Downloaded 19 times






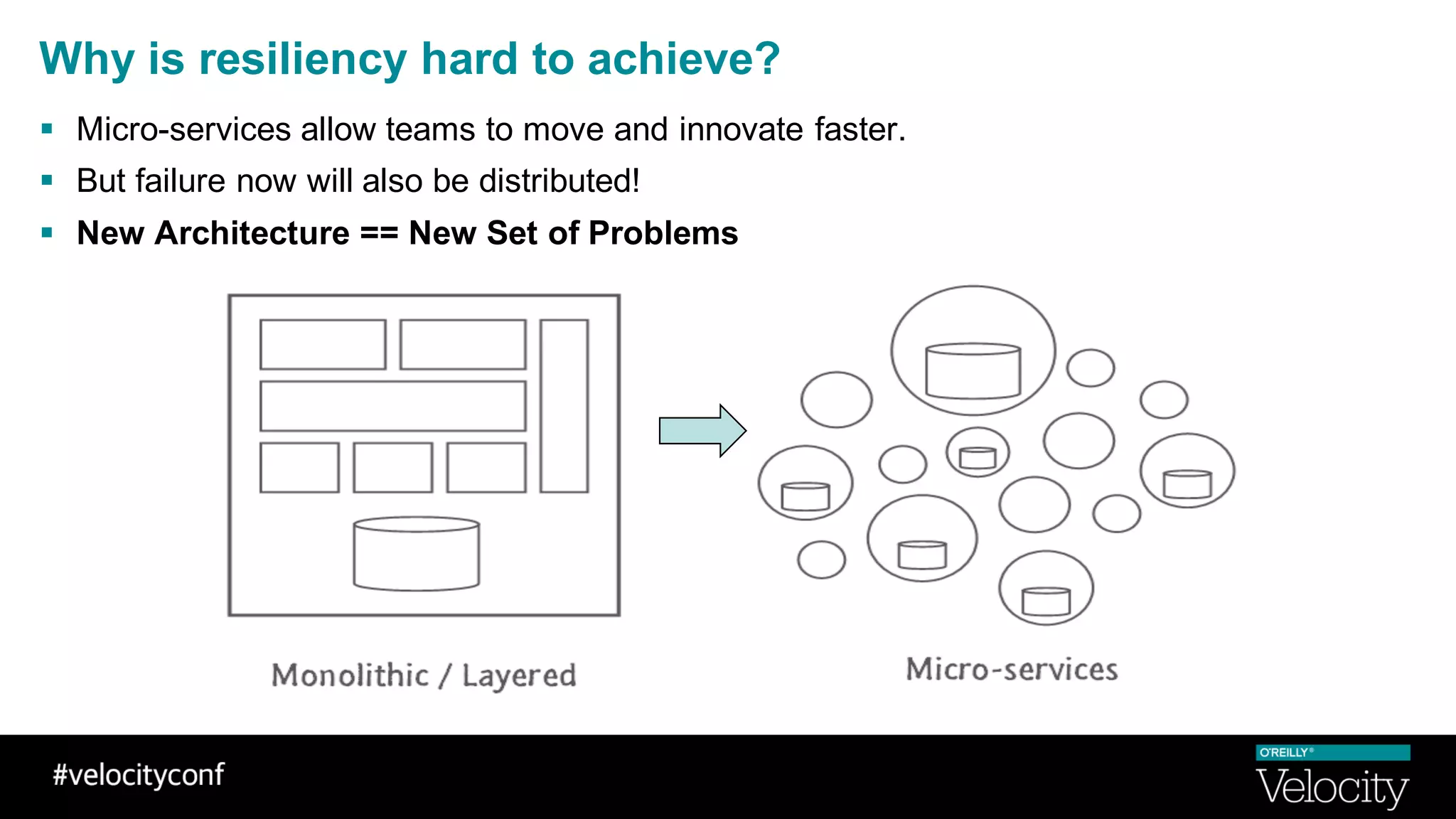
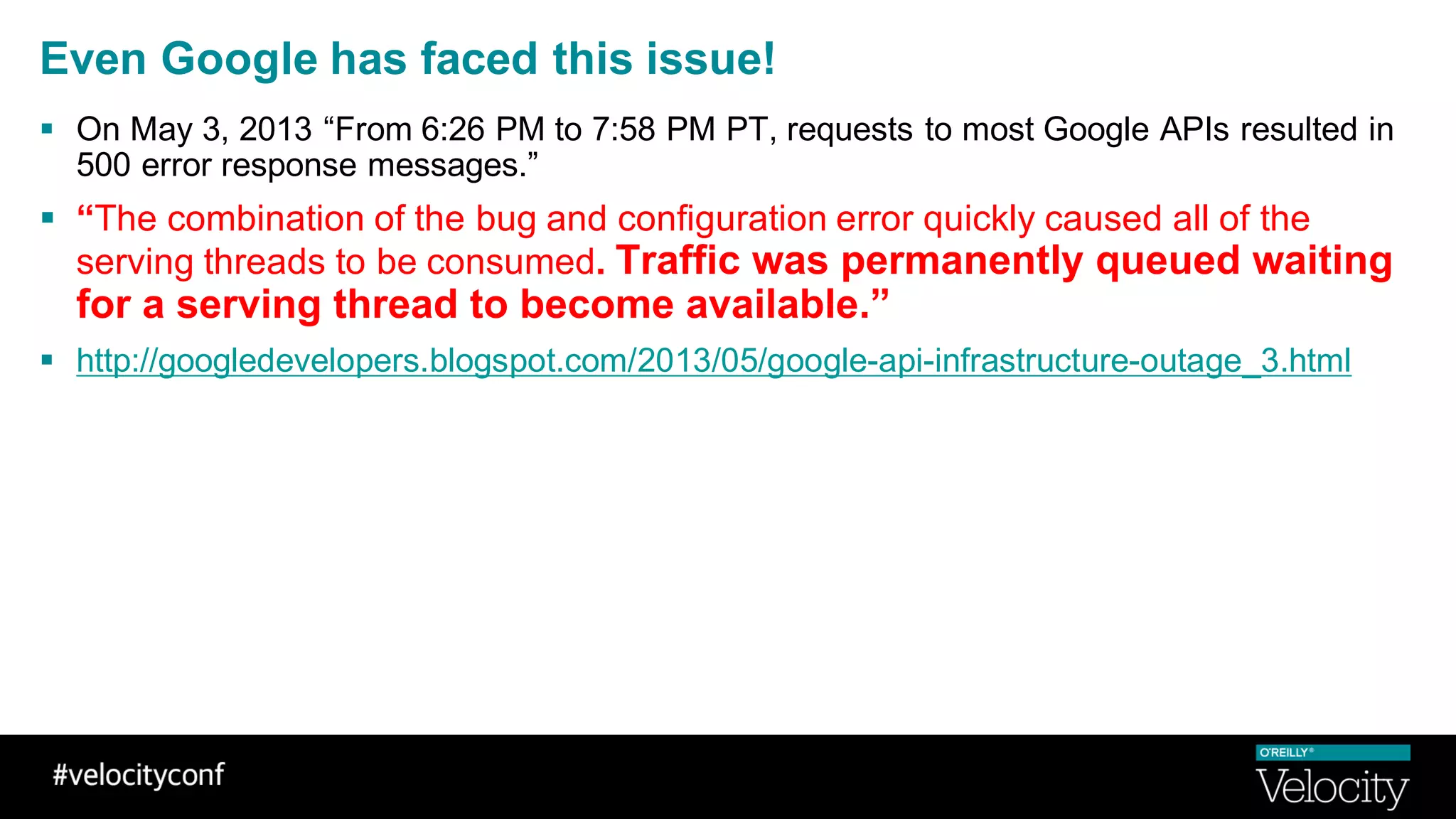


