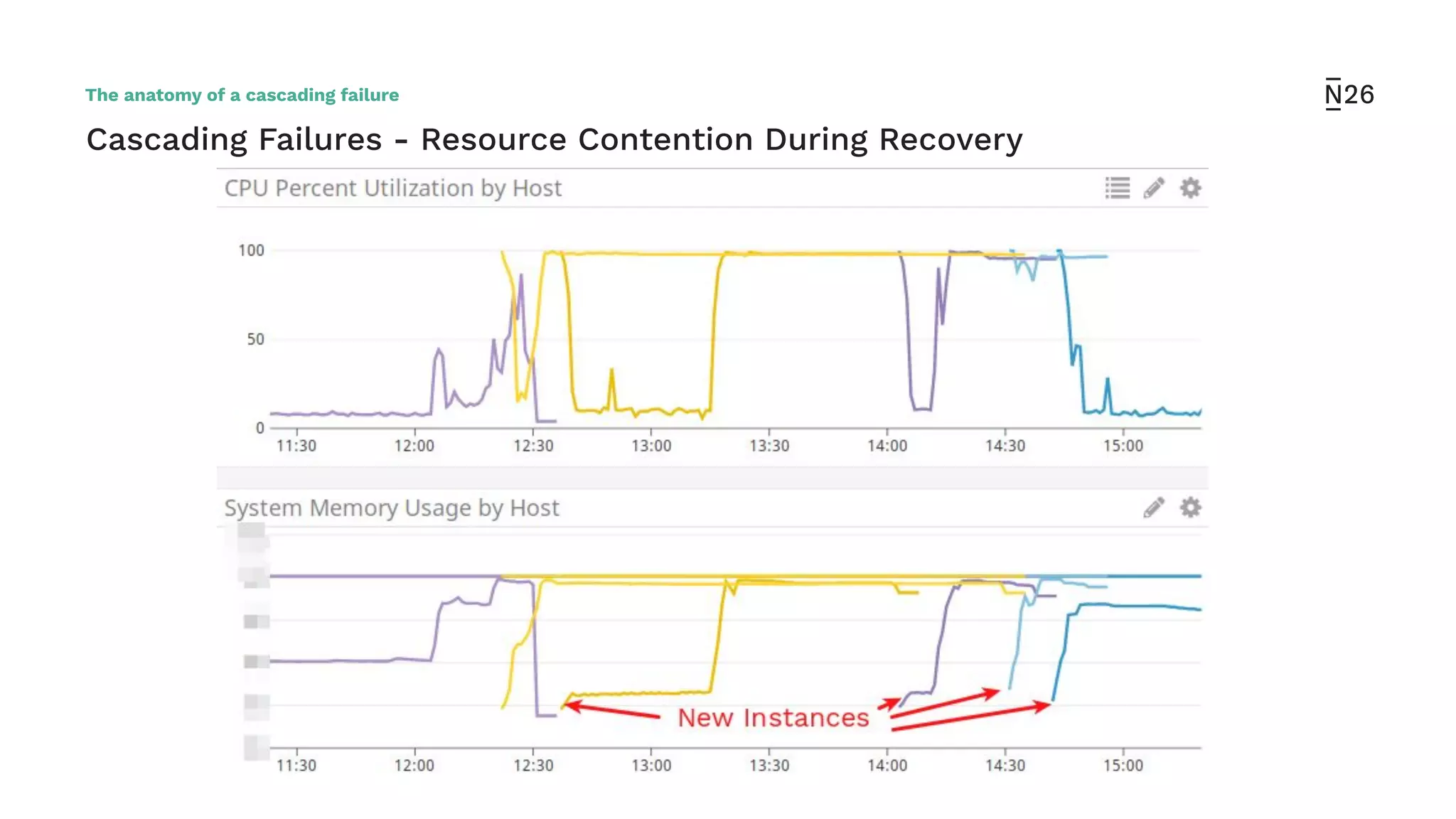
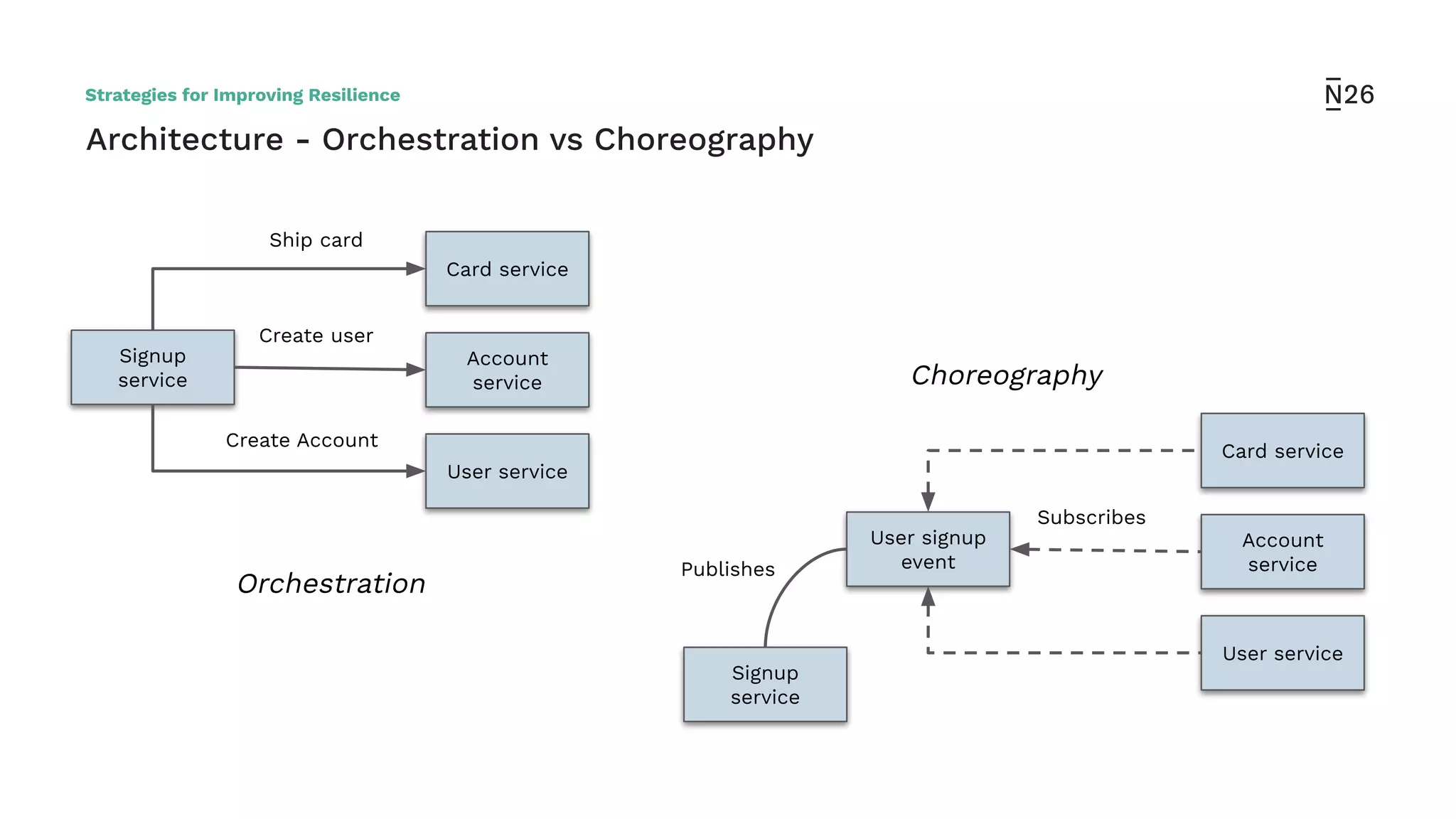
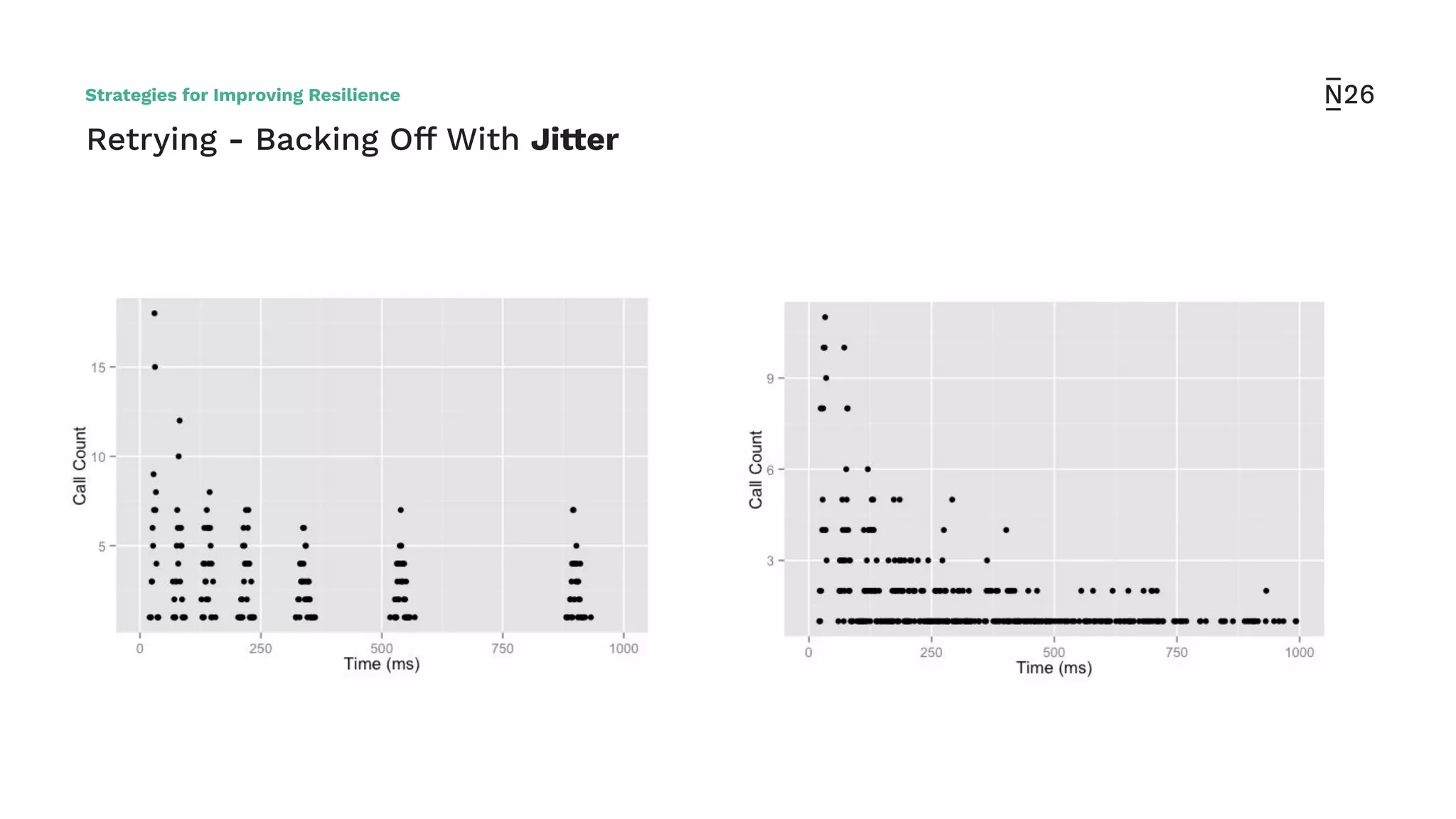
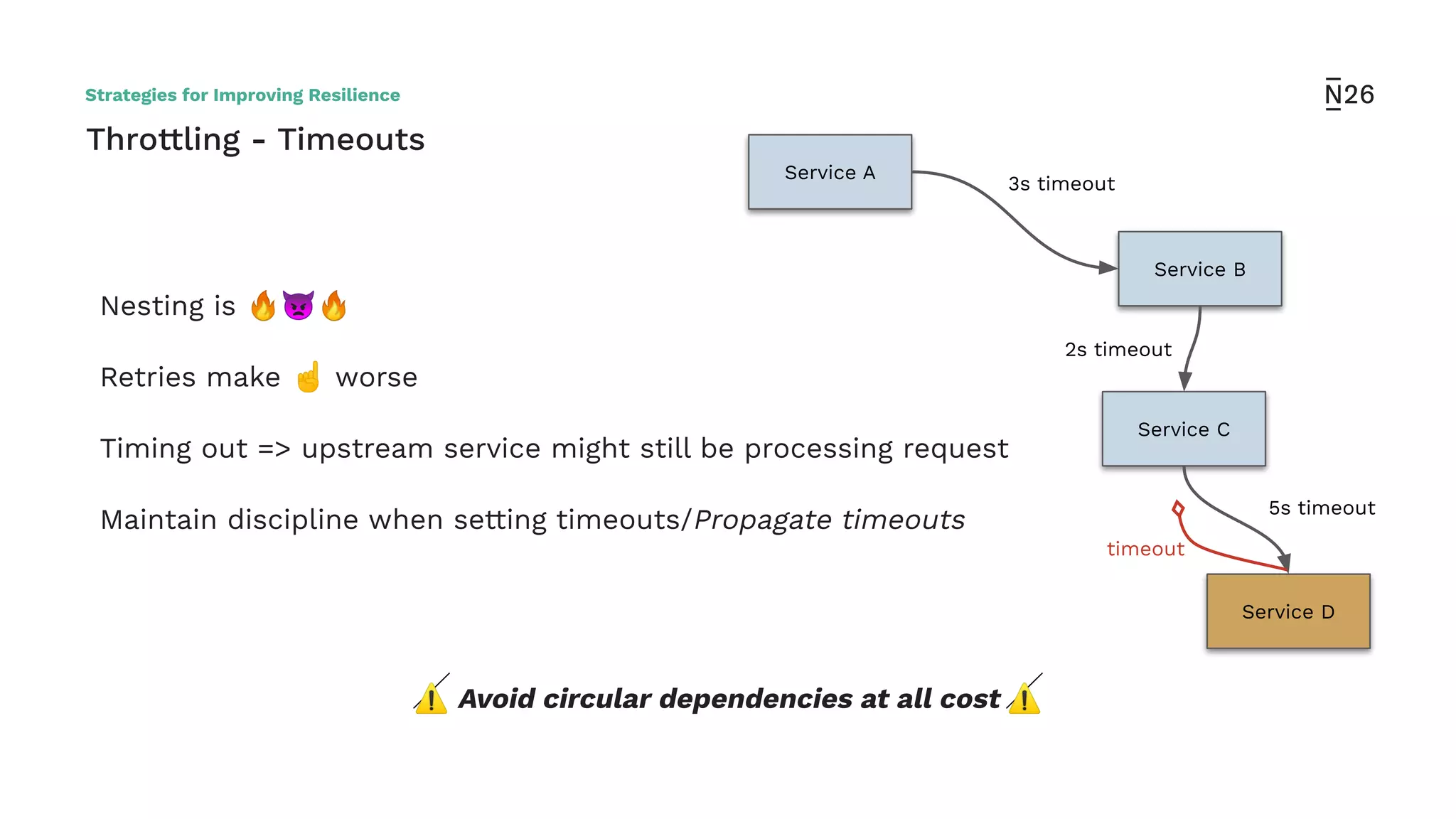
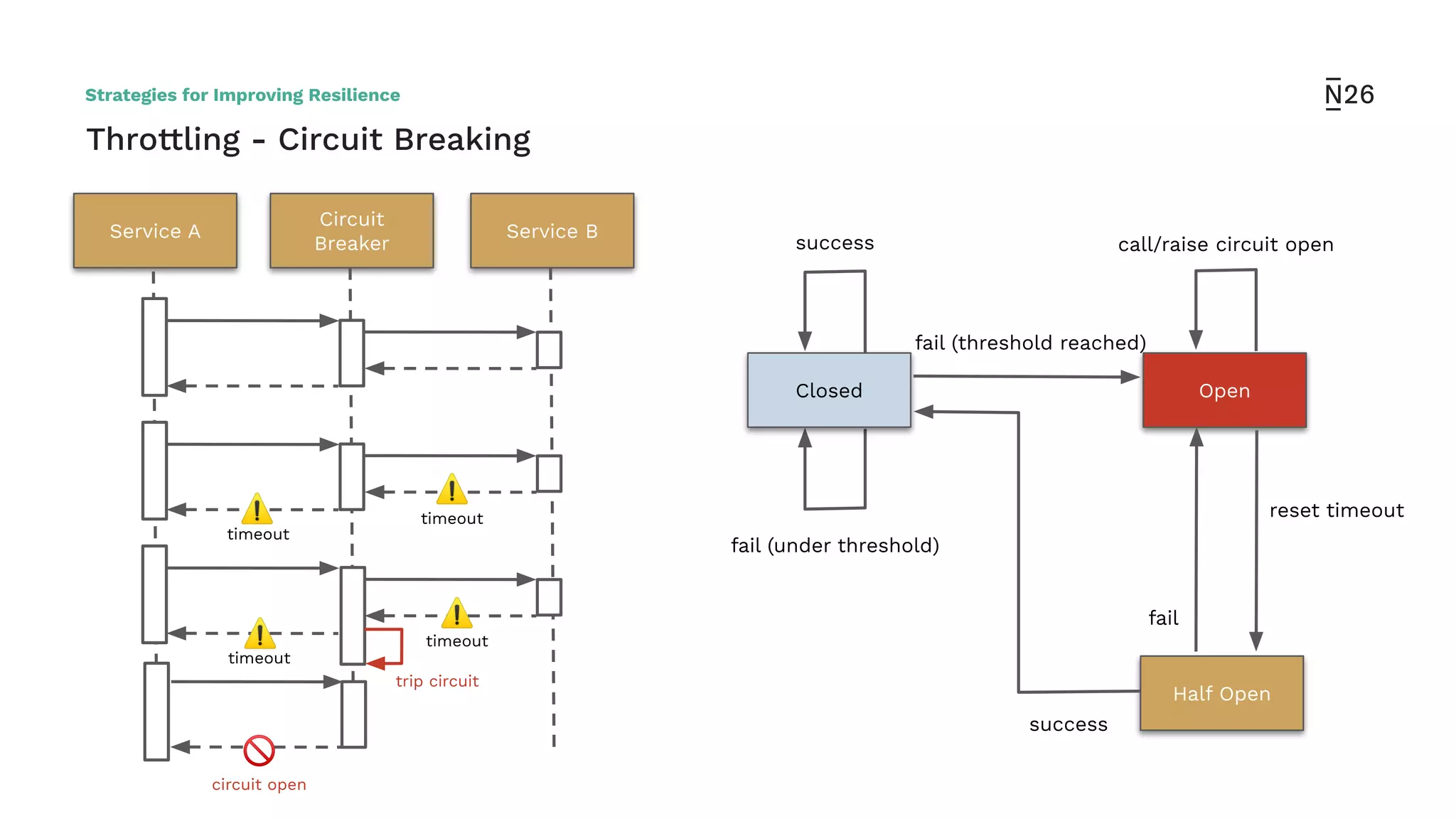