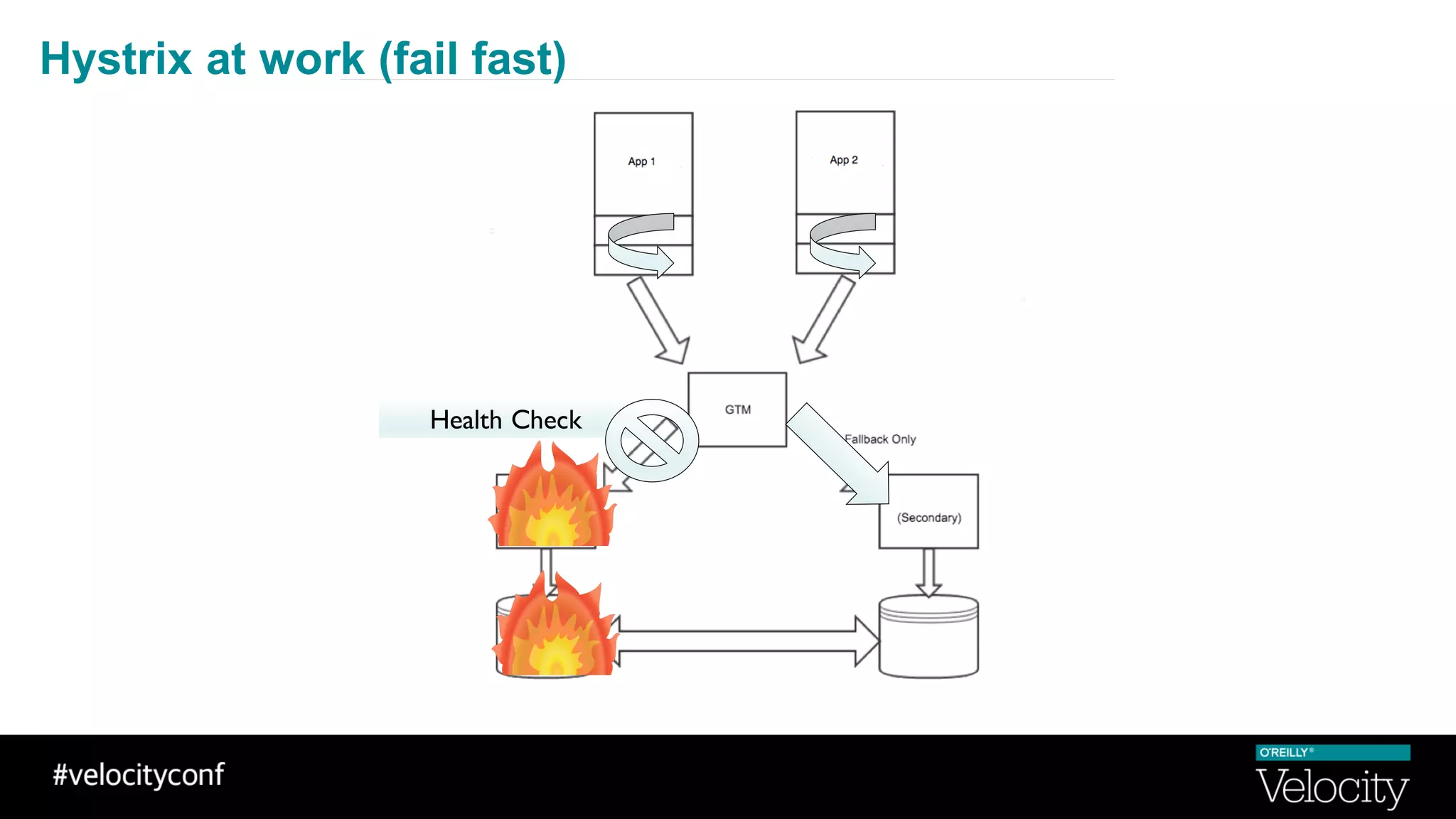




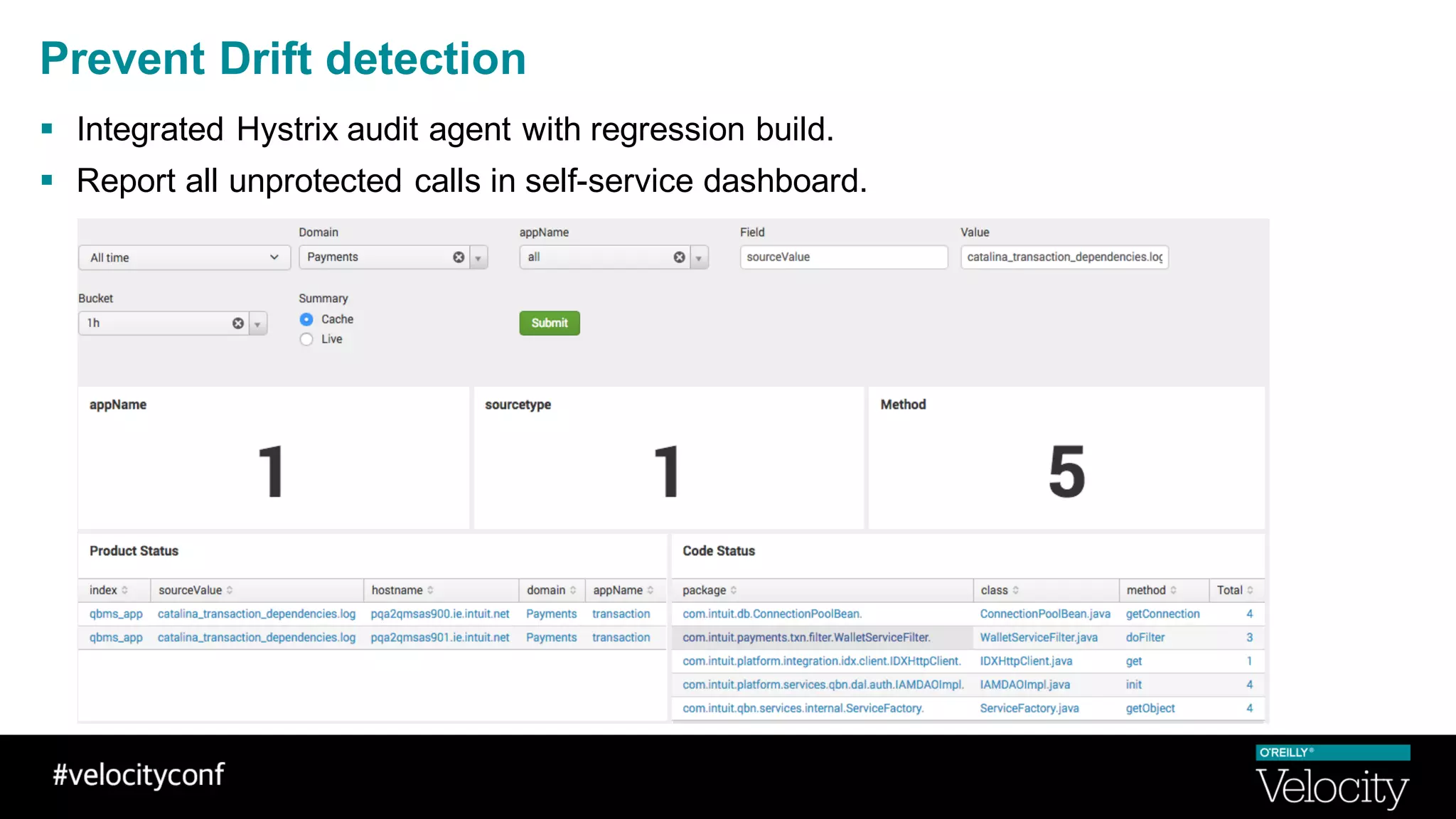

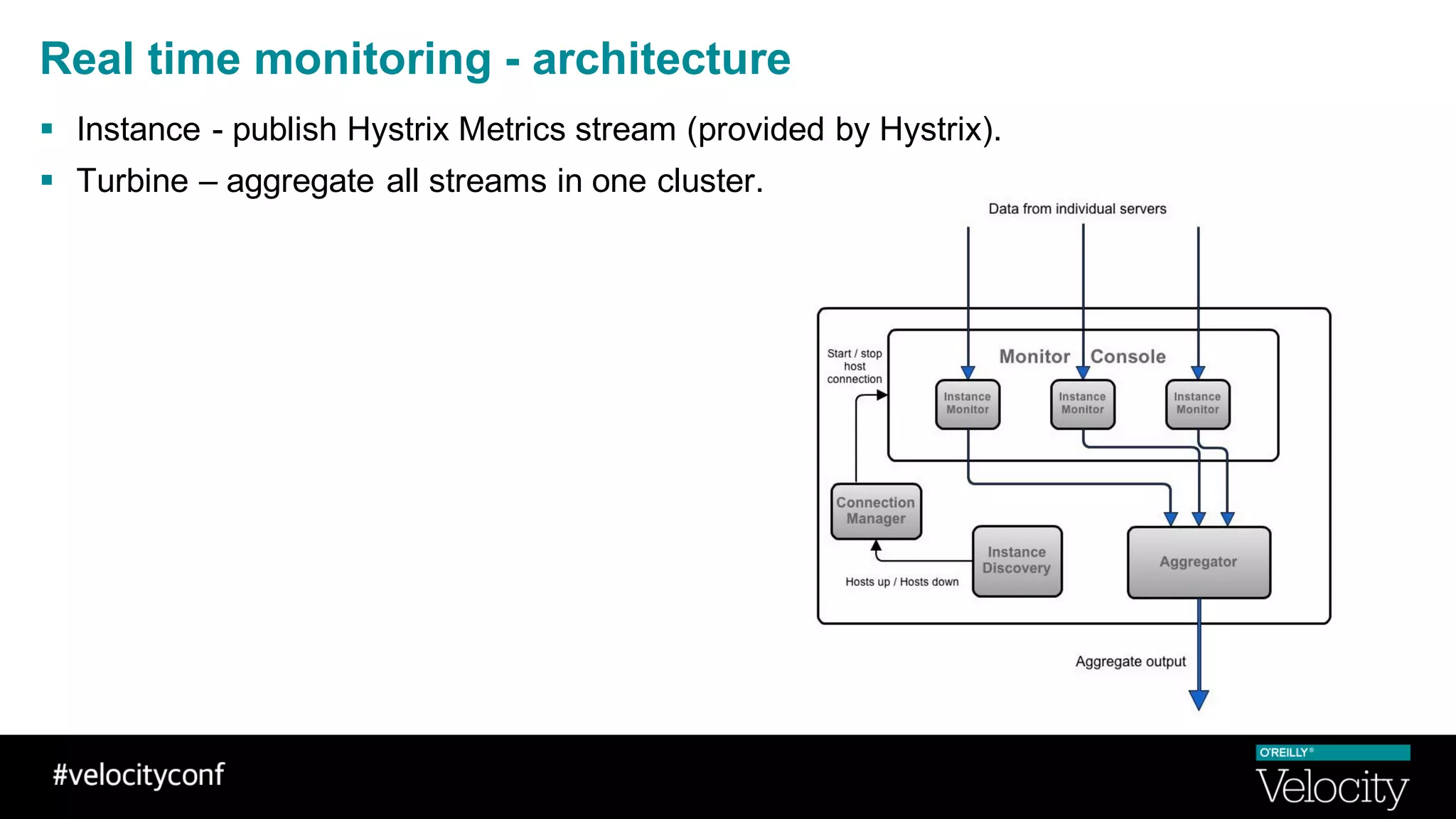