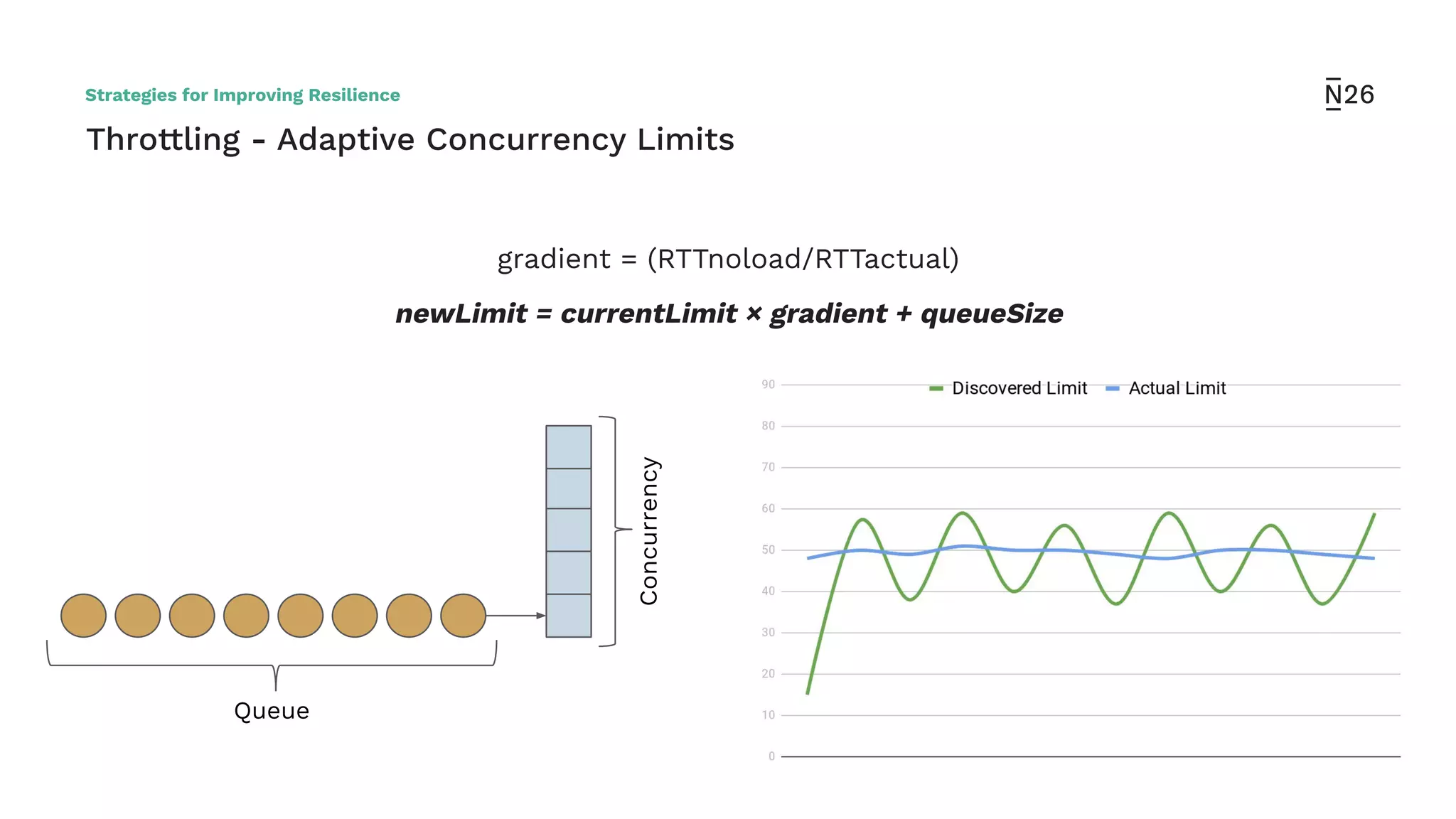
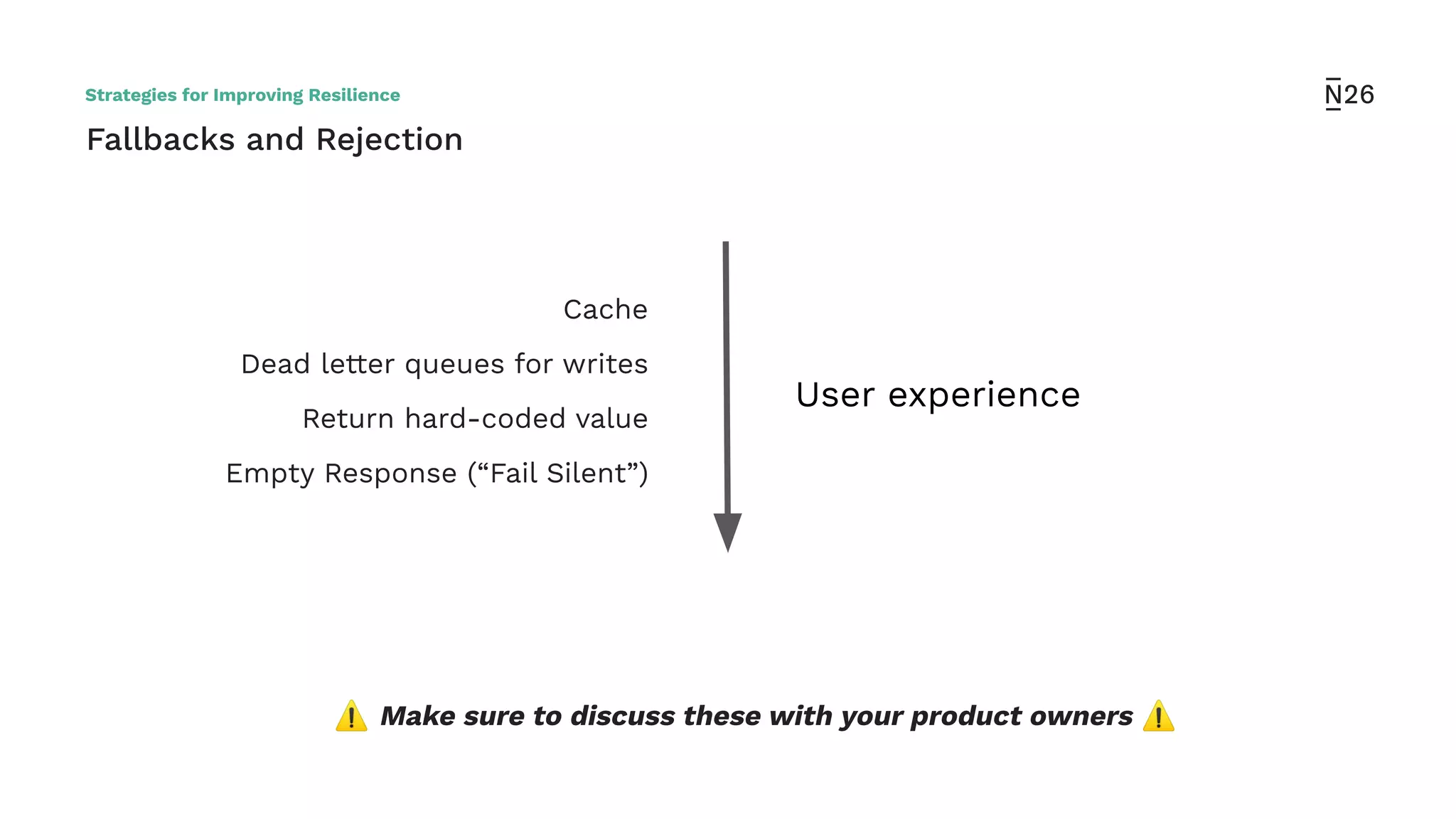
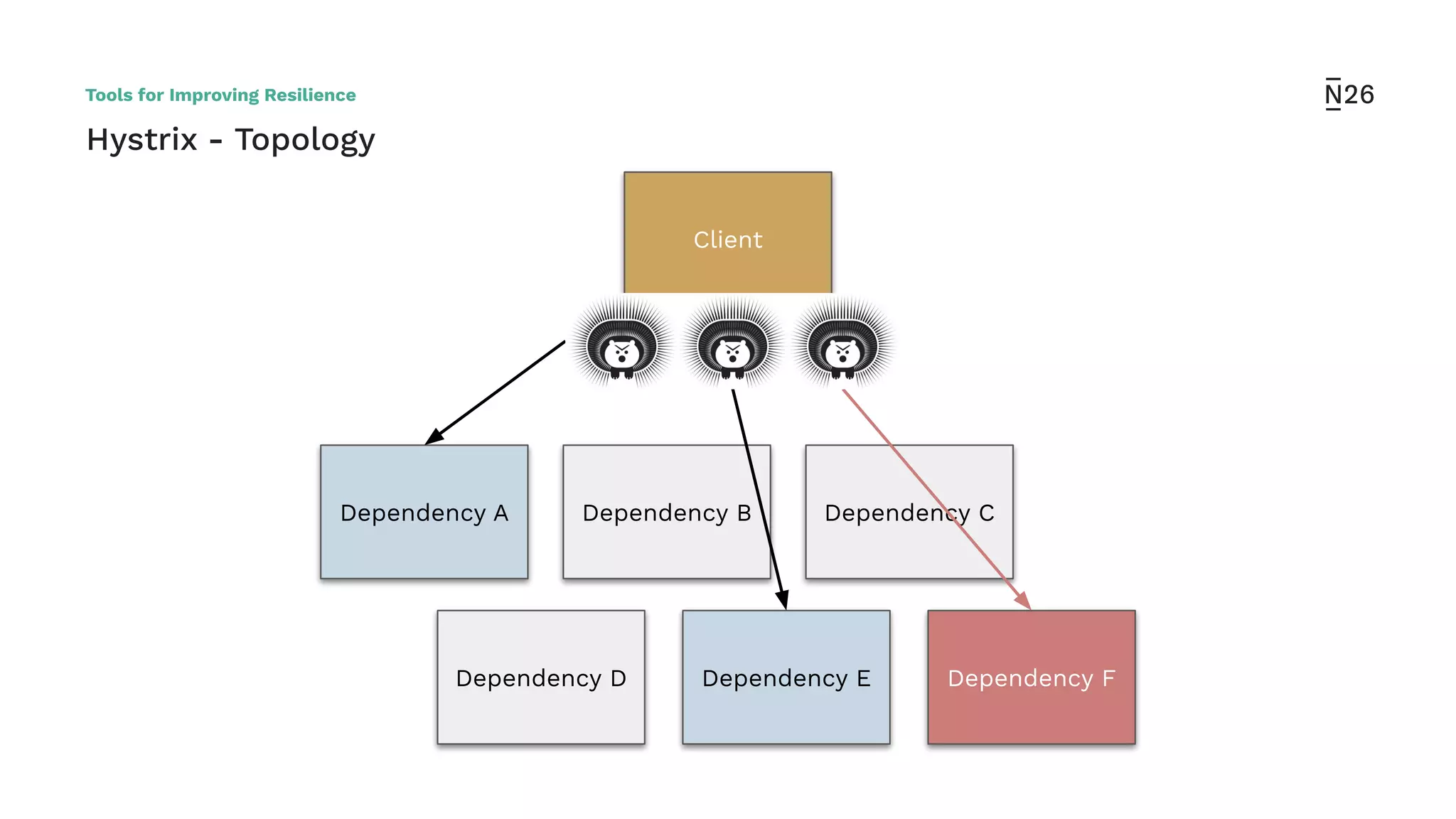
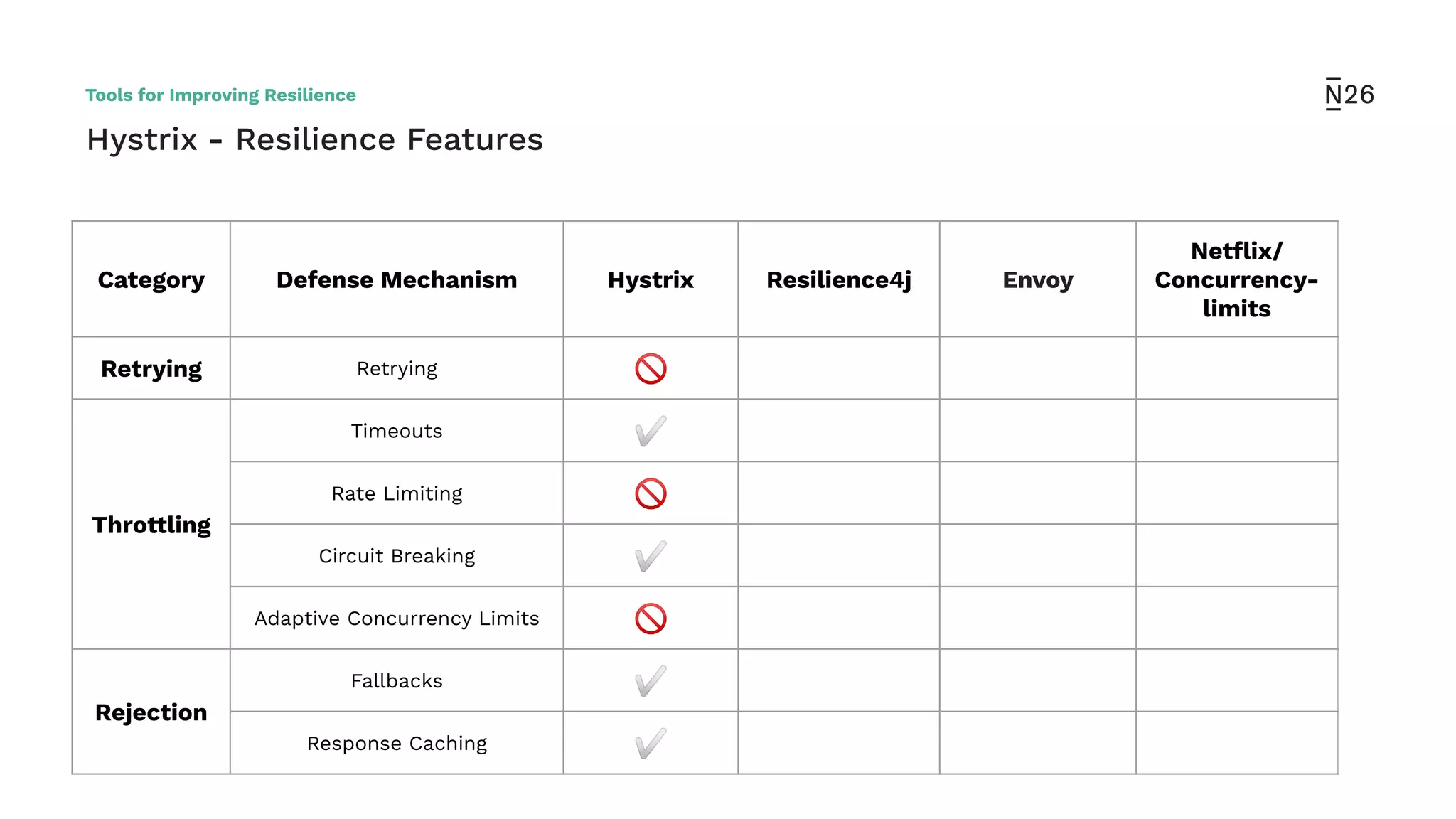
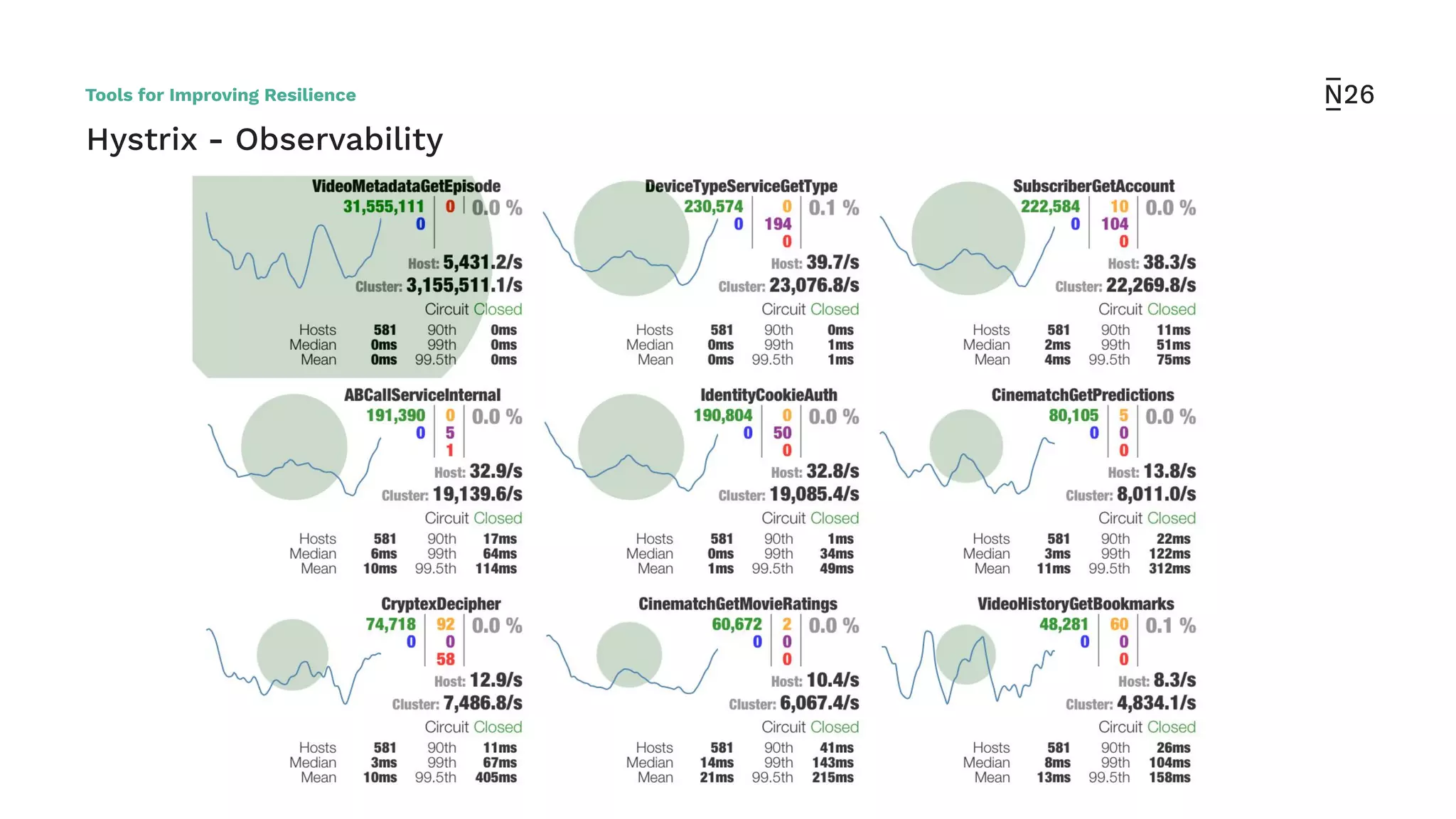
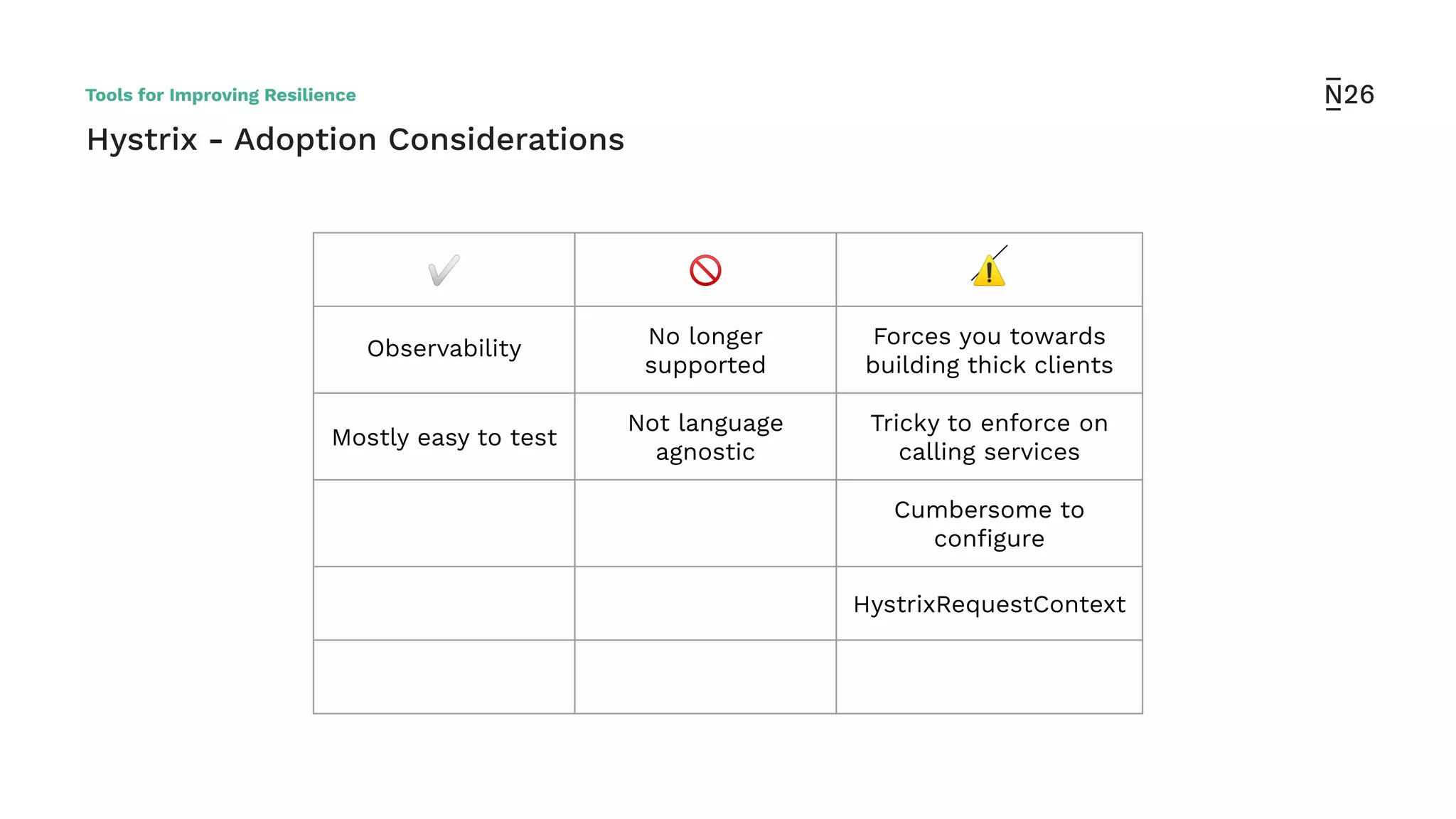
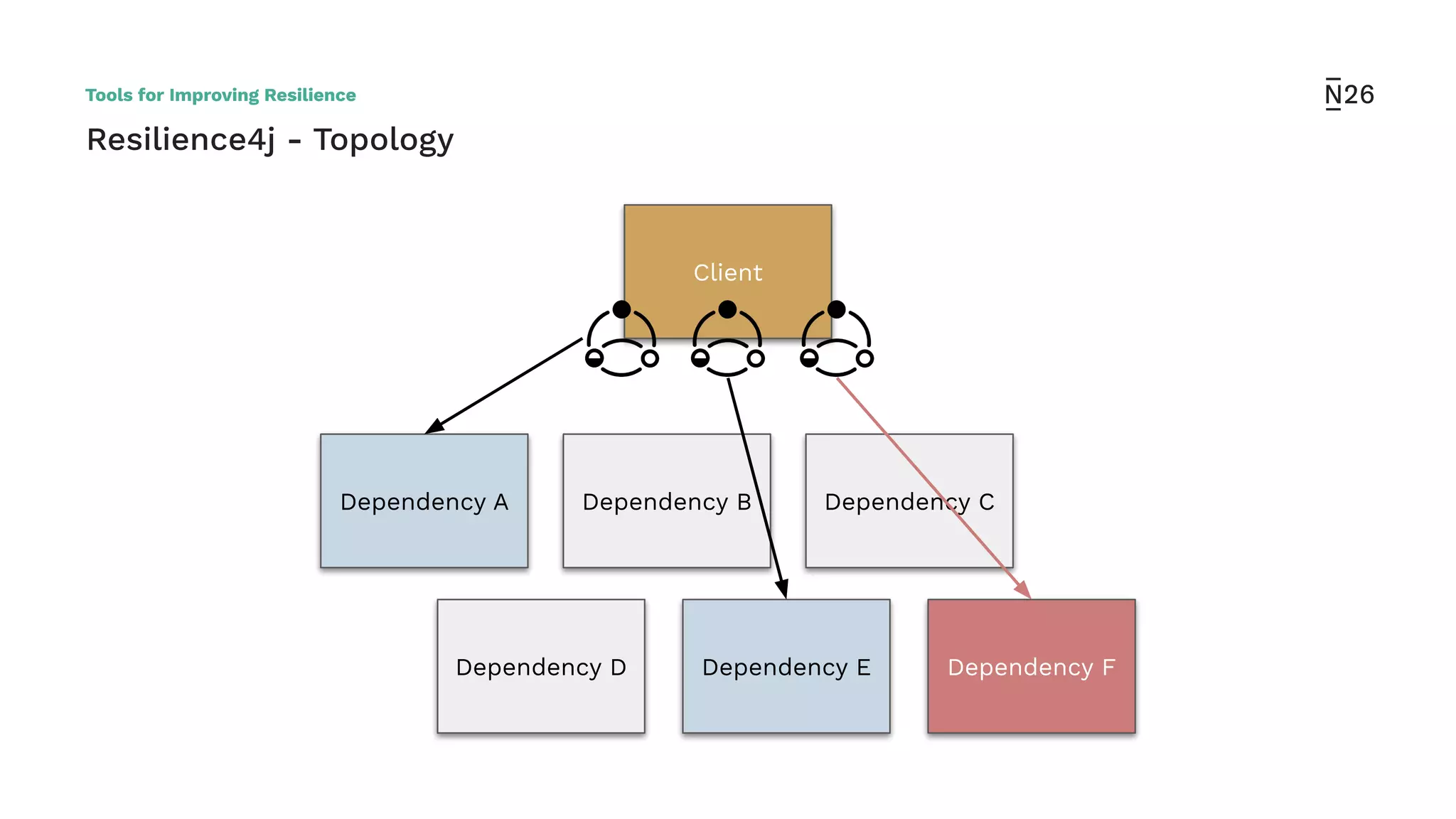
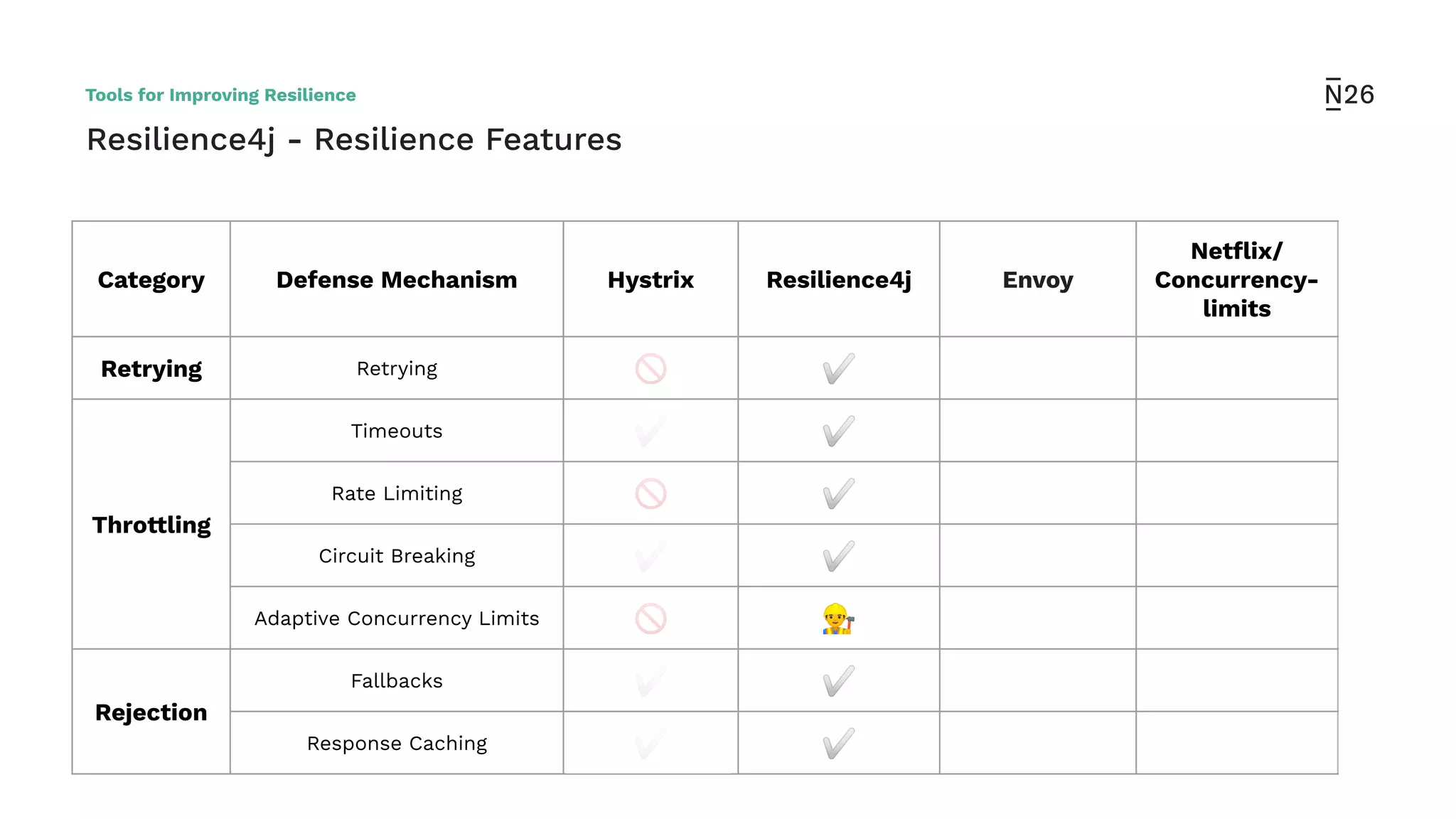
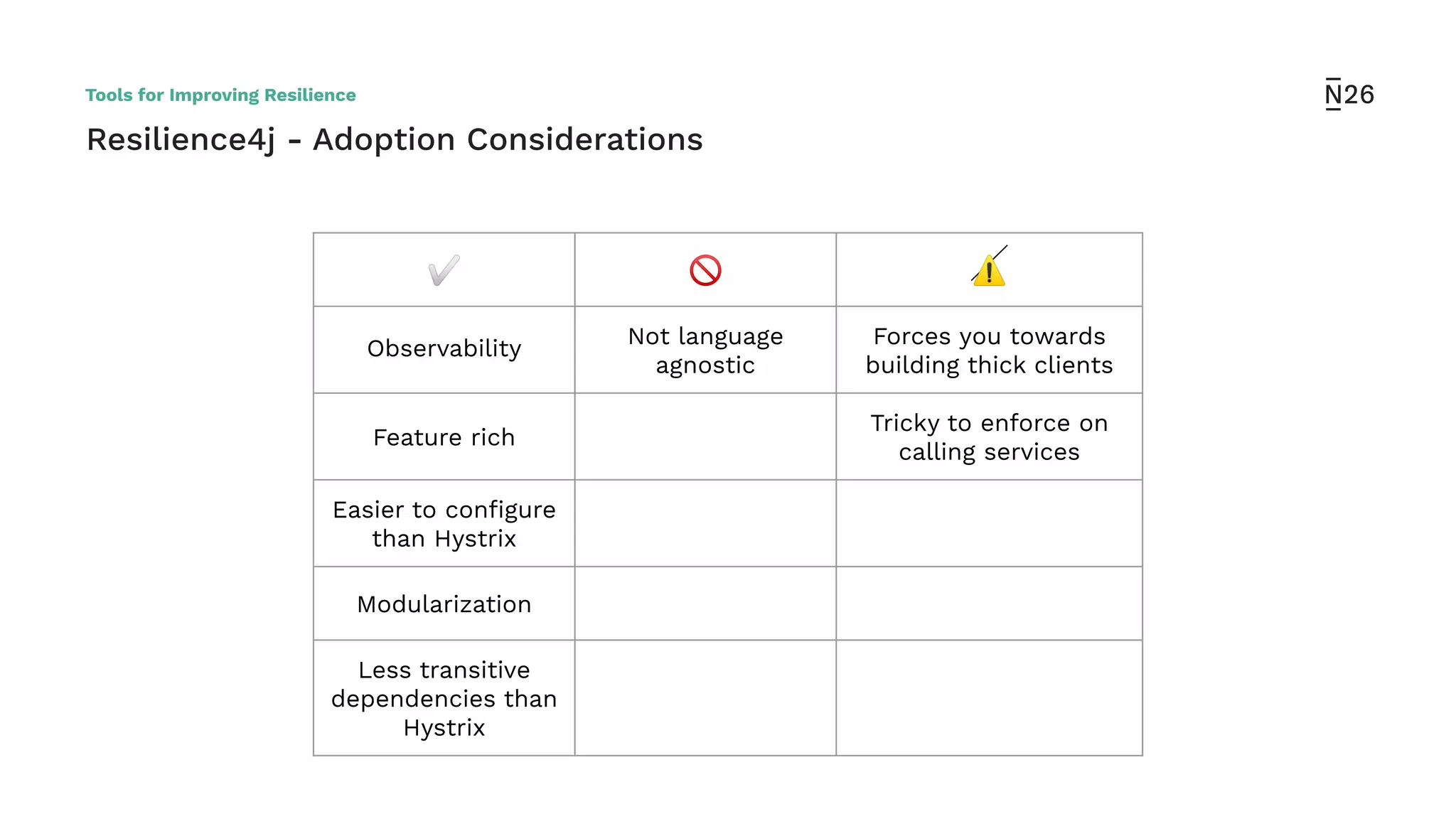
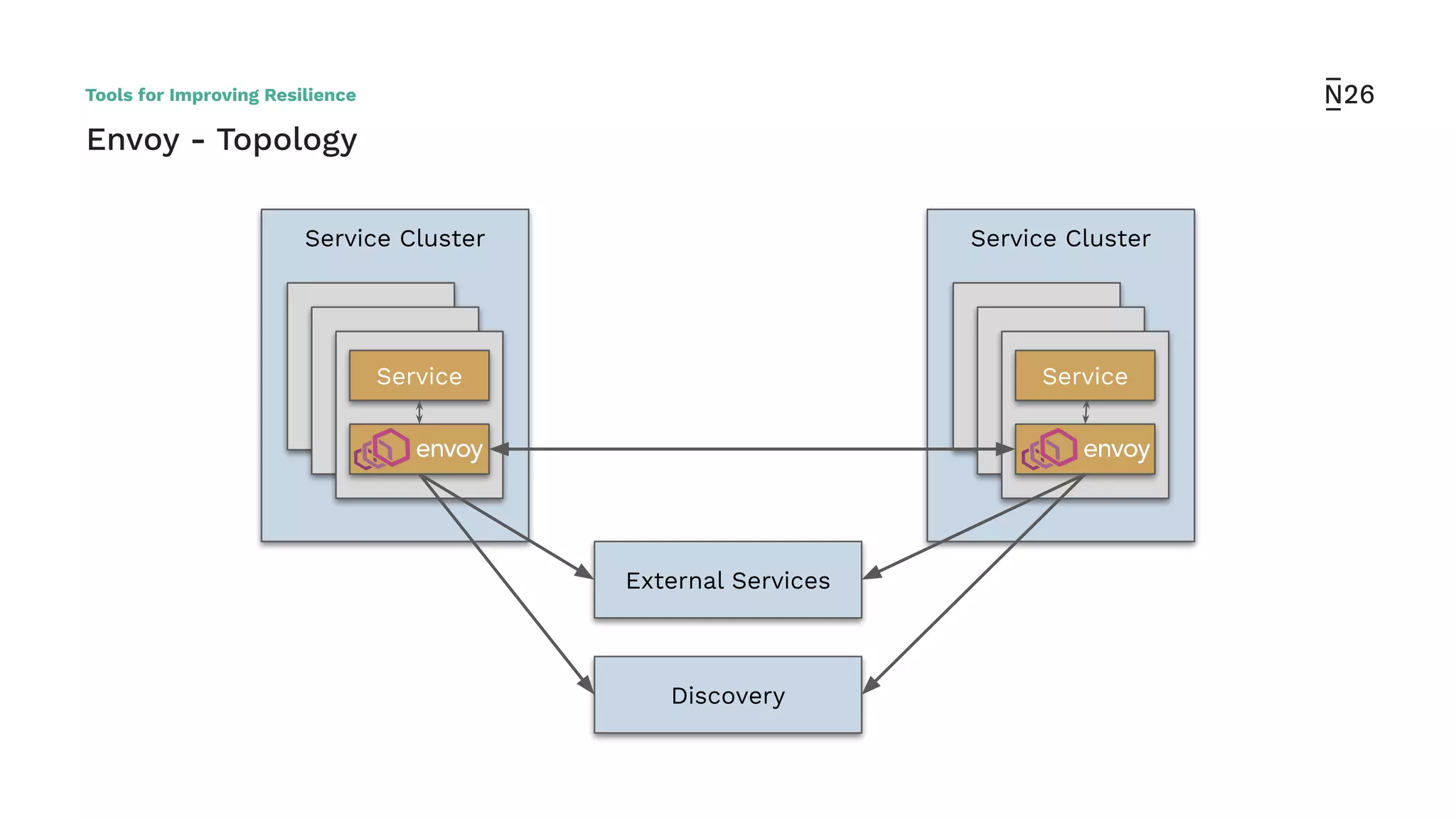
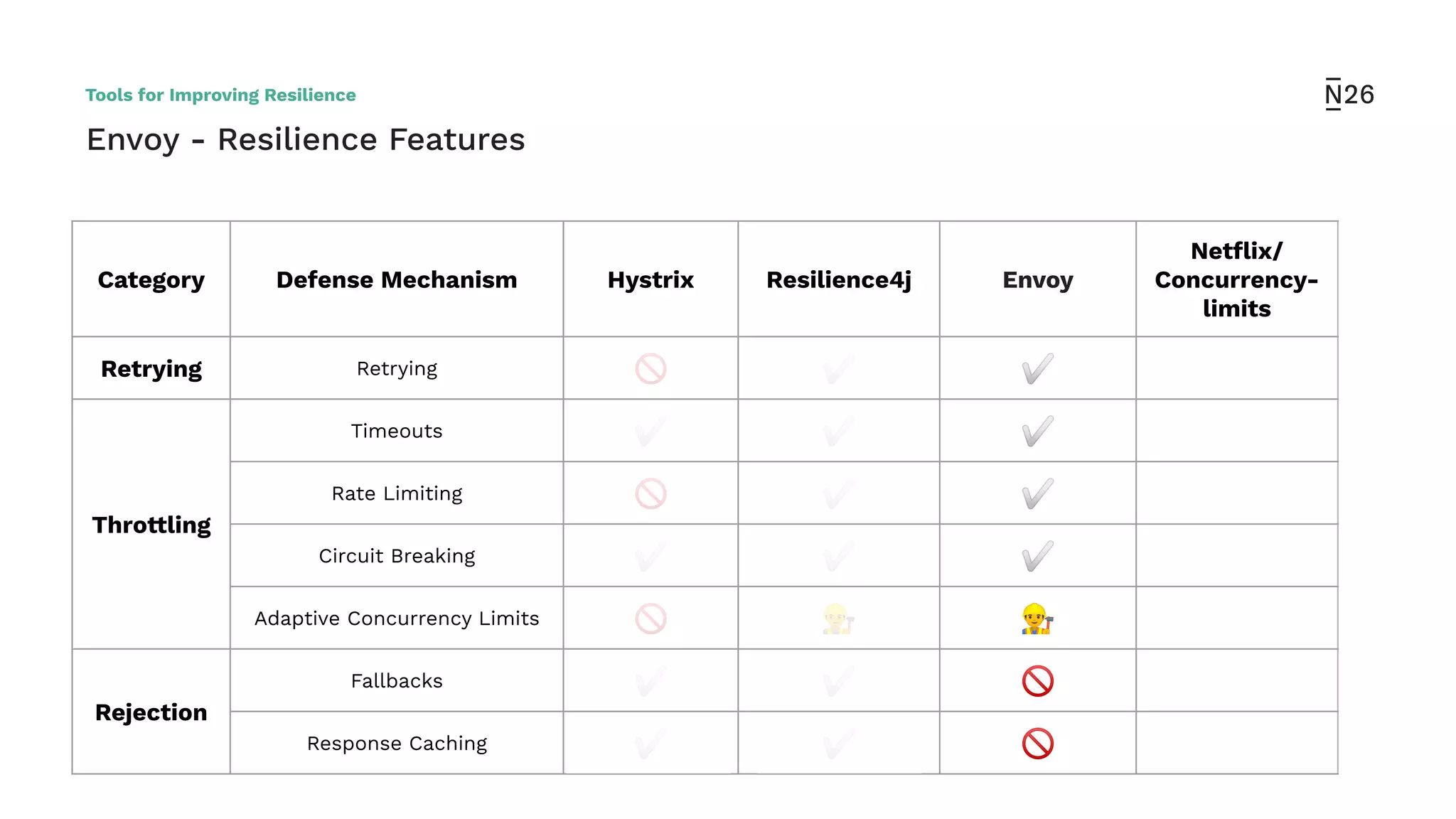