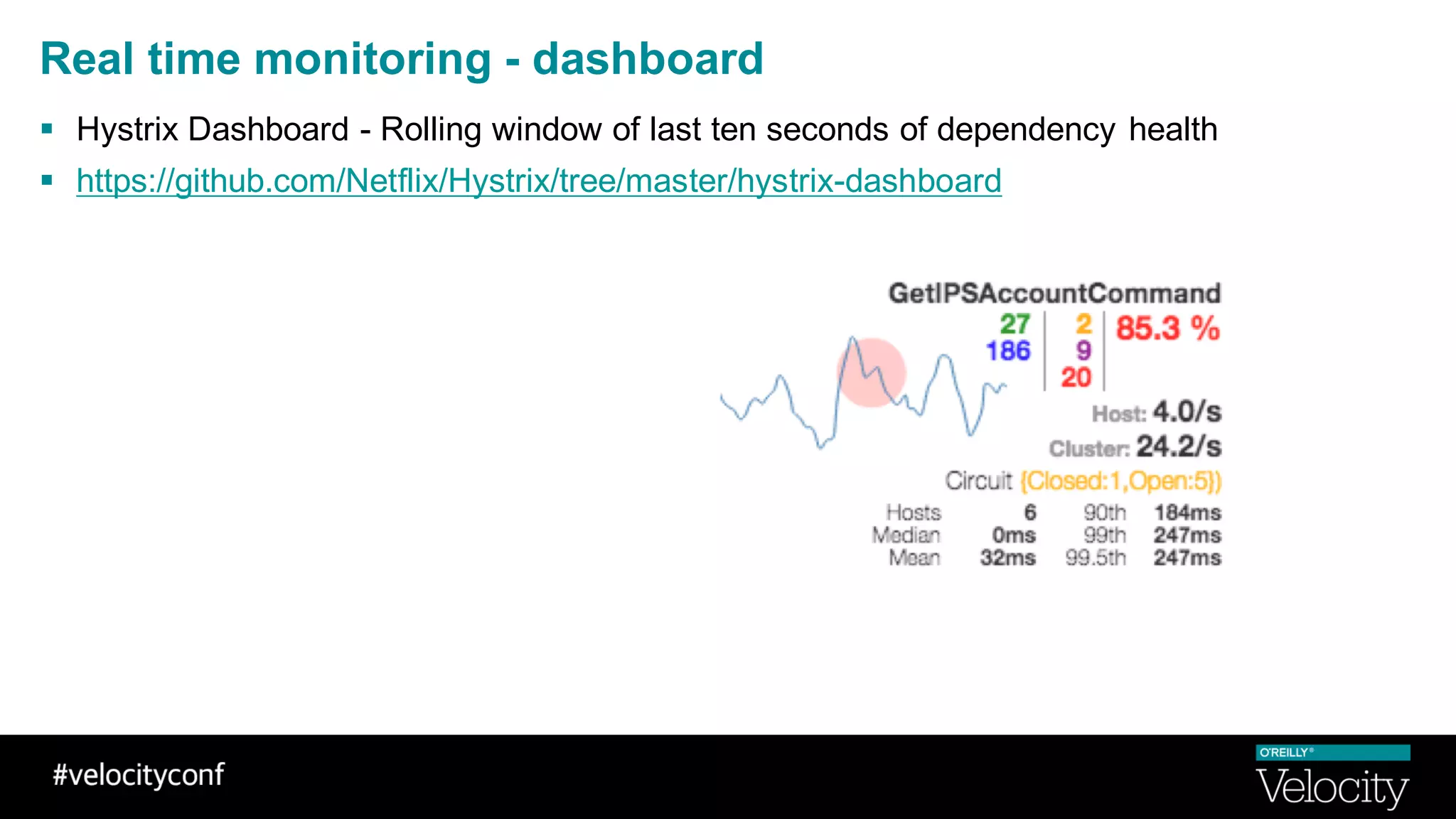


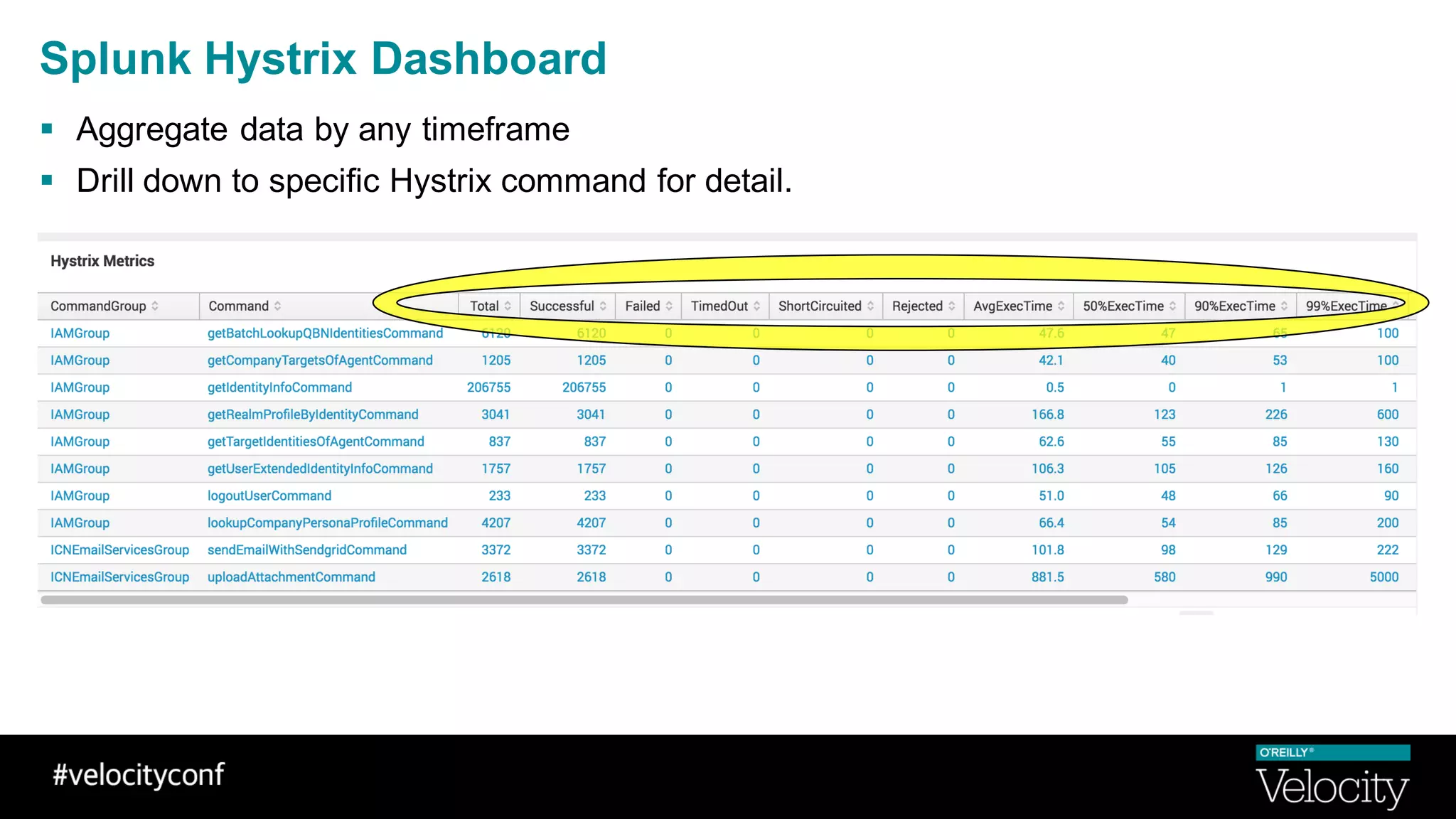
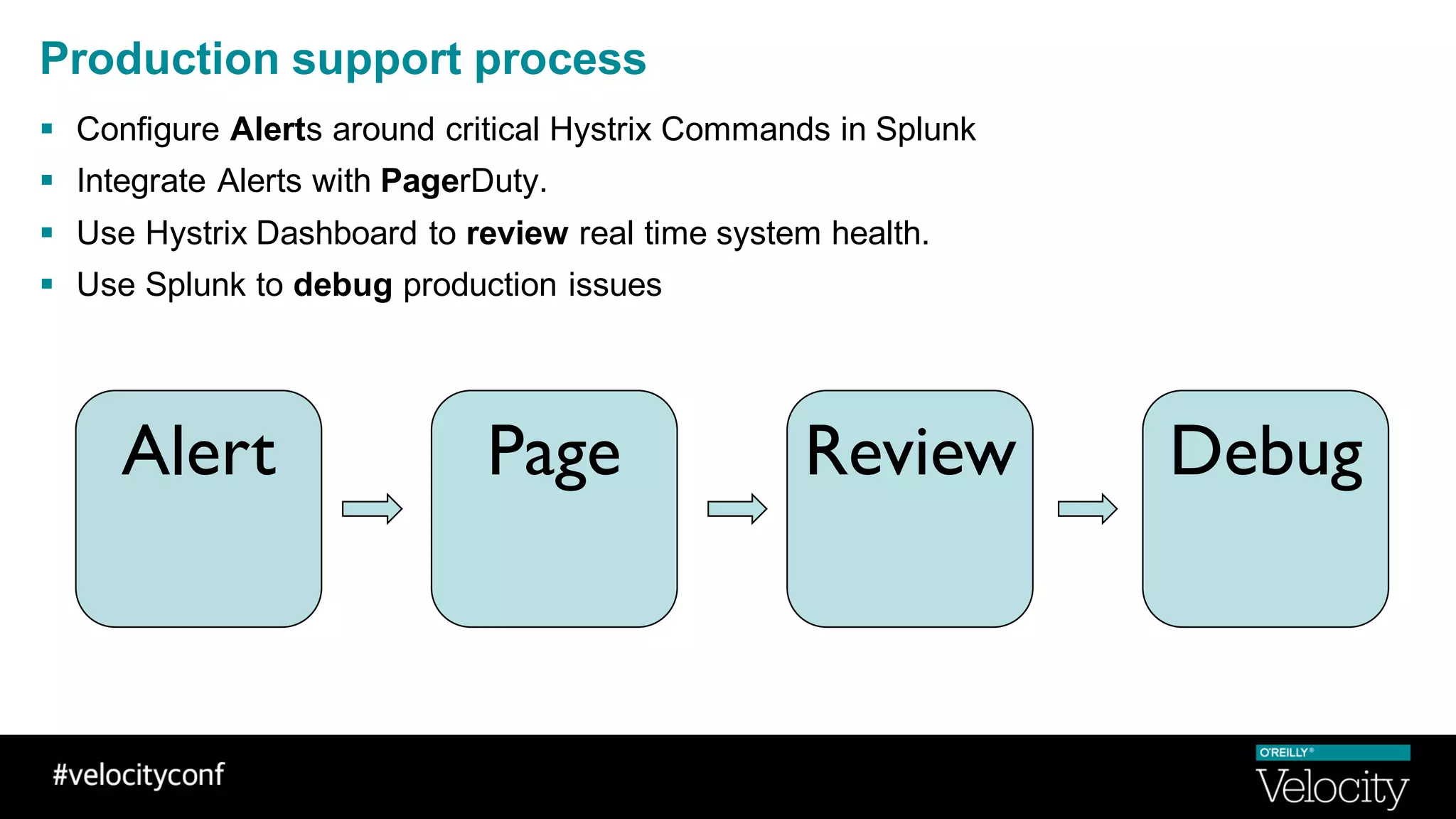