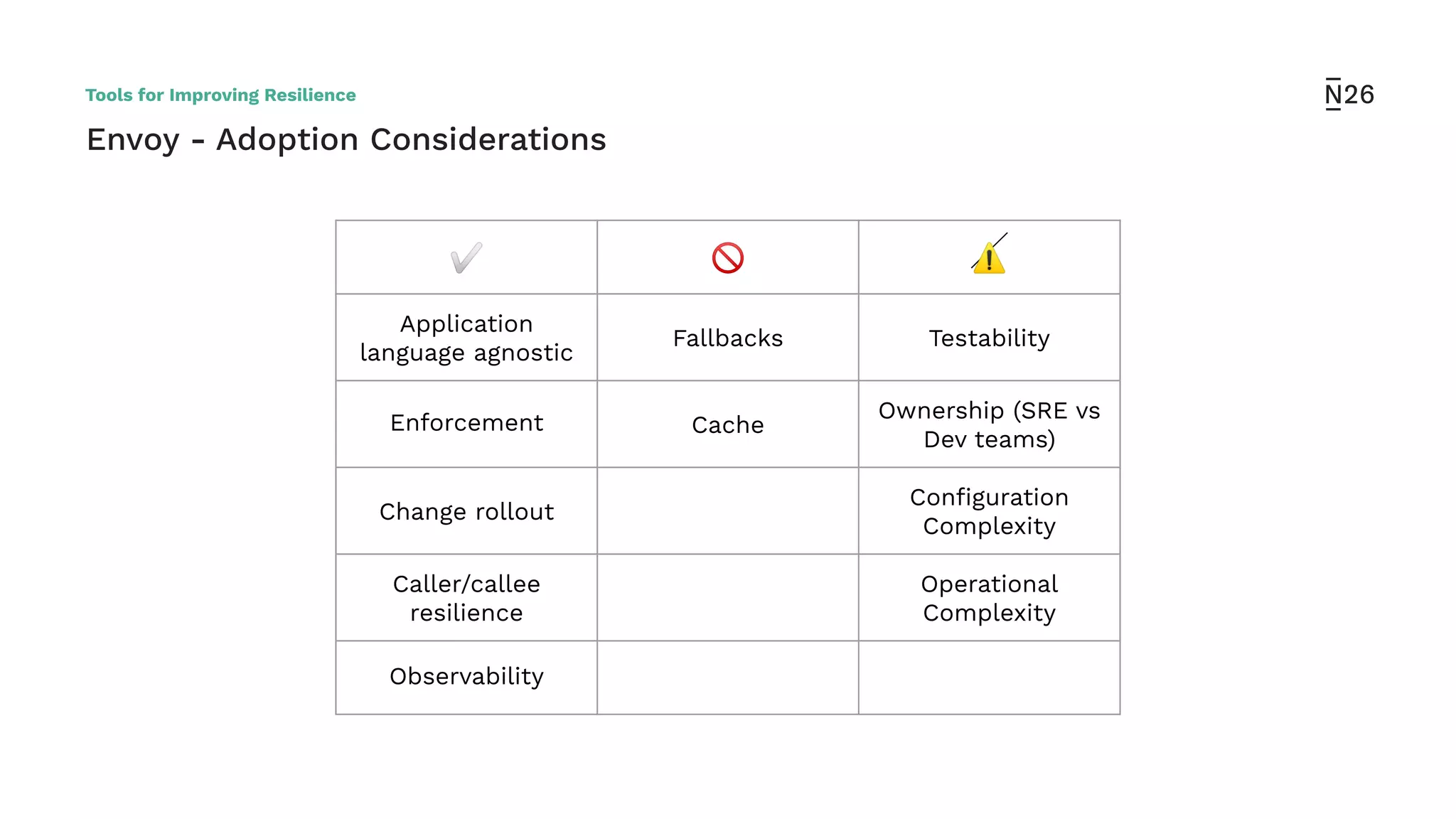
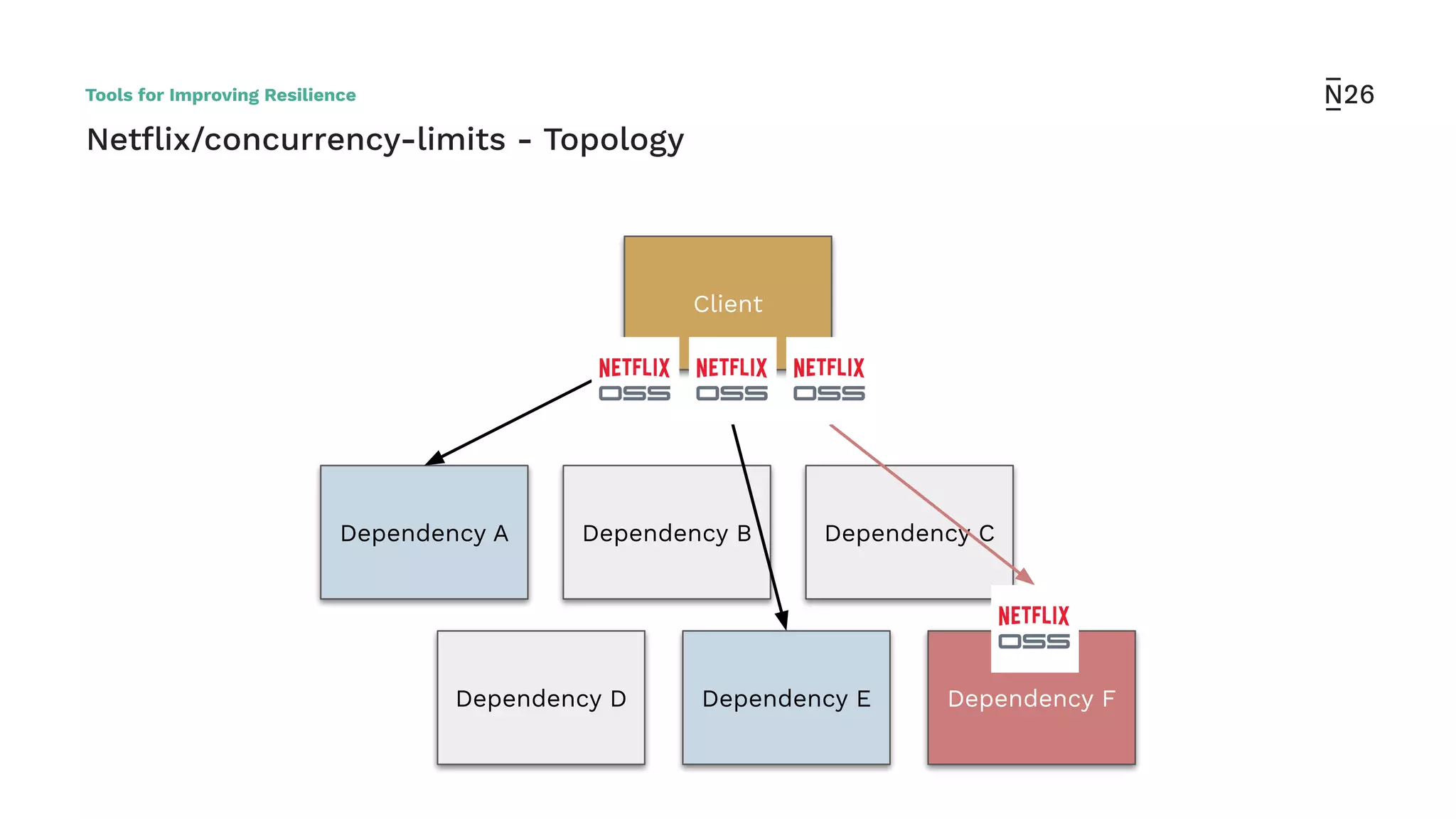
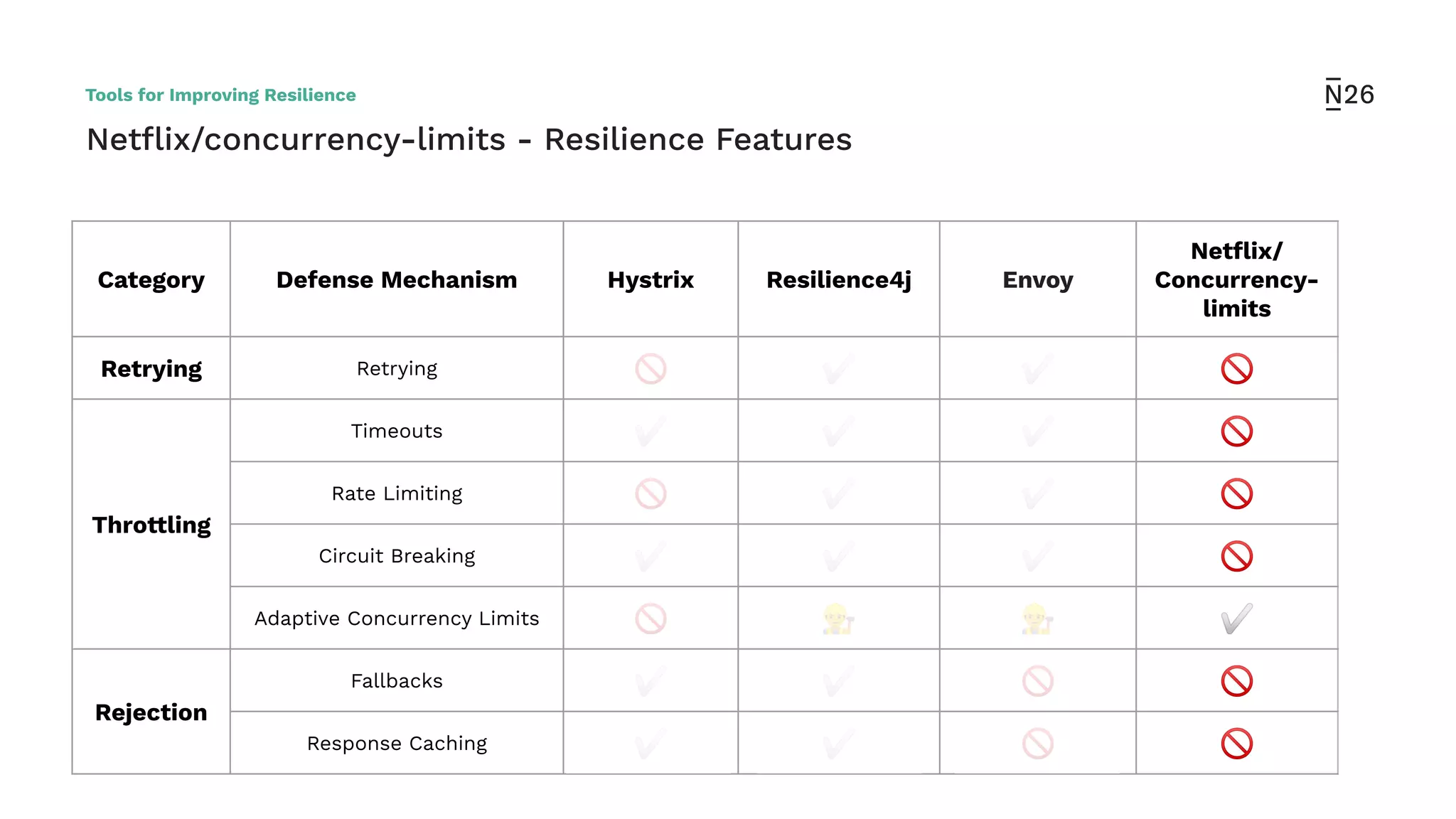
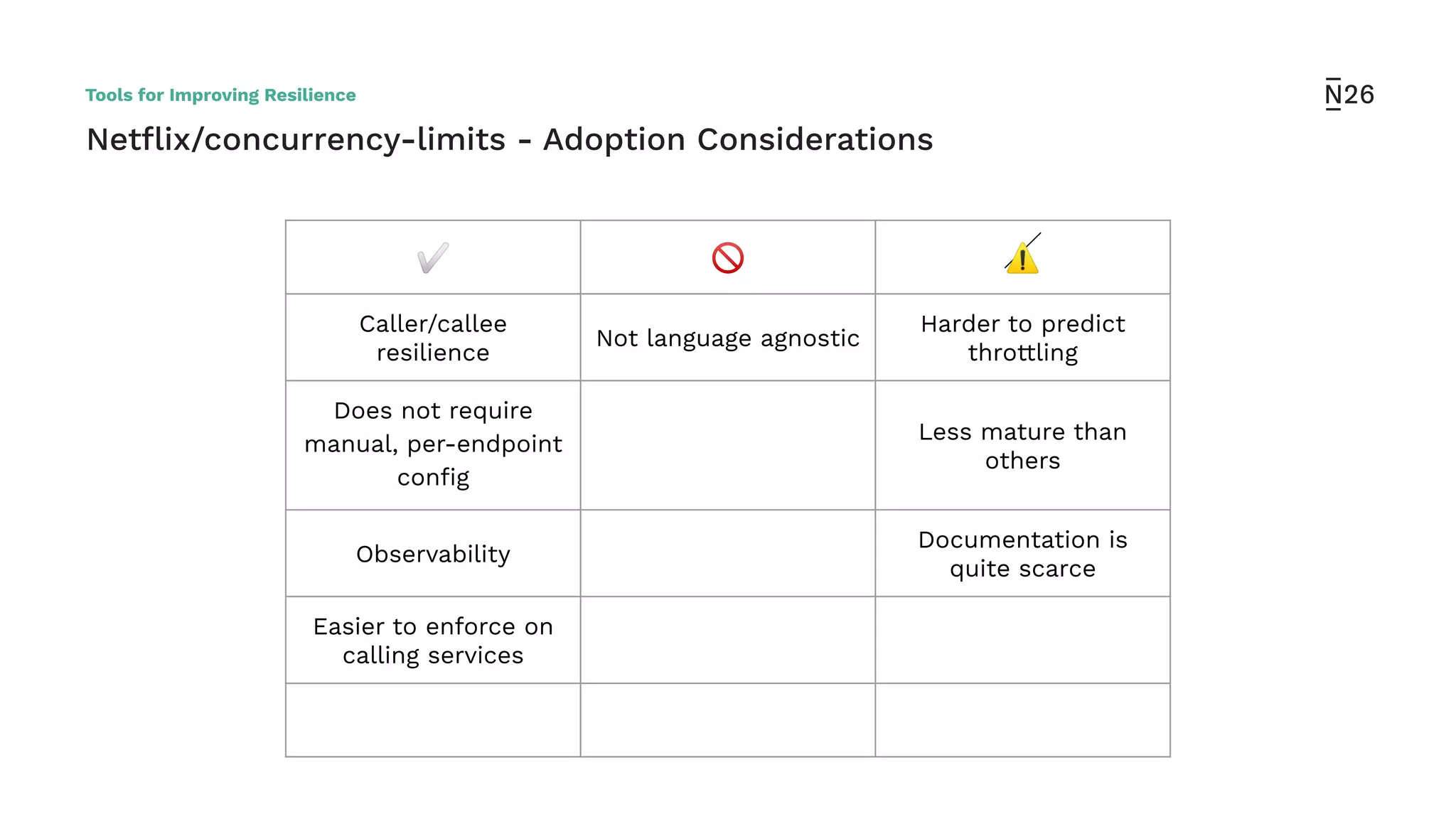
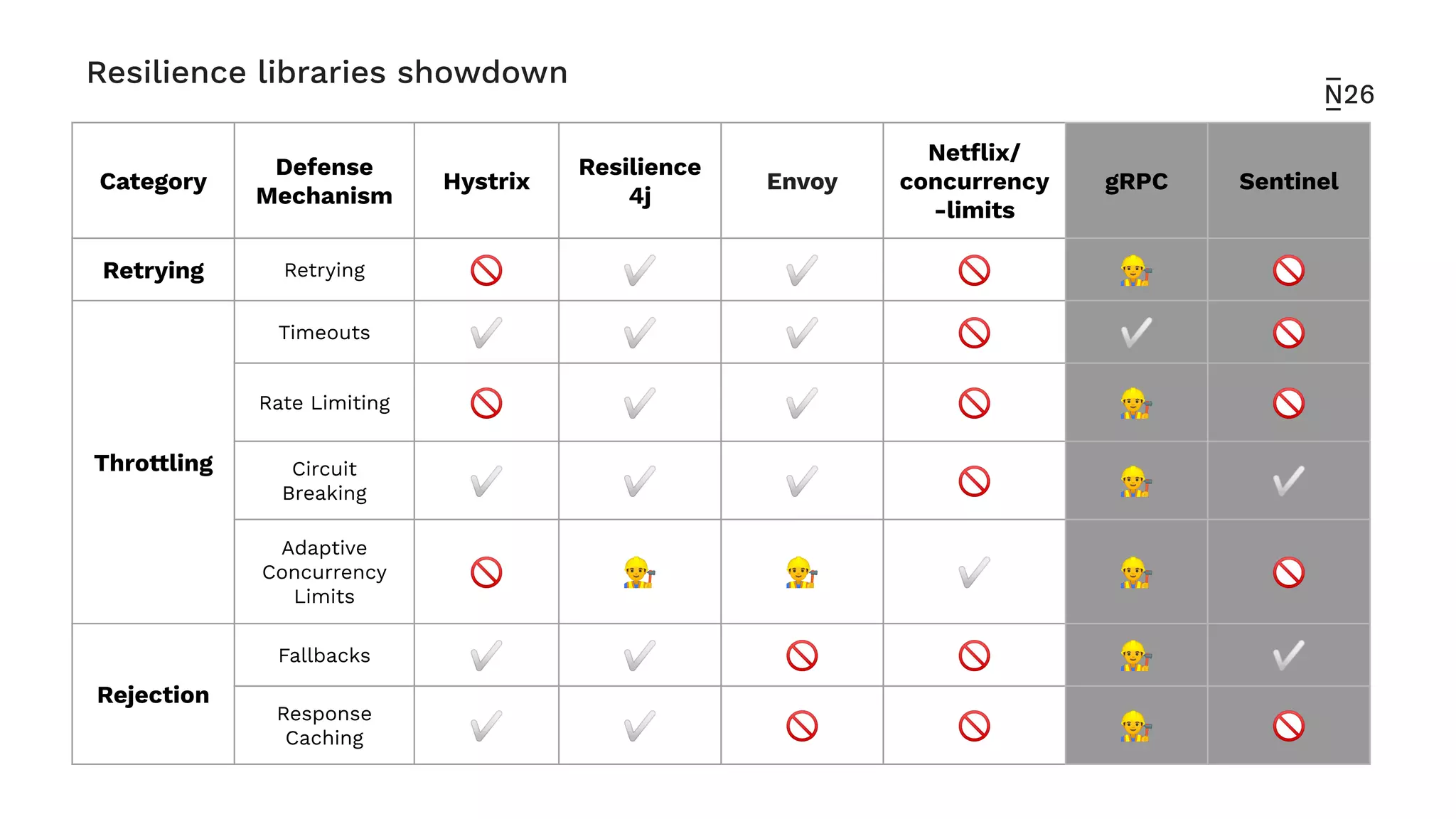
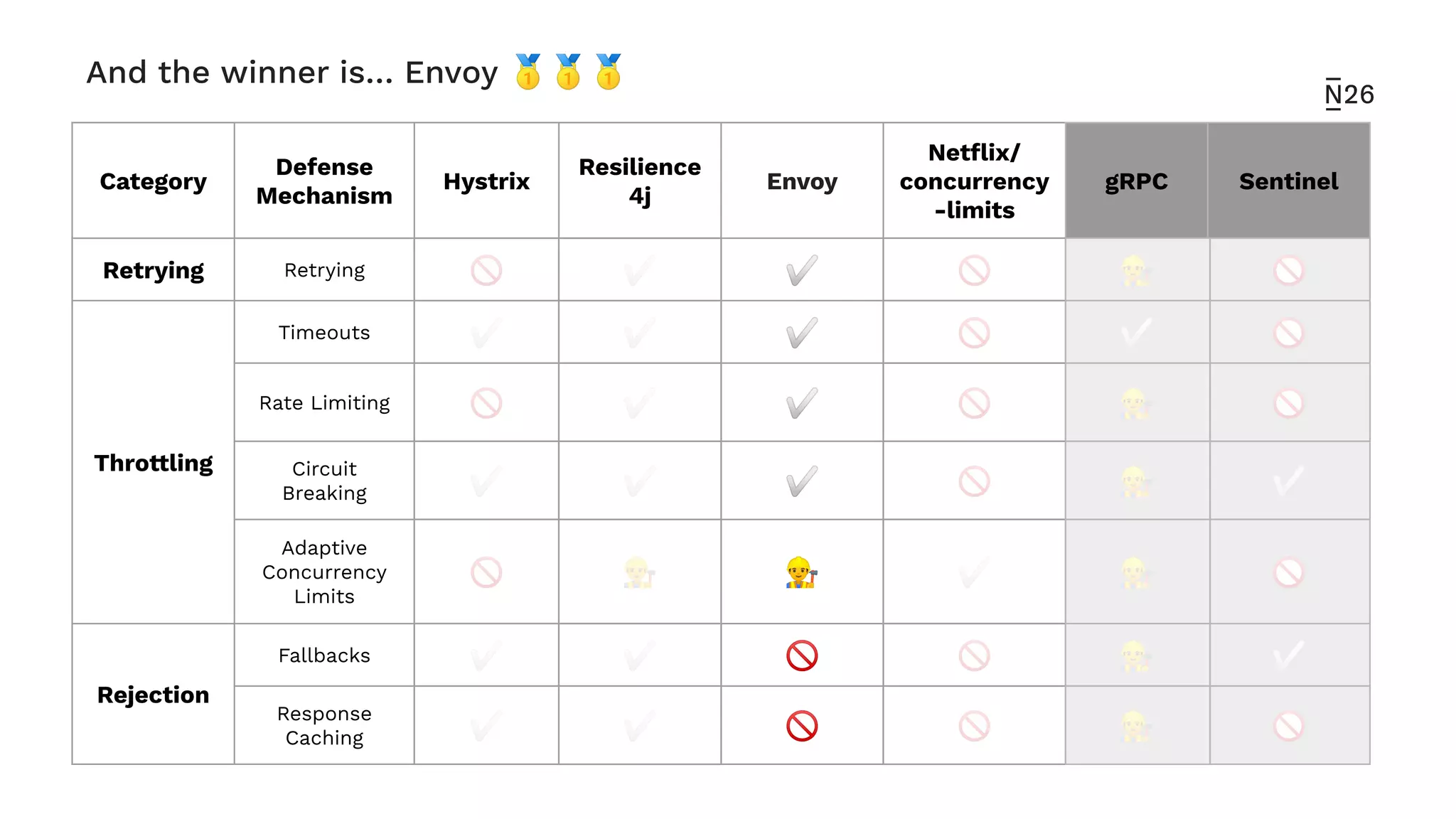
The document discusses strategies for achieving resilient service-to-service calls in modern microservices architecture, focusing on the limitations posed by the now-deprecated Hystrix framework. It highlights various methods for improving resilience, such as chaos engineering, retry mechanisms, throttling, circuit breaking, and the use of libraries like Resilience4j and Envoy, while comparing their features and adoption considerations. The conclusion emphasizes Envoy as the preferred solution due to its strong observability, ease of enforcement, and language agnosticism.












































![Deformable DETR Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/deformabledetrreviewcdm-201113070345-thumbnail.jpg?width=640&height=640&fit=bounds)

























