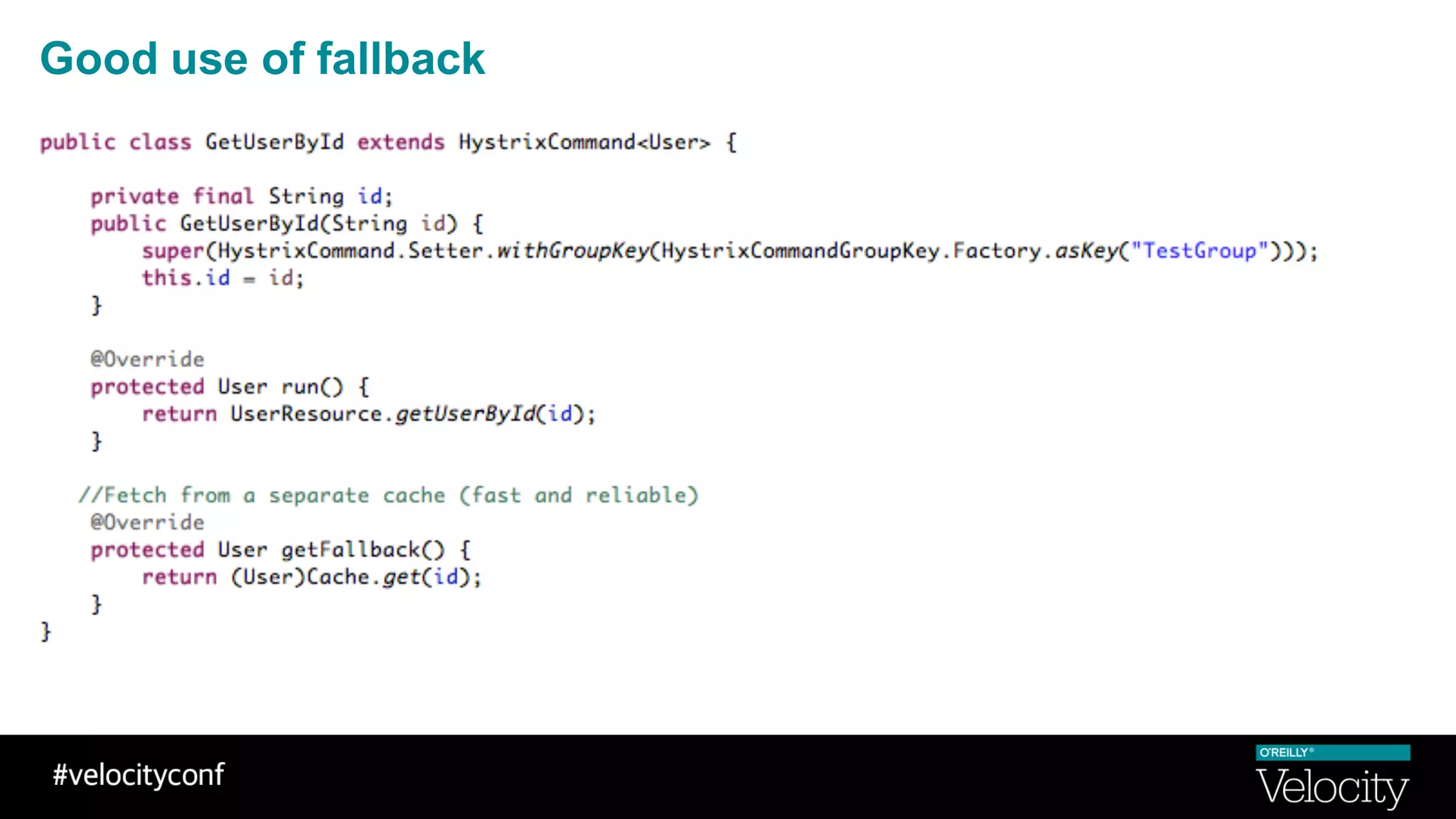









The document discusses operational excellence with Hystrix, a library for handling failures in distributed systems. It provides an overview of Hystrix and how Intuit's QuickBooks Online (QBO) team used it to address challenges from microservices and dependencies. The summary discusses how Hystrix implements automatic fail fast and fallback capabilities, and how the QBO team applied Hystrix, implemented monitoring, and used the data for troubleshooting.



































































